
基于池化的双维度视觉注意力模型*
2021-02-11 12:34张万玉张文娟邹品荣王晨阳
西安工业大学学报 2021年6期
张万玉,肖 锋,张文娟,邹品荣,王晨阳
(1.西安工业大学 计算机科学与工程学院,西安 710021;2.西安工业大学 基础学院,西安 710021;3.西安工业大学 兵器科学与技术学院,西安 710021)
卷积神经网络(Convolutional Neural Network,CNN)已经广泛地应用到图像分类、目标检测和语义分割等各种计算机视觉任务中。近年来,许多研究者[1-2]开始研究如何在现有CNN的基础上进一步提升网络性能和信息感知表达能力,一方面,从LeNet[3]到VGG[4]再到Residual风格[5-8]的网络通过不断堆叠重复的卷积模块或者使用残差块(residual block)的网络加深网络深度,从而捕获更多图像的表达信息。另一方面,考虑到CNN局部感受野自身的不足,许多工作从多尺度信息融合的角度入手,GoogLeNet[9]在同一层使用不同大小的卷积核,从而获取到不同感受野的信息;Res2Net[10]通过使用等级制度的方法,能更好表示多尺度的信息,使得网络能够获得更加颗粒级别的信息。此外,文献[11-13]使用膨胀卷积(dilated convolution)和分组卷积(group convolution)来对卷积网络进行改造,膨胀卷积在不增加池化操作的情况下,获得了更大的感受野信息,而分组卷积则是借鉴AlexNet[14]的工作,把卷积计算的操作分组执行,使得在保持网络基本性能的前提下,计算量显著减少。然而,尽管基于残差连接的方式能够在一定程度减少梯度消失和梯度爆炸的出现,但通过不断堆叠卷积来获取更多、更丰富的特征信息,实际上是一种不够高效的方式。此外,基于多尺度融合的方式,有时需要人为手动设计的卷积核的大小,以保证其对特定任务有较好的性能提升。
认知科学中指出,大脑可以有意或无意地从大量输入信息中选择小部分有用信息来重点处理,弱化其它冗余信息,从而将有限信息处理资源分配给重要的任务,这种具有选择的视觉能力称为视觉注意力机制。CNN在进行卷积操作之后,通道维度可以帮助网络获取不同物体的特征信息,即“看什么”;空间维度获得位置上的依赖信息,即“在哪看”。将视觉注意添加到“看什么”“在哪看”两个维度上,可以在获得较好网络性能的同时,获得更好的信息表达。因此,针对经典网络结构改进视觉注意力机制的方法不断涌现[15-17],SENet[18]提出一种自适应的重新标定特征通道上响应的方法,有差别地关注不同通道间的信息;ECANet[19]在SENet的基础上,提出一种自适应地捕获局部通道间关系的方法,并去除了瓶颈层设计。然而,它们只考虑了通道维度上的信息,而缺少空间维度上的信息。NLNet[20]提出通过自注意力(self-attention)的方式来捕获全局的信息,从而使得生成的新的像素值不只与局部的信息有关;CCNet[21]使用十字交叉的方式,显著地减少了自注意力机制下的参数量,且能够通过循环操作实现全局信息的捕获。这两种方法只利用了空间维度信息,而未对通道维度上的信息进行关注。CBAM[22]和BAM[23]同时关注了两个维度,使得注意力机制捕获的信息更加完整,但对于空间维度都仅仅考虑局部范围内的信息,缺少更加全局的空间信息;对于通道维度,捕获了较多冗余的通道信息,增加模型复杂度。
本文提出一种基于池化的双维度视觉注意力模型,使用Embedding池化的方法增强通道注意力机制聚合空间信息的多样性和优化空间自注意力机制捕获全局信息的计算方式,提升网络的表达能力,聚焦与目标物体有关的特征信息。
1 模型架构设计
1.1 模型整体架构
图1给出了通道和空间注意力模型(Channel and Spatial Attention Module,CSAM)。
当在CNN网络中输入一张特征图F∈RC×H×W,C、H和W分别表示特征图的通道数、高和宽。CSAM能够顺次得到通道注意力Ac∈RC×1×1和空间注意力As∈RC×H×W。整体的注意力计算流程如式(1):
F′=Ac(F)*F
F″=As(F′)*F′,
(1)
其中,*表示对应元素的点乘操作,计算F′时,默认使用了广播机制,使得计算过程中保证了计算维度的一致性,F″为CSAM最终的输出特征图。
1.2 通道注意力模块
在CNN网络中,不同的卷积核提取图像中不同特征,如:纹理、边缘等,因此不同通道下显示信息的特征表示具有明显的差异性。通过提取CNN中浅层网络通道特征,并进行可视化,如图2所示。由图2看出,特征图中每个通道能够捕获图像中物体的不同特征,但在实际任务中,只有部分重要的特征会直接影响最终目标的效果,因此在进行视觉任务时,应该重视特征图中反应图像特征的通道,对显示图像特征较少或较弱的通道予以较少的关注。
对经典的SENet通道注意力机制模型进行分析,发现其存在两点不足:① 对空间信息的聚合只使用了全局平均池化信息,缺少对全局多样性信息的表达。② 全连接网络的引入自然而然地丢失了注意力权重的准确性。SENet结构如图3所示。

