
基于深度学习的连续手语语句识别算法
2021-01-19 02:24黄元元胡作进
计算机技术与发展 2021年1期
李 晨,黄元元,胡作进
(1.南京航空航天大学 计算机科学与技术学院,江苏 南京 211106; 2.南京特殊教育师范学院 数学与信息科学学院,江苏 南京 210038)
0 引 言
在当今的人机交互技术中,手势是输入信息的一种媒介。作为特殊的手势类别,手语是聋哑人的重要交际工具。因此,研究手语识别不仅可以促进人机交互技术的发展,还可以促进聋哑人和健全人之间的交流。
1 相关工作
连续手语语句是由手语词和连接手语词的过渡动作组成[1]。由于手语动作的连贯性,从手语语句中分割出手语词变得极其困难,因此如何准确地检测手语词边界是连续手语语句识别的最大挑战。
在国内,张继海等[2]将手语语句进行首轮粗分割后得到的多个片段送入手语词的隐马尔可夫模型(hidden Markov model,HMM)中,并借助阈值矩阵和动态时间规整算法(dynamic time warping, DTW)确定出可能的候选词及它们的结束帧,再根据比率阈值进一步确定本轮粗分割的最优候选词,并以其结束帧的下一帧为起点,继续进行下一轮的粗分割……最后将得到的多个最优候选词按照先后顺序串联起来,即可获得语句的识别结果。该算法在包含34个词汇的手语语句库中取得77.8%的识别率,但由于它在确定候选词的结束帧时采用逐帧遍历的方法,因此运行效率较低。杨文文等[3]采用基于HMM的逐层构筑算法,同时辅以手语词帧长的约束和n元语法模型,最终在由21个词汇组成的20个手语语句上取得12.2%的错误率。然而该算法中语句的平均识别时间超过8秒,显然无法实现手语语句的实时识别。徐鑫鑫等[4]根据点密度提取手语的关键帧序列,然后利用若干连续关键帧的权值之和对关键帧序列进行分割和识别,从而获得手语语句的识别结果。该算法的运行效率较高,但如果大权值的关键帧出现漏检或者误识,将无法识别出正确的手语词边界。
在国外,Yang等[5]利用基于条件随机场(conditional random field,CRF)的阈值模型判断语句中各帧是手语词还是过渡动作,然后利用CRF对分割后的手语词进行识别,最终在由48个词汇组成的美国手语语句库中取得87%的识别率。由于非特定人群手语数据的差异性较大,所以阈值模型在实际应用时手语词边界的检测效果并不理想。Cui等[6]通过卷积神经网络(convolutional neural networks,CNN)提取每帧图像的空间特征,再通过叠加的时间卷积层和时间池化层提取各手语片段的空间-时间特征,并将其送入双向的长短期记忆网络(long short-term memory,LSTM)中建模,最后采用连接时序分类(connectionist temporal classification,CTC)算法作为整个架构的目标函数。在2012年的德国天气预报手语库中,该算法的错误率为38.7%。由于手语片段的类别概率分布大多较分散,所以采用波束搜索法进行CTC解码时,可能剔除部分片段的正确类别,进而影响手语词边界的准确性。Koller等[7]先利用CNN计算出每帧图像的隐状态类别概率分布向量,再通过Viterbi算法、一阶隐马尔可夫过程及n元语法模型求解手语语句的最优词汇序列,最终在2012年的德国天气预报手语库上取得32%的错误率。由于该算法在寻找手语词边界时需要对三个超参数进行网格搜索,因此算法的时间损耗较高。
目前,大多数的手语词边界检测算法对非特定人群没有很好的鲁棒性,这在一定程度上影响了手语语句的识别效果。
2 算法步骤
