
主题网络爬虫在校园网络平台监测中的应用研究
2021-01-20 06:21周林重庆大学城市科技学院
数码世界 2020年12期
周林 重庆大学城市科技学院
1 引言
校园网络平台主要包括校园论坛、校园贴吧、博客、微博、公众平台等,是学生最活跃的信息交流平台。大学生的互联网参与行为表现出参与意识强、知识层次高、个性化鲜明、好奇心重等特点,他们在“互联网世界”里非常活跃。从新媒体研究的视角来看,学生既是网络信息的接受者,也是网络信息的制造者与传播者,对校园网平台信息进行有效的监测,对督促学生良好的网络行为引导、正确价值观的构建等具有积极的意义和价值。校园网平台信息的主题相关性较强,因此选择主题爬虫“面向特定主题”的信息进行抓取,能够有效实现校园网平台信息的监测。
2 面向校园网平台的主题爬虫关键技术
2.1 采取策略
在爬虫技术应用中,针对不同类型的网络平台,所采用的爬虫关键技术有所区别,比如对于传统网页信息的采集,采用传统爬虫爬取更多页面,对于博客、微博、个人主页等类型的网络平台,考虑到其自行管理特征和实时更新特征,需要尽可能的缩短爬行周期,与信息更新的速度相匹配。在以往的应用中,简单咨询聚合(RSS)被广泛应用,但随着信息技术的不断发展,在不利用RSS的情况下,需要在爬行策略上进行思考,采取更多的、更有效的策略。从高校学生活跃度较高的网络平台情况来看,微博、博客、个人主页等是最受欢迎的,因此在具体的应用中,需要先对各网络链接类型进行区分,然后依据链接类型与链接结构爬取信息,缩短爬行周期,获得更好的效果。
2.2 主题相关性判断
在进行主题相关性分析时,先确定分析的流程,即网站结构分析→链接类型分析→网页内容获取→主题相似度计算。在具体实践中,先对学生主要参与的网络平台进行分析分类,明确每个网站的特定结构,然后针对性的对爬虫做统一的设置,以避免和排除不相干链接的干扰。比如新浪微博网址均以https://weibo.com/开头,那么在在爬虫设计时只要满足前缀为这个格式的即可,这样可以有效滤过其他网站的广告URL。在个人往来平台的的信息爬取中,以目录页为种子,以列表中所有链接地址为爬取内容,则可爬取该主页所信息。
当获得全部网络页面链接之后,为避免“主题漂移”,还需通过获取网页内容来评价主题相关性。为了提高网络信息爬取效率,需要先对网络内容进行判断,然后进行主题相似度分析,以避免主题无关性信息下载。在实践中,选择朴素贝叶斯算法,其概率公式为:
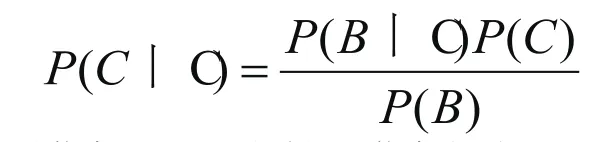
其中,B为信息网页,C为关键词信息类别,通过这个公式可对比出“是/非”的概率,然后在根据关键词w及权重t,对T个网页或T篇文章进行爬取,最终依据以下两个公式判断网页信息是否主题相关。
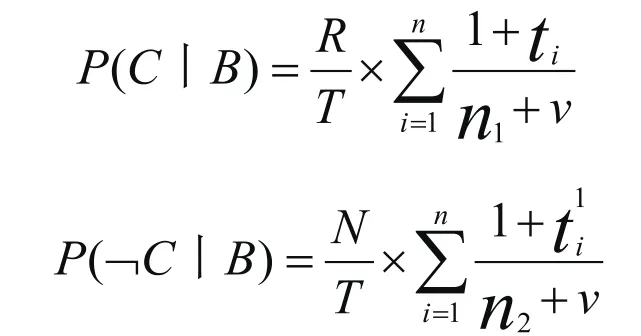
其中,R是主题相关的数量,N是主题不相关的数量,v是不同词数量。
3 校园网络平台监测主题爬虫架构设计
3.1 爬取流程
在主题爬虫系统框架设计时,先对爬虫进行初始化设计,包括种子管理与爬虫定时器设置,然后实施网页抓取,采用多线程技术,实现增量爬取,减少网络信息的重复爬取。针对校园网络平台的信息监测要求,主题爬虫系统在工作时需要实现四个爬取过程的内容,包括页面抓取、页面解析、去重、任务调度。
3.2 页面爬取与内容抽取
