
基于语义增强的改进混合特征选择的文本分类
2021-01-19 02:24高洁云赵逢禹
计算机技术与发展 2021年1期
高洁云,赵逢禹,刘 亚
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
文本分类是基于文本的内容将文本分配给一个或多个预定义类别[1]。传统上,文本分类是基于词的向量空间模型,每个文本被表示为高维空间中的向量,文本之间的相似性是基于词匹配计算的,即取决于文本之间词特征的共现率。因此,Salton等人[2]提出的矢量空间模型,也称为特征向量模型,有助于在二维空间中用词频建模来表示文本。通常,文本表示包括特征提取和特征加权两个步骤,特征提取可捕获文本上下文的重要特征,特征加权是各特征的赋予不同的权重值,表明其在该特定文本以及整个语料库中的重要性。词袋(BOW)[2]模型是把文本中的词与词频抽取出来,构成词袋,形成文本的特征空间,但是文本特征空间的大小随文本大小增加而变得极度稀疏,并且没有考虑词间的语义。
基于语义分析的技术可用于文本分类过程以提高性能和准确性。但是,大多数现有的文本分类方法都使用统计加权方法来计算特征加权。Deerwester等[3]提出了一种称为潜在语义分析(LSA)的纯统计技术,通过合并与具有相似含义的词相关联的维度来很好地解决同义词问题,但是多义性问题仍没有很好地解决。Gabrilovich和Markovitch[4]提出了一种显式语义分析(ESA)技术,利用维基百科中的概念将自然语言文本表示成细粒度的语义概念,对自然语言处理的研究发现,ESA在文本分类方面是成功的。然而,ESA算法在很大程度上依赖于维基百科的现有知识,这非常耗时。Banik等人[5]已经提出了类似的方法,其目的在于开发概念本体,其中从维基百科提取的背景知识用作语义核以改进文档表示。但是,基于词特征空间的文档表示有时不能很好地反映文档之间的语义相关性。
在Google推出词向量word2vec[6]后,出现了一种新的文档表示方法,陈磊等人[7]通过word2vec词向量特征选择的方法来创建分类特征。词向量是一种分布式表示,其中词以低维和实值向量表示,在向量空间中,语义上相似的词往往具有相似的向量。最近的研究已经应用词向量来提高文本分类任务的性能[8]。
为了更进一步优化文本分类性能并提高准确性,针对海量文本数据,该文提出了一种新的混合特征选择技术(hybrid feature selection,HFS),对海量文本使用HFS技术删除不相关且冗余的文本特征,通过去除不必要的特征来减少数据维度。由于word2vec会忽略词内部的形态特征这一问题,在应用混合特征选择之后,提出使用预训练的fastText词向量技术用于发现语义上相似的特征,以增强原始特征集,并应用这种增强的特征集进行分类。该文把增强特征方法(enhanced hybrid feature selection,EHFS)与两种特征选择方法(AC和MAD)以及著名的文本分类算法LSTM一起使用,并通过实验验证了EHFS对文本分类的有效性。