该文利用轨迹归一化算法提取手语词的轨迹特征,同时利用卷积神经网络提取手语词的手型特征,并在此基础上训练基于长短期记忆网络的手语词分类器。对于一个待识别的手语语句,该文采用基于轨迹信息的分割算法检测过渡动作。由过渡动作将语句分割为多个片段后,考虑到过渡动作可能是手语词内部的动作,所以将若干片段拼接成复合段,并对所有复合段运用手语词识别算法进行分类,然后跨段搜索出目标词汇序列,从而完成手语语句的识别。
2.1 手语数据的获取
该文借助Kinect获取手语者的手心位置和深度图像,并在此基础上获得手语数据。
2.1.1 手型图像的获取
该文将深度图像和手心位置相结合,从而实现手型图像的快速提取[8]。图1为手型图像的提取效果。

图1 手型图像的提取效果
由于获取的手型图像比较粗糙,为了更精确地描述手语动作,在手型图像的基础上,引入了轨迹数据。
2.1.2 轨迹数据的获取
将手语持续时间内、经卡尔曼滤波校正后的手心位置按照先后顺序连接起来,即可获得手心的轨迹。为了进一步地去除噪声,该文对左、右手心轨迹分别应用长度为3的均值滤波进行平滑。平滑后的左、右手心轨迹构成了轨迹数据。
2.2 手语词识别算法
该文录制了47个常用的手语词。在获得这些手语词样本的轨迹特征和手型特征的基础上,开展手语词分类器的训练。
2.2.1 轨迹特征的提取
为了消除手心轨迹的尺度差异、采样点数差异和起始点差异,提出了一种轨迹归一化算法。
假设有一个持续时间为n帧的手语词样本,它的左手心轨迹P={p1,p2,…,pn},其中pi(1≤i≤n)表示第i帧左手心的位置。轨迹P的归一化过程如下:
(1)创建一个长度为50的时间序列Q来存储归一化后的轨迹。
(2)计算轨迹P的尺度缩放因子αs和采样点数缩放因子αn:
αs=1/‖(Neckx,Necky,Neckz)-(SpineMidx,SpineMidy,SpineMidz)‖
(1)
(2)
其中,(Neckx,Necky,Neckz)、(SpineMidx,SpineMidy,SpineMidz)分别表示脖子和脊柱中心的位置。将轨迹P各采样点的手心位置乘上αs可以实现尺度归一化;将轨迹P各采样点的序号乘上αn可以指导采样点数归一化操作。
(3)计算轨迹P的第i(1≤i≤n)个采样点归一化后的下标j:
j=「n*αn」
(3)
其中,「x」表示对x进行四舍五入取整。如果在归一化的轨迹Q中qj未被赋值,则将轨迹P的起始点p1与原点对齐,并将pi尺度归一化后的值赋给qj:
qj=αs*(pi-p1)
(4)
如果qj已被赋值,则将轨迹P的起始点p1与原点对齐,并把尺度归一化后的pi和qj的均值赋给qj:
(5)
(4)遍历轨迹Q,对所有未赋值的qi,采用线性插值法补充数据:
qi=(qi-1+qi+1)/2
(6)
(5)返回归一化的轨迹Q。
对左、右手心轨迹分别进行归一化后,该文使用归一化的左、右手心轨迹共同描述手语的轨迹特征。
2.2.2 手型特征的提取
对MobileNetV2[9]稍加修改后,搭建出如表1所示的卷积神经网络。
这里的conv2d表示标准卷积层,avgPool表示全局池化层。由表1可以看出,该网络由3个标准卷积层、9个bottleneck模块和1个全局池化层组成。该网络的输入为224×224×1的手型图像,经过网络各层的作用后,最后输出61维的手型类别概率分布向量。
当完成卷积神经网络的训练后,移除网络的最后一个标准卷积层,剩余的网络架构可以用作手型特征提取器。因此,输入一张手型图像,该网络可以提取出160维的手型特征;输入一个手语词样本,该网络可以提取出它的手型特征序列,将该序列归一化到50个采样点,即可获得它的手型特征。

表1 卷积神经网络的参数信息
