
基于总体平均经验模态分解和一步式字典学习联合去噪的语音端点检测算法
2021-01-14 03:13张开生赵小芬
科学技术与工程 2020年35期
张开生,赵小芬,王 泽,宋 帆
(陕西科技大学电气与控制工程学院,西安 710021)
声音是沟通的最直接方式,随着信息科技的不断发展,语音识别技术在各行各业的应用中扮演着越来越重要的角色[1-3],端点检测技术是检测输入声音信号的起始位置与结束位置,从某种程度上来说,端点检测效果的好坏能直接影响到语音识别的成功与否[4-6]。针对端点检测技术的研究,目前广为使用的方法有双门限检测法、方差法、谱距离法、相关法等[7]。但是这些方法在复杂环境处于低信噪比下,检测效果并不十分理想,甚至会出现检测错误等情况,这显然会对后序语音处理产生消极影响[8],针对此种现象,相关学者在传统算法的基础上作出改进。朱春利等[9]提出基于最小均方误差(least mean square,LMS)减噪与改进的双门限语音端点检测方法,首先通过对输入语音进行LMS减噪,然后将传统的双门限法作出改进并进行端点检测,此方法实现起来较容易,但是在实际复杂噪声环境下,检测效果也不理想。刘玉珍等[10]提出基于频谱方差的抗噪声语音端点检测算法,根据语音信号和噪声信号频谱的差异来进行端点的检测,但是这种方法仅是在白噪声下适用。董胡等[11]提出改进的能量谱熵端点检测算法,此算法结合了贝叶斯信息准则和模糊C均值聚类算法,并对能量谱熵特征门限进行估计,最后采用双门限算法进行端点检测。此种算法虽然在低信噪比下能实现端点的检测,但是检测的准确率并不能满足实际情况需求,且并未提及检测效率的问题,实际场景中检测效率也是必须要考虑的关键因素。
针对上述方法存在的问题,研究一种将总体平均经验模态分解(ensemble empirical mode decomposition,EEMD)算法与一步式字典学习(one-stage dictionary learning,OS-DL)结合的方式联合去噪,并将其用于端点检测中。充分结合了EEMD算法平滑脉冲干扰异常事件的能力与OS-DL算法高效的字典训练能力,将去噪后的语音信号通过均匀子带频带方差法实现端点检测。
1 EEMD算法原理
EEMD算法在经验模态分解( empirical mode decomposition,EMD)算法的基础上进行了改进,由于EMD在分解信号得到本征模式分量(intrinsic mode function,IMF)时存在模态混合现象,这种现象导致了IMF分量不精确。EEMD算法正是解决了EMD算法存在的这个问题[12-14]。EEMD算法是通过信号极值点影响IMF,它的原理是引入白噪声,并将其运用到被分析的信号中,正是利用白噪声频谱均匀分布的特性,将白噪声与待分析信号叠加,这样可以使待分析信号自适应的分布在一个适宜的参考尺度,由于噪声具有零均值的特性,多次计算平均值之后就会使得噪声相互抵消,最终得到的均值结果与原始信号作差的值与平均计算次数之间会呈现出反比例的关系。因此,最终的结果就可以以均值计算结果来表示。EEMD算法的具体流程如图1所示。
