
基于关系自适应解码的实体关系联合抽取
2021-01-21 03:22丁相国桑基韬
计算机应用 2021年1期
丁相国,桑基韬
(北京交通大学计算机与信息技术学院,北京 100044)
0 引言
知识图谱在问答系统[1]、医疗文本挖掘[2]、推荐系统[3]、文本生成[4]等领域已经变得非常重要,然而大规模的知识图谱都是由数以万计的实体和关系组成,人工无法应对如此大规模的图谱构建,于是从非结构化文本中抽取实体和关系变得尤为重要。
在以往的大多数实体关系抽取工作中,研究者往往采用的是流水线模型[5-7]。流水线模型的思想是先进行实体识别,再进行关系分类,任务的分离使此类模型存在误差传递问题,即实体识别的错误会传递到关系分类中;并且此类模型忽略了实体识别和关系分类两个任务之间的关联信息。
编码器-解码器模型近年来备受关注,它能够很好地处理序列生成问题,比如在翻译模型中,将原始语言编码,通过编码信息解码生成目标语言。编码器-解码器模型能够将实体关系联合抽取问题转化为序列生成问题,自然地解决了上文流水线模型所提的两种问题。近期,许多关系抽取工作[8-10]都是围绕着编码器-解码器展开。
虽然以往基于编码器-解码器的模型[8-10]取得了优秀的效果,但是它们还是存在两点问题:
一是在解码阶段,同时生成实体和关系,两者是不同的对象,同一语义空间的映射降低了两者的抽取效果。例如,对于三元组(India,Goa,contains)的生成,解码阶段既要生成实体India 和Goa,也要生成关系contains,两种不同含义的对象使解码器很难准确地映射。
二是没有考虑不同关系之间的交互信息。以往模型更加注重的是实体与关系之间的交互信息,然而关系之间实际也存在着相关信息。语义相似性强的关系之间具有非常丰富的交互信息,特别是对于具有重叠实体的三元组,例如(India,Goa,administrative-divisions)的关系可以从(India,Goa,contains)中推断出来,也可以从(Goa,India,country)推断出来;administrative-divisions、contains、country 三个关系具有较强的语义相关性。
本文提出的基于关系自适应解码模型,将不同关系分而治之,模型通过共享的模型结构,将实体关系抽取任务转化为对应关系的实体对生成问题。如图1 所示,模型根据不同的关系输入,自适应输出相应关系的实体对,不同关系又共享同一编码器-解码器进行联合共享学习。

图1 本文模型的输入和输出Fig.1 Input and output of the proposed model
