
面向智慧运维的分布式光伏知识库构建方法
2021-01-14 01:49欧一鸣苏雍贺邹孝付张长志
计算机集成制造系统 2020年12期
欧一鸣,苏雍贺,邹孝付+,靳 健,张长志,陶 飞
(1.北京航空航天大学 自动化科学与电气工程学院,北京 100191;2.北京师范大学 政府管理学院,北京 100875;3.国网天津市电力公司 电力科学研究院,天津 300384)
0 引言
近年来,分布式光伏产业呈现爆发式增长,但行业飞速发展的同时也对分布式光伏电站的运维能力提出了新的要求。分布式电站距离过远、信息无法精准传递,因此无法像大规模集中式电站一样组建一支随时待命的高专业度运维团队。同时,目前的分布式光伏运维工作通常由第三方公司或个人承担,人员的专业度很不稳定,运维模式又很依赖经验,往往会误判电站的故障,造成人员在故障电站与运维站点间重复往返,降低运维效率。因此,亟需一种智慧运维系统,根据电站业主的运维诉求,提供精准的电站状态判断和方案支持,以节省运维人员的精力、避免重复往返浪费时间,进而改善当前的运维现状。
要实现这样的智慧运维系统,首先需要建立适用于分布式光伏运维领域的相关知识库。这种知识库有利于智慧运维系统从更加专业的角度分析问题,并利用分布式光伏领域知识为运维人员提供更专业的技术方案支持,因此建立分布式光伏领域的知识库是智慧运维的关键步骤。
对计算机系统来说,传统的文本形式知识库在检索速度、逻辑推理、知识结构表示等方面都存在一定的短板,因此建立一种细粒度的、图谱化的知识库已成为新型智能运维系统的新需求。知识图谱(knowledge graph)是Google公司在2012年提出的概念,它包含现实中的各种实体以及实体之间的关系,实体按照关系相互连接,表示为语义网络的形式。在知识表示方面,它的基本单元为[头实体(Head),实体关系(Relation),尾实体(Tail)]形式的三元组,有利于计算机进行推理、存储和表示。对分布式光伏领域而言,构建这样的知识库则是要将领域中的设备部件和技术故障等相关概念作为实体,并按照关系相互连接形成图谱。有了这种图谱化的知识库,智慧运维系统可以更加标准化、有逻辑地为运维工作提供服务,如雷兵[1]使用Web本体语言(Web Ontology Language, OWL)构建了一个商务需求领域的图谱化知识库,可以有效地对客户需求进行提取,这与分布式光伏运维领域利用知识库从运维诉求中提取信息是相通的。
在预想的应用场景中,为了充分利用图谱形式知识库的细粒度、可推理等特性,智慧运维系统应能够将运维诉求描述与图谱中的实体元素对应,并通过实体之间的关系,将诉求映射到图谱中的一个子图中,再利用图搜索技术获取方案。为支持该预想应用场景的实现,知识库对分布式光伏领域的实体与实体关系的提取步骤提出了更高的要求。为实现专业领域的诉求理解,需要进行更细粒度的实体提取,并对准确度提出更高的要求。为更好地发挥图谱化知识库支持推理的特性,需要更全面、更准确地提取实体之间的关系。对于当前的数据情况,基于无监督学习的实体提取和基于远程监督学习的实体关系提取方法是较为合适的方法,但现有算法模型与分布式光伏领域的数据特点不太契合,需要进行改进。
针对以上问题,本文在实体提取步骤上,将其转化为领域关键词发现问题,利用基于word2vec生成的词汇相似度,改良TextRank算法,实现分布式光伏领域的实体提取。在实体关系提取步骤上,对于领域中同一对实体可能同时有多种关系的情况,改良了分段卷积神经网络分段卷积神经网络(Piecewise Convolutional Neural Network, PCNN)的分类器层,使其更契合分布式光伏领域的数据情况。本文改良的知识库构建方法,自动化程度较高,可以有效减少构建所需的人工成本,并能够以现有数据填补面向分布式光伏智慧运维知识库的空白,同时提高准确性。