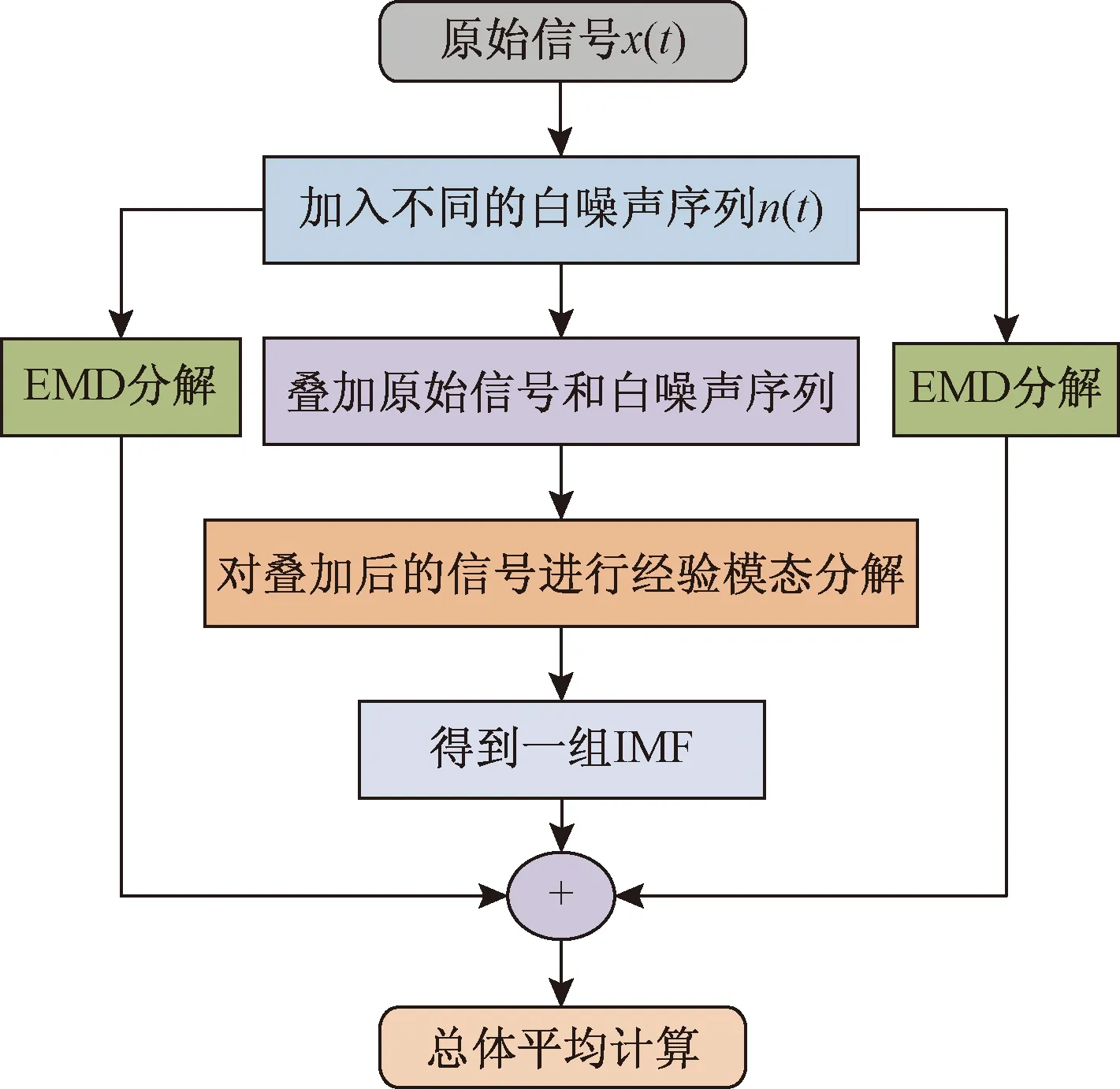
图1 EEMD算法流程Fig.1 EEMD algorithm flowchart
2 OS-DL算法原理
字典学习的主要思想是利用包含K个原子dK的字典矩阵D∈Rm×K,稀疏线性表示原样本Y∈Rm×n(其中m表示样本数,n表示样本的属性),即有Y=DX(理想情况),其数学描述为
(1)
式(1)中:X为稀疏编码矩阵;Xi(i=1,2,…,K)为该矩阵中的行向量,代表字典矩阵的系数;T0为逼近误差。对于系数的约束,OS-DL并未采用传统的l0范数,从本质上来说,l0范数并不是一个真正的范数,它主要的功能是在一个向量中去衡量一个非0元素数量,从准确性上来讲,由于得到l0范数的数学表达式并不容易,所以一般情况下,只是用它的优化式来解决问题,所以会存在一定的误差;而OS-DL算法利用l1范数,解决了l0范数存在的这个弊端。并且相较于传统的字典学习算法分为稀疏编码和字典更新两阶段,OS-DL算法实现编码与更新同步[15],在进行初始值系数矩阵设定的同时实现字典的更新,相较于广泛使用的字典训练K奇异值分解(K-singular value decomposition,K-SVD)算法来说,在效率上大大提升。
3 EEMD与OS-DL联合去噪算法方案构建
假设带噪语音信号为x(n),利用EEMD算法对输入信号x(n)进行分解,分解之后得到多个IMF,由于前两阶的IMF含有75%的噪声分量,因此丢弃掉前两阶的IMF,相当于对输入语音进行降噪处理,并且丢弃掉前两阶IMF可以减弱语音信号中的高频分量,并不会影响对于后序端点的检测。输入语音信号时,由于各种原因,其中常会掺杂噪声信号,而经过EEMD分解之后,得到分解出的语音信号相对来说较为纯净,因此分解之后的信号稀疏特性将会增强。然后利用OS-DL算法分别对纯净语音信号及噪声语音信号进行训练,得到联合谱字典,再利用离散傅里叶变换(discrete Fourier transform,DFT)计算出相位谱和幅度谱,对其进行分析之后对幅度谱进行稀疏表示,得到系数矩阵后,重构语音信号频谱,经过傅里叶逆变换得到降噪后的语音信号。
4 端点检测方法改进
4.1 均匀子带分离频带方差端点检测
