
机器学习在红外光谱沥青品牌识别中的应用
2021-02-04 08:30马子嵘
分析仪器 2021年1期
马子嵘
(福建省交通科研院有限公司,福州 350004)
1 引言
改性沥青是在基质沥青品质基础上的改性,性能优良的基质沥青是改性沥青路用性能优良的重要保障。在沥青生产方面很少有造假现象,但经过第三方“二次加工”的改性沥青则不一样。由于最终用户仅接收成品改性沥青,对基质沥青无法监管,以次充好、勾兑造假以及品牌造假等现象频现。目前检测单位一般只对到场的改性沥青检测,而对基质沥青的真假伪劣情况无从知晓,难以管理。
为了保证沥青路面质量,更好地服务公路建设发展,通过技术手段实现对基质沥青品牌的识别具有十分重要的现实意义。红外光谱技术能够对材料物质结构特性进行便捷、快速、高效的研究分析。近年来,该技术被广泛应用于沥青材料的研究上。
2 目标与试验方法
2.1 目标
各种化合物都具有其特征的红外光谱,沥青也不例外,可以通过对其的特殊官能团红外光谱分析进行定性分析和定量测定[1,2]。通过对不同品牌沥青的红外测试,开展谱图数据库建设工作,建立沥青红外指纹谱图快速检测系统,用于识别沥青品牌,避免沥青品牌假冒、混兑调和、以次充好的问题。
2.2 仪器设备
采用德国布鲁克TENSOR Ⅱ型红外光谱仪与纯金刚石晶体ATR配件。在红外谱图绘制方面采用OPUS软件。
2.3 试验方法
使用ATR配件,将沥青样品用不同方式制成厚薄较均匀的薄膜状,直接置于设备的测量窗上进行测试。试验中总共采用了固态压膜成型法、溶剂法与熔融成膜法3种方法。最终确定采用第三种方法即熔融成膜法进行。具体方法为:将沥青样本135℃加热搅拌均匀后,放至70℃烘箱内保温待用。加热金属样品匙,在不同取样位置,点取沥青并均匀涂抹在金刚石样品窗上后,进行测试[3]。
采用该法进行沥青样本的红外谱图绘制,整个测试过程步骤少,操作简单;一次试验后采用煤油与无水乙醇进行清洁试验窗与样品台的工作,安全便捷;试验背景单一,即背景的差异性对沥青样本的红外谱图数据影响非常小;试验中仅需要考虑水汽与二氧化碳的影响即可。从结果上看,测试的精确度很高,重复性与复现性好。
3 数据处理
3.1 数据获取
实验室收集了多种品牌大量的沥青样本。对每个样品在5个不同位置取样,进行4000 cm-1~400cm-1波段的测试,绘制红外谱图。
3.2 数据分析
仪器输出的红外光谱图,横坐标为波数,总计2520个波数,纵坐标为吸光度。全谱吸光度样本量:110×5,即550个样本,特征量即波数,2520个。
从红外光谱图来看,各品牌沥青无法通过人眼进行区分,需要借助数据分析算法实现品牌鉴别。同时,样本数据集不均衡,4个品牌沥青的样本量分布为70∶17∶10∶3,绝大多数常见的机器学习算法对于不平衡数据集都不能很好地工作,分类判决总会倾向于多数类,导致了对少数类样本的识别率低下;另外该数据集呈现出明显的低样本高特征量的特征,特征量为2520个,是样本量的4.58倍,导致无法使用通用的分析工具如SPSS直接建模。
针对上述问题,解决方案如下:
使用Octave软件进行数据的处理、分析工作;
采用特征构造的方法实现降维,对原始特征进行优化、组合,将组合后的特征作为新特征输入模型。拟采用的两种特征构造方法为:主成分分析(PCA)、峰面积替代特征峰数据;