1 光伏智慧运维知识库的国内外研究现状
1.1 知识库在智慧运维中的应用
目前,知识库在智慧运维中主要分为文本知识库和图谱化知识库两种形式,构建的主要数据来源包括维修工单和用户手册中的文本[2-4]。文本形式的知识库在应用中主要通过语义分析等手段与输入的诉求进行文本匹配。如鞠冬彬[5]将用户的业务查询信息与文本知识库中的文档进行比对,提高了运维客服的处理速度。但这种知识库的应用通常仅从文本分析的角度出发,在限定领域中缺乏专业的分析能力,容易误判诉求信息。而图谱化知识库由领域内的实体名词与实体关系构成,能够描述实体之间的关系,可以用于设备状态评估和运维预案生成。邱剑[6]利用图谱化的知识库构建了一种面向电网运维的自然语言处理引擎NLP4PG,可以从历史工单的文本数据中提取专业信息、评估设备的状态。许鑫[7]设计了一种自然语言预案生成系统,通过建立电力领域的图谱化知识库来提取和利用电力领域的知识,为运维人员的检修工作提供一定的指导。万姗等[8]将数控机床的结构化本体库作为一种图谱化知识库,根据维修需求的案例适应度匹配历史方案作为预案。这种知识库支持推理,在专业领域中能够更好地分析问题,在运维中提升诉求理解的准确性。
目前,在实践中图谱化知识库的构建主要有自顶向下和自底向上两种流程[9]:
(1)自顶向下构建 通常是半人工半自动构建,该方法先人工确定好数据模式与知识库结构,再往其中填入实体等知识,七步法[10-11]就是典型的专业领域图谱化知识库自顶向下构建方法。由于领域实体数量较多、实体之间关系复杂,这种自顶向下的构建方法比较耗费人力,而且对人员的专业度要求高,准确度容易受到人员主观影响。
(2)自底向上构建 该方法需要利用无监督或远程监督学习等技术手段,从文本中自动抽取知识构建图谱化知识库。如IBM Watson[12]平台使用了一种实体连接算法来自动构建图谱。这种自动构建方法可以节省人工成本,构建速度也较快,同时也能保证准确度。
1.2 图谱化知识库自动化构建相关研究
目前,图谱化知识库的自动构建分为自动映射和非结构化数据提取两种。自动映射主要有结构化数据映射[13]和基于模板抽取[14]两种方法。非结构化数据提取一般是指从文本中提取所需知识,提取目标为实体和实体关系,再将实体通过实体关系相连接形成知识图谱,因此流程分为实体提取和实体关系提取两步,典型的有DeepDive[15]提取框架。本文构建分布式光伏领域知识库的数据都来源于文本,因此要从非结构化数据中提取相应领域的知识,包括实体提取和实体关系提取两步。
1.2.1 领域实体提取研究现状
实体提取步骤又称为命名实体识别,分为有监督学习和无监督学习两类方法。在有足够标注数据的情况下,监督学习方法中的卷积神经网络(Convolutional Neural Network, CNN)、条件随机场(Conditional Random Field, CRF)结合BiLSTM模型[16]等方法可以得到较好的效果,但若没有现成的标注数据,则要消耗很多人力物力来获取。目前,由于分布式光伏领域还比较缺乏有标注数据,本文采用无监督的领域实体提取方法。对于无监督的实体提取任务,常用手段包括基于半结构化数据库、基于规则模板和匹配基于统计特征的方法。