1 相关技术
word2vec[9-10]从输入中构建词汇表,然后学习词的向量表示为每个词生成一个向量。但它忽略了词内部的形态特征,比如:“文本数据”和“文本”,这两个词有公共字符“文本”,即它们的内部形态类似,但是在传统word2vec中,这种词内部形态信息因为被转换成不同的词向量而被忽略。为了克服这个问题,该文引入了fastText,它可以计算两个向量在语义上的相似度,对相似特征进行语义上的增强。
1.1 fastText
Facebook于2016年推出的fastText是一个开源的词向量计算和文本分类工具[11-12]。在fastText模型中,字符级别的n-gram信息和词内部顺序的隐藏信息可以用于词表示,对于“文本数据”这个词,假设n的取值为3,则它的trigram有:“<文本”,“文本数”,“本数据”,“数据>”。其中,<表示前缀,>表示后缀,于是,可以用这些trigram来表示“文本数据”这个词,进一步,“文本数据”的词向量可以用这4个trigram的向量叠加来表示。对于未登录词的词向量可以使用词典中相应的子词向量之和的平均来进行表示。
fastText还可以计算两个向量在语义上的相似度。首先从输入中构建词汇表,然后学习词的向量表示。对于两个词向量,使用余弦相似度值确定它们的相似度,该值越大,两个向量在语义上就越接近,这些词向量可以用作分类问题中的特征。
1.2 LSTM算法
LSTM是由Hochreiter&Schmidhuber在1997年提出的[13],它是RNN的一种特殊类型,可以学习长期依赖关系[14]。LSTM结构如图1所示。
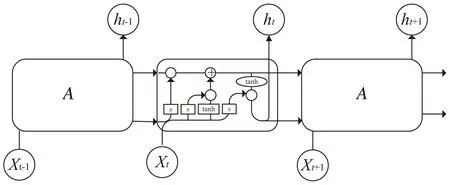
图1 LSTM结构
RNN是具有内部存储器的网络,可高效地预测时间序列[15]。在RNN中,信息从每个神经元流到其同层中的其他每个神经元。LSTM是RNN单元的扩展[16],它克服了RNN单元的缺点。与传统的循环神经网络相比,LSTM仍然是基于xt和ht-1来计算ht,只不过内部的结构加入了输入门、遗忘门以及输出门三个门和一个内部记忆单元ct[17]。输入门确定何时将当前计算的新状态更新到记忆单元中;遗忘门确定何时将前一步记忆单元中的信息遗忘掉;输出门确定何时将当前的记忆单元输出。
2 增强的混合特征选择EHFS
