
迁移蚁群强化学习算法及其在矩形排样中的应用
2021-01-14 01:49徐小斐饶运清孟荣华
计算机集成制造系统 2020年12期
徐小斐,陈 婧,饶运清,孟荣华,4+,袁 博,罗 强
(1.华中科技大学 机械科学与工程学院,湖北 武汉 430074;2.贵州交通职业技术学院 汽车工程系,贵州 贵阳 550008;3.武汉理工大学 机电工程学院,湖北 武汉 430074;4.三峡大学 机械与动力学院,湖北 宜昌 443002)
0 引言
矩形排样是二维优化下料问题的分支,指按照最优方案在矩形板材上排放不同尺寸规格的矩形零件,同时实现板材利用率最大。矩形排样广泛存在于钢板下料、玻璃切割、家具切割、皮革制造等行业中,可以帮助企业提高材料利用率,节约生产成本,也体现了“绿色制造”的理念,二维异形件也可以通过矩形包络转化成矩形排样问题,因此该问题具有很高的研究与实用价值。矩形排样是典型的NP-Hard问题,时间复杂度随零件规模增加呈指数式“爆炸”增长。将经典启发式定位算法如最低水平线法[1]、BL(bottom-left)算法[2]、剩余矩形匹配算法[3]与启发式智能搜索算法如遗传算法[4](Genetic Algorithm, GA)、蚁群算法[5](Ant Colony Optimization, ACO)、粒子群算法[6]等结合解决矩形排样问题已逐渐成为研究的热点,但仍存在着求解时间过、利用率偏低的问题。
蚁群强化学习算法将蚁群算法与强化学习中的Q-learning算法相融合,该算法不仅继承了蚁群算法强鲁棒性、并行性和正反馈的优点[7],还兼并了强化学习中权衡探索(exploration)与利用(exploition)的特点[8]。文献[9-10]在故障模型和网格资源分配问题中引入了强化学习和蚁群算法,文中首先使用Sarsa算法初始化各节点信息素资源分配,再借助蚁群算法进一步寻优。但两篇文献都是将强化学习作为信息初始化算法,没有借助强化学习的优势提高单只蚂蚁的寻优能力,容易陷入局部最优。文献[11]使用蚁群算法协调多机器人运行,同时用强化学习算法提高单机器人定位跟踪能力。该算法提高了单只蚂蚁的寻优能力,但在求解任务时只关注任务本身,任务之间彼此孤立寻优,求解优化相似新任务时不能有效利用已有的经验和知识,需重新开始搜索优化,从而导致效率低下。
在实际生产中,由于同类产品采取批次轮番生产的方式且同系列内的产品常采取变形设计,因此批量生产模式下前后排样任务的待下料零件有一定的重复性。为提高排样效率与优化效果,新排样任务在线寻优时应借助以前的排样经验和知识。机器学习中的知识迁移[12](Knowledge Transfer,KT)具有模拟人类思维的特点,旨在根据任务之间的相似性,利用已有知识和经验,帮助新相似任务减少学习时间,提高寻优性能。在实际工程问题中,文献[13]通过贝叶斯理论计算源任务与目标任务的相似度,从中筛选合适的样本迁移,但当任务规模增大时,需要耗费大量的时间计算相似度与筛选合适迁移样本;文献[14-16]分别将知识迁移引入到电力系统的无功优化、风险调度、多能源联合优化调度问题中,将Q-learning与群智能算法结合构造试错学习模式,通过状态—组合链实现大规模任务降维,并借助知识迁移技术实现智能群体的迁移学习。该算法适用于大规模电力系统问题快速求解,但目前尚未有将知识迁移应用于矩形排样方面的研究。
因此,本文将蚁群算法与强化学习中的Q-learning算法相结合,同时引入知识迁移技术,提出基于知识迁移的蚁群强化学习算法(Knowledge Transfer Ants Q-learning algorithm, KTAQ),以解决矩形优化排样问题。为验证本文所提KTAQ算法的有效性,对不同规模的矩形排样问题进行了仿真验证,并与其他传统智能算法对比,结果证明本文所提算法能够有效求解大中规模矩形排样问题。
1 矩形排样数学模型
由于生产工艺的要求和加工条件的限制,不同领域的优化下料问题对应不同的数学模型[17-18]。本文所研究的矩形排样问题为二维矩形件带排样问题(Two-dimensional Rectangular Strip Packing Problem, 2DRSP)。2DRSP可描述为:一组数量为n的待排矩形零件R1,R2,…,Rn,宽高一定,矩形之间有强互异性(strong heterogeneous)[19]。设第i个矩形的宽为wi,高为hi,则矩形Ri可表示为(wi,hi)(i=1,2,…,n);设矩形板材的宽为W,高度不限。2DRSP的目标是将n个小矩形排放到高度不限的矩形板材中,使板材利用率最大。2DRSP问题要满足以下约束条件:①矩形零件不超出板材边界;②任意矩形零件之间不相互重叠;③矩形零件允许90度旋转;④矩形零件的边需与板材边界平行。如图1所示为10个矩形排样的实例,灰色部分表示不能利用的空洞。

Hmax表示矩形零件排放完成之后最高轮廓线所对应的板材高度。2DRSP的目标是使板材利用率最大化,即使板材高度Hmax最小,适应度函数如式(1)所示:
(1)
且要满足约束:
s.t.