在频带方差的计算中,每帧数据长为N,经过快速傅里叶变换以后,在正频域内的谱线就有(N/2+1)条。然后将这些DFT后幅值谱线Xi={Xi(1),Xi(2),…,Xi(N/2+1)}分割成q个子带,于是就有每个子带具有p=fix[(N/2+1)/q]条谱线(fix[·]表示取其整数部分),则构成的子带为
(2)
令XXi={XXi(1),XXi(2),…,XXi(q)},则均值为
(3)
方差为
(4)
4.2 算法方案构建
改进算法的主要思路是首先利用EEMD算法对输入语音信号进行分解,以此得到多个IMF分量,并对其进行相关分析,去除噪声分量,再通过OS-DL算法进行字典的训练,得到纯净语音信号及噪声信号,并将分离出的语音信号及噪声信号进行稀疏表示,求得包含系数的矩阵,利用此系数矩阵对语音信号进行重新构建,新构建出的语音信号便是降噪后的语音信号,然后将消噪后的语音信号通过子带频带方差法可以得到每帧均匀子带分离的频率方差值,在已知前导无话端的帧数后,求出相应的阈值,进而确定语音信号端点的位置。
4.3 具体算法步骤
(1)输入语音信号x(n)(带噪)。
(2)利用EEMD算法对x(n)进行分解。
(3)利用OS-DL算法进行字典训练。
(4)稀疏表示出训练出的语音信号和噪声信号,并得到系数矩阵。
(7)计算每帧子带分离的频带方差。
(8)根据频域方差双门限法进行端点的检测。
改进算法的流程框图如图2所示。

图2 改进算法流程框图Fig.2 Improved algorithm flow diagram
5 结果与分析
本文算法是在Intel(R) Core(TM)i5-6200U CPU,主频为2.30 GHz,GPU显卡为AMD Radeon R5 M315以及4 GB内存配置的Windows7计算机上进行测试。由于本文算法是在语音控制垃圾分类背景下进行的研究,因此所选用的语音数据内容来源于《西安市生活垃圾管理办法》中的相关垃圾种类。在MATLAB 2014软件下进行的仿真实验,其语音信号采样频率为8 000 Hz,语音格式为wav格式。为了验证本文算法的准确性,对《西安市生活垃圾管理办法》中所涉及到的30余种垃圾类型都作为语音输入,如“瓜果皮核”“废弃电池”等。分别由10名男生、10名女生以及10名儿童进行录入,录入语音均为标准普通话。每种垃圾类型对应的语音每人读入1遍,共1 000余条语句。
5.1 不同语音消噪算法比较
为了检测本文语音消噪算法的有效性,将本文消噪算法与目前常用的LMS自适应消噪算法、谱减消噪算法进行比较,得到图3、图4。其中图3所示为输入语音“废弃电池”在5 dB时的语音消噪结果。图4所示为输入语音“废弃电池”在0 dB时的语音消噪结果。可以看出,在信噪比较高的情况LMS自适应消噪算法、谱减消噪算法以及本文消噪算法都表现出了良好的降噪效果,但是在信噪比为0 dB时,相较于其他两种算法,本文消噪算法表现更佳。