文本经过预处理后一般含有数以万计个不同的词组,这些词组所构成的向量规模同样也很庞大,计算机运算成本就比较高,因此进行特征选择,对文本分类具有重要的意义。该文采用改进的混合特征选择方法,从全局特征中提取最具区分度和较多文档中出现的特征[18]。由于相似特征对分类价值不大,该文采用基于特征向量的绝对余弦(AC)相似度,去除部分相似的冗余特征。然后采用基于词频(term frequency,TF)的平均绝对差值(MAD)与基于词文档频率(document frequency,DF)的平均绝对差值(MAD)相结合的方法选择特征。
2.1 绝对余弦(AC)
绝对余弦(AC)基于相似性得分去除冗余特征,将两个词经过预训练好的fastText模型转成词向量,计算余弦相似度,如果相似度得分过高,则删除其中之一。特征的绝对余弦相似度可以通过式(1)计算,其中wi和wt是词,v(wi)与v(wt)是对应的词向量。
(1)
2.2 基于词频的平均绝对差值
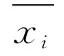
(2)
(3)
2.3 基于词文档频率的平均绝对差值
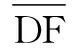
(4)
(5)
2.4 混合特征选择HFS
为了得到对文本分类重要的特征,该文提出了一个混合特征选择方法HFS,获取最具区分度和较多文档中出现的特征。算法1给出了HFS算法的描述。
算法1:混合特征选择HFS。
输入:经过数据预处理后的文本特征集T={t1,t2,…,tf}。
输出:特征子集featuresHFS。
(1)在文本特征集T中,用绝对余弦AC进行特征选择去除冗余特征获取特征子集FS1。
(2)在FS1中,用基于词频的平均绝对差值MAD进行特征选择获得MAD值较大的特征子集FS2。
(3)在FS1中,用基于词文档频率的平均绝对差值MAD进行特征选择获得MAD值较大的特征子集FS3。
(4)选取FS2∪FS3特征子集作为featuresHFS。
2.5 增强混合特征选择EHFS
通过混合特征选择方法HFS获取的特征子集featuresHFS并未考虑低频且对分类有重要价值的特征,由于这类特征出现的频率低,在分类训练算法中的作用常被忽略。为了解决这一问题,该文使用特征增强方法对这类特征在语义上进行增强。算法2给出了EHFS算法的描述。
算法2:特征增强方法EHFS。
输入:经过数据预处理后的文本特征集T={t1,t2,…,tf}。
特征子集featuresHFS。
输出:特征子集featuresenhanced。
(1)在混合特征选择方法HFS的基础上,选择MAD值较高但是词频较低的部分特征。