2.2.3 基于长短期记忆网络的手语词分类器
手型特征和轨迹特征共同组成手语词的特征。考虑到手语词的特征是时间序列数据,而长短期记忆网络(LSTM)善于学习时序数据中的关联信息,于是搭建出如表2所示的长短期记忆网络。

表2 长短期记忆网络的参数信息
该网络包含一个双向LSTM层、一个Flatten层以及三个全连接层。网络的输入为手语词的特征,即一个长度为50的时间序列,序列中的每个元素为166维的向量,经过网络各层的作用后,最终输出47维的词汇类别概率分布向量。其中双向LSTM层用于捕捉每个采样点的上下文信息;而Flatten层是把50个采样点的隐状态拼接起来,进而获取整个序列的上下文信息。至于三个全连接层的功能则有点不同,前两个全连接层的作用是实现特征的学习和降维,最后一个全连接层则主要负责分类计算。
2.3 连续手语语句识别算法
对于一个待识别的手语语句,该文先采用分割算法检测过渡动作,然后采用基于过渡动作的手语语句识别算法获取语句的识别结果。
2.3.1 手语语句的分割
鉴于过渡动作的速度相对较快,且方向的偏转角度较小,因此提出了一种基于右手(主导手)轨迹信息的手语语句分割算法,它的详细步骤如下:
(1)初步确定过渡动作。
在图2中,pi-1、pi和pi+1为三个相邻采样点上右手心的位置。第i个采样点的右手心速度vi可以定义为pi和pi+1之间的距离,即:
vi=‖pi+1-pi‖
(7)

图2 三个时间上相邻的采样点
图2中的θi表示第i个采样点上的方向角,它刻画了右手心在时刻i的方向偏转情况,即:

(8)
其中,u1=pi-pi-1,u2=pi+1-pi。针对右手心的速度,设定阈值ρv=(2*avg(v))/3;针对右手心的方向角,设定阈值ρθ=20。其中avg(v)表示所有右手心采样点的速度的均值。当vi≥ρv且θi≤ρθ时,采样点i是过渡帧。因为过渡动作不止一帧,所以该文将距离三帧以内的过渡帧合并到同一个过渡动作中。由该方法确定出的第一个过渡动作位于起始手势和第一个手语词之间,而最后一个过渡动作位于最后一个手语词和终止手势之间,它们均不属于过渡动作,因为它们不是相邻手语词之间的连接动作,该文先剔除最后一个过渡动作,至于第一个过渡动作则暂且保留。
(2)剔除错误的过渡动作。
非特定人群在比划具有语义的关键手势时会降低动作的速度,在轨迹上的表现就是这些手势对应的点密度较大。通过对手语语句样本的观察,发现所有手语词的关键手势的右手心点密度均≥5。而过渡动作位于前一手语词的尾个关键手势和后一手语词的首个关键手势之间,所以该文根据右手心的点密度进一步剔除错误的过渡动作。
假设由步骤(1)获得过渡动作序列T={t1,t2,…,tm},其中m表示过渡动作数量。初始化i=1,接下来采用迭代算法剔除错误的过渡动作:
①若i≥m,考虑到t1不是过渡动作,所以将t1从序列T中剔除,并得到最终的过渡动作序列,否则进入步骤②;
②若ti的终止帧到ti+1的起始帧之间的区间不存在右手心点密度≥5的采样点,则剔除ti+1,并更新序列T和数量m,然后重复该步骤;否则保留ti+1,并令i=i+1,跳转至步骤①继续判断后续的过渡动作。
2.3.2 基于过渡动作的手语语句识别算法
假设对一个手语语句运用上述分割算法检测到T-1个过渡动作,由这些过渡动作可以将手语语句分割为T个片段。因为检测出的词间过渡动作包含下一手语词的部分信息,所以对于任意相邻过渡动作间的手语片段而言,为了尽可能地保留手语词的特征,该文将前个过渡动作的中位点帧设为起始帧,同时为了尽可能地剔除手语词的上下文信息,将后个过渡动作前右手心点密度大于3的帧设为终止帧。