不同关系分而治之,使解码阶段专注于对应关系的实体对生成。虽然输出阶段不包括关系的生成,但是生成的实体对隐含了输入的关系,也就是实体对的生成隐含了关系抽取。如图1 所示,输入一个句子和关系,模型专注于对应实体对的生成。简单地将不同关系分离成不同的模型,模型会丢失关系之间的交互信息;本文将不同关系共享同一编码器-解码器模型,共享的模型联合学习不同关系,充分地考虑不同关系之间的交互信息。其次,本文对解码器进行了改进,类似于文本摘要模型[11],本文在解码器的映射层考虑当前时刻隐向量的注意力信息并在下一时间步的输入考虑上一时刻的注意力信息,当未登录词出现时能够以映射层注意力分数最高的词代替,以减缓未登录词带来的影响。经过实验结果表明,所提模型在纽约时报(New York Times,NYT)数据集上得到了令人鼓舞的效果。
在实际场景中,需求是动态变化的,往往会添加新的实体关系抽取需求。本文将已有的关系称为源域关系,添加的关系称为目标域关系。以往的模型需要将目标域关系加入源域关系中,重新整理数据,从头训练模型。本文基于关系自适应解码的模型,整体参数共享,保留了不同关系的共性信息,能够分别处理不同关系;所以本文模型能够单独在目标域关系上微调,模型在F1 指标上有不错表现的同时能够缩短训练时间。
本文的主要工作如下:
1)本文将实体关系联合抽取任务转化为对应关系的实体对生成任务。模型将不同关系分而治之,根据不同关系自适应输出相应的实体对,在解码阶段更加专注于对应关系的实体对生成。同时不同关系之间共享同一模型参数,充分地考虑了不同关系之间的交互信息。
2)模型能够适用于动态关系抽取需求的场景,能够迁移到目标域关系上。在目标域关系上微调的效果要优于从头开始训练。
3)本文模型在NYT 数据集上比目前的先进模型具有更好的表现。
1 相关工作
从非结构化文本中抽取实体和关系一直以来都是信息抽取的重要任务之一,实体关系三元组的抽取对其他自然语言处理任务有非常重要的意义。早期的一些工作主要使用流水线模型。此类方法存在两个任务之间误差传递的问题,即实体识别的误差会影响关系分类的效果,而且此类方法忽略了实体与关系之间的交互信息。后续一些工作[12-13]通过设计复杂的特征对实体关系进行抽取,但是这些工作需要专家参与特征的设计。近期有一些工作[14-15]使用神经网络的方法自动地学习特征,他们通过对模型的部分参数共享,得到的实体识别的结果,通过最后的决策阶段对所有的实体进行关系分类;但是他们定义了两个损失函数,使此类模型还是分成了两个任务,没有充分地考虑实体与关系之间的交互信息。文献[16]首次使用了一种新颖的标注机制对每个单词标注,将问题转化为序列标注问题,它首次考虑两个任务之间交互信息,但是由于每个单词只能标注一种标签,模型不能处理具有重叠实体的关系三元组。
最近,许多研究者针对具有重叠实体的关系三元组展开了很多工作,其中:文献[17]将句子的所有单词作为图中的节点,单词的依存语法作为图中的初始边,使用图卷积网络对关系进行预测。文献[18]使用两层的强化学习分别对实体和关系进行抽取。目前最为出色的一些工作[8-10],使用编码器-解码器模型生成实体关系三元组,将问题转化为序列生成问题,自然地解决了关系三元组中存在的重叠问题,其中文献[10]取得了在NYT 数据集上最好的效果,但是这些优秀的模型没有考虑解码阶段的实体和关系是两个不同的对象以及不同关系之间是存在交互信息的。