∀Ri:0≤xi≤W,0≤xi+yi≤W,yi>0
∀Ri和Rj,且i≠j:xi≤xj≤xi+wi与
yi≤yj≤yi+hi不同时成立。
(2)
其中式(2)保证矩形零件排放后不超出板材边界和零件之间互相不重叠。
本文采用十进制编码方式,将一个不重复的十进制整数作为矩形零件的唯一标识码,一个完整的整数序列即对应一个可行的排样方案。求解矩形优化排样问题的关键在于零件的定序和定位算法。定序算法是搜索一组最优的矩形排样顺序,目标是调用定位算法解码后的板材利用率最大;定位算法是对搜索到的序列进行解码,由算法中的定位规则确定零件在板材中的具体排放位置,由此生成排样图,并计算板材利用率即适应度值。本文采用KTAQ算法搜索零件排入序列,用基于匹配度评价的最低水平线法进行零件定位,将矩形零件排入板材最低轮廓线。
2 KTAQ算法原理
KTAQ算法主要分为预学习、知识迁移和迁移学习3个阶段。预学习阶段主要是学习源任务,以积累经验知识;知识迁移阶段是挖掘目标任务与源任务的相似性,并从相似源任务中迁移合适的经验策略;迁移学习阶段将迁移知识作为初始动作策略,加速目标任务在线学习寻优过程。其中预学习和迁移学习虽知识初始化和具体参数设置不同,但都有相同的学习模式。下面具体阐述KTAQ算法学习模式和迁移模式。
2.1 KTAQ算法蚁群学习模式
2.1.1 知识获取方式
传统蚁群算法中蚂蚁完全依赖概率对解空间进行搜索,凭借蚁群的分布式搜索得到最优解[20]。而强化学习中的智能体学习如何基于环境而行动,靠反复“试错”达到学习目的,学习的是当前状态下应采取的动作策略[8]。因此,KTAQ算法中基于Q-learning的蚁群强化学习算法与传统的蚁群搜索算法有较大的差异。
KTAQ算法中蚁群是有自学习能力的智能体,能不断改善自身行为,其学习模式如图2所示。蚂蚁总是处于某种环境状态中,蚁群根据状态从知识空间获取知识,并制定动作策略对环境进行试错学习。一旦蚂蚁做了某种动作选择,状态就随之改变,在完整的动作序列执行完毕后,反馈以奖励形式给出,用以更新空间中原有知识。蚁群反复试错学习,直至获得最大化长期总收益对应的动作策略。在Q-learning中,知识空间内的元素表示智能体在不同状态下选择不同动作的Q值,为智能体制定动作策略提供依据[21]。

2.1.2 知识空间分解降维
在Q-learning中,知识空间以lookup表形式呈现,设状态集和动作集分别为S和A,则lookup表的大小为S×A={(s,a)|s∈S,a∈A}中元素的个数。当任务规模增大时,表中元素个数呈指数式“爆炸”增长,发生高维空间常遇到的“维数灾难”,使计算时间大大增加。
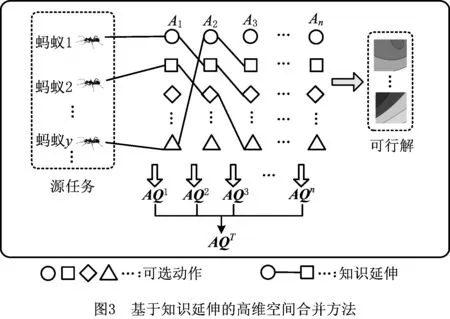
本文将AQ空间定义为KTAQ算法的知识空间。空间元素AQ(s,a)值即为当前状态(s)与动作(a)下的经验知识,简称为AQ值,其值越大,表示经验中此状态动作联系越紧密,选择该动作的评价也越高。在矩形排样中,每个矩形既可以作为“当前状态”,也可以作为“待选动作”。针对大规模矩形排样问题出现的“维数灾难”,受文献[14]对高维动作状态空间分解的启发,本文提出一种基于知识延伸的高维空间合并方法,如图3所示。假设任务有n个变量,每个变量的可选动作集为Ai(i=1,…,n)。将AQ空间划分为n个二维小矩阵AQi(i=1,…,n),相邻变量间根据AQi中储存的知识来联系。变量i的动作即为变量i+1的状态,由此形成基于知识的链式延伸。对于矩形排样等组合优化问题,每个变量的“状态”和“动作”都是从待排零件中选择,因此每个小矩阵AQi的状态集和动作集都相同。为避免矩阵过于稀疏,将所有小矩阵的知识都集中到一个二维矩阵AQT中,依靠该矩阵完成所有步骤中知识的更新与利用,该二维知识矩阵的横纵坐标分别为状态集和动作集。