(1)基于半结构化数据库的方法 是利用网络百科等有一定书写规律的数据来提取实体,建立词典后,借助词法和句法分析手段,提取出数据中蕴含的实体名词。Guo等[17]设计了一种基于维基百科的实体提取流程,通过建立字典并设计一套流程,提取出句子中蕴含的实体。
(2)基于规则模板匹配 是由人工制定一套规则来进行直接匹配。这种规则可以是基于词典的字符串匹配等,由人工进行测试,然后不断改进,最终达到较好的效果[18]。
(3)基于统计特征的方法 是根据词汇在领域文本中的统计信息所提取的特征,通过赋予词汇权重或者与开放领域语料库进行比较,来提取领域实体名词,该过程也用于解决关键词提取问题。赵志滨等[19]采用词频—逆文档频率值(Term Frequency-Inverse Document Frequency, TF-IDF)值结合词向量作为特征来发现领域词汇,Lee等[20]使用基于PageRank的算法来判断一个词是否属于关键词。
对于本文来说,由于分布式光伏运维是一个新兴领域,相关的百科数据库尚不完善,缺乏难以直接使用基于网络数据库的方法。基于规则模板匹配的方法对人力的依赖程度非常高,需要高度专业的领域和语言专家进行大量的工作才能完成。基于统计特征的方法对人力成本的消耗很低,通用性较强,常用方法有TF-IDF和TextRank等,但容易受到固定句式等因素影响,需要引入外部信息来进行改进。
1.2.2 实体关系提取研究现状
实体关系提取的主要任务是给定一对实体,从已有的文本数据中提取出这两个实体之间的关系,通常以三元组的形式表示,主要分为有监督学习、无监督学习、半监督学习和远程监督学习4种方法。在有标注数据充足的情况下,TextCNN等卷积神经网络是一种行之有效的文本分类有监督学习模型[21],但由于目前分布式光伏领域缺乏已标注数据,无法使用有监督方式进行。无监督方法主要应用于开放领域,对于限定领域的关系提取不够细致,无法满足面向智慧运维的知识库要求。半监督方法能够只利用少量的有标注样本,让模型根据一定的模式自我训练,如Hakami等[22]基于自监督方法进行关系提取,倪维健等[23]通过转导支持向量机(Transductive Support Vector Machine, TSVM)转导支持向量机进行半监督学习。半监督方法虽然对人工标注的需求较低,但容易出现“语义漂移”的问题,准确度不足。远程监督方法可以利用公共领域知识库,通过学习其他知识库中表示同样实体关系的文本特征,来判断分布式光伏领域文本中的实体关系,这种方法不需要领域内的有标注数据,准确度也较高。
远程监督关系提取主要包括基于语法特征的方法、基于隐变量概率分布的方法和基于神经网络的方法。基于语法特征的方法是指分析两种实体之间的语法特征作为实体关系的分类依据。Mintz等[24]利用依存句法分析了维基百科中的文本,在使用这种方法时首次采用了远程监督手段,同时还作出了“远程监督假设”,认为所有同时提到两个实体的句子都有可能蕴含两个实体的关系信息。基于隐变量概率分布的方法采用隐含狄利克雷分布的模型对句子的统计信息进行建模。如周娜等[25]通过构建隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)主题模型,提取核心期刊的“作者—内容—方法”之间的关系。基于神经网络的方法将深度学习模型用于实体关系提取,常用的深度学习模型包括卷积神经网络等,在实体关系提取任务上的准确度已显著高于传统的机器学习方法[26]。