目前,绝大部分共享模型都是共享单词嵌入层,或者编码层等部分模型,例如在多任务学习[19]中共享部分模型。很少有工作将整个编码器-解码器共享;文献[20]中使用了共享的编码器-解码器学习不同摘要风格的平均风格,这给予了本文启发。
本文模型将不同关系分而治之,不同关系共享整个编码器-解码器模型;模型根据输入的关系自适应输出相应的实体对,使解码阶段更专注于对应关系的实体生成,并且模型通过共享机制充分利用不同关系之间的交互信息。
2 本文模型
实体关系三元组是由头实体、尾实体、关系组成,实体关系抽取的目标是从句子中抽取出所有的实体关系三元组。在本文的模型中,以句子、关系作为输入,输出为对应关系的实体对(头实体,尾实体),实体对之间隐含了输入的关系。如图1 所示,模型输出的实体对,根据输入的关系扩展为实体关系三元组,所有关系扩展的三元组经过整合得到句子关系抽取最终的结果。
在模型实际输出中,跟翻译模型类似,会有几个特殊字符的存在,例如“<sos>头实体1;尾实体2 | 头实体1;尾实体3<eos>”;其中<sos>和<eos>表示输出结果的开始和结束。在测试阶段,解码阶段输出<eos>表示解码的结束,输出结果只有<sos>和<eos>表示该关系下没有实体对,例如图1 的null。“;”分割实体对中的头实体和尾实体,“|”分割不同的实体对。


其中,RAD(Relation-Adaptive Decoding)为关系自适应解码模型,s为输入句子,rj表示关系j,|R|表示关系的数量,T为s中所有的关系三元组,其中一些关系三元组可能为空。
模型的详细结构如图2 所示,图2 仅展示了contains 关系的模型结构,其他关系共享同一模型结构,训练时,所有关系联合共享学习,所以其他关系不再进行展示。模型由编码器和解码器构成,句子在编码器阶段输入,关系在解码器阶段输入,对应的关系实体对在解码器映射层输出。本章将对编码器、解码器、损失函数分别进行介绍。
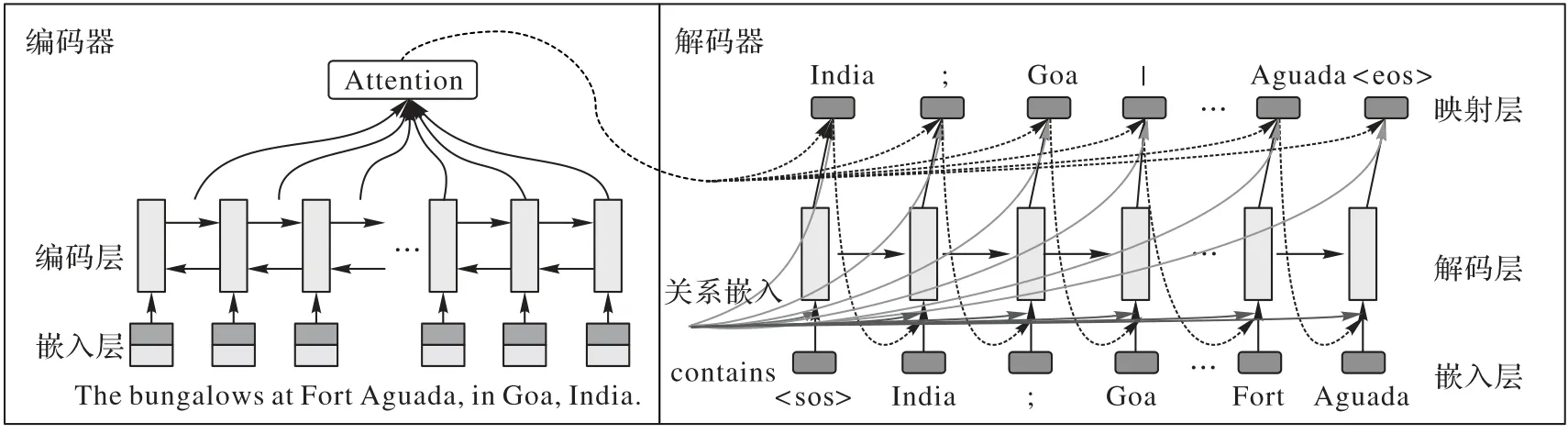
图2 本文模型框架Fig.2 Architecture of the proposed model
2.1 编码器
输入的句子s通过编码器得到句子的上下文隐向量表示其中为第i个单词的隐含向量表示,n为句子长度。编码器由嵌入层和编码层构成。
2.1.1 嵌入层
句子s={w1,w2,…,wn}经过嵌入层得到单词向量表示X={x1,x2,…,xn},其中wi表示第i个单词,xi表示第i单词的向量表示。单词的向量表示X的计算过程如下:

单词的向量表示X由单词嵌入和单词的字符特征表示Cw={c1,c2,…,cn}连接而成,||表示向量的连接。表示第i个单词的嵌入表示,ci表示第i个单词的字符特征向量。单词和字符的嵌入通过维护查找表,根据索引对嵌入表示查询,查找表随着训练不断地更新。根据文献[21],本文模型使用带有最大池化的卷积网络提取单词的字符特征向量,如式(3)所示,MaxPool(ConV())表示带有最大池化的卷积网络。为字符的嵌入表示。其中
2.1.2 编码层
双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)考虑了当前时间步的输出不仅和之前的状态有关,还可能和未来的状态有关,双向LSTM 在自然语言处理的各个领域展现出了它的优势。为了更好地对输入句子进行编码,本文使用双向LSTM作为编码层。单词的向量表示X通过双向LSTM得到编码层隐含向量表示HE:
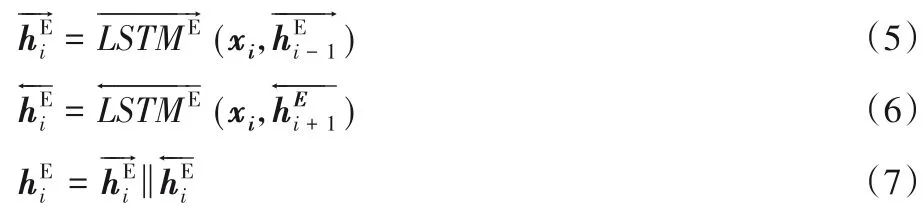
2.2 解码器
在解码器中,本文使用单向的LSTM 从左到右在每一个时间步t对相应的实体或特殊字符进行预测。解码单元以关系嵌入,上下文向量et,上一时间步的结果yj,t-1作为输入,通过解码层和映射层得到最终的结果。其中,关系嵌入类似于词嵌入,根据关系索引rj查询查找表得到关系的向量表示,查找表随机初始化,随着训练不断地更新。
2.2.1 注意力层
注意力机制[22]最早应用在图像领域,在自然语言处理领域中,通过注意机制动态获取编码器隐向量的不同权重,从而得到基于解码器隐向量的动态上下文向量。本文通过注意力机制获取上下文向量et:

其中,注意力机制Attention具体计算过程如下。


其中:Wu、Wq、bq、Va为训练参数;at表示t时刻对第i个单词的注意力分数。
2.2.2 解码层
本文模型的解码层输入不仅仅要考虑上一步的输出结果,也考虑了上一步的注意力信息。通过解码层得到每个时间步的隐含向量表示:
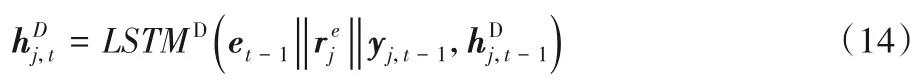
其中:yj,t-1表示上一时间步结果的嵌入表示为时间步t的解码器隐含向量表示,et-1为上一时刻的上下文向量表示,LSTMD为解码器LSTM 计算单元。在训练阶段,yj,t-1使用上一个时间步真实的结果,在测试阶段本文模型使用上一时间步预测的结果。
2.2.3 映射层
以往的关系抽取模型[8-10],映射层仅仅考虑当前时刻的隐向量,本文认为当前时刻的注意力信息有助于映射层的推断,并且对于未登录词的推断,使用当前时间步的注意力信息更加合理。在映射层,本文同时考虑了当前时刻的上下文向量、关系嵌入、上一时刻的隐向量,映射层将解码信息映射到预先在训练集构建的词典中:
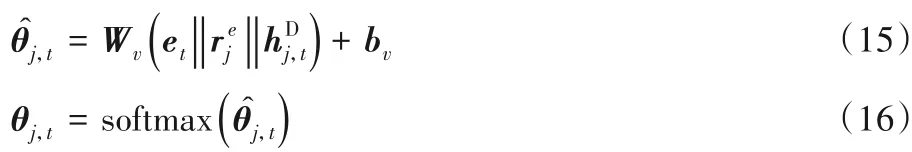
2.3 损失函数
对于输出结果Tj={vj,1,vj,2,…,vj,m},其中:m表示输出序列的长度;vj,t表示关系j下t时刻的输出结果;v:,1和v:,m分别为<sos>、<eos>,表示输出结果的开始和结束。