针对校园网络平台中学生个人主页地址集中的特征,可在深度优先爬取的基础上,采用多线程技术实现多个页面爬取任务并发执行,可以同时爬取多个个人网络主页,最大限度提升爬取效率。考虑到校园网络平台上的信息是不断更新的,而且原有信息多是保留的,这时为了尽可能减少重复爬取,可采用增强爬取的方法,在爬虫定时器的控制下,按照设定好的爬取周期进行二次爬取或多次爬取。在一次爬取时,所有检索信息按照URL和sha-1值以extractor表的方式存储数据库,当二次爬取时,为避免重复,系统先在数据库中查询前一次爬取的数据,查看URL是否存在,以及文章内容sha-1值是否变化,若URL存在且sha-1值无变化,则无需再次爬取;若sha-1值有变化,则在数据库信息表中更新文章信息。
在主题相似度计算时,中文分词是基础,这就需要选择合适的分词器,而且分词器的效果直接影响主题相似度计算的准确性。分词器的选择中,要充分考虑系统要求、面向网页的特征、网页信息的文字特征等因素,同时还需要注重单击分词速度、分词精度等指标,而且还要满足“支持自定义词典”的功能。分词器选定后,在相应的校园网络平台选取微博、博客、论坛、个人主页等平台上的文章进行训练,用选定的分词系统进行分词处理。在朴素贝叶斯算法函数下,分别计算出网页文章信息属于和不属于相关主题的概率。最后,对于满足爬行条件的网页信息,将HTML文件下载到本地,然后在数据库中建立一一对应额文件夹进行保存。
页面爬取流程完成后,对信息内容的抽取将成为主要任务。首先对网页信息进行抽取,比如微博内容、博客文章、网页文章等,抽取内容主要包括标题、发布时间、内容。当网页信息中包含图片内容时,可借助图片转换文字的软件工具提取文字信息,然后对文字进行比对处理,最后存储于数据库。由于校园网络平台中的信息内容是不定时更新的,而且学生对网络的参与热情较高,在互联网上十分活跃,发布信息较为频繁,因此针对这些信息的监测,需要系统对网页信息的爬取周期更短,需要更大频率的监测。从目前最常用的方法来看,主要采取抽取定时器、爬虫定时器等功能。爬取定时器设置一定的爬取周期,然后以自动的方式在周期内实现网页信息爬取。
3.3 去重与任务调度
系统正常运行中,虽然可以通过数据库存储的原始文件进行比对,最大限度避免网页信息的重复爬取与解析,但实际上这样会大大降低程序的效率。而且校园网络平台不仅仅局限于博客、微博、论坛、个人主页等作者发布的“主贴”,还会涉及到很多的“回复”信息,而这些信息同样需要进行监测。分析可知,在校园网络平台上用户发布的言论都是按照时间顺序排序的,因此针对这些信息则可以选用爬过的言论发表时间中最大值作为标准,对网页上这类信息进行判断其是否已经被爬取过。基于这种考虑,可以在数据库建立一个“历史时间表”,借助存储的时间信息完成去重任务。在任务调度中,首先需要对各类校园网络平台上的用户账号进行汇总统计,然后在多线程爬取方式下,依据账号书目确定开启线程的个数,以确保各线程间无重复竞争的问题。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
甘肃教育(2021年12期)2021-11-02
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
少儿美术(2020年11期)2020-11-06
福建基础教育研究(2019年6期)2019-05-28
智能计算机与应用(2018年5期)2018-10-20
魅力中国(2018年5期)2018-07-30
电脑知识与技术·经验技巧(2018年1期)2018-05-30
中学科技(2016年7期)2017-05-16
