
1998—2017 年中国南北方地区森林火灾的时空特征
2021-01-22 09:26黄嘉文李士静张杰豪尤翠玲温永仙
福建农林大学学报(自然科学版) 2021年1期
黄嘉文, 李士静, 张杰豪, 尤翠玲, 温永仙
(福建农林大学计算机与信息学院,福建 福州350002)
森林火灾是一种突发性强、破坏性大、处置救助较为困难的自然灾害[1],不仅会引发一系列环境问题,而且与人类的生命财产安全息息相关[2].全球每年发生森林火灾在2×105次以上,每年烧毁林地面积超过6.40×106hm2[3].1998—2017 年我国平均每年发生2 800 余次森林火灾,年均受害森林面积13 000 hm2;1987 年黑龙江省大兴安岭林区和2019 年四川凉山的森林火灾都造成了严重的人员伤亡.为了更好地进行林火预防预报和开展科学林火管理,必须了解和把握近年来林火发生规律和时空特征.
林火时空分布规律的研究大体上分为两个方面:一是从年际变化分析森林火灾发生的规律;二是以行政区划或是某个特殊地域为单位来研究森林火灾的空间分布状况.根据森林火灾的特点,分析火灾在时间分布上的变化规律和空间分布上的变化规律[4].萨如拉等[5]基于遥感影像,借助ArcGIS 10.2 和Origin 等软件,分析了1980—2015 年内蒙古地区森林火灾特点,探讨林火的时空动态规律;张玉红[6]利用黑龙江省30 年的火灾记录,绘制了黑龙江林火空间分布图,分析了森林火灾的发生原因;伊伯乐等[7]基于2007—2016 年我国西南地区森林火灾数据,通过统计描述对该地区的火灾时空分布特征进行分析,并且利用主成分分析和聚类分析将森林火灾进行分级.
上述学者基于森林火灾数据的分析,建立的模型多数都是线性的,对数据的分析、描述处于静态视角,无法挖掘更深层次的信息.而结合动态分析的方式对森林火灾数据进行研究具有更加重要的意义.函数型数据分析是一种从函数视角对数据进行分析的方法,它不同于依赖过多假设条件的传统建模分析,因此具体应用和适用的数据类型有一定的局限性[8].而将观测到的离散数据点看成是由函数产生的一个整体,视其为动态数据,并表示为光滑曲线或连续函数,在此基础上进一步挖掘数据潜在的信息[9].由此,本文运用函数型数据分析方法对中国南北方地区近20 年的森林火灾发生时空特征进行分析,探讨近20 年南北方森林火灾发生的动态规律和时空特征,为开展林火管理提供科学依据;并且在一定层面上响应和支持我国生态环境建设的可持续发展战略.
1 材料与方法
1.1 数据收集
森林火灾数据来源于中国林业信息网(http:/ /www.lknet.ac.cn/),收集并整理我国29 个省市(自治区、直辖市)1998—2017 年的森林火灾发生次数(见表1).
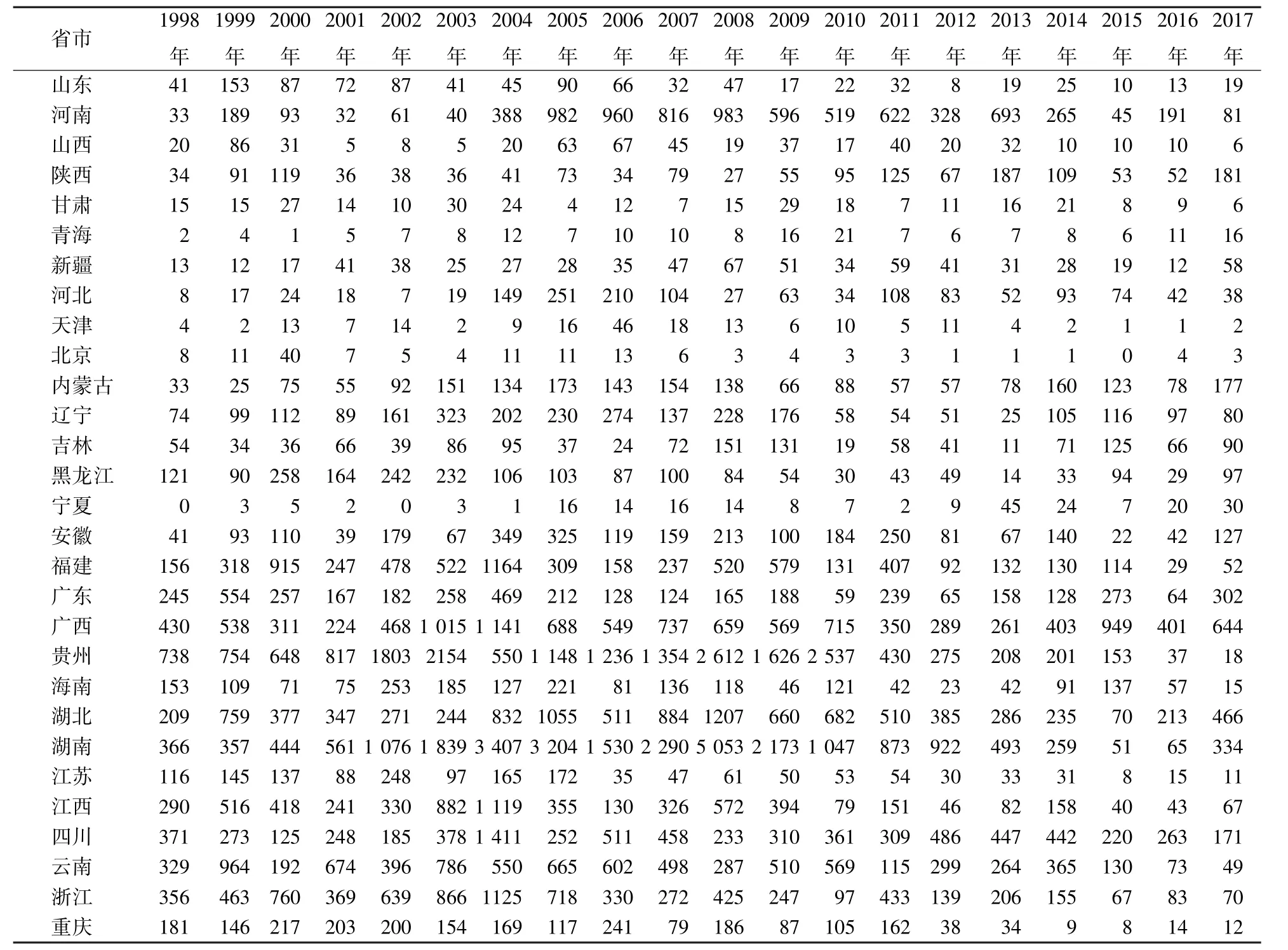
表1 我国29 个省市1998—2017 年森林火灾记录Table 1 Forest fire records across 29 provinces and cities of our country in 1998—2017
1.2 数据处理
1.2.1 拟合函数型曲线 森林火灾的发生事件满足以下条件:(1)林火发生为一独立增量的随机过程;(2)不同时间间隔内发生的火灾事件之间彼此独立;(3)林火发生次数只能为非负整数;(4)林火发生在不同时间间隔内的平均次数不一定相同.首先假设29 个省份1998—2017 年的森林火灾发生次数服从参数为λ(t)的非齐次泊松过程N(t),N(t)代表在t时间内累计发生的火灾总数.在这一非齐次泊松过程中,将时间间隔[a,b]内发生的火灾次数记为N(b)-N(a),此时该火灾次数遵循以下泊松分布[10]:
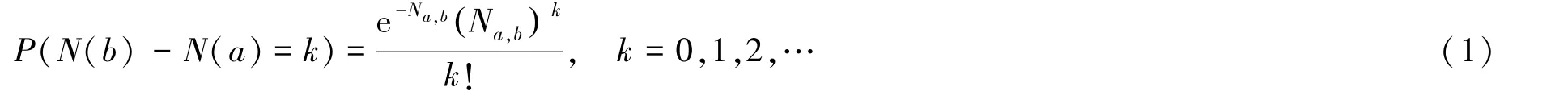
式中,Na,b表示在时间a和b之间预期发生的火灾次数,表示为