(2)使用预训练好的fastText模型计算每个特征f与未标记数据集的其他所有特征之间的余弦相似度得分。
(3)选择每个特征语义上最相似的前k个特征,如果这k个特征在T中,且不在特征子集featuresHFS中,则将其添加到最终的特征集featuresenhanced中。
3 文本分类器训练
为了评估针对文本分类提出的增强混合特征选择方法EHFS的性能,该文将分类算法LSTM应用于使用该算法生成的最终文本向量上得到分类模型,然后验证模型的正确性。图2描述了文本分类流程。
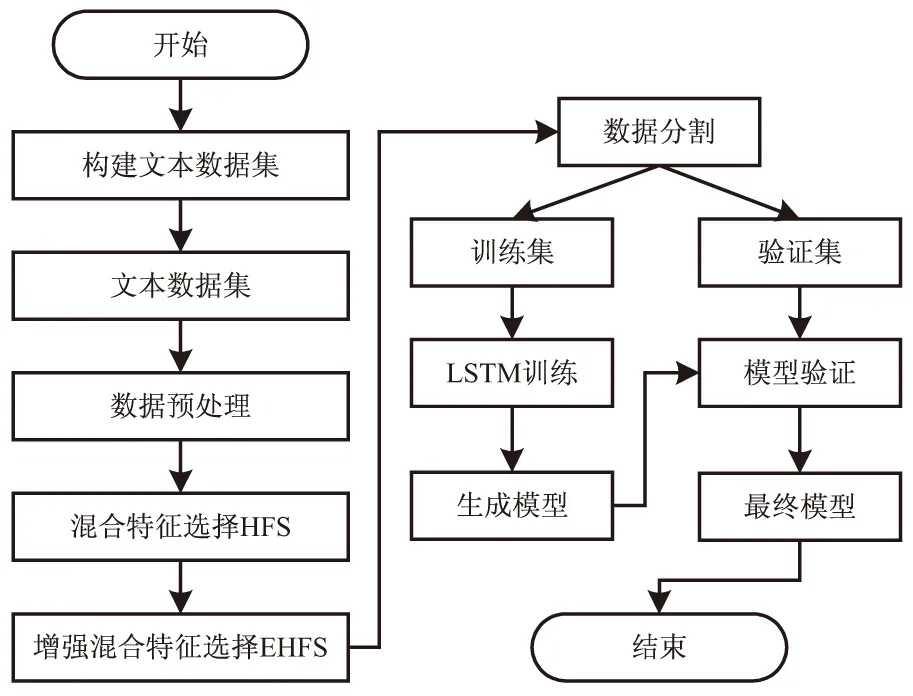
图2 基于语义分析的文本分类流程
4 实验过程
为了更好地验证增强的混合特征选择EHFS算法对文本分类的作用,构建了一个实验。该实验首先抓取不同类型的文本数据,构建文本数据集,然后进行数据预处理并采用增强混合特征选择方法进行特征选取,最后采用LSTM模型对文本分类,并基于分类结果验证该方法的性能与效率。
4.1 语料集数据
使用python抓取工具scrapy收集了来自新浪、今日头条、腾讯、百度、人民网五个热门站点共71 825个文本数据,数据收集自过去3年到2019年12月之间。类别和文本数量如下:文化(6 024),经济(13 167),科技(7 580),法律(4 122),教育(9 809),军事(2 675),旅游(8 352),娱乐(1 954),历史(5 124),体育(13 018)。由于来自所有网站的合并数据集并未将数据公平地分布在所有类别中,因此该研究仅限于十个类别。
4.2 文本数据预处理
4.2.1 文本词频
该文用python编写了对各类别中每个文本处理程序,提取词干,统计每个类别对应的词干和词频,然后在数据库中构建文本词频表,表的字段有文本文档、词干、词频,以法律文本law0.txt为例,law0.txt、诉讼、13。
4.2.2 文本的词文档频率
根据文本词频的统计,统计每个词的词文档频率DF。以每个类别的文本特征为例,针对每个词干计算被多少个文本所覆盖,将结果插入到词文档频率表中,表的字段有词干、词文档频率,以法律词干“诉讼”为例,诉讼、217。
4.3 增强混合特征选择EHFS
在获取每个类别每个文本的特征后(包括词干与词频),通过merge_stem函数可以将每个类别的文本进行词干合并,最后得到该类别所有词干集合all_features。以法律为例,将law0.txt、law1.txt…law4122.txt的特征合并到law.txt文本中。
4.3.1 词干去冗余