2.1.3 知识更新策略
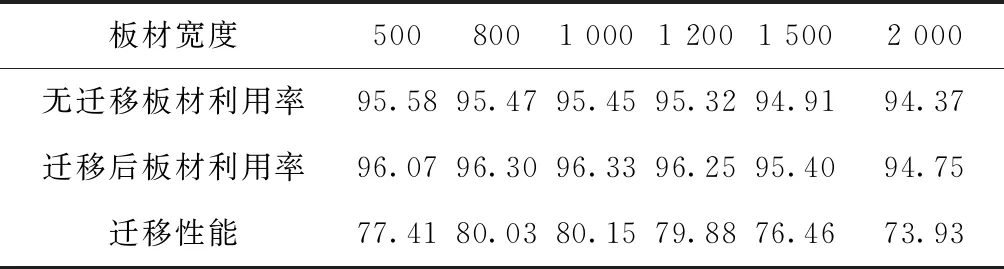
KTAQ算法中所有蚂蚁都根据初始矩阵对食物环境进行试错学习,并将环境奖励反馈给知识矩阵。单次迭代循环内,当蚂蚁完成一条完整路径的构造(即产生一个可行的排样序列),为加深对优秀解邻域的探讨,同时避免知识的学习进入停滞阶段,本文设计局部调整算子对已生成的排样序列进行调整,过程如下:设蚂蚁数量为m,计算每只蚂蚁对应序列的适应度并将其从高到低排列,取排名前m/2的序列进行局部调整。设R={R1,R2,…,Rn}为矩形零件排入板材的一种顺序,在序列中任意取两个不重复矩形,按e(e∈(0,1))值决定是否交换。随机生成(0,1)之间的数r,若r (3) 式中:kiter为当前迭代次数;kiter_max为最大迭代次数;μmin和μmax为经验因子,大量实验表明,取0.5和0.9时可取得最佳仿真结果。每个序列重复上述交换操作s次,计算新序列的适应度,若交换后新序列的适应度高于原序列,则保留新序列,否则不改变。 与Q-learning中只有单智能体学习试错的模式不同,KTAQ算法中多智能体蚁群共同试错学习,全部蚂蚁共有一个AQ知识矩阵,大大加快了学习寻优的速度[22]。每次试错学习后,KTAQ算法会对本次迭代内序列适应度值最高的蚂蚁进行奖励,并更新知识矩阵。其他序列对应的知识只执行挥发操作。矩阵元素更新操作如式(4)所示: AQ(s,a)=AQ(s,a)+α[R+ (4) 式中;α为学习因子;γ为折扣因子;s′为状态s下选择动作a之后的状态;z为s′状态下可选的动作;R为选择动作a后获得的奖励函数值,表示期待学习优化的方向,但当执行挥发操作时,R值为0,表示不对该序列路径进行奖励。本文为知识矩阵中每一个元素AQ(s,a)设置上下阈值,使值的大小控制在[AQmin,AQmax]范围内,避免学习陷入停滞。 2.1.4 动作选择策略 蚁群在探索完整的序列时,每一步都面临如何选择下一步动作的问题,即要选择路径上的下一个矩形。与ACO算法完全依赖概率选择路径不同,KTAQ算法需要博弈“利用”和“探索”两种动作选择模式。侧重知识利用时可以加快学习速度,但会造成知识的不准确,极易陷入局部最优;侧重随机探索时会加大全局搜索,有更高的概率收敛到最优解,但对知识的利用程度较低且寻优速度极慢。为权衡知识的利用和探索,本文选用知识经验和随机选择结合的ε-greedy策略进行动作选择,如式(5)所示: a= (5) 式中:ε∈[0,1],且为均匀分布的随机数;ε0为按照知识经验选择动作的参数,ε0∈(0,1);u表示状态s下的可选动作集合A(s)中某一动作;δ和β分别表示经验知识AQ值和启发知识HE值对蚂蚁下一步动作选择的重要程度。 随着矩形零件逐渐排入板材中,水平线被分割,会产生众多零碎的水平线段,此时若没有合适的矩形零件排入就会产生空隙,导致板材的浪费。若将小零件靠后排放,就可以填补这些零碎的空隙。由于长宽比相差较大的矩形零件对空间的排放要求更高,因此也需优先排放这些零件。