采用极大似然估计法对λ(t)进行估计,假设L为极大似然估计函数,则

式中,kj代表第j年发生的火灾次数.由于森林火灾发生次数只能为非负数,因此对式(2)中的λ(t)进行非负约束,以指数eρ(t)替代λ(t),则

在此基础上,将式(4)中的ρ(t)用函数型的形式进行替换,其中,为包含一系列傅里叶基函数的向量.傅里叶基函数为(1,sin(ωt), cos(ωt), sin(2ωt), cos(2ωt)…),而c=(c1,c2,…ck)T代表包含一系列对应的基函数Øj(t)的系数所组成的向量.将其改写成

通过将ρ(t)进行函数型转化,将似然函数L转换为对数形式.

在式(6)的基础上,采用复合辛普森法则[11]进行计算.
1.2.2 平滑拟合曲线 对于最终通过泊松分布拟合的函数型数据曲线,为了使曲线能够不过度拟合数据并且较平滑地展示出来,选择基函数来拟合数据,并在式(6)后面添加惩罚项来控制整个拟合项[10].此时对数似然方程转化为:
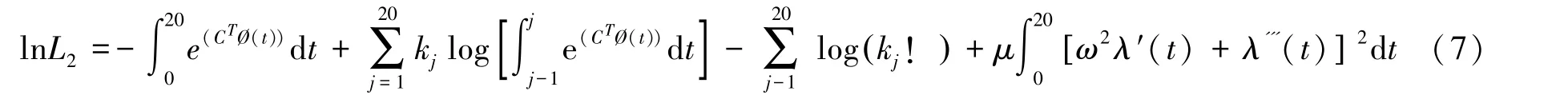
式中,μ为平滑参数,用来控制惩罚项的权重,ω为傅里叶基函数的周期,λ′(t)为替换后的参数一阶导数.式(7)为最终需要求解的极大似然估计方程.此时需要对基函数系数c进行估计,使得似然方程值达到最大,等同于求解方程:
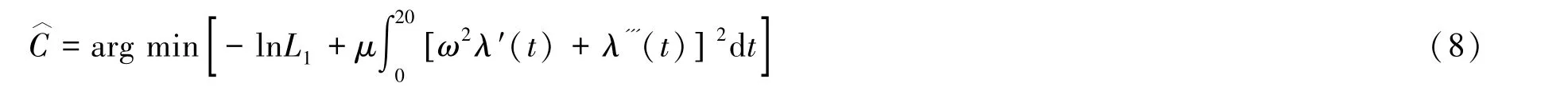
采用最优化方法中的共轭梯度法[12]来求解最优值,将林火数据进行拟合并处理成平滑的函数型曲线.
1.3 研究方法
1.3.1 函数型主成分分析 函数型主成分分析与传统的主成分分析类似,是基于已经得到的函数型数据曲线xi(s),找到一个模为1 的函数β(s),使得xi(s)在该函数上的投影ξi的方差达到最大.
首先,将观测数据xi(s)在β(s)上的投影ξi称作第i个对象的主成分得分,即

