
基于城市交通监控大数据的工作位置推理方法
2021-01-21 03:23于彦伟赵金东
计算机应用 2021年1期
陈 凯,于彦伟,赵金东,宋 鹏
(1.烟台大学计算机与控制工程学院,山东烟台 264005;2.中国海洋大学计算机科学与技术系,山东青岛 266100)
0 引言
随着各种智能设备(例如车载全球定位系统(Global Positioning System,GPS)、智能手机、摄像头监控等)的快速发展以及移动社交网络(例如微博、微信、Twitter 等)的广泛普及,人们的时空轨迹数据能够从越来越多的资源中获取到。针对这些时空轨迹数据的挖掘与行为分析,已经在交通调度、医疗健康、城市计算、推荐系统等各方面得到了广泛应用。推理用户的工作位置在实际应用中也变得越来越重要,在产品推荐、精确营销、交通管控以及城市规划等方面都有着非常重要的应用前景。例如,如果能够推理出用户的工作位置,就可以为他们推荐工作区域附近商场或者娱乐场所的热门活动。
目前,已存在很多基于不同时空数据源的位置推理研究,主要包括基于移动社交网络数据的位置推理[1-2]、基于GPS 轨迹数据的位置推理[3-4]、基于智能手机的位置推理[5-6]以及基于智能乘车卡的位置推理[7-8]。
尽管已经存在大量基于时空数据的位置推理方法,但是这些方法在基于城市交通监控大数据的车辆位置推理方面仍存在问题。首先,移动社交媒体数据中并不包含用户驾驶车辆的位置数据,所以不能用于车辆的位置推理;其次,虽然连续的GPS 轨迹数据在推理用户位置方面有着很高的精度,但是由于存在隐私保护等原因,很难获取到私家车大量的GPS轨迹数据进行科学研究。
近些年,在国内各大小城市,交通摄像头被广泛部署以监控城市的实时交通状况,这些智能化的摄像头能够实时捕获到交通车辆的各种信息,比如车牌号、速度以及行驶方向等。因此,无论车辆是否装有GPS设备,都能够通过城市的交通监控系统获取到整个城市所有车辆的行驶轨迹信息。虽然城市交通监控系统的部署正在逐步完善,但是由于安装和维护的成本问题,交通监控摄像头的覆盖范围仍然有限。此外,交通监控数据是从固定部署的监控摄像头获得的,因此观察到的车辆轨迹数据并不是完整的车辆行驶轨迹。
尽管工作位置推理在当前现代城市管理中非常重要,但是基于交通监控数据的工作位置推理还尚未被探索,这主要因为基于城市交通监控大数据的位置推理问题面临着巨大挑战:
1)稀疏性。交通监控摄像头只部署在城市的部分路口和道路处,所以每辆车每天的行驶轨迹只能被很少的摄像头记录到。因此基于交通监控摄像头的车辆轨迹在时间和空间上都是不完整且稀疏的。
2)噪声。交通监控摄像头收集到的信息充满噪声。例如,车辆在不同天的工作时间可能出现在多个区域,有些摄像头因为故障原因可能有些时段并没有抓拍到经过的车辆,都会导致数据的不一致问题。
3)固定性。由于部署摄像头的位置是固定的,因此获取到的车辆空间信息也是固定的。也就是说,车辆轨迹中的位置点仅由固定的摄像头位置构成。
为了解决上述挑战,本文提出了一种基于交通摄像头监控大数据的车主工作位置推理方法。首先,收集了路网、兴趣点等上下文数据,通过路网匹配预处理获得了一个含有摄像头、兴趣点等丰富语义信息的真实路网;其次,通过聚类车辆轨迹中所提取到的起点-终点(Origin-Destination,O-D),获得车辆重要的停留区域,即候选工作区域;之后,利用所提的访问时间模式约束,从多个候选区域选择出最大可能的工作区域;最后,利用所获取的路网信息及周围兴趣点分布信息提取出车主可达兴趣点(Reachable Point Of Interests,RPOI),进一步缩小车主的工作位置范围。