受此启发,基于板材利用率最大,启发知识HE值设置要优先考虑零件面积和长宽比,设lu和su表示零件u的长边和短边,启发知识设置如式(6)所示: (6) 式中Wa和Wr分别表示零件面积和长宽比在启发信息中所占权重。 式(5)表明,当随机数ε≤ε0时,蚂蚁受经验知识和和启发知识的指导来选择下一个动作;否则,按照S式进行随机概率探索,如式(7)所示: (7) 蚂蚁每次动作选择前都要进行判断,使智能体既可以利用知识矩阵中的先验知识,也可以进行新的探索,这样不仅加深了对优秀解的探索能力,还能使算法有较强的全局搜索能力,避免陷入局部最优。 传统强化学习所获得的经验知识与特定的任务相关,任务之间是孤立的。而迁移学习能将以往任务的经验和知识迁移到相似任务中,以减少新任务学习时间,因此近年来在强化学习中有着广泛地应用[23]。如果新旧任务相似,则状态集合和动作集合有很大的重叠和相似情况,可以将源任务学到的最优知识矩阵通过一定的方式迁移给目标任务作为其初始知识矩阵,通过这种方式实现知识的迁移和再利用。 在用迁移知识解决目标任务之前,KTAQ算法需要对一系列源任务Si(i=1,…,p)进行预学习以储备知识,如图4所示。将相似源任务Si的知识矩阵AQSi通过线性迁移策略迁移给目标任务T,作为其初始知识矩阵AQT,以便目标任务利用知识进行快速高效的在线学习。 源任务与目标任务存在一定的相似性,但迁移过程中不可避免地会产生负迁移(negative transfer)现象[24]。知识矩阵中存在着一些无价值、无关联的知识,若不加以分辨并剔除则会使迁移后的寻优性能变差。为此,要对新旧任务之间的相似性进行深入挖掘,提取有效知识。后文将针对矩形优化排样问题展开相似性以及具体迁移策略的分析。 图5对KTAQ算法的3个阶段做了详细描述。选定有代表性的任务为源任务,在预学习阶段对其寻优求解,积累学习经验,并将其最优知识矩阵存储到知识库;在线性知识迁移阶段,根据目标任务的特点选取相似源任务,对其最优知识矩阵线性组合并迁移到目标任务中;第3阶段为迁移学习阶段,将上阶段整理得到的知识经验作为目标任务的初始化动作策略,以便加速目标任务在线学习过程。算法结束的条件为迭代次数kiter>kiter_max或‖AQk-AQk-1‖<σ(σ∈R+且取较小值),σ为AQ矩阵收敛判定系数。 用KTAQ算法求解矩形排样时,选择一个动作表示从剩余矩形零件中挑选一个矩形加入到排样序列,当前选择的“动作矩形”即为下一步动作选择时的“状态矩形”。因此,本文知识空间中的状态动作都由当前任务的矩形零件构成。每两个不重复矩形Rs和Ra都对应知识矩阵中的元素AQ(Rs,Ra),其值表示经验中当前两个矩形的密切程度,可作为矩形排样序列构建时动作选择的知识依据。 式(1)给出的模型目标函数是追求板材利用率最大,即最高轮廓线对应的板材高度最小,而KTAQ算法式(4)的奖励函数R表示期待优化的方向,因此更小的板材高度代表着更优的学习效果,设置环境奖励函数如式(8): (8) 式中:ER为环境奖励系数,hib表示当前迭代最优的蚂蚁对应的板材高度。若最优蚂蚁不经过(Rs,Ra),R值为0,表示不对此序列路径进行奖励。 KTAQ算法可学习得到一个完整的矩形排样序列,代表零件依次排入板材的顺序。本文提出基于匹配度评价的最低水平线法对序列进行解码,以确定零件在板材中的具体排放位置,生成排样图并计算板材利用率。