目前,基于CNN的方法性能较优,该方法可以减少对现有词法、句法分析等自然语言处理工具的依赖,避免错误率叠加,从而提高准确度和可用性。同时,在网络的池化层使用分段池化方法,可以将实体的上下文与位置关系等信息也提取出来,提升模型效果。在当前的CNN模型中,分类器层多使用Softmax分类器,这种分类器适合多分类问题,并能够得到每个类的相应概率。但由于分布式光伏领域中,同一对实体的多种关系之间并不互斥,如果使用CNN模型,可以对分类器层进行相应的修改,使提取结果更加全面,提高准确度。
2 分布式光伏图谱化知识库构建模型
当前分布式光伏领域可利用的文本数据主要包括维修工单和运维手册,数据量较大,均为没有标注的文本数据。本文将利用分布式光伏领域无标注文本,采用无监督的方法,进行基于统计特征的实体提取,构成领域实体库;利用开放领域的知识库数据,采用远程监督的方法,进行实体关系提取,构成实体关系库。
具体构建流程如图1所示,包括实体提取步骤和实体关系提取步骤。
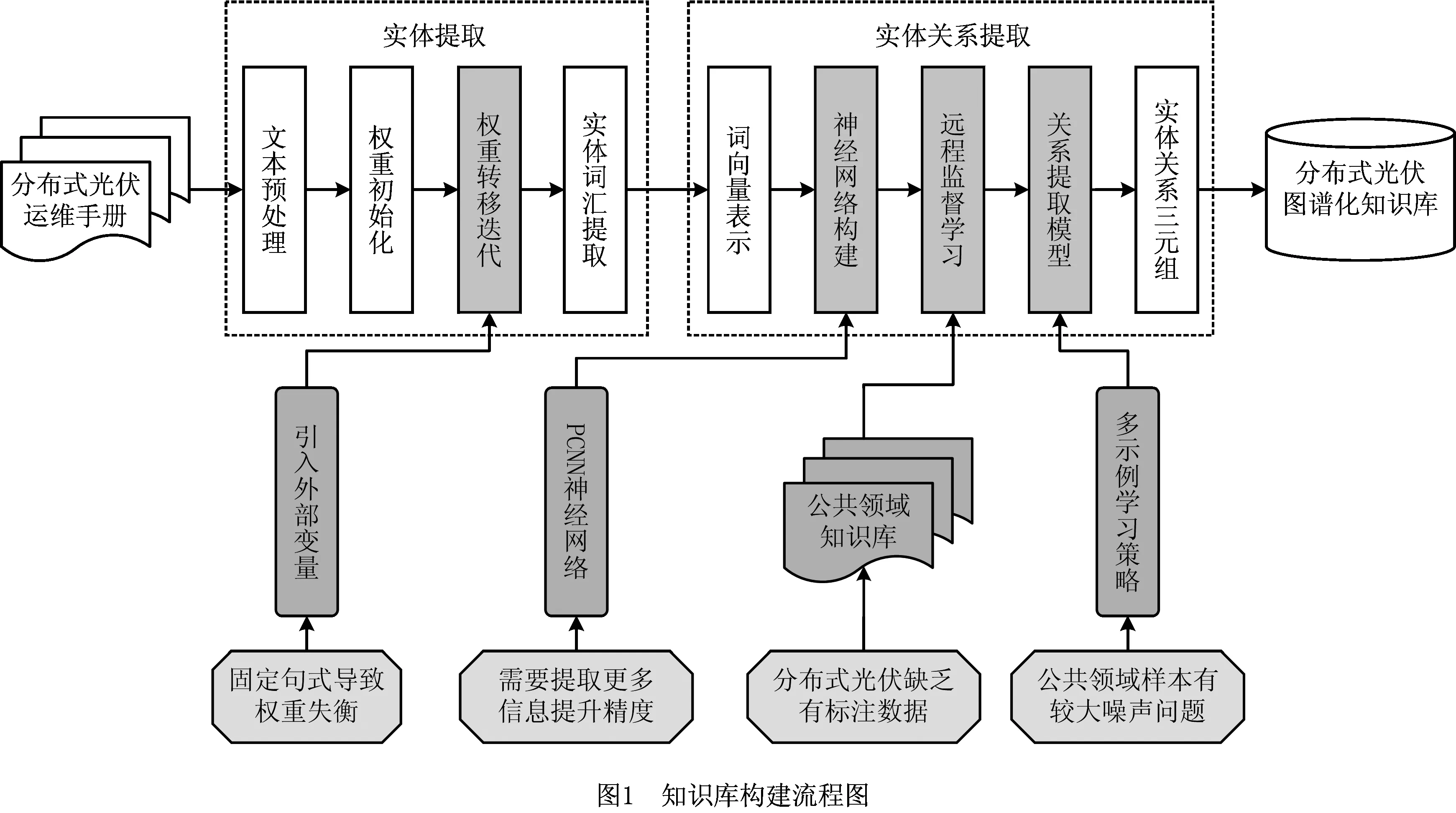
(1)实体提取步骤 因为分布式光伏领域可利用的数据中多为无标注的陈述性文本,所以可以转化为关键词提取问题。在该问题上,基于图模型的TextRank算法是一种广泛使用的方法[27-29],该方法通用性较强,不需要额外的训练数据。但是在单一领域的文本数据中,存在固定句式导致非领域词汇权重相互抬升的现象。因此,本文根据李俊等[30]引入外部语义信息改善权重传递过程的方法,针对分布式光伏领域,通过引入外部词向量来改进TextRank算法。该步骤利用运维手册中的无标注文本数据,获取光伏领域的实体词汇,以降低人工筛查的工作量,并提高提取性能。
(2)实体关系提取步骤 本文利用公共领域的百科数据库,通过远程监督学习的方法建立神经网络模型,从分布式光伏领域的无标注文本中提取实体关系。本文采用PCNN模型,更加注重实体之间的位置、距离和上下文关系;又根据分布式光伏领域实体之间可能有多种关系的特点,对模型的分类器层进行修改,形成了更适用于该领域的分段卷积神经网络—光伏(Piecewise Convolutional Neural Network-Photovoltaic, PCNN-PV)模型;又由于远程监督学习面临较大的数据噪声问题,使用多示例学习的方式来回避错误样本对模型训练过程的影响。最后,利用该模型处理分布式光伏领域文本,获得领域内的三元组信息,完成图谱化知识库的构建。
3 基于改良TextRank的图谱化知识库实体提取方法
3.1 TextRank方法介绍
TextRank[31]是一种经典的无监督关键词提取算法,具有良好的通用性。其输入是需要提取关键词的全部文本,通过给输入文本中的所有词赋予权重,得到所有词汇的权重列表作为输出。该算法的核心思想是:每个词将权重转移给它连接到的词,并获得其他词转移来的权重,经过多轮迭代后逐渐收敛,得到稳定的词汇权重。
令语料库中所有词汇的集合为M,向量M的长度为m,建立权重转移矩阵A,则A∈Rm。词汇wi从wj获得的权重转移量表示为aij,因此,对于A中的元素aij有:
(1)
式中:ωij表示权重在转移过程中wi在wj的共现窗口中出现过的次数;O(wj)表示wj为中心的共现窗口中出现除自己外所有词的数量。按这种方式对所有词汇组合生成aij,直到权重转移矩阵A建立完毕。初始化权重向量内所有的词的权重R(vi)=1,所有词汇的TextRank权重组成词汇权重向量S,则有S0=[1,…,1]T。将状态转移矩阵A作用于权重向量,k为迭代次数,得到Sk+1=ATSk。为保证权重达到收敛,定义阻尼参数d,此时有Sk+1=(1-d)Sk+dASk。按如此过程反复迭代,直到权重向量S收敛。求出所有词汇权重后,可以按照权重大小排序,提取出分布式光伏领域的关键词。最后,根据关键词的词性进行筛选,提取出名词关键词作为光伏领域的实体名词。