综上所述,本文主要工作如下:1)提出并正式定义了基于城市摄像头交通监控大数据的工作位置推理问题;2)提出了一种基于城市交通监控大数据的工作区域推理方法,通过对车辆轨迹中提取出的O-D 点聚类获取到可能的候选工作区域,之后利用访问时间模式约束匹配出最大可能的工作区域。
1 相关工作
本章主要从不同数据源上的位置推理研究介绍相关工作。
1)基于社交网络数据的位置推理。目前,已存在很多基于社交网络媒体数据的位置推理方法研究。其中一类工作是基于用户的推文内容来推理用户的位置[9-12];但是这些方法只能实现城市级的位置推理。另外一类研究使用用户的签到数据或文本信息来推理用户的位置[2,13-15]。文献[2]提出了一种利用带有地理标记的推文数据推理工作位置和家庭位置的方法,准确率达到80%时,误差范围在10 km。这类方法主要利用用户签到数据的时间、频率等信息推理用户的重要位置(例如:家庭和工作地点),由于用户更喜欢在新到达的兴趣点签到,这类方法推理的准确率往往比较低。还有很多工作利用移动社交网络中用户的好友位置信息来推理用户的位置[1,16-19]。这类研究主要基于半监督学习的框架,利用好友的位置以及社交网络中好友关系影响传播模型推理用户的家庭位置等信息。最近,还有一些研究[20-21]基于社交媒体数据对时空轨迹数据进行语义探索。Yuan 等[20]提出W4(Who+Where+When+What)概率模型,利用地理标记的推文数据,从时间、空间和参与的活动方面标注用户的移动行为;Wu 等[21]使用高斯混合模型和核密度估计获取移动记录在社交媒体数据上相关的语义词为用户的移动记录进行语义标注。
2)基于密集GPS数据的位置推理。当前也存在很多基于密集GPS 轨迹进行位置推理和轨迹理解的研究工作[3-4,22-26]。Krumm 等[3]使用4 种启发式算法从GPS 轨迹中推理用户的重要位置,误差范围大约60 m。Xiao 等[25]提出了一个通过停留点检测来为用户的GPS轨迹进行语义位置建模的方法,例如,为用户的GPS 轨迹建模成:购物中心→餐馆→电影院。Wan等[4]提出了一种基于车辆GPS 数据和兴趣点(Point Of Interest,POI)数据从私家车轨迹中挖掘时空语义移动模式的方法,他们设计了一个基于潜在变量的概率生成模型来描述车辆的语义移动性。由于GPS 轨迹数据远比交通监控点密集,且采样点任意,因此,这些方法都不适用于交通监控数据中的位置推理研究。
3)基于手机数据的位置推理。一类方法利用手机呼叫详细记录(Call Detail Record,CDR)来推理用户的重要位置[5,27]。Isaacman 等[5]通过聚类的方法将用户的CDR 数据进行聚类获得多个簇,之后通过分析数据的多种因素并使用逻辑回归模型来推理哪些簇是重要的,这些重要的簇就代表用户的一些重要位置。Alhasoun 等[27]利用CDR 来发现人们在城市范围内的移动模式,通过识别用户在白天和晚上花费时间最多的位置来推理用户的工作位置和家庭位置。另外一类研究工作基于智能手机的各类传感器数据进行用户的位置推理[6,28-29]。Do 等[28]利用手机多种传感器数据(地理坐标、APP日志、蓝牙记录等)对用户日常访问的场所进行自动标注。Zhao 等[6]提出了一个基于手机WiFi 扫描列表数据的位置推理方法,具体来说,首先从移动轨迹数据中检测出活动区域并引入活跃度和多样性度量来衡量个人的移动性,其次结合用户在家中的停留时间、晚上外出活动以及工作日和休息日的工作时间等特征来识别用户的家庭位置和工作位置。