本文使用负对数似然函数作为损失函数:

其中:Lossj是关系j的损失函数,sb为训练批次中第b个句子,Θ为模型所有的参数。
在目标域关系训练的场景中,损失函数如下所示:
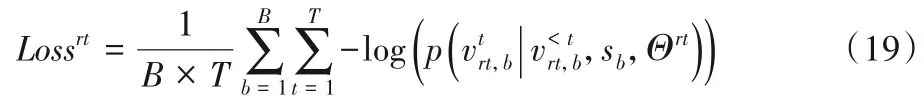
其中:rt是目标域关系,此时模型的损失为关系rt的损失函数;模型初始参数Θrt为源域关系训练过的参数,关系rt的嵌入表示随机初始化。
3 实验结果与分析
3.1 数据集
本文使用纽约时报(NYT)数据集作为实验数据集。NYT数据集有多个版本,本文使用NYT24、NYT29作为本文的实验数据集。两个数据集的统计信息如表1 所示,其中NYT24 中有24种关系,NYT29中有29种关系。数据集中训练集占原始数据的90%,其中验证集从训练集划分出10%。为了具有可比较性,基线模型使用同样的训练集、测试集划分。

表1 两个数据集的统计信息Tab.1 Statistics of two datasets
3.2 实验设置
与基线模型相同,本文使用word2vec[23]得到的单词向量表示初始化模型的单词嵌入。对于模型的关系嵌入,本文模型进行随机初始化。其中,单词嵌入维度大小dw为300,单词的字符特征表示维度dcf为50,单词的字符嵌入表示dc维度大小为50,关系嵌入维度dr为100,隐含层向量维度dh为300。本文使用Dropout[24]来预防模型过拟合,其中Dropout 的大小为0.3,本文使用了EarlyStoping 机制,即模型效果在验证集上5 次没有提高,则停止模型训练。本文使用Adam[25]作为模型的优化器。验证集用于获取最优结果的模型,获取的模型用于测试集上测试。
3.3 基线模型和评价指标
Tagging[16]:此模型使用序列标注机制对每一个单词打标签。此模型考虑了实体和关系之间的交互信息。
CopyR(using Copy mechanism for Relation extracting)[8]:此模型首次使用了带有copy 机制的编码器-解码器模型,但是它每次只复制实体的其中一个单词。本文使用它具有最好表现的多解码器模型作为基线模型。
GraphR(using relational Graphs for Relation extracting)[17]:此模型将句子中的所有单词作为图中的节点,依存关系作为图中的边,使用图卷积网络对图中节点关系预测。
HRL(Hierarchical Reinforcement Learning)[18]:此模型使用两层强化学习的方法对实体关系进行联合抽取,第一层抽取实体,第二层抽取关系。但是此模型不能保证每次都能抽取出两个实体。
CopyMTL(Copy mechanism with Multi-Task Learning)[9]:此模型是对CopyR 模型的改进,模型使用多任务学习的方法抽取实体和关系,解决了CopyR不能抽取多单词实体的问题。