3.2 基于词向量距离的TextRank改良方法
在当前TextRank算法的假设中,在每一轮的权重迭代时,每个词应该只以共现窗口中的出现次数为依据,将权重传递给相邻的词。但是光伏运维手册中含有大量的固定组合句式如“……检查原因”,使得这些固定组合中的词汇存在相互抬升权重的现象,从而导致分布式光伏领域实体名词的权重排序受到干扰。
针对这种情况,本文对权重转移过程进行了改良。受无监督的聚类算法启发,本文认为,在以寻找光伏领域关键词为目的时,可以引入词向量影响权重转移的过程,减小无关词汇权重相互抬升。设定数个分布式光伏领域词汇作为“核心词汇”,在词向量空间中距离“核心词汇”越近的词将拥有更高的“质量”,在权重转移的过程中将获取更高的权重。
本文中TextRank算法的主要任务是获取分布式光伏领域的实体名词,因此可设置“光伏”、“设备”等词为核心词汇,如果核心词汇不止一个,在判断词汇质量时分别计算与核心词汇的词向量距离,取最小值。假设有核心词汇{wc1,wc2,wc3},核心词汇的词向量分别为{Vc1,Vc2,Vc3},待判断词汇wi的词向量为Vi,两词向量之间的距离取欧氏距离,记为:
dic=‖Vi-Vc‖。
(2)
根据词向量之间的距离,定义该词与核心词汇的相似度函数,使得越靠近核心词汇相似度越大,并用一个非线性函数将相似度限定在(0,1)之间,避免权重都向某几个词集中,本文使用如下双曲正切函数:
(3)
aij为词汇wi从wj获得的权重转移量,则进一步处理式(3):
(4)
为了保证在迭代过程中,权重总量不过分膨胀或缩水,对所有从wj转移出去的权重进行归一化操作,并使单个词汇的权重转移向量元素之和为1:
(5)
归一化之后可得新的权重转移矩阵,在词向量空间距离的影响下,分布式光伏领域词汇的权重在转移迭代中提升更快,更容易与其他无关词汇相互区分。
4 基于PCNN-PV的图谱化知识库实体关系提取方法
4.1 PCNN模型建立
远程监督的实体关系提取主要任务是从公共领域的百科数据中训练出一个模型,使得该模型在分布式光伏领域的文本中也能较好地进行实体关系提取,本文根据Zeng等[32]的远程监督学习研究构建了PCNN模型。由前文的TextCNN可知,以词的向量表示作为输入,并用卷积神经网络进行文本处理可以更好地捕捉上下文的相关信息。在池化层将句子根据实体词汇位置分割进行分段池化,可以为模型提供更丰富的信息。神经网络结构如图2所示。
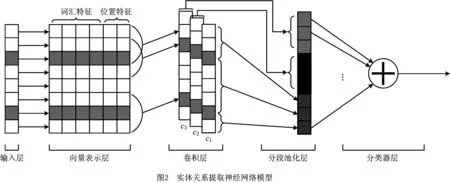
首先,将要处理的句子中每一个词都表示为词向量,从而生成一个相应的矩阵,该矩阵将作为初始数据输入到神经网络中。输入的矩阵经过一维卷积的处理后进入池化层,根据文献[32],使用分段最大池化(piecewise max pooling)进行操作,对于含有2个实体名词的句子来说,天然地可以按照实体位置将句子分割为3个部分。按照这种分割方式,将3个部分分别进行最大池化操作,可以捕捉到更细致的文本特征,从而更好地进行实体关系提取。最后,池化层的输出进入分类器层,通过Softmax等函数进行判断,得出关系提取的结果。
4.2 基于分布式光伏领域多标签问题改进的PCNN-PV模型