零件排入板材过程中,出现的最低轮廓线为最低水平线Llow,若出现多段,则取最左一段。大部分文献将矩形排入最低水平线时只考虑到矩形的宽度和水平线长度的匹配程度[25-26],而较少有文献考虑高度方向上的匹配度,致使板材利用率不高。 本文提出基于匹配度评价的最低水平线法,考虑矩形零件的宽高尺寸,依据评价值灵活的选择排入最低水平线的矩形件,实现对板材空隙的充分利用。以矩形排入最低水平线后的对齐情况作为匹配度评价值,如表1所示。其中浅色部分表示已排入板材的零件,深色部分为待排入零件。 表1 匹配度规则评价表 具体排样步骤如下: 步骤1初始化水平轮廓线集合为板材的底边,同时也为最低水平线。 步骤2当要排入零件Ri时,从当前水平轮廓线集合中选取最低的一段作为最低水平线,在排样序列中从矩形Ri向后搜索,对后续每个矩形及其旋转后的情况按匹配度规则进行评价,选取匹配度最高的矩形排入最低水平线,若有多个,则取最靠前的矩形;若所有待排矩形的匹配度值都为0,则提升最低水平线至与其相邻且高度较低的一段平齐。更新轮廓线集合。 步骤3重复步骤2,直至所有矩形都排入板材中。 KTAQ算法迁移效果优劣的关键在于是否将合适的知识迁移到目标任务中。在矩形排样中,相似任务的排样结果往往有相同或相似的规律。排样任务的相似程度主要取决于零件的组成情况,本文采用矩形重叠率作为衡量标准,它能够反映源任务与目标任务相似的程度,其值越大,相似程度越大,其计算如式(9)所示: (9) 式中:nSi表示源任务Si与目标任务T中矩形件重叠的数目,n为T中矩形零件的数目。目标任务T进行快速学习需要的是描述矩形与矩形间密切程度的知识,而与其矩形重叠率高的源任务正可以提供较多的知识供其学习。 为了充分利用源任务的知识,同时尽量避免负迁移现象的产生,迁移策略的设计本着相似度越高、迁移贡献率越大的原则,从源任务中选择相似度最大的两个任务进行知识迁移。由Ω1和Ω2归一化处理得两个源任务的迁移贡献系数λ1和λ2,使λ1+λ2=1,则目标任务T的知识矩阵元素值为式(10)所示: (10) 综上所述,具体的迁移过程如下:①选取若干典型源任务进行学习,以获得储备知识;②选取与目标任务T最为相似的两个源任务,将其与T的矩形重叠率Ω1和Ω2归一化处理,得到迁移贡献系数λ1、λ2;③初始化目标任务T中的知识矩阵,按上述迁移规则进行知识迁移;④T利用知识矩阵策略进行快速在线学习寻优。 在KTAQ算法中,对学习和寻优效果影响较大的参数主要有蚁群规模m、学习因子α、折扣因子γ、知识经验参数ε0、环境奖励系数ER。经过多次仿真实验,发现各参数对寻优结果的影响如下: (1)蚁群规模m参与学习的蚂蚁智能体数量,m值越大,搜索到最优解的可能性越大,但需要耗费大量计算时间。经多次试验仿真,将预学习阶段和迁移学习阶段的蚂蚁数量分别设置为150和50。 (2)学习因子α蚁群从食物环境中学习的速度,α∈(0,1),α值越大表示学习越快,但极易陷入局部最优。本文预学习和迁移学习阶段分别设置为0.5和0.3。 (3)折扣因子γ对历史奖励值的折扣程度,γ值越大,表示对当前奖励越重视,本文两个阶段都取值0.9。 (4)知识经验参数ε0表示蚁群利用经验知识和随机探索之间的权衡。当目标任务已获得初始的经验策略时,可适当增大ε0,以提高寻优的速度。因此预学习和迁移学习阶段分别取值0.75和0.9。 (5)环境奖励系数ER代表环境对最优解的奖励。本文统一设置ER为500。 