观测数据在函数上投影ξi的方差为因此,在投影的方差达到最大的条件下求解第一主成分权重函数β1(s),即利用以下约束条件求解最大化问题[13].

同理,对于求解第k个主成分权重函数βk(s),利用以下约束条件求解最大化问题.

定义协方差函数:

主成分权重函数满足下式:

式中,ρ为特征值.
定义协方差算子V满足

协方差算子V是L2空间上的自伴正定算子,求主成分等同于求解如下特征值问题:

求解主成分最后归结为求解特征值问题,而解决该问题通常采用的方法有对函数进行SVD 离散化方法和对函数进行基函数展开的方法.对函数进行基函数展开[15],采用基函数将观测数据xi(s)展开为:


同样,采用基函数将主成分权重函数β(s)展开.

式中,b=(b1,b2,…,bk)为待估参数向量,将式(18)代入式(13),则


定义u=W1/2b,则式(20)最终转化为

通过式(21)可以求得u,进而求得b,最终求得主成分权重函数β(s).ρ为特征值,称为第k个主成分的贡献率,通常选取的主成分累计贡献率应达到85%以上[13].
1.3.2 自适应模型聚类 传统离散数据的聚类分析难以直接应用于连续函数的分类问题.基于降低算法计算成本和提升分类准确率的考虑[16-17],结合研究数据维度不高、时间跨度较长的特点,本文采用函数型数据的自适应模型聚类[18]中的FunFEM 方法来划分各省份的林火曲线类别.FunFEM 算法允许对时间序列或更一般的函数型数据进行聚类,此模型可处理较长的时间序列.在对函数型数据进行平滑处理后,将函数型数据拟合到具有较低维子空间的函数型潜在混合模型中;在指定聚类数之后,通过期望最大化(EM)算法推断潜在混合模型;观测数据的最终聚类结果是通过潜在混合模型估算其属于第k个聚类的概率而获得.先估计函数型数据的基函数展开式中权重函数组成的正交矩阵U=(ujl),以获得最具区分性的子空间F;然后利用最大化模型的对数似然函数[18]得到EM 算法.FunFEM 算法的迭代是在以下3 个步骤中交替进行的(假设为第q次迭代)[19].
(1)F 步.F 步的作用主要是为了寻找区分性的潜在子空间F,并且确定潜在子空间F的方向U.在该空间中不同类之间的方差达到最大化,而同一类别中的样本差异达到最小.寻找F等同于寻找U[19],求解下式:

(2)M 步.以从F 步骤获得的方向矩阵U为条件,遵循EM 算法的经典步骤,以最大化似然的条件期望进行迭代.其中θ为待估参数,B=UΛ+ε,Λ 为观测数据在潜在子空间F转换后的基函数系数矩阵,ε为随机误差.
(3)E 步.以M 步迭代的模型参数为条件,更新观测数据属于第k类的后验概率.