4)基于智能乘车卡数据的位置推理。还有一类相关研究工作就是基于智能乘车卡数据的用户位置推理方法研究[7-8,30-33]。龙瀛等[7]使用智能乘车卡数据、居民出行调查数据和土地利用图来识别公交持卡人的居住地、工作地以及通勤出行模式。Munizaga等[31]通过将智能乘车卡数据和GPS数据结合起来,推理乘客在不同情景下的一个起点-终点(上车位置和下车位置)位置矩阵。Ma等[32]使用北京智能卡数据生成用户的旅行链(trip chains),基于构建的旅行链,应用聚类算法提取乘客的旅行模式和旅行规律。Tian 等[8]提出了一种从智能乘车卡数据中识别住宅和工作场所位置的方法。该方法首先识别数据中的停车点,其次识别出停车点的路口,接下来考虑停车点附近有没有其他停车点,最后利用地块级土地利用地图进一步细化住宅和工作场所位置的识别。上述方法都是基于公共通勤车数据的重要位置推理研究,公共通勤车在时间和空间上都具有很强的规律性,并且停靠的站点位置固定,而私家车相对来说行车线路不固定,出行的时间也相对随意,因此这些方法也不能直接应用于基于交通监控数据的工作位置推理问题。
2 问题定义
本章首先给出本文重要的概念定义,其次对基于交通监控大数据的工作位置推理问题进行了定义。
定义1摄像头记录。一个摄像头记录被定义为一个三元组(vehid,camj,ts),它表示车辆vehid在时间ts时刻经过了摄像头camj。
定义2车辆轨迹。车辆vehid的轨迹是一个根据时间排序的摄像头记录序列,表示为其中每个记录表示车辆vehid在tsi时刻经过了轨迹中的第i个摄像头cami。
由定义2 可知,车辆轨迹由经过的所有摄像头的时间序列构成,考虑车辆的周期性特点,将每一天的数据记为车辆的一条车辆轨迹。一辆车vehid所有的车辆轨迹集合记作TRid。所有车辆的轨迹集合记作TRs。
定义3路网。一个路网表示为G=(N,E),其中:N={n1,n2,…,nm}表示所有路口的集合,E表示路口之间所有路段的集合,ei,j∈E表示从路口ni到路口nj的一条路段。需要注意的是,每个路段都是有方向的,例如路段是不同于路段的,因为它们的方向不同。
定义4兴趣点(poi)。每个兴趣点表示为(poiid,loc,cat),其中:poiid是兴趣点的名称,loc表示兴趣点的地理位置信息(例如经度和纬度),cat表示兴趣点的类别。
所有的兴趣点构成了兴趣点集合POI。本文将基于交通监控大数据的工作位置推理问题定义如下:
问题定义工作位置推理。给定路网G、兴趣点集合POI以及车辆的轨迹集合TRs,本文的目标是推理出每位车主最大可能的工作区域位置,并通过对可达兴趣点的提取进一步缩小车主的工作位置范围。
3 基于交通监控数据的工作位置推理方法
3.1 工作位置推理总体框架
图1 给出了本文提出的工作位置推理方法的总体框架,该框架主要包括3 部分:数据预处理、工作区域推理以及基于外围信息的可达兴趣点提取。数据预处理主要从交通监控数据中提取车辆轨迹,以及将摄像头和poi映射到路网上;工作区域推理首先提取车辆轨迹中的停留点(例如起点摄像头和终点摄像头)进行聚类,获得候选工作区域,其次使用访问时间模式约束推理出车主最大可能的工作区域;可达兴趣点提取则结合外围信息将车辆不能达到的兴趣点剪枝掉,进一步缩小工作位置范围。
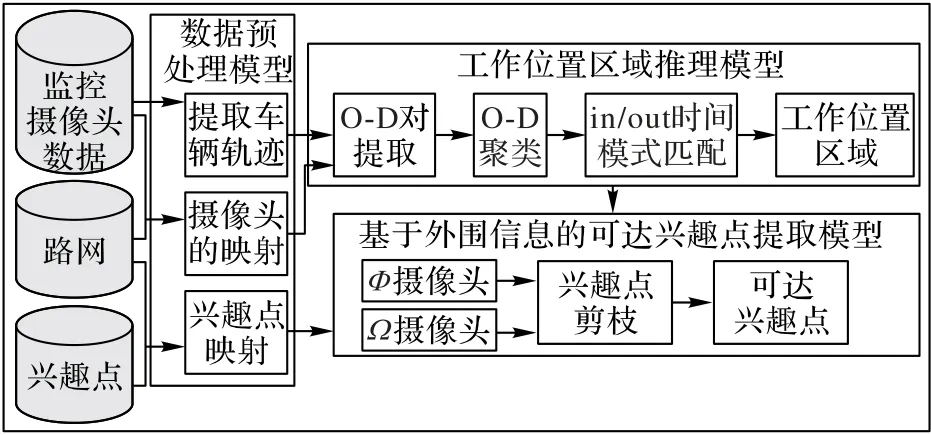
图1 本文方法总体框架Fig.1 Overall framework of the proposed method
3.2 数据预处理
3.2.1 提取车辆轨迹
在交通监控数据中,每个摄像头监控记录表示为一辆车在某个时间经过某个摄像头。由定义2 可知,通过车辆的车牌号并根据时间排序的摄像头记录可得到车辆轨迹。一般来说,人们的活动往往是遵循以天为周期的,很多研究也验证了这一点[34-35]。因此本文将每辆车每天经过的摄像头作为一条车辆轨迹,从原始数据库提取车辆轨迹,所有的车辆轨迹形成轨迹集合。
3.2.2 路网匹配