图3 几种不同语音消噪算法在5 dB时结果对比Fig.3 Comparison of the results of several different speech denoising algorithms at 5 dB

图4 几种不同语音消噪算法在0 dB时结果对比Fig.4 Comparison of the results of several different speech noise reduction algorithms at 0 dB
5.2 端点检测结果及分析
图5所示为输入语音“剩饭剩菜”分别在信噪比为5、0、-5 dB时本文算法的端点检测结果,图5中语音信号的起始位置用实线标记,语音信号结束位置用虚线标记。这里标记的是单个字的起始位置与结束位置。从图6中可以看出,在信噪比下降的情况下,仍然能准确的检测出语音信号端点。图6所示为输入语音为“废弃电池”在信噪比为5、0、-5 dB时的检测结果,同样可以验证本文算法的可靠性。
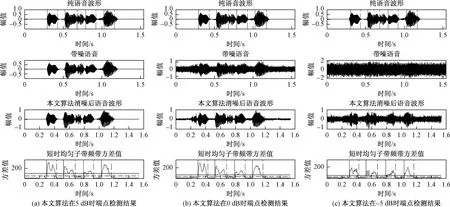
图5 输入语音“剩饭剩菜”在5、0、-5 dB时端点检测结果Fig.5 Endpoint detection results of input voice “leftovers” at 5,0,-5 dB

图6 输入语音“废弃电池”在5、0、-5 dB时端点检测结果Fig.6 Endpoint detection results of input voice “waste battery” at 5,0,-5 dB
对实验中所采用的30余种垃圾类型对应的输入语音分别进行多次实验,输入语音类型分为男声、女声、童声。并对端点检测的准确率(准确率=检测正确的帧数/总帧数)作以统计,随机选取10组结果,如图7所示。从图7可以看出,输入语音的变化,并不会引起端点检测准确性的降低,在信噪比下降到0 dB以下,多数检测准确率大于90%,平均检测准确率达到85%以上。

图7 不同输入语音男声、女声、童声检测准确率统计Fig.7 Statistics of male,female and child detection accuracy of different input voices
为进一步验证本文算法的可靠性,对传统常用的端点检测方法(包括双门限法、能熵比法、谱距离法)的平均耗时进行统计,结果如表1所示。由于在对语音信号进行端点检测之前,首先进行消噪处理,去除噪声的干扰且OS-DL算法将稀疏编码与更新同步,因此本文改进算法在效率上得到大幅度提高。