式中,πk=P(Zk=1)是第k个类别的先验概率,bi为观测数据在原始空间的基函数系数.调用R 语言中的FunFEM 软件包[20]来对拟合成平滑曲线的林火数据进行聚类分析.
2 结果与分析
2.1 1998—2017 年南北方森林火灾次数的拟合曲线
利用函数型泊松分布将我国29 个省市(包括自治区、直辖市等)1998—2017 年森林火灾发生次数拟合成函数型曲线,并进行平滑处理,得到各个省市的拟合曲线图.为了更加准确、完整地提取森林火灾发生规律等信息,将29 个研究对象划分为南北方区域,其中,南方地区包含安徽、福建、广东、广西、贵州、海南、湖北、湖南、江苏、江西、四川、云南、浙江、重庆共14 个省份(包括自治区、直辖市等);北方地区包含北京、天津、甘肃、河北、河南、黑龙江、吉林、辽宁、内蒙古、宁夏、青海、山东、山西、陕西、新疆共15 个省份(包括自治区、直辖市等).从南北方地区各选择两个具有代表性的省份进行拟合效果展示(图1 ~4).图1 ~4 中实线代表通过函数型泊松分布拟合的林火曲线,蓝色虚线代表拟合曲线95%的置信区间.从图1 ~4 可以看到,部分观测数据点位于拟合曲线上,大部分数据点均匀分布于曲线两侧并且位于拟合曲线的置信区间内,少部分数据点位于置信区间外.表明利用函数型泊松分布模型来拟合林火数据的效果好.从拟合曲线图(图1~4)可看出,代表性省市在研究时段的最后5 年内森林火灾发生次数相对较少,并且变化幅度较小,而在中间时段变化幅度较大.
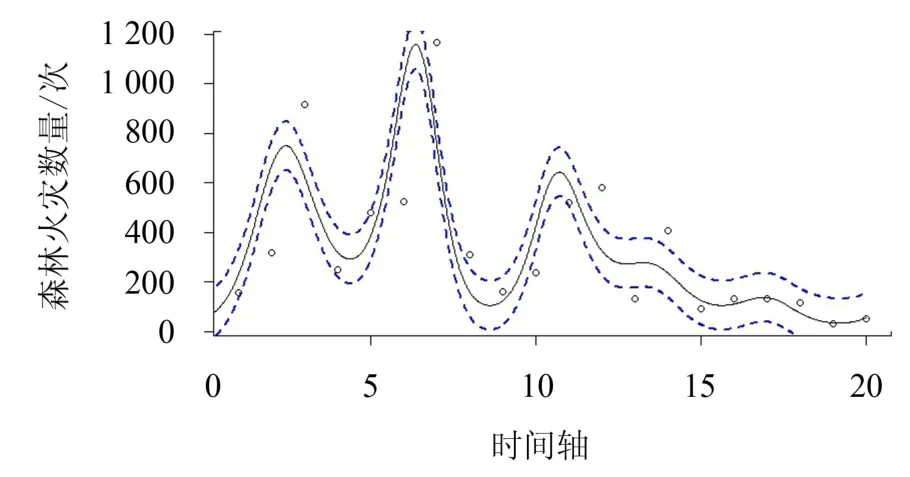
图1 福建省泊松分布拟合曲线Fig.1 Poisson distribution fitting curve of forest fire cases in Fujian province
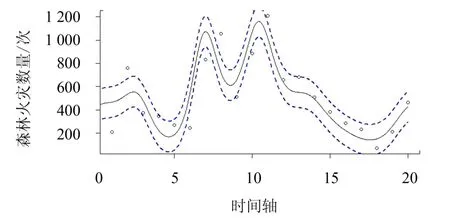
图2 湖北省泊松分布拟合曲线Fig.2 Poisson distribution fitting curve of forest fire cases in Hubei province