从目前已发表文献来看,国内外缺乏将知识迁移应用于矩形排样领域中的研究,因此并没有标准算例来对本文提出的算法进行效果对比。为验证本文所提算法的有效性,对现今国际通用的矩形排样标准算例加以修改,进而保证源任务和目标任务的相似性,用改进的几组算例来对本文算法进行测试,使之能适应迁移策略的展开。仿真算例均在CPU为Intel(R) Core(TM) i3-2100、主频率为3.10 GHz、内存为8 GB的计算机上运行,算法基于Windows平台并采用C++语言编程实现。为消除随机因素的影响,结果均10次独立运算后取平均值。 本实验采用NICE测试集中的nice5问题进行矩形优化排样问题研究。为保证任务之间的相似性,便于迁移动作的展开,本文中的源任务和目标任务均从nice5中的500个矩形零件中随机选取375个零件进行优化排样。现由系统随机生成3个源任务S1、S2、S3和目标任务T,S1、S2、S3与T的矩形重叠率分别为80%、73%、67%。 首先,为证明矩形重叠率越高,知识被利用的程度越高,从而迁移效果越好,进行单源迁移实验。单源迁移即为从单个源任务中获取知识,并将其迁移到目标任务中。如图6所示为从各源任务迁移的KTSk算法和无迁移的标准蚁群ACO算法的排样高度收敛情况。 由图6可以发现,ACO在初期搜寻和后期收敛阶段的寻优性能均劣于其他3种算法,并且陷入了局部最优。这是由于目标任务缺乏经验知识,只得在与环境不断交互中为自己积累经验,因此排样寻优效果较差。同时可以看出,源任务与目标任务的矩形重叠率越高,算法的求解效果越好,重叠率为80%的源任务S1的迁移性能最优。这是由于任务越相似,可提供给目标任务借鉴的经验越多,迁移知识被利用的程度越高,因而减少了目标任务在线寻优的盲目性。因此,为提高迁移性能,应尽可能选择重叠率高的源任务进行知识迁移。 二维矩形件带排样问题的特点是板材宽度确定、高度不限,本文选定板材宽度作为板材型号划分依据。上述单源迁移实验中,源任务与目标任务所使用板材型号相同。但在实际生产中,板材型号不止一种,前后排样任务可能存在零件相似、板材型号不同的情况,迁移效果可能有所差异。为验证板材相似度对迁移效果的影响,以上述单源迁移实验中板材宽度为1 000的S1为源任务,对不同板材宽度的目标任务T的迁移效果做对比分析。由于板材宽度不同,无法直接从排样高度或利用率的角度来衡量不同型号板材的迁移效果,为更准确地描述迁移结果的优劣,现对迁移性能TQi作定量描述[13],如式(11)所示: (11) 式中:ANT表示无迁移的ACO算法的排样高度收敛曲线与x轴所围成的面积,Ai表示各板材型号的排样高度收敛曲线与x轴所围成的面积,A0为其他智能算法所求得的最优排样高度y=h0与x轴所围成的面积,可得各型号板材的迁移效果如表2所示。 表2 不同型号板材迁移效果对比 % 由表2可以看出,同种型号迁移后的板材利用率明显优于迁移之前,从而表明了知识迁移的有效性。同时可以看出,宽度为1 000的目标任务板材利用率最高,迁移性能也最好,这是由于源任务S1的板材型号也为1 000,源任务的经验可以较多地被目标任务所借鉴,帮助其提高在线寻优能力。比较其他型号的迁移效果,发现目标任务与源任务的板材宽度差异越大,迁移效果越不明显,板材利用率也会有所下降,但仍高于无迁移的板材利用率,这是由于板材宽度差异较大,目标任务只能从源任务中借鉴少部分的经验知识。