路网匹配包括摄像头与路网的匹配以及poi与路网的匹配。首先,从开源的地图平台OpenStreetMap[36]上获取真实路网。如定义3 所示,一个路网包括路口集合以及路口之间的路段集合。通常来说,监控摄像头被部署在邻近路口处的位置,用来获得所有经过此路段的车辆信息。因此,通过使用摄像头的位置信息(例如经度和纬度)将摄像头匹配到相应路段上,就能够获得车辆在路网上的不完整轨迹以及行驶方向。
其次,本文从百度地图上爬取到poi信息,利用经纬度信息将poi匹配到路网中距离它最近的路段上。最终,通过路网匹配获取得到了一个含有poi和摄像头等丰富语义信息的真实路网,以方便后续的工作区域推理与可达兴趣点的提取。
3.3 工作区域推理
本节将介绍如何为每位车主推理出最大可能的工作区域。推理方法主要包括3 个步骤:1)提取出车辆轨迹中的O-D 对;2)使用密度聚类算法对提取到的O-D点聚类;3)使用访问时间模式约束推理出车主的最大可能工作区域。
3.3.1 提取O-D对
上班工作是人们每天中最重要的活动之一,通常情况下,人们每天早上从家里出发去工作地点上班,下班后离开工作地点。因此,车主的工作区域往往就隐含在车辆轨迹中的起点和终点附近。虽然基于摄像头监控的车辆轨迹在时间和空间上都非常稀疏,但可以根据车辆轨迹中的停留点来将整个轨迹划分成多个子轨迹,这样可以最大化地利用整个车辆轨迹。具体方法为:判断车辆轨迹中两个相邻摄像头的时间间隔是否超出了给定的阈值τ,来将整个轨迹划分成多个子轨迹。其中每个子轨迹中的起点和终点称为一个O-D对。需要注意的是,O-D 对中的起点和终点其实是监控摄像头的固定位置。
为了确定时间阈值τ的合理取值,本文统计分析了车辆轨迹中相邻摄像头间的时间间隔分布情况。从图2 可以看出,时间间隔在1 min 以内情况仅占了21%,时间间隔占比最高的区间为1~5 min,占38%左右,可能的原因是相邻摄像头之间的距离较远或者是车辆需要等红绿灯或堵车等情况。时间间隔在1~2 h 和大于2 h 占比较小,长时间间隔表示车辆在此处有较长时间停留,此位置可能为工作位置或其他重要位置等。

图2 车辆经过相邻摄像头的时间间隔分布Fig.2 Time interval distribution of a vehicle of passing adjacent cameras
3.3.2 聚类O-D点
如前面所述,交通监控摄像头数据是稀疏的并且存在很多噪声。为了减少数据稀疏以及噪声的影响,本文使用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法为每辆车提取的O-D 点进行聚类,通过聚类能够将车辆不经常去的一些地点以及一些因为摄像头故障原因产生的异常O-D 点排除掉,从而获得车主经常去的一些重要区域。将所有O-D 点的位置(经纬度)作为输入数据,通过聚类获得的包含摄像头信息的每个簇就代表车主经常访问的一个区域,工作区域作为最重要的区域之一就隐含在这些簇中。接下来将讨论如何从这些簇中选择最大可能的工作区域。
3.3.3 访问时间模式约束推理工作区域
通过聚类O-D 点能够找出车主常去的一些重要区域,例如工作区域、家庭区域、常去的购物商场等。为了进一步从这些区域中找到最大可能的工作区域,本文将利用访问时间模式约束来推理车主最大可能的工作区域。
通常来讲,绝大部分的人都是早上从家里去上班,下午或晚上下班离开工作地点,有时人们也可能中午离开工作地点去吃午饭,下午继续返回工作地点上班。因此本文提出了一个in/out 访问时间模式分别表示车主访问每个区域(簇)中终点摄像头和起点摄像头的时间模式,其中,in时间模式记录着车主进入该区域的时间模式(对应访问该区域内终点摄像头的时间),out 时间模式相应地表示离开该区域时的时间模式(对应访问该区域内起点摄像头的时间)。如果一个簇中in时间模式中大部分时间是在上午(5:00~11:00),并且out时间模式中大部分的时间是在下午(16:00~22:00),那么这个簇相比于其他的簇来说,更可能是车主的工作区域。