WDec(Word Decoding)[10]和PNDec(Pointer Networkbased Decoding)[10]:两个模型是文献[10]提出的,WDec 使用带掩码机制编码器-解码器对实体关系抽取,PNDec每一个时间步输出一个三元组。目前WDec 是NYT 两个数据集上最先进的模型。
其中Tagging 是首次以联合的方式进行实体关系抽取的模型,CopyR、CopyMTL、WDec、PNDec 模型是基于编码器-解码器的模型。其他基线模型都是近两年实体关系抽取任务中优秀的模型。
本文使用实体关系联合抽取通用的评估指标:精确率(Precision)、召回率(Recall)和F1 值,F1 值能够反映模型的整体效果。对于每个关系的提取的实体对,如图1 所示,本文先进行去重,最终整合所有关系的三元组,整合结果和测试集中的三元组进行比较。三元组(头实体,尾实体,关系)的所有元素和顺序全部正确,本文才认为该三元组的结果是正确的。
3.4 实验结果
3.4.1 总体效果
在基线模型中,HRL模型使用文献[10]的实验结果,其他基线模型使用模型对应文献报告的实验结果。与HRL 和WDec 相同,本文的模型运行5 次,取所有结果的中位数。本文在复现WDec 模型时发现,WDec 实际结果中会比文献报告的效果要差一些,但是本文仍然使用文献中报告的结果作为模型的结果。
表2 中列出了所有模型的效果,其中“—”表示该模型未在该数据集上进行验证。从表2 中可以看出WDec 模型在所有的基线模型中各项指标中效果最好。本文模型在NYT 两个数据集上的F1 值分别比WDec 模型提高了2.5 个百分点和2.2个百分点。特别是在召回率上,本文模型分别比WDec 提高了4.5 个百分点和3.4 个百分点。对比经典的Tagging 模型,本文模型F1值分别提高了42.2个百分点和24个百分点。对比基于copy 机制的编码器-解码器模型CopyMTL,本文模型F1 值在NTY24 上提高了12.2 个百分点。本文模型相比其他基线模型各评估指标都有比较大的提升。本文模型在保证精确率的同时,较大幅度地提升了召回率,最终提高了模型的F1值。随后,本文进行了模型融合[10],即5次模型训练的测试结果进行融合,抽取出现3 次及其以上的三元组作为模型融合的结果。
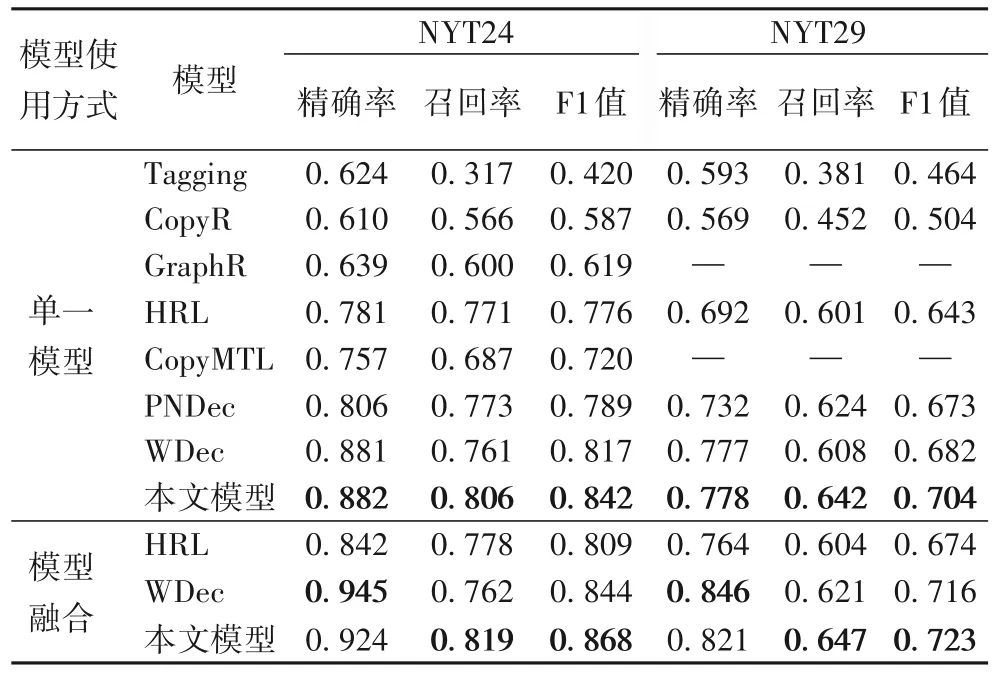
表2 NYT数据集的结果Tab.2 Results on NYT datasets
如表2 中的模型融合结果所示,相比WDec,本文模型的融合结果在NYT24 数据集上F1 值提升了2.4 个百分点,在NYT29数据集F1值上提升了0.7个百分点。
3.4.2 消融研究
此部分实验研究编码器-解码器模型的共享机制和改进的解码器对模型的影响。