表1 各个算法平均耗时统计Table 1 Statistics of average time consumption of each algorithm
不同噪声下各个算法的平均检测准确率如图8所示,选取noisex-92噪声库中的白噪声、粉红噪声、餐厅噪声及工厂噪声在不同信噪比SNR下各个算法的准确率进行统计,从图8可以看出在信噪比为5 dB以上时,各个算法的检测准确率都接近80%,其中本文算法更是达到了90%以上的检测准确率,而在信噪比为-5 dB以下,传统算法几乎失效,而本文算法无论是在高信噪比还是低信噪比下,其准确率最低达到85%,多数在90%以上。
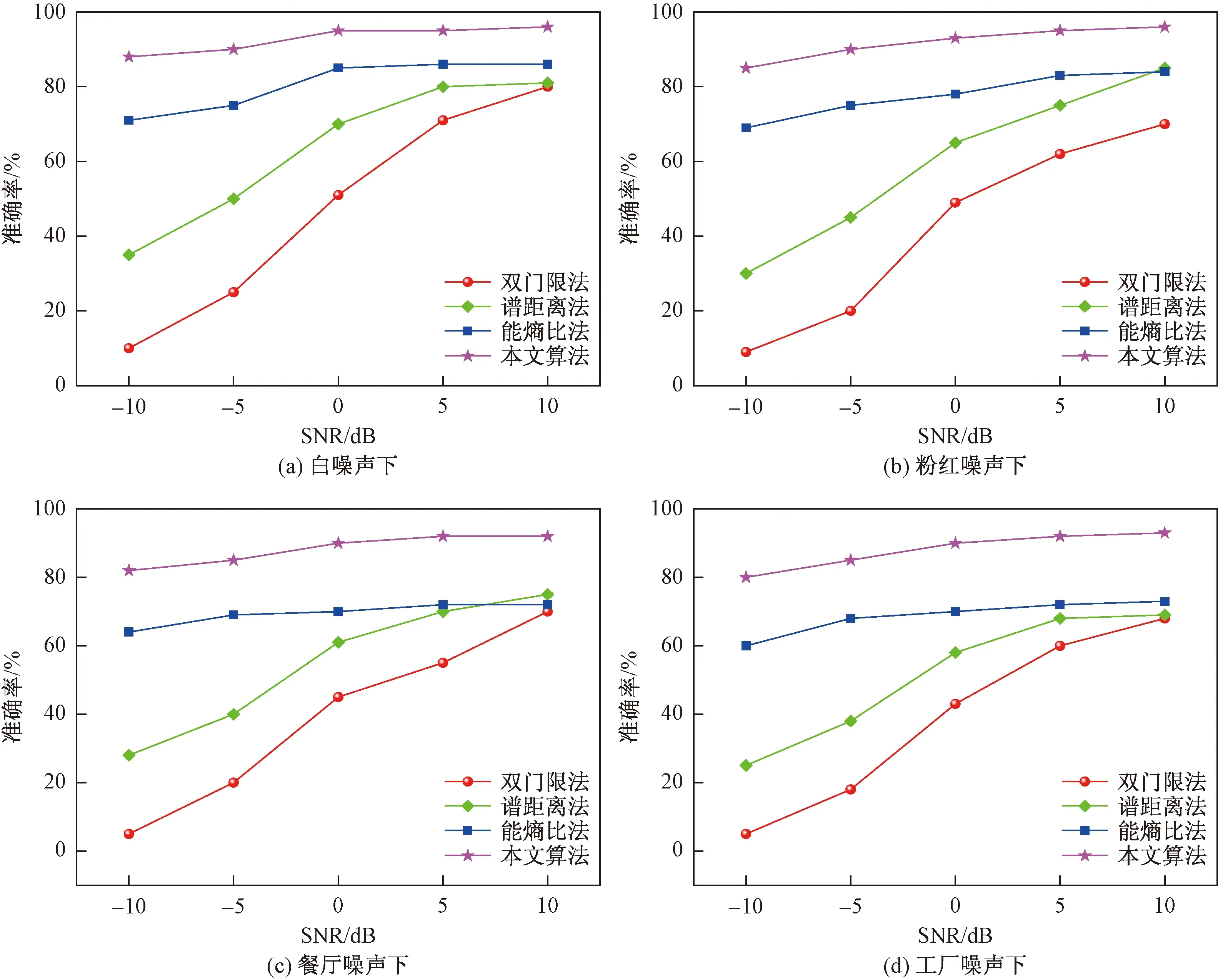
图8 不同噪声下各种算法检测准确率比较Fig.8 Comparison of detection accuracy of various algorithms under different noises
6 结论
对基于EEMD和OS-DL联合去噪的语音端点检测算法进行了相关研究,首先利用EEMD算法对含噪语音信号进行分解,并得到本征模式分量,然后进行相关分析后,去除噪声分量,再通过OS-DL算法进行字典的训练,得到纯净语音信号及噪声信号,并将分离出的语音信号及噪声信号进行稀疏表示,并根据获得的系数矩阵重构出语音信号,重构出的语音信号就是消噪后的语音信号,然后将消噪后的语音信号通过子带频带方差法可以得到每帧均匀子带分离的频率方差值,在已知前导无话端的帧数后,求出相应的阈值,进而确定语音信号端点的位置。实验结果表明,本文改进算法在信噪比下降到-10 dB以下时仍然具有85%以上的检测准确率。由于OS-DL算法相较于传统的字典算法,训练和重构是同步的,因此对于效率增强方面其效果是很明显的。其检测效率缩短至传统算法的近1/3。并且在各种类型噪声及不同输入语音下仍然具有较高的准确率,显示出本文改进算法较强的鲁棒性。并为语音识别垃圾分类提供了创新思路。
猜你喜欢
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
语数外学习·高中版中旬(2020年8期)2020-09-10
中学生数理化·教与学(2019年8期)2019-09-18
小学阅读指南·低年级版(2019年11期)2019-07-01
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·九年级(2017年10期)2017-11-08
读者(2016年14期)2016-06-29
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