图3 SENet 网络结构
本文在全局平均池化聚合空间维度(RH×W)信息的基础上,增加了全局最大池化来获取更多显著性的特征,使网络既能表示更多全局的信息,又能关注到最显著的特征,综合提升了信息聚合时的多样性表达[24-26]。
全局最大和全局平均池化的计算方法为
qc=max(uc(i,j)),
(2)
(3)
其中,i∈(1,H),j∈(1,W),c∈(1,C),qc表示全局最大池化后的结果;Zc表示全局平均池化后的结果;uc表示输入特征图。
对于SENet池化后学习通道注意力权重的共享层,通过使用一个简单的局部通道连接(一维卷积)的方式进行替代,使得每一个输出通道的注意力权重只与局部通道响应,有效地消除了注意力权重不一致的问题。为了更进一步验证更加准确的通道注意力权重,选择单独为每一个通道建模一个可学习的权重参数,但实验证明其性能差于局部通道的连接方式,详细的实验结果见表2。通道注意力模块设计如图4所示。
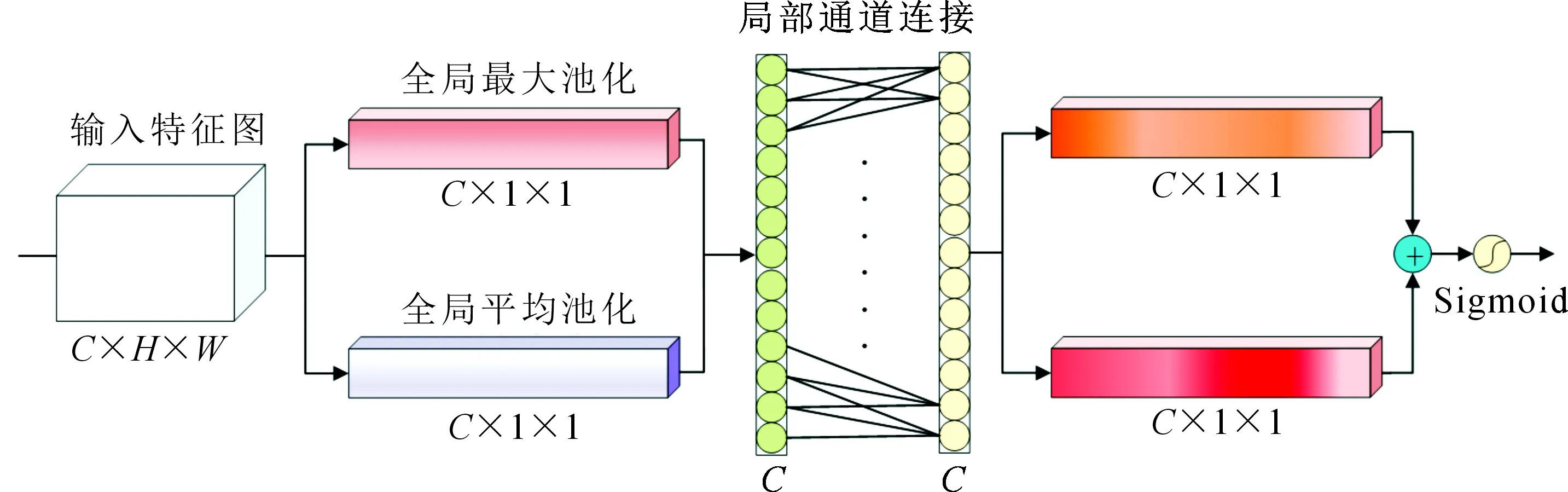
图4 通道注意力模块
通道注意力模块计算的整体流程如下:
Ac(F)=Sigmoid(1Dk(GlobalAvgPool(F))+
1Dk(GlobalMaxPool(F)))
(4)
其中,1Dk表示一维卷积操作,下标k表示一维卷积核的大小,即自适应局部通道的个数。
对于k值的选择,为了能使网络能够实现自适应的根据网络不同的通道数选择相对应的近邻值k。建立一个通道数目C值与k值之间的线性函数C=k×α+β,考虑到通道数C的取值一般为2的倍数,因此将线性函数变换为:C=2k×α+β。通过计算得到有关于k的表达式为
(5)
式中:下标odd表示所选k值要保证为奇数,α和β的取值分别设定为2和1。
最终,模型会在训练过程中根据相应网络的通道数值对k值进行自适应地调节,实现自适应地捕获局部通道间的相关关系。W∈Rk为不同类型的全局池化操作后共同享有的参数,即一维卷积核的参数。Sigmoid函数表示计算相应通道的注意力权重,能将权重数值映射到[0,1]区间内,使其表示为一个概率数值,从而能够起到注意力门控的功能,其计算表达式为
(6)
式中S(x)为输出响应;x为输入。
1.3 空间注意力模块
当人们观察一幅图片时,大脑视觉皮层会自觉地对图中感兴趣的区域响应更多的刺激信息,致使眼球视野聚焦在这部分区域,形成空间注意力。如图5所示(感兴趣目标为手套):