考虑到检测出的过渡动作可能是手语词内部的动作,所以该文将若干个片段拼接在一起形成复合段。因为语句样本中的词汇平均大约包含1.7个手语片段,所以根据片段数T粗略预估语句中的手语词数量N。
N=「T/1.7」
(9)
其中,「x」表示对x进行四舍五入取整。由于语句样本中的手语词至多包含5个片段,为了避免过度的片段拼接给后续识别带来干扰,由式(10)预估手语词的最大片段数β。
β=min(5,「T-(N-1)×1.3」)
(10)
为了进行手语语句的识别,该文需要在线创建类别标签矩阵C和分类概率矩阵S,并将它们的元素初始化为0。对于以片段t的起始帧开始、以片段t'的终止帧结束的复合段,Ct,t',q保存该复合段的候选手语词的类别标签,St,t',q则保存该复合段是手语词Ct,t',q的概率,其中1≤t≤T,t≤t'≤min(t+β-1,T),1≤q≤5。后续的手语语句识别过程如下:
(1)复合段的分类。
首先初始化当前层各复合段的起始帧为片段1的起始帧,并令t=1,接下来开始复合段的分类工作。
①依次截取以片段t的开始帧为起点,以片段t'(t≤t'≤min(t+β-1,T))的结束帧为终点的复合段,并对这些复合段运用手语词识别算法进行分类。如果这些复合段存在概率值≥0.2的类别,则把对应的类别和概率分别存入类别矩阵C和概率矩阵S中;
②令t=t+1,跳转至步骤①,继续对下一层的复合段进行分类。
(2)目标词汇序列的跨段搜索。
定义δ(t,t',q)表示以片段t的起始帧开始、以片段t'的终止帧结束的复合段是手语词Ct,t',q的累积概率,其中1≤t≤T,t≤t'≤min(t+β-1,T),1≤q≤5。令
目标词汇序列的跨段搜索算法如下:
①初始化。
(11)
φ(1,t',q)=NULL
(12)

(13)
②递归。
δ(t,t',q)=
(14)
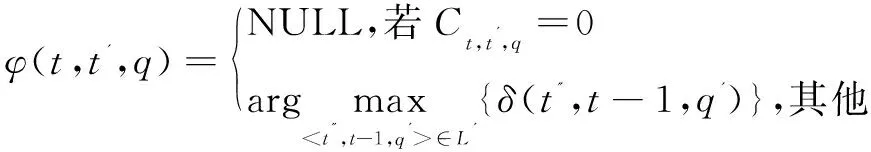
(15)
(16)
其中,L'表示满足P(Ct,t',q|Ct'',t-1,q')≠0且η(t'',t-1,q')
③终止。
(17)
(18)
④路径回溯。


3 实验结果与分析
为了验证手语词识别算法的有效性,邀请6名手语者参与47类手语词的样本录制。此外,以这47个词组成的30条手语语句作为样本进行语句识别实验。共有6名手语者参与语句样本的录制,其中2名是熟练手语者,2名是次熟练手语者,还有2名是不熟练手语者。需注意,参与词汇样本采集的手语者和参与语句样本采集的手语者不重叠。
3.1 卷积神经网络的训练
针对录制的47类手语词的样本,该文使用关键动作提取算法提取关键手型[10],然后采用K均值算法对关键手型进行聚类[11],其中K设为60,由此可以获得60类关键手型的样本。由于手语动作中还存在关键手型之间的过渡手型,所以还需为过渡手型类选取样本。鉴于手型样本数有限,该文采用平移、旋转及缩放变换来扩充样本集。最终每一类手型均有240个样本作为训练集,60个样本作为测试集。
在交叉熵损失函数[12]的基础上,使用随机梯度下降法优化卷积神经网络。设置初始学习率为0.001,最大迭代次数为800。学习率的变化公式如下:
(19)
其中,i为迭代次数,decay=1.0×10-2。为了防止网络出现过拟合,该文对除最后一个标准卷积层外的其他卷积层都进行了批量归一化(batch normalization,BN)处理。其中训练集的batchSize设为50,测试集则无需划分batch,把所有的测试样本一次性送入网络进行识别。采用Keras框架训练该网络,最终训练出的网络模型在测试集上的精度为94.58%。
3.2 长短期记忆网络的训练