S_ensemble 模型是指不同关系不再共享同一编码器-解码器模型,而是每个关系独立对应一个编码器-解码器单独训练,最终也是由多个关系进行聚合得到所有的三元组结果。如表3 所示,本文模型相比S_ensemble 模型的F1 值在两个数据集上分别提升了3.7 个百分点和6.3 个百分点。结果表明了本文提出的共享机制考虑了不同关系之间的交互信息,有效地提高了实体关系抽取的效果。同样是多个关系的结果聚合,本文模型在F1值上能够具有明显提升。
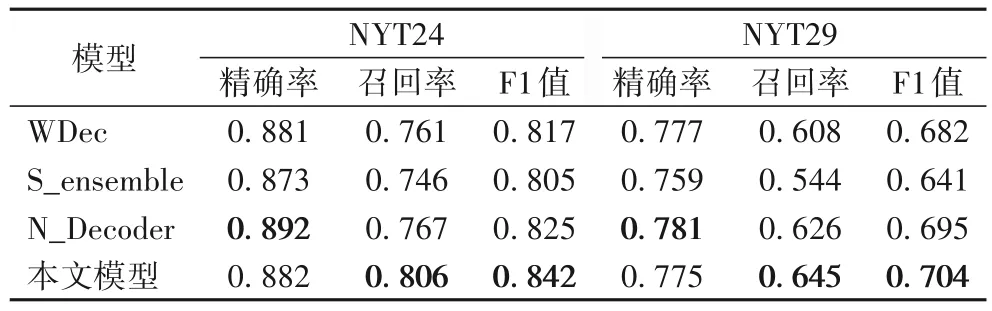
表3 模型消融结果Tab.3 Ablation results of models
N_Decoder 模型是在WDec 模型中将解码器替换成本文改进的解码器。从表3 中可以看出,N_Decoder 模型比WDec模型在两个数据集上F1值分别提升了0.8个百分点和1.3个百分点。解码阶段考虑当前时间步的注意力信息以及未登录词的推测使用当前时间步的上下文信息,使解码阶段更加准确地提取实体和关系。
3.4.3 结果分析
基于编码器-解码器模型的实体关系抽取任务主要是由实体生成任务和关系抽取任务组成。实体生成任务本文只关注三元组中的实体,关系生成任务本文只考虑三元组中的关系。如表4 所示,本文模型在实体生成任务中F1 值在两个数据集上分别提升了2.2个百分点和3.1个百分点,特别在召回率上分别提升了4 个百分点和5.3 个百分点。在关系抽取任务中F1 值分别提升了3 个百分点和3.5 个百分点,召回率提升了5.8 个百分点和6.7 个百分点。本文模型根据不同关系自适应输出相应的实体对,使模型输出阶段更加关注实体的生成,提高了实体生成的召回率,提升了模型在两个任务的效果,最终综合提高了模型的整体效果。
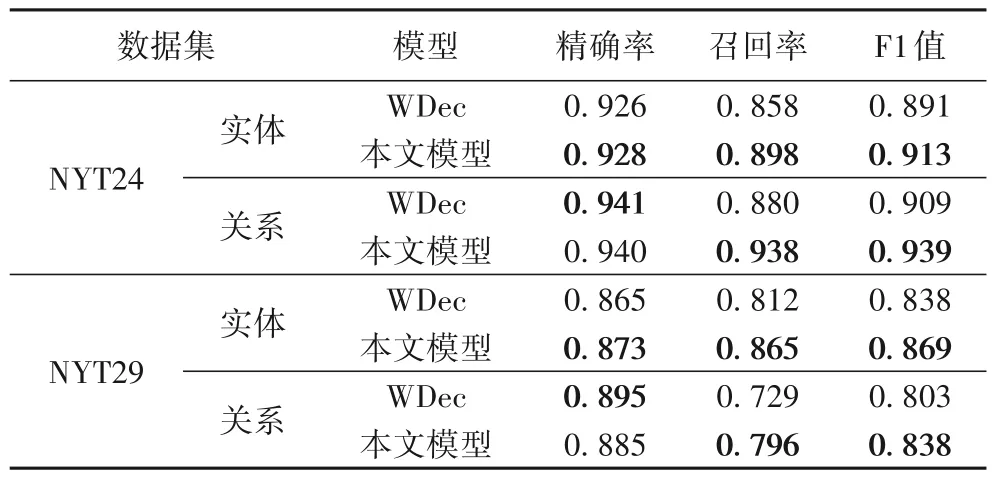
表4 实体生成和关系生成的结果Tab.4 Results of entity generation and relation generation
3.4.4 关系向量可视化
本文将模型学习到的部分关系嵌入表示进行可视化,关系嵌入两两之间做余弦相似度,其结果作为热图展示,其中,颜色越深表示相似度越大。如图3 所示,语义之间具有联系的关系之间相似度也会大,例如people 和ethnicity、majorshare-holder-of 和major-shareholders 具有较强的语义关系,其嵌入的相似度也较高。数据集中有一些关系数据量特别少,关系之间区分与联系不如数据丰富的其他关系,但是本文模型依然能够通过共享的模型在少量数据关系上表现不错的效果。从统计意义上讲,关系嵌入能够通过共享的模型学习到全局的语义信息,表明共享模型机制能够到学习不同关系交互信息。
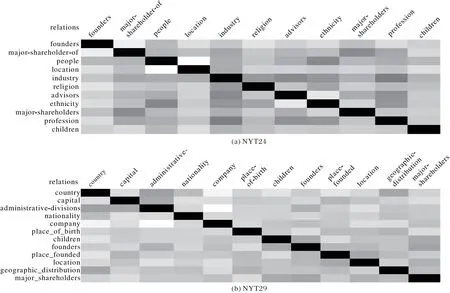