采用分类器集成的方式,即通过结合多个分类器的输出,来增强分类器准确率;
将多分类问题,即原来的四分类问题转化为二分类问题,属于A品牌的归为正类,其他类归为负类。
3.3 数据处理
3.3.1波段积分计算峰面积,生成峰面积样本数据集
运用光谱仪自带的OPUS软件,针对沥青选取了10个特殊峰段,如“2990-2878”、“1636-1546”、“825-787”等峰段采用A、B两种方法进行积分计算,得到峰面积结果。结果大量数据分析,A方法比B方法的差异性更大,对不同沥青有更强的判断能力,最终应用A方法来处理。
3.3.2使用Z-score标准化方法对数据进行归一化处理。3.3.3主成分分析,对原始特征进行降维重构
S_lambda(i)>= 0.99,计算结果K=9,即提取前9个新的特征代替原始特征,累积贡献率分别为:0.69447、0.91346、 0.93802、0.95825、0.97033、0.97897、0.98389、0.98746、0.99018。
3.3.4将样本数据集按7∶3的比例随机划分训练集、测试集
经过数据预处理,得到6份数据集:吸光度训练集、吸光度测试集;吸光度PCA训练集、吸光度PCA测试集;峰面积训练集、峰面积测试集。
4 机器学习模型及应用
4.1 目的
在对现有样本建模的基础上,找到可以进行品牌准确分类的模型。当新样本入库时,能够快速鉴别其品牌属性。
4.2 建模思路
多个分类器集成的方式,对适用的分类器算法逐一进行训练、测试。根据训练集、测试集的准确率,进行初步筛选,剔除欠拟合或过拟合,且无法调优的模型;再对保留下来的分类器算法进行集成。
4.3 模型选择及构建
初步选定8个模型:基于吸光度PCA数据的逻辑回归、多项式逻辑回归模型、神经网络模型、FISHER判别分析模型;基于峰面积数据的多元线性逻辑回归模型、多元非线性逻辑回归模型、FISHER判别分析模型;考虑到神经网络作为近年来发展最快速的机器学习模型,具备较强的学习能力,能够支持低样本高特征量的数据集,因此尝试对原始特征即基于吸光度数据建立神经网络模型[4-6]。
神经网络模型:采用3层神经网络,即两层隐藏层+一层输出层。其中隐藏层的神经元数量作为超参数,在建模过程中进行调优,输出层神经元数量为1;激活函数采用sigmoid函数。因为样本量较少,直接使用全样本批次梯度下降算法,优化网络参数。
逻辑回归模型:逻辑回归(Logistic Regression)是机器学习中的一种分类模型,由于算法的简单和高效,在实际中应用非常广泛。首先,生成特征量的线性函数;其次,将其作为sigmoid函数的参数建立相应的决策函数,当计算结果大于等于阈值,视为正类,否则为负类;最后通过梯队下降算法进行参数求解。通过逻辑回归分析,可以判别一个新样本属于A品牌的概率。
多项式逻辑回归模型:在逻辑回归模型的基础上进行改进,尝试增加模型容量,即提升算法的复杂度,为样本添加二项式特征项。
FISHER判别分析模型:在已知研究对象分成若干类型,且已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,确定的原则是使两类间的类间离差最大,而类内离差最小;当建立了判别式以后,可以将新样品的特征值代入判别式求出Y值,然后与判别临界值对比归类。