由于不同职业会存在不同的上下班时间的情况,为了最大限度地适应更多职业的上下班时间,本文设置了两个较长的上下班时间段,上班时间段设为5:00~11:00,下班时间段设为16:00~22:00。
本文采用了基于高斯核的核密度估计(Kernel Density Estimation,KDE)方法去估计每个簇中in和out时间模式中访问时间的分布情况。将经过摄像头的时间作为输入,KDE 可统计出车辆访问每个簇的时间分布。利用KDE 时间分布,可进一步找出每个簇中in 时间模式中峰值对应的时间ti以及在out时间模式中峰值对应的时间to。通过峰值对应的时间可估算出车辆进入这个区域以及离开这个区域的大概时间区间。根据国家统计局[37]数据统计可知,各类企业就业人员的周平均工作时间约为46 h,平均每天为9 h左右。本文设置了一个日工作时长阈值tw,也就是说,如果to-ti≥tw时,则认为满足日平均工作时长,可推理出这个区域是车主的一个可能工作区域。由于9 h是各类企业就业人员的平均日工作时长,本文设定日工作时长阈值为tw=7 h。
如果有多个簇符合该时间约束条件,则选择车辆访问摄像头次数最多的簇作为车主最大可能的工作区域。
图3 展示了对一辆车O-D 点聚类所获得的三个最大簇的in/out 时间模式分布情况。图中第一行为三个簇中所有摄像头的总体访问时间分布,第二行和第三行分别是in和out时间模式的访问时间分布。从总体访问时间分布来看,簇1和簇3在早晚都各有一个时间峰值,簇2 的访问时间较为分散,没有明显峰值;而从in 和out 时间模式分布来看,簇1(真正的工作区域)的in 时间模式在9:00 左右出现了一个明显峰值,而out时间模式在19:00 左右也出现了明显峰值,日工作时长为10 h 左右。尽管簇3 的总体时间分布与簇1 相似,但是in 和out 时间模式中访问时间峰值是完全相反的。根据本文所提的时间模式约束,簇1 更可能是车主的工作区域,而簇3 更可能是车主的家庭区域。
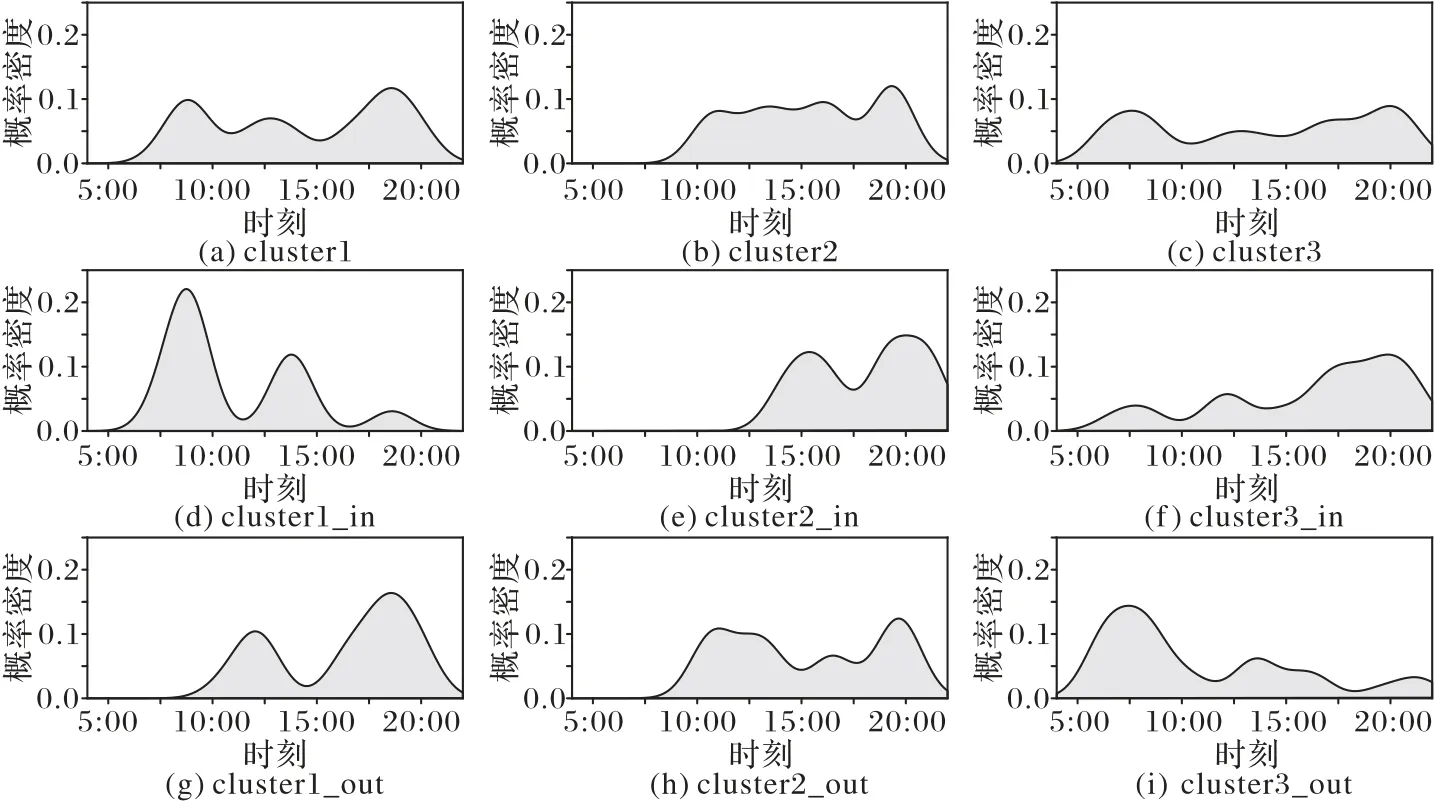
图3 in/out时间模式的例子Fig.3 Examples of in/out time pattern
3.4 提取可达兴趣点
车辆轨迹中存在两种重要的摄像头:起点摄像头(O)和终点摄像头(D)。设定Ω=为工作区域内的起点摄像头集合,Φ=为工作区域内的终点摄像头集合,需要注意的是,有些双向摄像头既是起点摄像头又是终点摄像头。结合路网中摄像头以及各兴趣点在路网中的位置,获得车辆经过Φ中摄像头之后能够到达哪些兴趣点,以及车辆在离开工作区域时从哪些兴趣点出发会经过Ω中摄像头。下面结合起点摄像头和终点摄像头,给出车主在工作区域内可达兴趣点的定义。
定义5可达兴趣点。给定工作区域内的一个兴趣点pi,如果车辆经过Φ中摄像头进入这个区域后,不需要经过其他摄像头可直接到达pi,同时车辆离开这个区域时从pi出发可直接到达Ω中的摄像头,则pi被称作该车主的一个可达兴趣点。
下面给出在工作区域内提取可达兴趣点的算法。
算法1 提取可达兴趣点算法。

如算法1 所示,首先,找出工作区域内距离Ω和Φ中摄像头r范围内的所有兴趣点作为候选可达兴趣点集合,记为P;其次,从集合P中筛选出能直达起点Ω摄像头的兴趣点集合Po,如6)~11)行所示。RoadNet(poi,camo)表示在路网中获取兴趣点poi到摄像头camo的最短路径;之后,再筛选出从终点Φ摄像头出发能直达的兴趣点集合Pd,如12)~16)行;最后求出Po与Pd的交集,获得该车辆的可达兴趣点集合RP。
4 实验与结果分析