图3 关系相似度热图Fig.3 Heatmap of relation similarity
3.4.5 迁移实验
在实际的场景中,往往随着需求的变化,会有抽取目标域关系的需求,以往的模型需要重新将目标域关系加入源域关系数据中,重新进行训练;而本文的关系自适应模型能够适应此场景,能够将先验信息和不同关系的共性信息迁移到目标关系上,提升目标域关系的训练效果。
本文将数据量在100以上的关系分为3组,用任意两组关系数据作为源域关系进行预训练,剩下的一组关系作为目标域关系中分别进行模型微调。如图4所示,本文将3次实验的目标域关系结果进行整合,single_model 是指模型在目标域关系上从零开始训练,不使用先验的模型进行微调,fine_tune_model 是目标域关系经过源域关系模型微调之后的模型结果。图4 中横坐标为目标域关系,图中的各个拐点表示不同关系的结果,纵坐标为F1 值。从图4 中可以看出几乎所有的目标域关系经过微调的效果都比从零训练的F1值高,而且实验发现,fine_tune_model 模型训练速度要快,能够在很少的epoch 上达到验证集上的最好效果。结果不仅表明本文模型适应目标域关系加入的场景,而且能够学习到不同关系之间以及实体与关系之间的交互信息,这些先验的交互信息能够帮助目标域关系的训练和推断。
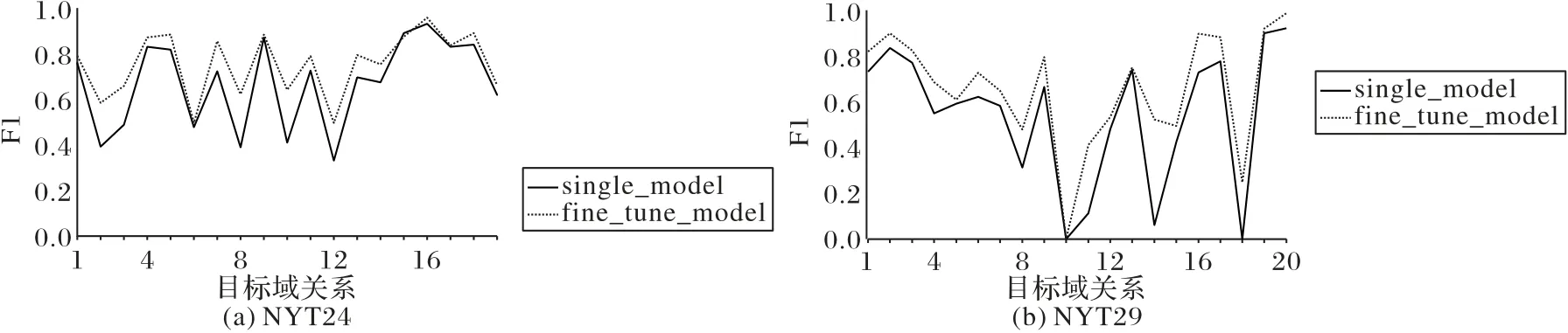
图4 目标域关系微调结果Fig.4 Fine-tuning results of target domain relations
4 结语
本文提出的基于关系自适应解码的实体关系联合抽取模型,将抽取任务转化为不同关系的实体对生成任务,模型根据不同的关系自适应输出相应的实体对。模型不仅能够在解码阶段更加注重实体的生成,而且模型的参数共享能够利用到不同关系之间的交互信息。本文模型可以在目标域关系上迁移,能够适用于动态关系抽取的需求。本文的模型也在各项实验中表现了出色的成绩。
同时,本文的模型也具有非常大的潜力,关系嵌入可以看作模型的一个插件,我们的未来工作是能够实现终身学习,在只训练插件的情况下实现实体关系的抽取。本文模型学习到的关系嵌入表示具有关系语义信息,此嵌入表示可以辅助其他任务,例如知识图谱关系预测等。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年3期)2022-05-24
数字技术与应用(2021年1期)2021-03-24
睿士(2020年6期)2020-08-18
南方周末(2019-12-19)2019-12-19
现代信息科技(2019年18期)2019-09-10
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
科技创新与应用(2017年26期)2017-09-12
科技与创新(2017年5期)2017-03-28