因此,目标任务在套料时,要尽可能选择与源任务相同或宽度差异较小的板材,以更有效地利用迁移知识。但在实际生产中,二维矩形件带排样问题多用于卷材下料问题,卷材的宽度型号有限,前后相似任务大都会使用同种型号的板材下料,因此为更有效地验证知识迁移效果,使其在生产中得以应用,下述双源迁移等实验中,源任务与目标任务板材型号仍相同。 为验证本文所提双源迁移设计的有效性,现进行双源迁移实验。单源迁移实验已证明迁移效果与矩形重叠率有关,只需比较重叠率最高和最低的源任务组合即可。现选取重叠率较高的S1、S2形成迁移算法KTS12,取重叠率较低的S3和S2形成迁移算法KTS23,并将迁移结果与无迁移的ACO算法以及单源迁移最优算法KTS1进行比较,如图7所示。 为更准确地描述迁移结果的优劣,现对迁移性能TQi作定量描述,借助式(11)求解迁移性能。其中,Ai表示图7各迁移算法的收敛曲线与x轴所围成的面积,其余字母含义不变。求得迁移性能如表3所示。 表3 迁移性能对比 由图7可以看出,无论是单源还是双源迁移,其收敛速度与结果明显优于ACO算法,证明了知识迁移的有效性。虽然在迭代初期,单源迁移KTS1的收敛速度快于双源迁移KTS23,但在收敛阶段,KTS23结果优于KTS1。结合表3可看出,双源迁移的性能都达到90%以上,明显高于单源最优迁移结果的性能80.15%。多源迁移为目标任务的在线学习提供了更全面有效的知识,但为了减少无用知识的干扰,降低迁移难度,无需进行三源等多源迁移实验,两源知识足以为目标任务的优化提供充足的经验。观察图表可以看出,两个源任务与目标任务的矩形重叠率越高,迁移性能越好,KTS12的迁移性能达到了99.34%。因此,在选择迁移的知识时,要选择更有迁移价值的两个源任务,以便获得较优的迁移结果。知识迁移前后效果如图8所示,深色部分表示板材中没有被利用的空洞。可以看出知识迁移后,空洞部分明显减少,板材使用高度由776降低到765,提高了板材利用率,也证明了本文提出的KTAQ算法的有效性。 为验证本文算法的有效性,现采用不同规模的算例对双源知识迁移算法进行测试。与实验1相同,测试中源任务和目标任务均从相应算例中随机选取总零件数量的3/4,以保证任务之间的相似性。设置两个源任务与目标任务的相似度分别为70%和80%。测试算例均从标准算例C21、CX、NICE、N13测试集中选取,经过整理得到相应的源任务和目标任务。 遗传算法和狼群算法作为经典和新兴智能算法的代表,在求解组合优化问题上获得了广泛的应用,同时在矩形优化排样问题上也展现出优异的性能。为验证KTAQ算法的有效性,现将基于复合因子评价的遗传算法[27]、十进制狼群算法[28](Wolf Pack Algorithm,WPA)和ACO算法求解目标任务的结果与本文KTAQ相比较。各算法优化结果如表4所示,表中h表示排样高度、t表示计算时间(单位:s)加粗字体表示每个算例的最优计算结果,所有结果均取整。 表4 算例优化结果对比 从表4可以看出,对于小规模算例C61和Nice3,KTAQ算法结果稍劣于其他3种算法,分析认为,源任务不可能为目标任务提供其所需要的全部知识,目标任务仍需要根据任务特点学习新知识,并不断做出权衡,将迁移知识和新知识融合,这个过程反而阻碍了小规模问题快速收敛,使迁移优势不明显。与ACO算法相比,从第3个算例起,随着零件数目的增加,计算时间急剧增长,KTAQ算法的迁移优势便逐渐突显出来。