根据类别得到合并后的文本,然后计算任意两个词之间的的绝对余弦AC值,这里词的特征向量通过fastText计算。如果特征相似度得分超过设置的0.8,就认为这两个特征是冗余关系,可去掉其中DF值低的词。本文通过调用removed_redundancy(all_features)程序获得去冗余后的数据集FS1。
4.3.2 提取重要特征FS2
本实验提供mad_tf程序,该程序基于每个类别特征子集FS1中各类别词频的平均绝对差值获取每个类别的特征子集FS2。该程序的处理方法是:(1)计算FS1中所有词的词频均值(合并文本时,将相同的词干,所对应的词频相加);(2)根据每个词干Ti的词频,计算MADtfi;(3)将词干的MADtf由大到小排序,取前60%的词干加入到特征子集FS2中,获得的特征子集FS2的信息(文本文档、词干、词频、词频的平均绝对差值MADtf)放在数据库的表1中。

表1 词频的平均绝对差值
4.3.3 提取重要特征FS3
本实验提供mad_df程序,该程序基于每个类别特征子集FS1中各类别词文档频率DF的平均绝对差值获取每个类别的特征子集FS3。该程序的处理方法是:(1)计算所有词文档频率的均值;(2)根据每个词干Ti的词文档频率,计算MADdfi;(3)将词干的MADdf由大到小排序,取前60%的词干加入到特征子集FS3中,获得的特征子集FS3的信息(词干、词文档频率、词文档频率的平均绝对差值MADdf)放在数据库的表2中。

表2 词文档频率的平均绝对差值
4.3.4 获取增强特征子集featuresenhanced
根据算法2,该文提供了enhanced_features程序对低频特征在语义上进行增强,来获取每个类别增强后的特征子集featuresenhanced。
4.4 训练LSTM分类模型
获得每个类别的特征子集后,使用TensorFlow库中的LSTM的实现类BasicLSTMCell用于构建和训练深度学习模型。LSTM的建模工作是:(1)拆分数据集为80%训练集和20%验证集;(2)定义一个LSTM的序列模型,模型的第一层是嵌入层(Embedding),它将上面获得的每个类别的特征子集features经过fastText模型构建的词向量而形成的矢量矩阵作为模型的输入;(3)输出层则为包含10个分类的全连接层。因为是多分类问题,所以激活函数设置为“softmax”,损失函数为分类交叉熵。
5 实验结果分析
基于上面的实验过程,构建了两个实验。实验1采用混合特征选择HFS选择的特征训练分类模型,实验2采用增强混合特征选择方法EHFS,在混合特征选择后对低频特征做语义上的增强,然后用增强后的特征训练分类模型。针对两个实验,从精确率(Precision)、召回率(Recall)、F值(F1-score)[19-21]的得分来评判分类的效果。