本章将在真实数据集上的实验评估验证本文所提工作区域推理方法WorkInf(Work Inference)的有效性。
4.1 实验数据集
本文实验数据集采用了一个省会城市上的交通监控数据集,以及从多个数据源收集的外围数据。
1)交通监控数据。该数据集包括2016 年8 月1 号到8 月31 号总共31 d 的从1 704 个监控摄像头抓拍的4 亿多条数据记录。
2)路网。路网是从开源地图OpenStreetMap[36]上采集的,选取的路网包括1 034个路口和4 350个路段。
3)兴趣点。在百度地图API(Application Programming Interface)上爬取了相应路网区域内的兴趣点集合,包括17 个大类、120个小类。
4.2 实验设置
4.2.1 真实数据标注
评估实验需要知道车主真实的工作位置来评估本文方法的有效性,然而在原始交通监控数据中并不包含这部分信息。因此,利用人工标注方法,邀请了实验室10 名研究生,标注了570 个车主的工作区域位置。人工标记的过程主要分为两部分:首先将聚类O-D点获得的簇映射到百度地图上,并将车辆访问每个簇的时间进行可视化处理;其次采用投票的方式,让邀请的同学投票,将票数最多的簇作为该车主真实的工作区域,用以评估本文方法的有效性。
据统计,在交通监控数据中,车辆出现21~31 d 的数据是最多的,因此重点评估该数据区间的车辆,共选取240 辆。为了评估数据稀疏性对方法的影响,又分别在仅出现5~10 d、11~15 d、16~20 d三个数据区间的车辆中各标注了110辆车的工作区域位置。最后,获得了车辆数据区间为5~31 d 总计570辆车的工作位置区域。
4.2.2 对比算法
根据文献检索,目前尚未有使用城市交通监控数据推理重要位置的相关工作。因此本文使用了基本统计方法StatInf(Statistic Inference)作为对比算法。
StatInf方法将车辆的每次停留的位置记为D-O对,D为该停留的最后经过的摄像头,O 为该停留结束离开时经过的摄像头,因此,每个D-O对可以认为是车主去往的一个区域。其次,根据访问频率,对每个D-O 对进行统计,频率越高的D-O对表示该车主更频繁访问该区域,所以将该D-O 对所在区域作为车主的工作区域。
StatInf+time 方法在StatInf 算法的基础上,考虑了本文所提的in/out访问时间模式约束推理最大可能的工作区域。
4.2.3 实验设置
实验默认参数设置:停留点时间间隔阈值r=120 min,KDE 模型带宽设为h=2,DBSCAN 算法参数设置MinPts=20,Eps=1000 m。
4.2.4 评估指标
本文采用准确率评估方法的有效性,定义如下:

其中:N为车辆的总数;若第i辆车的推理工作位置与标注的工作位置区域一致,则ri=1;否则,ri=0。
4.3 性能评估
本节首先评估了所提工作区域推理方法以及对比算法的总体性能,其次评估了数据稀疏性对本文方法的影响。
从表1 中的实验结果来看,本文所提的WorkInf 方法在不同稀疏的数据以及总的5~31 d数据上的表现都要优于对比算法。在总的5~31 d 数据上,WorkInf 方法准确率达到了89.8%,相比StatInf 算法和StatInf+time 算法分别提升了17 个百分点和6 个百分点,这说明本文所提WorkInf 方法在推理车主工作区域问题上具有较好的性能。主要的原因是因为本文方法通过提取车辆轨迹中所有的停留点,最大限度地利用了整个车辆轨迹,并且使用聚类算法对提取的停留点进行聚类有效获取到了车辆常去的一些区域,相较于简单的统计方法来说能够更好地利用数据的空间信息。另一方面,城市中绝大多数人们的工作都是早出晚归的,本文提出的in/out访问时间模式方法充分考虑了工作时间的规律特性,考虑了in/out时间模式的StatInf+time算法的准确率比StatInf算法有明显的提升(在5~31 d 数据上提升了11 个百分点)也验证了这一点。通过对车辆轨迹数据时间和空间信息的充分利用,使得本文所提的WorkInf方法达到了较好的性能。