尽管PCNN在开放领域是一种较为有效的关系提取模型,但其在光伏领域内需要一定的改进以提高性能。在开放领域中PCNN模型会假设实体关系提取是一个多分类(multi-class)问题,即认为两个实体之间只存在一种关系,只需要从候选关系中找到最可能的一种。但对本文要构建的光伏领域知识库来说,两种实体之间可能存在不止一种关系,例如实体“空气断路器”对于实体“电路”来说,前者既是从属于后者的一种部件,也对后者起到了保护作用。因此,在光伏领域中,实体提取是一个多标签(multi-label)问题,广泛使用的Softmax多分类器并不直接适用于该领域。对此,可以使用多个2分类器来替代多分类器处理多标签问题,改良后得到针对分布式光伏领域优化的PCNN-PV模型。本文中模型使用多个Logistic分类器来输出结果。
池化层输出为g,W1是长度与g相等的权重向量,b为常数。Y为分类器的输出,由于该分类器为2分类,输出可能有Y=0或Y=1,将其表达为条件概率分布,有
(6)
(7)
(8)
为了减轻远程监督附带的噪声对实体关系提取效果的影响,在训练网络时需要使用多示例学习(Multi Instance Learning, MIL)策略,该策略由PAuer[33]首次提出。多示例学习的策略是将训练数据分为许多组,构成一个个“样本包(bag)”,每个“包”中包含多个“示例(instance)”。在训练时,不考虑任何单个样本的正或负类标注,而是关注“样本包”整体的标注情况。多示例学习作出如下假设:对于一个“样本包”,只要其含有的任何一个样本被认为是正类,则该“样本包”的整体就被标注为正;而当且仅当该“样本包”中所有样本都不是正类时,该样本才被认为是负类。而多示例学习的最终目标是训练出针对某一种实体关系、单个样本的分类器,以对单个样本进行单个实体关系的正负标注预测。通过这种训练策略,可以有效回避远程监督学习中的噪声问题。整体算法流程如算法1所示。
算法1多示例学习流程。
步骤1初始化神经网络的参数,将样本划分成许多个样本包。
步骤2随机将一个样本包M中的样本依次输入PCNN-PV模型中。
步骤3根据当前模型参数的预测,找到在当前样本包M中与目标分类最接近的样本m。
步骤4根据对m数据的最优化结果,对神经网络的参数进行更新。
步骤5重复步骤2~步骤4,直到收敛或达到预定循环次数。
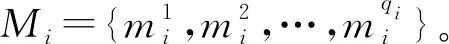
由于多示例学习是作用于“样本包”而不是单个样本上的,需要针对整个“样本包”进行条件概率计算。在所有的T组“包”中的样本都根据当前分类器得出判断结果后,才可以对模型进行参数更新。由于本文的实体关系提取是二分类问题,目标概率分布只有0和1,因此根据交叉熵(cross entropy)公式,可定义损失函数:
(9)
利用该损失函数,可以找到每个“样本包”中与目标分类最符合的样本。假设第j*个样本最接近目标,则有
(10)
接下来利用随机梯度下降(Stochastic Gradient Descent, SGD)、自适应矩估计(Adaptive moment estimation, Adam)等参数优化手段使得函数J(θ)最小化,以此实现分类器的训练过程。
5 构建效果验证与分析
5.1 验证设置与评价指标
5.1.1 知识库设计