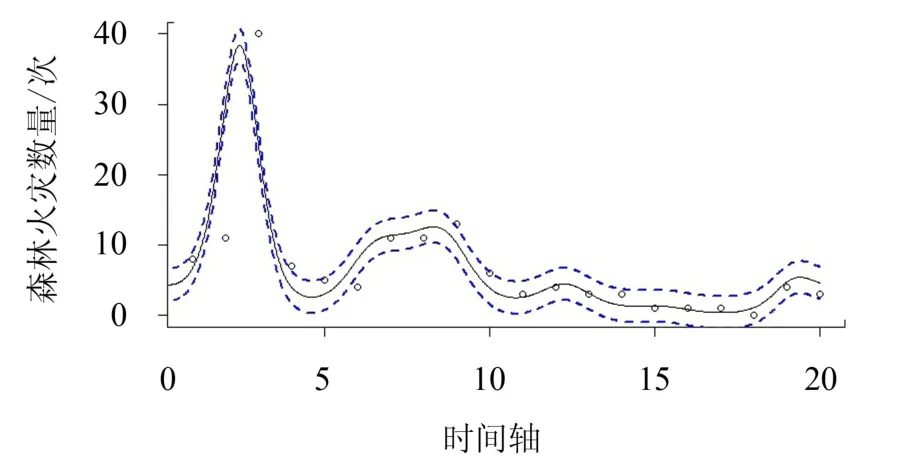
图3 北京市泊松分布拟合曲线Fig.3 Poisson distribution fitting curve of forest fire cases in Beijing
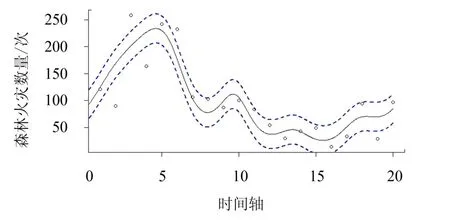
图4 黑龙江省泊松分布拟合曲线Fig.4 Poisson distribution fitting curve of forest fire cases in Heilongjiang province
2.2 南北方地区森林火灾的时间分布规律
在得到29 个省市的函数型泊松分布拟合曲线的基础上,分别对南方地区和北方地区的林火曲线进行函数型主成分分析.对南方14 个省市的林火曲线进行函数型主成分分析,结果显示前两个主成分的累计贡献率达到92.6%,解释能力分别为81.3%和11.3%.因此只提取前两个主成分进行解释就能得到大部分南北方地区森林火灾的时间分布规律.
从图5 可看出主成分对林火曲线变化的影响,其中实线为南方地区1998—2017 年林火发生次数的均值曲线,“+”和“-”分别为均值曲线加上和减去主成分的适当倍数后得到的曲线.从图5 可以看到,第一主成分的权重函数在2002—2009 年对林火的变化有显著影响,对林火整体变动的影响最大;而第二主成分的权重函数在1998—2002 年和2009—2011 年两个时间段内对林火整体变动的影响较为明显.
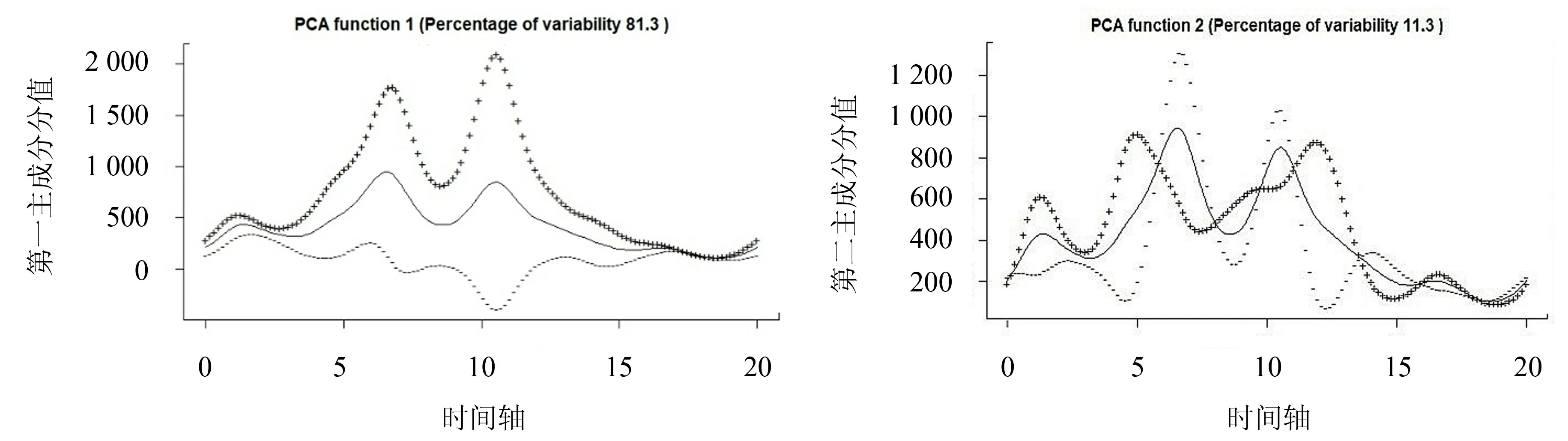
图5 南方林火均值曲线与主成分加减效应曲线Fig.5 The mean curve of forest fire in South China and the addition and subtraction effect curves by principal component analysis