图5 空间注意力的表示
在CNN中,空间注意力的形成主要通过重新标定特征图空间位置上的权重分布来实现。然而,调整空间位置上的权重需要有效地扩大CNN的感受野区域,使网络能够考虑到更多不同位置上的信息。视觉自注意力机制能实现对每一个位置计算全局的相关关系,使得生成的新特征点包含了全局的信息,但暴力地计算所有位置上的全局信息,增加了网络模型的参数运算量,其计算复杂度为O((H×W)2),计算方式如图6所示。

图6 空间自注意力计算
通过池化方法优化视觉自注意力机制,将计算复杂度减低到O((H×W)(H+W-1))。在池化方法的选择方面,为保留更多的局部语义信息,使得待池化的特征都具有一定的贡献能力,选择平均池化的操作。而最大池化则会关注局部更显著的特征,弱化对局部多种特征信息的表达。
1) 在空间维度W和H上分别使用平均池化操作,使网络获得相应维度下的空间Embedding信息,整个计算过程中保证通道维数C不变。
空间维度H与W的平均池化操作计算为
(7)
(8)

2) 把池化后的特征图维度扩展(保证相对位置上数值不变,横线或纵向进行扩展)到原始输入特征图大小(RC×H×W),特征图AW∈RC×1×W和AH∈RC×H×1进行维度扩展的操作如图7所示。
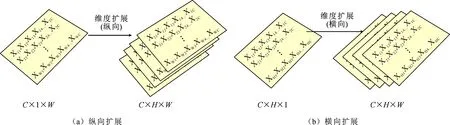
图7 维度扩展
3) 将两个分支上所获取的信息进行特征融合,即进行相同位置逐元素相加的计算,使生成的新像素点包含先前在此位置水平和垂直维度上的信息,丰富特征信息的来源。
4) 为了获取某一位置更加全局与丰富的空间语义信息,仅需对空间注意力模块进行一次重复堆叠,便能获得某位置全局上下文的信息,使用Sigmoid函数计算得到空间位置的注意力权重。子模块的详细组成结构如图 8所示。

图8 空间注意力模块
空间注意力模块的整体计算流程如式(9)
As(F)=Sigmoid(Conv1×1(expand(AvgPoolh(F))+
expand(AvgPoolw(F))))

(9)
其中,AvgPoolh、AvgPoolw分别表示在空间维度(RH×W)的子维度h、w上对应的平均池化操作;f代表卷积操作,1×1卷积[27]表示对通道维度进行缩减;E表示对应维度上的扩展运算(维度扩展);Sigmoid实现权重放缩,计算表达式如式(6)。
1.4 注意力模块的连接
从空间维度和通道维度分别进行注意力模块化的设计,使网络能够同时兼顾两个维度上的注意力信息。有效地连接双维度下所获取的视觉注意力信息,是更好地提升模型视觉表达能力的关键。两个维度下的连接形式共有三种:先通道后空间、先空间后通道和空间通道并行。
通过实验验证了先通道后空间的连接方式具有更好的效果,因此选择其作为模型最终的连接形式。这种连接方式也表明文中所设计的模块倾向于先注意到具体的目标对象,再对其所在位置给予关注。详细的实验分析在消融实验中体现,如图9所示。