图谱化知识库关系设计如图3所示,由领域实体库和实体关系库两部分组成。领域实体库包含“设备部件”和“故障概念”两类,“设备部件”指组成光伏电站的设备及部件名称,“故障概念”包含“热斑”、“短路”等设备部件可能发生的故障名称。实体关系库分为“因果关系”、“作用关系”等8类:“因果关系”指故障造成现象的因果,如“过热”会导致“报警”等;“作用关系”指某部件起到某种作用,如“蓄电池”是用来“蓄电”的;“发生关系”表示部件会发生的故障,如只有“光伏板”才会出现“热斑”、“隐裂”等;“包含关系”是概念上的包含,如“短路”是一种“故障”;“位于关系”表示位置上的联系,如“光伏板”位于“支架”上;“从属关系”代表设备由哪些部件组成,如“配电柜”由“柜体”、“断路器”、“互感器”等部件构成;“同义词关系”如“空开”、“空气开关”与“空气断路器”是同义词;“其他关系”则是其他不能直接概括的关系。

5.1.2 验证数据来源
根据目的不同,本文验证流程分为实体提取验证和实体关系提取验证两部分。其中:实体提取验证部分使用分布式光伏运维手册中的所有文本数据,利用基于词向量距离改良的TextRank算法进行实体提取,使用人工抽验的方法与其他算法进行准确度对比;实体关系提取验证部分使用CN-DBpedia[34]中包含的相关数据进行PCNN-PV模型训练,再利用该模型从分布式光伏运维手册的文本数据中进行实体关系提取。词向量表示部分均使用北京师范大学和人民大学共同开发的中文领域大规模预训练词向量Chinese-Word-Vectors[35]。
本文采用国家电网提供的《分布式光伏电站系列操作手册—运行维护》和书籍[36]作为该领域的文本数据集,数据量约6 000条句子、共40万字。用于远程监督的数据集CN-DBpedia格式如表1所示。

表1 CN-DBpedia数据格式
5.1.3 参数设置及实现
实体提取过程中,词表长度约22 000,初始权重向量为相应长度的全1向量,设置核心词汇为“光伏”、“设备”、“故障”,构建权重转移矩阵的共现窗口设置为w=5,迭代平滑参数d=0.85。
实体关系提取中,设定实体关系8种,分别为:“因果”、“作用”、“发生”、“包含”、“位于”、“从属”、“同义词”、“其他”,按以上设定从CN-DBpedia中获取训练样本。获取样本后,将所有词汇替换为词向量,每条文本对应为一个矩阵,作为模型的输入。该部分实验的主要超参数包括以下7种:词向量维数dw、位置特征向量维数dp、卷积核窗口长度w、卷积核个数k、单个样本包的大小n、学习率λ,以及防止发生过拟合设置的Dropout率。根据卷积层结构相近的多组实验结果[32,37-38],超参数设置如表2所示时,模型的性能较好。

表2 实验超参数设置
5.1.4 评价指标设置
在实体提取步骤,以准确率(Accuracy)作为评价指标,采用小批次人工抽验的方式,重复多次求平均值。准确率A的计算公式如下:
(11)
式中:T为正确的样本数,F为错误的样本数。
在实体关系提取步骤,根据前文远程监督学习的提出者Mintz[24]的实验,模型的评估应分为自动评估和人工评估两部分。评估分为两部分的原因在于可以用于评估的知识库本身是不完备的,也是因此才需要使用远程监督的方法。自动评估部分使用精度(P)与召回率(R)作为衡量性能的评价指标。人工评估部分采用小批次抽验,以准确率作为评价指标。精度P、召回率R和准确率A的计算公式如下:
(12)
(13)
(14)
其中:Tp为真正例,FP为假正例,FN为假反例。
5.2 验证结果分析
5.2.1 实体提取结果
在实体提取步骤,改良TextRank、TextRank和TF-IDF三种方法的准确率对比结果如表3所示。

表3 实体提取结果对比