从图6 可以看出,第一主成分曲线在1998—2017 年都大于0,在前5 年和后5 年都接近于0;而在第5年到第15 年间,第一主成分随着小幅度的波动处于一个全时段内的较高水平,反映了1998—2017 年南方地区森林火灾发生的变化程度.从图1~4 可看出,第5 年到第15 年间的拟合曲线波动较大,与第一主成分函数曲线的变化相符.由此得出南方地区在2003—2012 年间森林火灾的发生具有变动程度大、火灾发生情况不稳定的特点.而第二主成分的函数曲线图显示,第5 年到第15 年间曲线呈现上下大幅度波动的变化趋势,表明南方地区在2003—2012 年间的林火发生次数处于较大幅度增减的波动趋势.
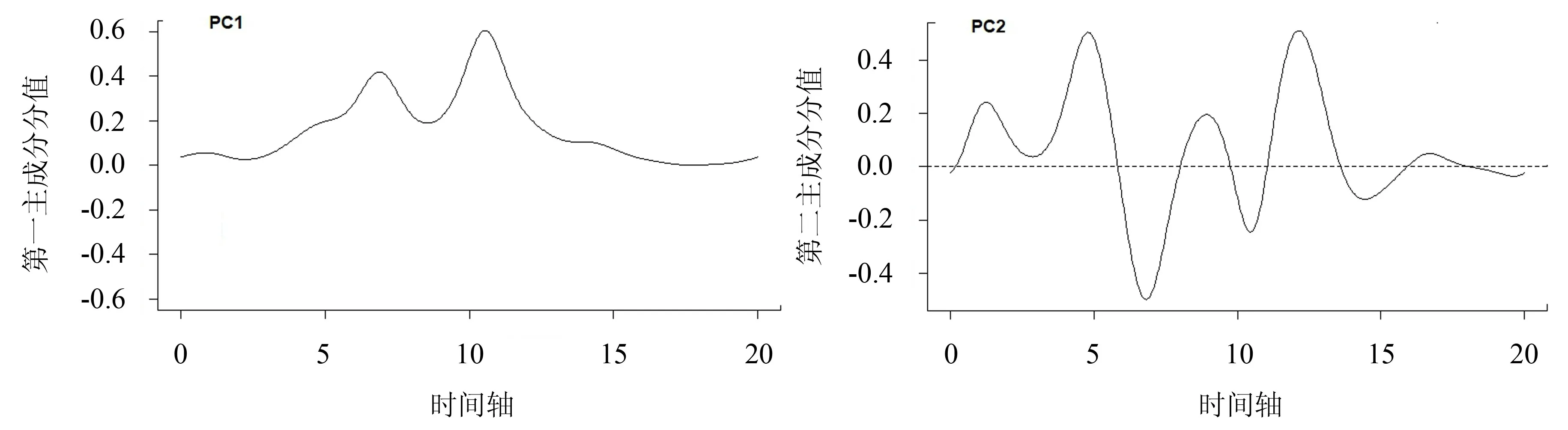
图6 南方林火数据的主成分分析曲线Fig.6 FPCA curve of forest fire in southern China
从图5、7 可看出,大部分省份在得分图上的分布较为接近,而湖南省在第一主成分上的得分最高.说明湖南省的林火变化与第一主成分的权重函数相关,即湖南省2002—2009 年林火发生次数变化最大;贵州省在第二主成分上的得分最高,说明贵州省的林火发生次数变化与第二主成分的权重函数相关,即贵州省1998—2002 年和2009—2011 年林火发生次数变化最为显著.
对北方15 个省市的林火曲线进行函数型主成分分析,结果显示第一个主成分的贡献率达到89.5%,因此只提取第一个主成分进行解释.
图8 是第一主成分偏离均值曲线的效果图.从图8 可以看到,第一主成分的权重函数在2003—2010年对林火的变化有显著影响,对林火整体变动的影响最大,通过绘制第一主成分的变化曲线进行研究.
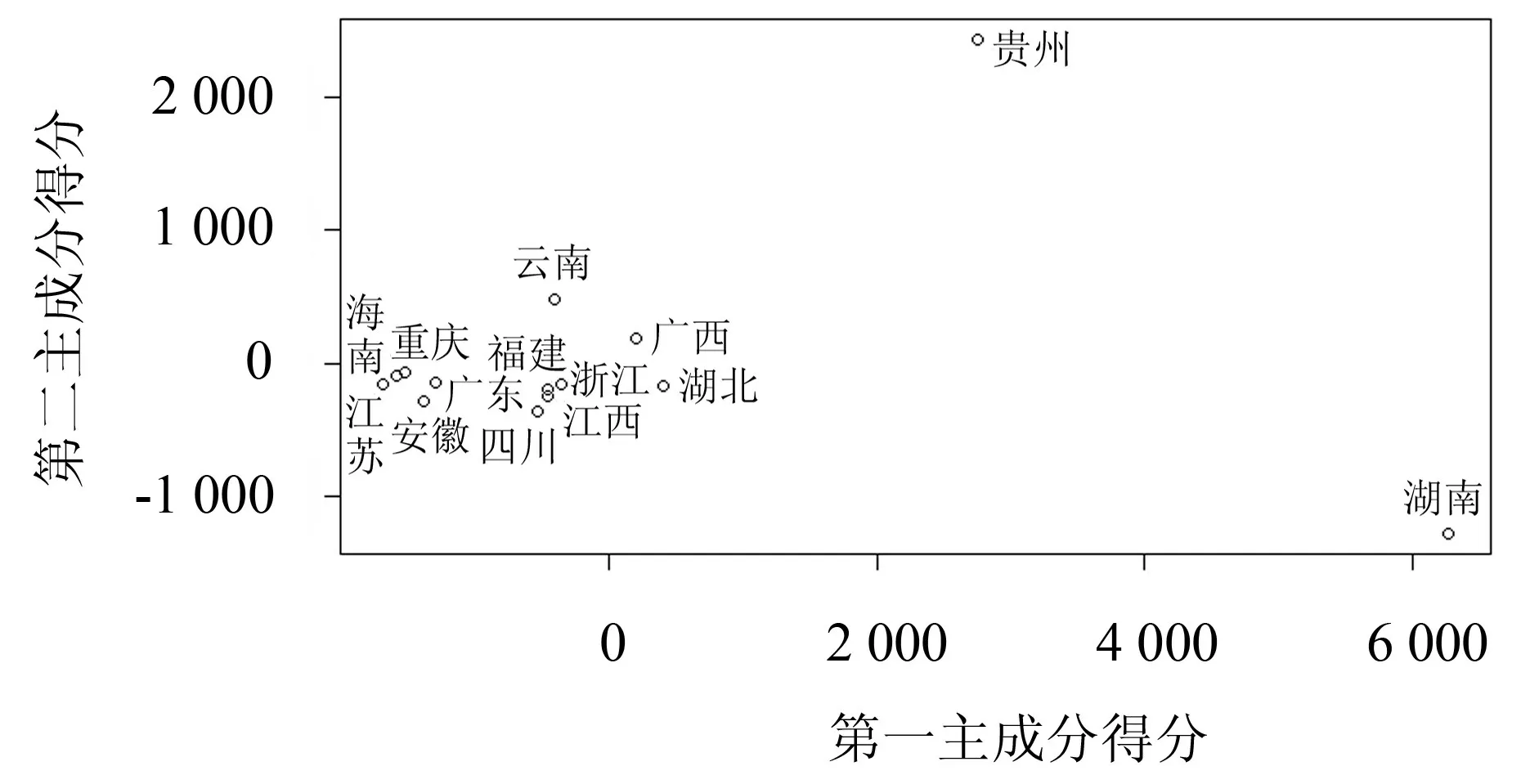
图7 南方省份主成分得分图Fig.7 Principal component scores of forest fires in the southern provinces