除了N11算例求得的排样高度相等以外,KTAQ算法求得的排样高度均明显优于ACO算法,求解速度基本是ACO的2~6倍,呈现出良好的优化性能。这是由于ACO缺乏迁移知识,只能与环境在线交互积累经验,而KTAQ算法在寻优过程中得到了相似任务经验知识的指导,因此寻优性能大大提高。与智能算法GA、WPA相比,当排样任务为大中规模时(零件数量达到100以上),除算例1 000外,KTAQ算法求解到的排样高度整体上优于前两个算法。在算例1 000中,KTAQ算法也有寻得GA算法中最优解的能力,但其平均排样高度稍逊于GA算法,因此算法的寻优稳定性还有改进的空间。从求解速度上来看,KTAQ算法的速度基本上能达到GA、WPA算法的2~6倍,能满足大中规模零件快速寻优的要求。 上述算例中KTAQ算法板材的利用率都能达到96%以上,具有较好的实用性。整体来说,KTAQ算法在保证较高质量解的同时,寻优时间大幅缩减,证明了本文提出的基于知识迁移的蚁群强化学习算法的有效性。 本文将知识迁移引入到基于强化学习的蚁群算法中,提出了KTAQ算法,并将其应用到矩形优化排样中。在大中规模矩形优化排样问题上,该算法能在获得高质量解的基础上,求解速度达到普通智能算法的2~6倍,可以有效降低求解时间,提高寻优性能。本文的创新点可归纳如下: (1)借鉴Q-learning的试错学习模式构造具有自学习能力的蚂蚁群体,并建立基于局部调整算子的知识更新策略和知识利用探索权衡的动作选择策略,加速蚁群知识空间的形成,并在此基础上实现知识的学习、迁移和再利用。 (2)针对矩形排样问题知识空间出现的“维数爆炸”情况,提出基于知识延伸的高维空间合并方法,极大地降低了计算难度,使之更适应大规模矩形排样问题求解。 (3)提出基于匹配度评价的最低水平线法,结合动作选择策略中的优先考虑排入零件面积及长宽比较大的矩形,使矩形排入板材时充分利用了板材空隙,提高了板材利用率。 (4)提出双源线性迁移策略,对最相似的两个源任务用线性组合的方式迁移知识,仿真实验也对提出的双源线性迁移策略的有效性进行了验证。 此外,在迁移寻优过程中,求解的稳定性还可以进一步提高;仍需要对迁移算法进行改进,使之适宜求解有复杂约束的矩形排样问题。同时,将知识迁移、强化学习与智能算法相结合,用于求解旅行商、车间调度等其他组合优化问题,也是笔者下一步研究的重点。
2.2 KTAQ知识迁移方式

2.3 KTAQ算法流程

3 矩形排样求解
3.1 状态动作与奖励函数设计
3.2 基于值评价的最低水平线法

3.3 迁移设计


3.4 参数设置
4 仿真实验
4.1 实验1

4.2 实验2



4.3 实验3

5 结束语
猜你喜欢
石材(2022年1期)2022-05-23
数学年刊A辑(中文版)(2020年2期)2020-07-25
中国设备工程(2020年3期)2020-03-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国有色金属学报(2018年2期)2018-03-26
浙江工业大学学报(2017年5期)2018-01-22
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
重型机械(2016年1期)2016-03-01
印制电路信息(2015年6期)2015-12-30
西安工业大学学报(2015年4期)2015-12-26