针对神经网络、逻辑回归模型,均采用梯队下降算法进行参数求解。模型中涉及的超参数分别有神经网络层数、隐藏层神经元数量、正则化了λ、分界阈值。本文采用验证集训练以上超参数,最终确定的超参数为:神经网络隐藏层为2、神经元数量为5、正则化λ依次为0.005(吸光度PCA+神经网络)、0.01(吸光度神经网络)、0.01(峰面积逻辑回归)、1(峰面积多项式逻辑回归)、分界阈值为0.7。
4.4 模型评估
经过训练、验证和测试,最终生成8个模型的准确率,见表1。
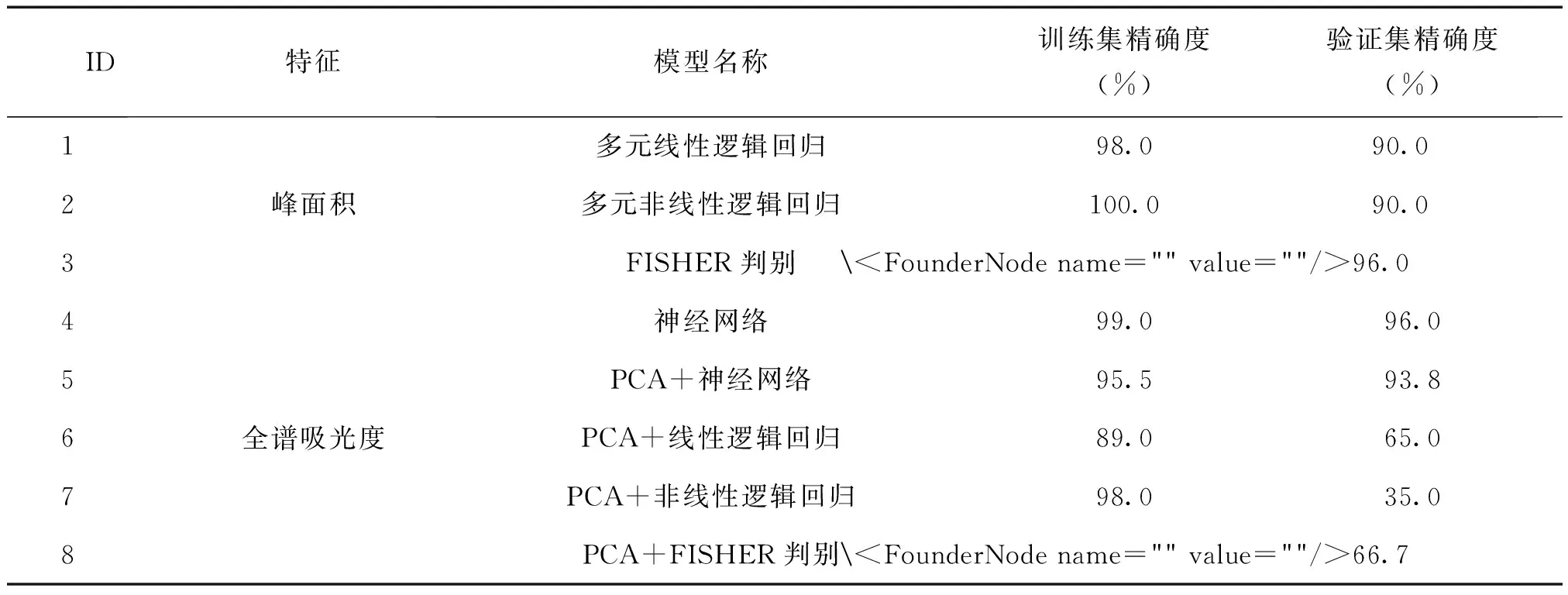
表1 模型评估
吸光度PCA的逻辑回归模型训练集准确率为89%、验证集为65%,吸光度PCA的FISHER判别模型准确率仅为66.7%,模型欠拟合,不予采用;
吸光度PCA的多项式逻辑回归模型,训练集准确率达到98%,验证集仅为35%,说明该模型出现过拟合,只有继续需要增加样本量才能进行优化;
其它5个模型均有不错的表现,训练集、验证集准确率均较高。因此将这5个模型进行进一步的集成。
4.5 分类器集成
分类器集成即通过构建并结合多个学习器来完成学习任务,也被称为多分类器系统。可以获得比单一学习器更加显著的泛化性能。
一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。结合策略主要有平均法、投票法和学习法等。本文要解决的是分类问题,因此使用投票法选择输出最多的类,即少数服从多数。
4.6 模型应用
建模完成后项目组先后收集了两次共计10个沥青样本,每个样品依例在5个不同位置取样,编制盲样进行红外光谱绘制,并采用以上5个分类器集成的模型进行分类,输出结果均与实际值一致,准确率达到100%。
5 结论及发展方向
采用红外光谱分析技术和机器学习算法,对入库沥青进行特征提取及品牌识别。经过模型验证,机器学习算法能够正确识别沥青品牌。在实际应用环境中能够发挥打击不良商家,保护正规厂商利益的作用,同时避免客户使用假冒伪劣产品,确保工程质量。
但是沥青品牌众多,样本的收集需要与沥青厂商直接对接,且市面上没有沥青品牌开放数据库,样本数据的收集具有一定的难度。因此,后续会在逐步收集、完善各品牌沥青谱图数据库的同时,进一步探索小样本量特别是单样本量的品牌鉴别模型,借鉴目前深度学习较为成熟的人脸识别领域中的一次学习算法,在下阶段多品牌小样本的条件下,尝试探索Siamese网络在沥青红外光谱品牌识别方面,进行迁移学习的可能性。
猜你喜欢
电子测试(2022年16期)2022-10-17
环球时报(2022-05-23)2022-05-23
金桥(2021年4期)2021-05-21
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
汽车电器(2019年1期)2019-03-21
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
中国光学(2015年5期)2015-12-09
航天返回与遥感(2014年5期)2014-07-31