该文在每个手语词样本的基础上造了2个样本,它们分别保留了原始样本前14/15和后14/15的采样点。最终每一类手语词的样本总数增加至162,该文随机选取其中的129个样本用作训练集,其余的33个样本则用于测试。
采用交叉熵损失函数测量长短期记忆网络的分类误差。设置学习率的初始值为0.001,最大迭代次数为500。学习率的变化公式如下:
lri=lr0*gamma∧(floor(i/stepsize))
(20)
其中,i表示迭代次数,gamma=0.1,stepsize=200。为了防止网络出现过拟合,该文对双向LSTM层和fc2都进行了BN处理,其中训练集的batchSize设为30,测试集无需划分batch。在GPU上训练该模型,最终训练出的模型在测试集上的精度达98.55%。
考虑到语句中的手语词和孤立手语词的差异较大,所以需要人工标注语句中的词汇,并将其送入长短期记忆网络中训练[13-14]。该文对熟练、次熟练及不熟练的3名手语者的语句样本中的手语词进行标注。每条语句有这3名手语者的27个样本,其中的21个样本用于网络的再训练,剩余的6个样本用于再测试。由于语句中手语词的样本数有限,该文采用窗口规整方法[15]造样本。最终每类手语词用于再训练和再测试的样本数分别为84、24。对长短期记忆网络再训练500次后,网络在测试集上的精度为95.32%。
3.3 连续手语语句的识别
为了验证手语语句识别算法的有效性,与文献[4]以及文献[13]中的算法进行对比。对熟练程度不一的6名手语者的语句样本进行识别。其中手语者一和手语者二能够熟练地表达手语,手语者三和手语者四能够较熟练地表达手语,手语者五和手语者六则无法熟练地表达手语。且手语者一、手语者三和手语者五的部分语句样本参与了长短期记忆网络的训练。运用各算法对上述手语者的语句样本进行分类后,得到的识别准确率和平均识别时间如表3所示。

表3 算法效果对比
(1)文献[4]是基于加权关键帧实现手语语句的识别。该算法的执行效率较高,但是它依赖于大权值的关键帧。对于非熟练的手语者,可能由于动作不够规范导致大权值关键帧的错识概率增高,从而极大地影响语句的识别效果,因此该算法的稳定性较差。
(2)文献[13]采用连接时序分类算法实现手语语句的识别。虽然该算法的运行效率高,但它的识别精度较低,这是因为它需要将手语语句划分成多个等长的片段,而大多数片段的类别概率分布比较分散,所以利用波束搜索法进行解码时,手语片段的真实标签可能被剔除,从而极大地影响了语句的识别效果。
(3)相比较来说,文中算法面向非特定人群的稳定性较高,能够实现手语语句的实时识别。
4 结束语
针对当前手语语句识别算法中存在的问题,提出了一种基于深度学习的手语语句识别算法。它充分利用了卷积神经网络的特征提取能力和长短期记忆网络的时序建模能力,并借助分割算法检测出的过渡动作,将手语语句的识别转化为复合段的分类和目标词汇序列的跨段搜索,降低了手语语句识别的复杂性。实验证明,该算法具有良好的稳定性及实时性。
猜你喜欢
百花(2021年5期)2021-09-12
新基础教育研究(2021年7期)2021-09-10
星星·散文诗(2021年7期)2021-08-30
歌海(2021年3期)2021-07-25
作文周刊(高考版)(2019年9期)2019-04-29
视野(2016年4期)2016-03-26
青少年科技博览(中学版)(2015年8期)2015-10-28
作文与考试·小学低年级版(2015年5期)2015-04-30
新校园·中旬刊(2014年2期)2014-07-19
广西教育·A版(2010年5期)2010-05-24