表1 各方法在不同区间的车辆数据上正确推理出工作位置的准确率对比Tab.1 Accuracy comparison of different methods to infer correct work location on vehicle data with different intervals
表1中第2~4列数据展示了所提WorkInf方法和对比算法在不同稀疏的数据上的实验结果。从实验结果来看,本文方法在不同稀疏数据上的结果都要优于对比算法,并且WorkInf算法在5~10 d 数据上的结果相比于11~15 d 的结果只降低了1.8 个百分点,而两个对比算法在5~10 d 数据上的结果相对于11~15 d 的结果有非常明显的性能下降。这是因为尽管在5~10 d数据上获取的停留点数量明显减少,但是WorkInf算法使用的聚类算法对停留点进行聚类依然能够有效获取到一些重要区域。而StatInf 算法仅仅对D-O 对的统计次数作为每个区域的重要程度,当车主在多次进入/离开某个区域时,如果经过了该区域附近不同的摄像头时,统计方法无法将这些不同的摄像头归结为同一区域,而是根据每个D-O 对将此区域划分成多个区域;因此随着车辆轨迹数量的减少,数据稀疏性的增加,噪声对对比算法产生的影响越来越大。而本文所提出的WorkInf方法在稀疏的数据上依然表现出很好的性能。
通常来说,车辆的轨迹数据越少,提供的信息就越有限,但是从表1 的实验结果中可以发现,WorkInf 方法在5~10 d 和11~15 d 的数据中性能并没有明显下降,反而比16~20 d 的数据有一定的提升,可能的原因有两点:1)正如前面所提到的,本文方法最大限度地利用了稀疏数据的时间和空间信息,降低了稀疏数据对本文方法的影响;2)虽然车辆数据增加了,但是数据中的噪声也会随之增加。16~20 d 数据中可能还存在部分车辆经过的区域摄像头覆盖范围有限,导致车辆轨迹更加稀疏,使得准确率有所下降。
4.4 参数敏感性评估
本节将评估参数变化对本文方法的影响。评估的参数包括时间间隔参数τ、聚类算法参数MinPts和Eps以及KDE算法带宽参数h。
图4是本文方法在参数τ从60 min变化到300 min的准确率曲线。从图4 中可以看出,当120 ≤τ≤240 时达到最佳性能,而当τ=60 和τ=300 时,准确率有明显的下降,这是因为:当τ=60时,可能会有很多间隔较短与工作位置不相关的停留点被提取出来,影响了结果的准确性;当τ=300 时准确率是最低的,这是因为时间间隔设置太长,很多重要停留点被丢失。比如,对于那些上午上班、中午回家休息、然后下午继续工作的人来说,每次在工作地点停留时间一般不会超过300 min,因此工作区域的停留点会被丢弃掉,导致本文方法不能够正确推理出工作区域。
图5 展示了在21~31 d 数据集上变化聚类算法参数MinPts从5到40,Eps从500 m 到1 500 m 的准确率结果。如图5 所示,随着MinPts的增加,各个Eps结果的准确率均呈现先升后降趋势。这可能是因为当MinPts数值较小时,聚类之后会获得很多个不相关的簇,对实验准确率产生一定影响;而当MinPts值(MinPts>20)太大时,使得很多重要的簇(包含工作区域)被合并,因此导致准确率急剧下降。

图4 时间间隔τ与准确率的关系Fig.4 Relationship between time interval τ and accuracy