由该结果可知,本文采用的改良TextRank算法与经典TextRank算法,以及基于统计的TF-IDF算法相比,平均准确率更高。引入核心词汇机制和词向量作为外部信息后,在权重转移的过程中,在向量空间中与核心词汇相近的词汇可以获得更多优势,减少固定句式对实体提取效果的影响。TF-IDF算法虽然有IDF值作为外部信息,但该算法仅考虑词频,忽略了词与词之间的联系,用于实体提取时效果不如TextRank。因此,改良TextRank算法可以更准确地提取出目标领域范围内的实体名词,也能够有效地减少实体提取步骤的人工工作量。
5.2.2 实体关系提取结果
使用MIL的PCNN-PV模型、使用多示例学习的TextCNN模型,以及不使用学习策略的PCNN-PV模型准确率、召回率曲线对比如图4所示。人工评估部分实验结果如表4所示。

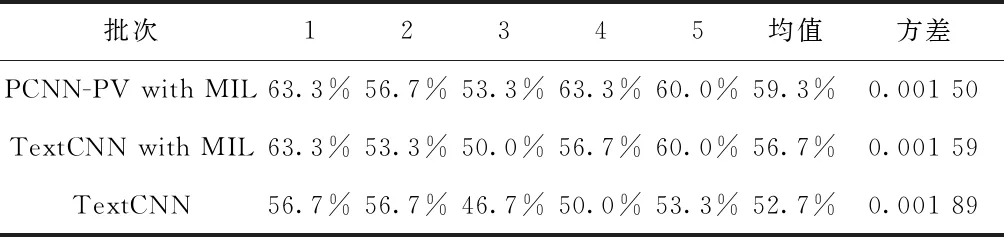
表4 实体关系提取人工评估准确率对比
由图4可知,在远程监督学习中,噪声问题较为明显,可以使用多示例学习等策略有效缓解。在使用多示例学习的情况下,PCNN-PV方法对比TextCNN方法,产生的结果准确率更高。当召回率高于0.3时,PCNN-PV的准确率比经典TextCNN模型准确率高约0.05,从而证明该模型的提取性能在一定程度上优于经典模型。分段池化的操作利用两个实体的位置将句子分割成3部分,分别池化之后可以将更多上下文信息纳入分析中。对分类器的修改让同一对实体可以同时属于多个分类,使模型适配了分布式光伏领域的特点,提高了准确度。由表4可知,本文所采用的PCNN-PV在光伏领域的实体关系提取上效果略优于经典的TextCNN。考虑到实际建立的图谱化知识库中,一些实体对可以通过其他实体跳转联系起来,例如“光伏组件”与“光伏板”是同义词,“光伏板”会产生“热斑”,这样通过跳转可以将“光伏组件”与“热斑”相联系,这提高了在实际使用中的容错性能。因此,本文构建的分布式光伏图谱化知识库对于智慧运维应用场景具有实践意义。
6 结束语
随着近年来分布式光伏产业的发展,该行业对于智慧运维的需求也随之增长。因此,构建一种面向智慧运维的分布式光伏知识库,在提升运维工作的智能化程度、标准化规范化运维流程、降低从业人员门槛等方面都具有重要作用。本文从实体提取和实体关系提取两方面出发,改良了分布式光伏知识库构建流程。该流程减小了对标注样本的依赖,缓解了传统专业知识库构建方式耗时耗力的问题,填补了分布式光伏智能运维系统中缺乏特定知识库的空白,准确性也得到了一定提升。但这套流程仍有不足,通常来说实体提取还应有“实体发现”的步骤,但受限于样本数据,难以有较好的效果,遂使用光伏术语词表作为替代。实体提取和关系提取这两部分的输入都受限于中文分词工具的性能,难以有效发现一些较长的词(如“离网发电系统”),从而不可避免地发生了错误率叠加的现象,然而类似长度的词在专业领域术语中比较常见。因此,对于该流程,未来还有许多可以改进的方面,如实体提取中调整模型,减少对分词工具的依赖;目前的实体提取模型还是从比较简单的单层CNN模型改进而来,未来可以应用深度学习和强化学习手段,更好地利用词向量等文本特征,提升模型效果。
猜你喜欢
中国交通信息化(2019年5期)2019-08-30
制造技术与机床(2019年6期)2019-06-25
能源(2018年8期)2018-09-21
能源(2017年10期)2017-12-20
能源(2017年11期)2017-12-13
能源(2017年5期)2017-07-06
中国交通信息化(2016年9期)2016-06-06
现代工业经济和信息化(2016年8期)2016-05-17
雷达与对抗(2015年3期)2015-12-09
图书馆研究(2015年5期)2015-12-07