图8 北方林火均值曲线与主成分加减效应曲线Fig.8 The mean curve of forest fire in North China and the addition and subtraction effect curves by principal component analysis
从图9 可以看出,北方提取的第一主成分曲线与南方类似,在1998—2017 年都大于0;在第5 年到第15 年间,第一主成分出现小幅度的波动,处于全时段内较高的水平.表明2003—2012 年森林火灾的发生具有变动程度大的特点.然而,与南方地区不同的是,北方第一主成分的得分值较南方低,说明在同样时间段内北方林火发生的波动程度没有南方大.
从图10 可看出,河南省在第一主成分上的得分最高,说明河南省的林火变化与第一主成分的权重函数相关,即河南省在2003—2010 年林火发生次数变化最大,辽宁、内蒙古、河北省次之.
2.3 南北方地区森林火灾的空间分布特征
通过函数型聚类分析,将南北方各省份林火曲线分别划分为4 个和3 个典型区域.本文划分的各类聚类区域的林火级别标准与实际划分的林火级别标准不同.
根据拟合后的函数型林火曲线进行聚类,结果显示南方地区林火灾害的空间分布可分为如下4 类(见表2).
Ⅰ类( 蓝色曲线):林火级别最高,该区域内省份的林火灾害属于南方地区最严重一类.其中湖南省为南方地区林火灾害最严重省份,1998—2017 年共发生26 344 次林火,平均每年发生1 317 次林火,贵州次之.
图9 北方林火数据主成分分析曲线Fig.9 FPCA curve of forest fires occurred in northern China
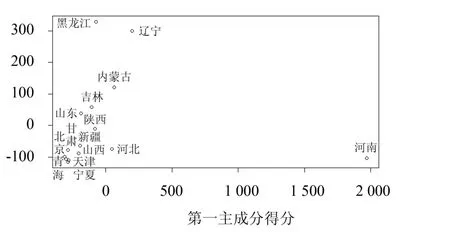
图10 北方省份主成分得分图Fig.10 Principal component scores of forest fires in the northern provinces
Ⅱ类(绿色曲线):南方中度森林火灾区域,包含广西、湖北、四川3 个省份,各省累计发生林火次数都在105次左右.从图11 可以看出该类别省份的林火变化趋势比其他3 个类别省份稳定,林火曲线保持在一个区间内上下波动,说明1998—2017 年3个省份的林火灾害无明显减轻或加重.
Ⅲ类(红色曲线):相对于Ⅰ类和Ⅱ类区域,该类区域的林火灾害程度较小,包含福建、江西、浙江、云南4 个省份,该类别包含的省份主要分布在华东地区.
Ⅳ类(黑色曲线):包含安徽、广东、海南、江苏、重庆5 个省份,这些省份属于1998—2017 年南方地区林火灾害程度最轻的类别,各省份累计火灾发生次数大多在3 000 次以下,林火灾害程度较轻.