实验1:混合特征选择HFS和LSTM模型的评估。
表3描述了混合特征选择HFS进行特征选择获取特征子集,然后将其作为LSTM模型的输入数据,进行文本分类,分类的实验结果中,军事文本的分类精度为96%,经济文本的分类精度为68%。
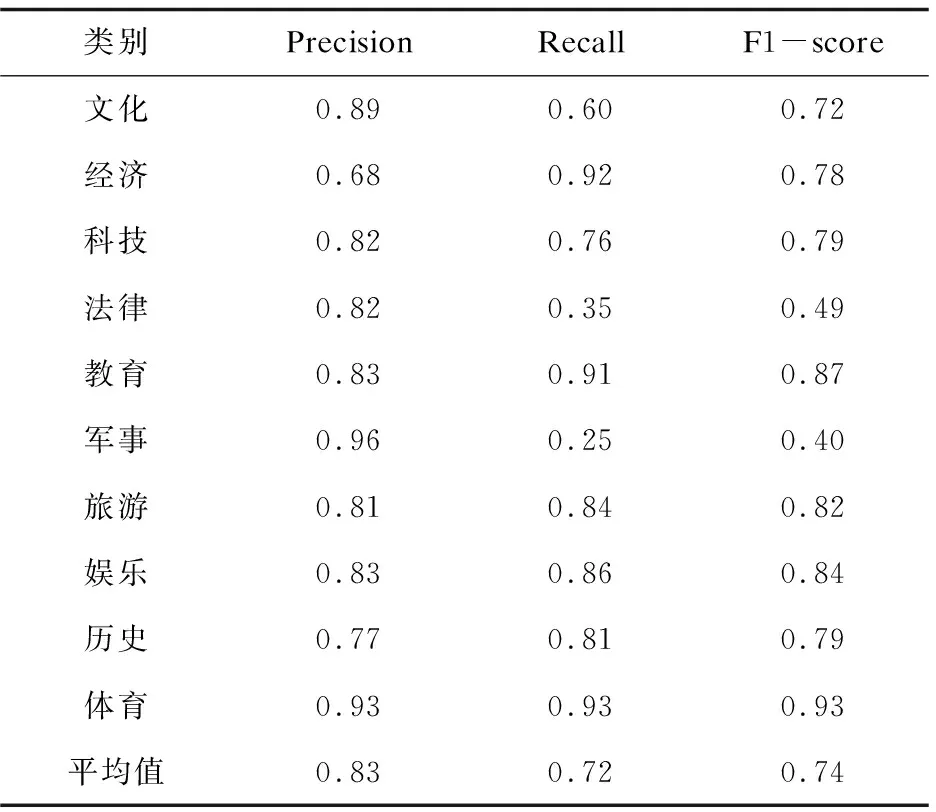
表3 使用HFS和LSTM的分类结果
表4使用经典的算法TF-IDF来做一组对比实验。实验表明HFS方法的分类效果优于TF-IDF算法。
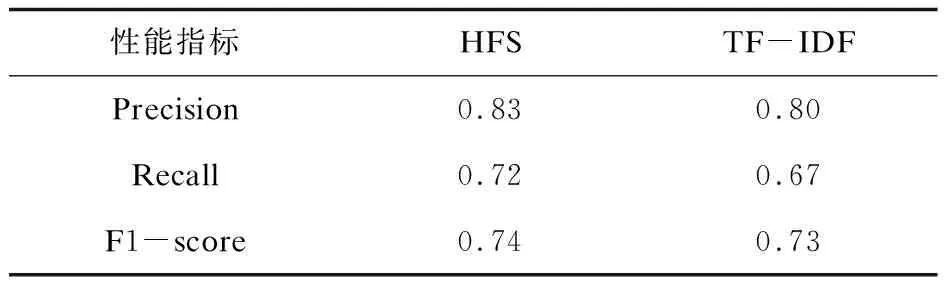
表4 HFS和经典算法TF-IDF的平均实验结果对比
实验2:增强混合特征选择方法EHFS和与HFS对比。
首先使用该文提出的基于语义的增强混合特征选择方法EHFS获取特征子集,然后将其作为LSTM模型的输入数据,进行文本分类,得到的分类结果见表5。
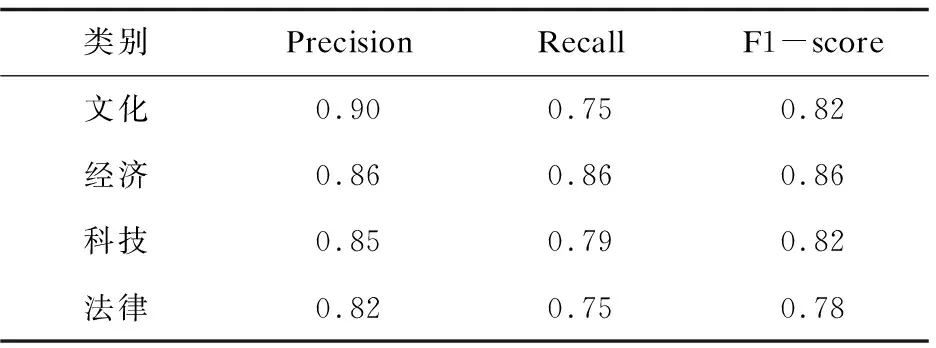
表5 使用EHFS和LSTM的分类结果
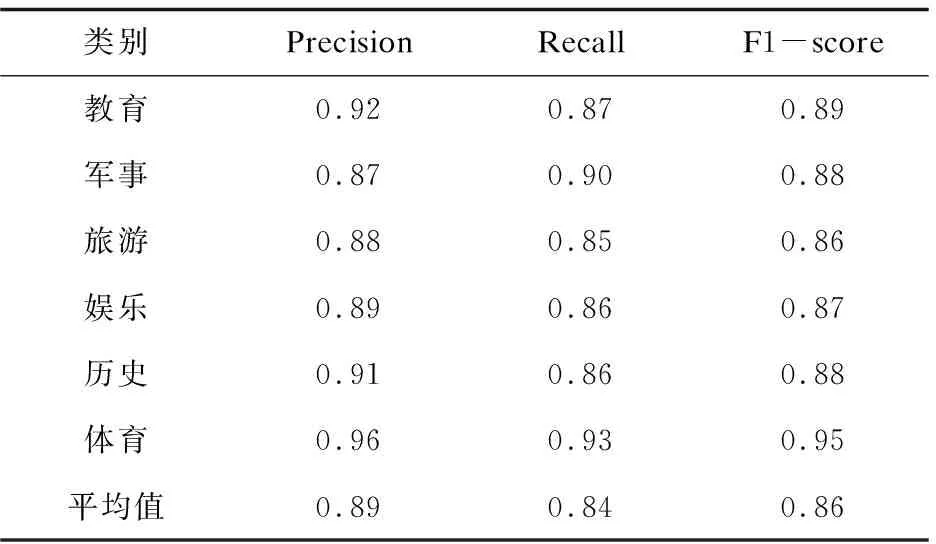
续表5
从实验结果可以得知,考虑了语义的特征选择实验2的分类效果较实验1有很大改善。并且实验2在准确度上也比实验1更高一些。实验的分类准确性如图3所示。
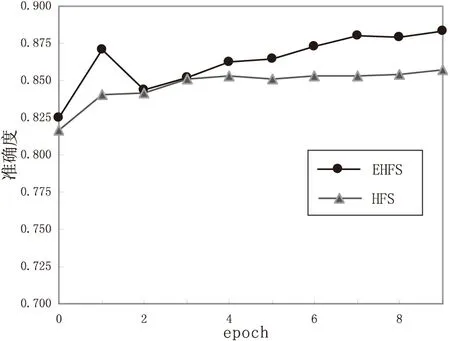
图3 实验1和实验2的分类准确性与epoch的关系图
6 结束语
在混合特征选择上,提出一种新的增强混合特征选择方法EHFS。该方法先使用改进的混合特征选择,再使用特征相似分析对低频且对分类有重要价值的特征进行语义上的增强。然后将得到的特征向量矩阵作为LSTM模型的输入进行模型的训练。数据集来自五个热门网站的数据,并将其效果与指标进行了比较。实验结果表明,提出的增强混合特征选择方法EHFS比不考虑语义只进行混合特征选择HFS,分类效果有很好的改善。文本数据集被分为十个不同的类别,其中体育的准确度最高为96%,法律类的准确度为82%。实验基于相对较小的数据集,还可以获取更多文本数据集来进行改进。另外,该文只是基于10类文本进行分类,还需要增加数据类别验证文本分类方法的实用性。
猜你喜欢
中学生数理化·高一版(2022年1期)2022-04-05
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
数学教学通讯·初中版(2015年5期)2015-06-17
读者·校园版(2015年7期)2015-05-14
都市丽人(2015年4期)2015-03-20
心理学报(2014年4期)2014-02-02