图5 核心点数量MinPts和邻域半径Eps与准确率的关系Fig.5 Relationship between core point number MinPts and neighborhood radius Eps and accuracy
接下来分析当MinPts=20 时,Eps变化对准确率的影响。从实验结果中可以看出,Eps=1000 时达到最佳性能。Eps=500 时,准确率最低,这是因为Eps=500 时范围较小,通过聚类之后可能很多重要区域被划分成了多个子区域,导致准确率降低;当Eps≥1250 时,相比于Eps=1000 来说准确率略有降低,这是因为聚类范围较大,通过聚类获得的簇中会包含很多不相关的停留点,这也会对本文方法性能产生一定影响。
图6展示了本文方法在带宽参数h从1~5 h变化时的准确率。从图6 中可以看出,随着横坐标带宽变化,准确率基本都保持平稳的状态。这是因为带宽变化对访问时间分布中峰值影响不大,也就是说,峰值点对应的大体时间没有变化,因此参数h的变化对本文方法准确率影响不大。

图6 带宽h与准确率的关系Fig.6 Relationship between bandwidth h and accuracy
4.5 案例分析
本节以案例分析的方式展示所提可达兴趣点提取方法的有效性。首先,利用所提的工作区域推理方法可获取到车主的最大可能工作区域,如图7 所示为获取某车辆的工作区域,其中起点摄像头集合和终点摄像头集合分别为:Ω=图中实线箭头表示车辆在经过Φ中摄像头之后可能去往的方向,虚线箭头表示经过Ω中摄像头离开工作区域的方向。表2 为该工作区域内各兴趣点和可达兴趣点的数量。设p1和p2表示图中两个兴趣点的位置。当车辆经过Φ中摄像头进入这个区域时,根据实线箭头可以看出,车辆可以往三个方向行驶,因此车辆能够到达兴趣点p1和p2。而车辆在离开这个区域时,需经过Ω中摄像头,根据图中的路线能够看出,车辆在离开p2时,是很难直接到达Ω中摄像头,而需要绕过几个其他摄像头,因此p2不是可达兴趣点,要被剪枝掉。最后获取到的该车主在该区域各类别的可达兴趣点如表2 所示。对比表2 中各类POI 数量可以看出,POI 总的数量从49 减少到24,POI 类别从7 类减少到6 类,验证了可达兴趣点提取方法在缩小车主工作位置范围及兴趣点类别方面是有效的。

图7 提取可达兴趣点案例Fig.7 Case of extracting RPOI

表2 各类兴趣点和可达兴趣点数量Tab.2 Number of POIs and RPOIs of different categories
5 结语
本文提出了一个基于城市交通监控大数据的车辆工作位置推理方法。该方法首先通过路网匹配的方法得到了一个含有摄像头、兴趣点等丰富语义信息的真实路网;其次,通过聚类方法获取车辆一些重要的经常访问的区域;之后,利用所提的in/out访问时间模式约束,从多个候选区域选择出最大可能的工作区域;最后利用所获取的路网信息及周围兴趣点分布提取出工作区域中的可达兴趣点,进一步缩小车主工作位置的范围。在真实数据上的实验评估和案例分析验证了本文方法的有效性。
城市交通监控数据不仅包含车辆的工作位置信息,还包含其他有趣的活动信息,如购物活动和娱乐活动等,因此,在之后的工作中,将城市交通监控数据与上下文兴趣点数据相结合来探索挖掘车辆的移动模式。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
南京理工大学学报(2022年1期)2022-03-17
汽车工程师(2021年12期)2022-01-18
计算机应用与软件(2021年7期)2021-07-16
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
网络与信息(2009年6期)2009-07-31