表2 南方地区聚类结果1)Table 2 Clustering results of forest fires in southern China
根据拟合后的函数型林火曲线进行聚类,结果显示北方地区林火灾害的空间分布可分为如下3 类(见表3):
Ⅰ类(红色曲线):北方地区林火灾害最严重一类,且从图12 可以看出,该类地区灾害程度远大于Ⅱ、Ⅲ类地区,主要包含河南、内蒙古、辽宁、黑龙江4 个省份.其中河南省为北方地区林火灾害最严重省份,1998—2017 年共发生7 917 次林火,平均每年395次.而Ⅰ类地区的其他3 个省份的林火次数都只有2 000 余次.
Ⅱ类(黑色曲线):北方中度森林火灾区域,包含山东、山西、陕西、新疆、河北、吉林6 个省份,各省1998—2017 年累计发生林火次数都在2 000 次以下.

表3 北方地区聚类结果1)Table 3 Clustering results of forest fires in northern China
Ⅲ类(绿色曲线):相对于Ⅰ类和Ⅱ类区域,该类区域的林火灾害程度最轻,各省1998—2017 年累计林火发生的次数都小于300 次,主要包含甘肃、青海、天津、北京、宁夏5 个省份,主要分布在西北地区.
南北各省份林火曲线的动态聚类结果与主成分得分图的结果相符,即在主成分得分图上较为靠近的散点更容易聚为一类.聚类结果显示,南方各个类别地区的林火发生在整个时间范围内的变化情况大致相同,均呈现下降趋势.而最后4 条类别的曲线都呈现不同幅度的上升趋势,说明研究时段内南方地区林火发生有所减少,但近3 年来林火发生出现反弹.南方地区4 条类别曲线对应的林火发生次数多于北方地区,说明南方地区的森林火灾防范形势较北方严峻.
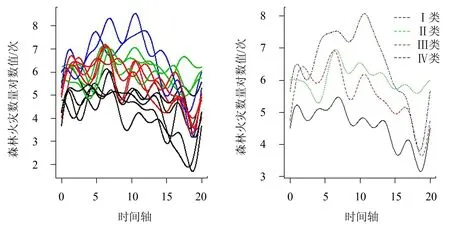
图11 南方14 省函数型聚类图Fig.11 Functional clustering diagram of forest fires in 14 southern provinces
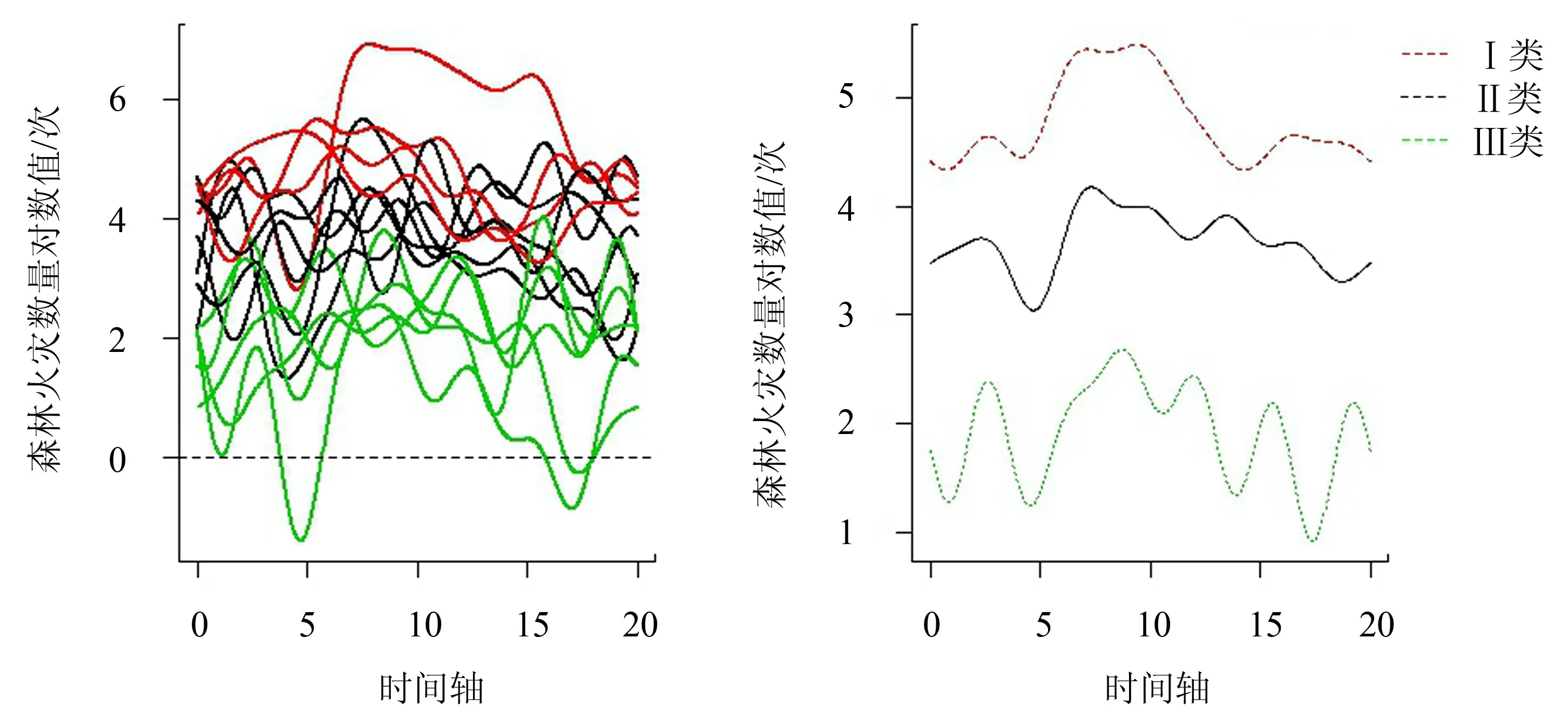
图12 北方15 省函数型聚类图Fig.12 Functional clustering diagram of forest fires in 15 northern provinces
3 小结与讨论
本文应用函数型数据分析方法,结合林火数据特征,将我国29 个省市1998—2017 年(共20 年)的森林火灾次数拟合成光滑的函数型曲线,进一步分别对南北方地区林火曲线进行函数型主成分分析,研究南北方地区森林火灾数量的变化规律及各省份林火数量特征.此外,利用函数型聚类分析对南北方地区进行动态聚类,分析南北方地区森林火灾的空间分布特征,结果表明:南北方地区森林火灾发生在2003—2012年,具有变动程度大、火灾发生情况不稳定等特点;但南方地区林火发生的波动程度较北方更加显著,其中,湖南省、贵州省、河南省分别在2002—2009 年、1998—2002 年、2009—2011 年、2003—2010 年林火特征最为显著,变化最大.在空间分布上,函数型聚类分析结果表明,南方地区和北方地区按林火严重程度可分别划分成4 类和3 类典型区域,且南方地区整体的森林火灾形势较北方严峻.本文得到的结果与苏立娟等[20]及张颖等[21]的分析结果较一致.但河南省的聚类结果存在差异,一是因为对其他灾害指标的考虑以及研究年限等不同;二是河南省在研究时段的前5 年与之后年限的林火曲线有十分明显的变化差异,由于函数型聚类过程不是基于离散静态数据,而是一种连续动态的聚类过程,从而造成了聚类结果上的差异.
通过本研究结果能够了解南北地区一定时段、区域内火灾的整体变化情况,并对各省份林火情况进行分级分类,为林火预防预报、开展科学的林火分区管理提供更加详细的数据.
猜你喜欢
当代水产(2022年3期)2022-04-26
———《中原北方地区宋金墓葬艺术研究》评介
美育学刊(2021年4期)2021-08-10
现代计算机(2021年7期)2021-05-12
小学阅读指南·低年级版(2021年4期)2021-04-20
中国新闻周刊(2020年6期)2020-03-08
中国经济周刊(2018年31期)2018-08-14
决策探索(2017年11期)2017-06-23
安徽农学通报(2015年10期)2015-06-15