图9 模块连接方式
2 实 验
通过进行消融实验,对模型设计的合理性和准确性进行验证。针对图像分类任务,对CSAM模型进行评估。使用CIFAR-100标准数据集,在骨架网络ResNet[5]和ResNeXt[8]网络上分别对提出模型的泛化能力进行了定量分析,与先前较优的视觉注意力模型进行了性能上的对比。最后,实施了进一步的可视化实验,比较了设计模型与其它注意力模型之间的注意力区域聚焦能力。
2.1 实验详情
2.1.1 数据集
CIFAR-100数据集包含100个类别的60 000张32×32彩色图像。训练集和测试集分别包含50 000张和10 000张图像。对于该数据集,采用随机裁剪的标准数据增强方法,该方法采用4像素填充和水平翻转。对于预处理,使用RGB平均值和标准差对数据进行归一化。
2.1.2 训练策略
网络参数通过随机梯度下降(SGD)进行优化,其中权重衰减为1e-4,动量为0.9,并设定了初始学习率为0.1。对于ResNet-50的训练,选择批量大小为64,在200个epoch内完成网络的训练,分别在100、150个epoch时,对学习率进行0.1倍速率衰减。对于ResNeXt-50和ResNeXt-101网络的训练,选择批量大小为128,在100个epoch内完成网络的训练,每隔30个epoch进行0.1倍的学习率衰减。
2.1.3 运行环境
所有程序均由PyTorch1.4[28]实现,CUDA版本为10.1,且在装有两个GeForce GTX 1080GPU的PC上运行,运行操作系统为Ubuntu 16.04。
2.2 消融实验
2.2.1 模块连接方式
提出的注意力机制模型是基于两个维度考虑,而双维度下的模块连接形式共有三种,除了如图1所示本文采用的先通道后空间的连接方式外,其它两种连接方式如图9所示。
比较了不同连接形式下的分类准确率。实验上选择ResNeXt-50作为消融实验的骨架网路和基准线,将三种组合形式添加到骨架网络中进行训练、评估,最终得到的消融实验结果见表1。

表1 不同连接下的准确率
Com1表示图 9(a)中的结构,Com2表示图 9(b)中的结构。由表1看出,CSAM分类准确率明显高于基准线,而在另外两种组合下,其效果均低于基准线水平。因此,本文最终选择如图1所示的先通道后空间的连接形式,从实验上佐证了CSAM组合方式选择的合理性和准确性。
2.2.2 共享MLP设计
在通道注意力子模块中考虑了不同共享层的设计,为了能够定量地分析共享层设计选择的合理性,比较了三种不同的连接形式:瓶颈层(Var1)、局部自适应通道连接以及Var2。瓶颈层、局部自适应通道连接如图 10所示。Var2直接将两种池化后的结果进行融合,不设置共享层。

图10 共享层的连接方式
通过消融实验证明,采用局部通道连接方式的性能不仅优于基准线网络(ResNetXt-50),而且对于另外两种形式(Var1和Var2)也有明显的提升。因此,有效的局部自适应通道连接能够在一定程度上提升网络的性能,进一步证明了模型设计的合理性。实验结果见表2。

表2 不同共享全连接方式准确率比较
2.3 图像分类
针对标准图像分类任务,实验中选择了经典的残差系列网络。ResNet和ResNeXt作为实验中的两种不同类型的骨架网络,并与State-of-the-art的注意力机制模型SENet、TANet[29]、CBAM、ECANet和BAM进行比较。为体现实验的公平性,所有注意力模块的测试均在相同的实验条件下进行,且在骨架网络中添加的位置相同。
注:加粗字体为每列最优值。
1) 将以ResNet网络为骨架网络添加提出的注意力机制模型和添加其他注意力机制模型后的收敛性能比较。由于ResNet-101网络参数量大,硬件性能不足,故只给出深度为50层网络的比较结果。训练过程中的Top-1泛化误差曲线如图11所示。

图11 ResNet-50在不同注意力模型下的Top-1泛化误差
由图11结果表明,添加提出的注意力机制模型后的收敛性较骨架网络ResNet网络显著提升,一定程度上优于其他注意力机制模型。而进一步在测试集上计算各比较模型的Top-1和Top-5准确率。添加CSAM模型的准确率分别为79.7%和95.22%,均优于基准线和其它注意力模型。实验结果如图 12所示。
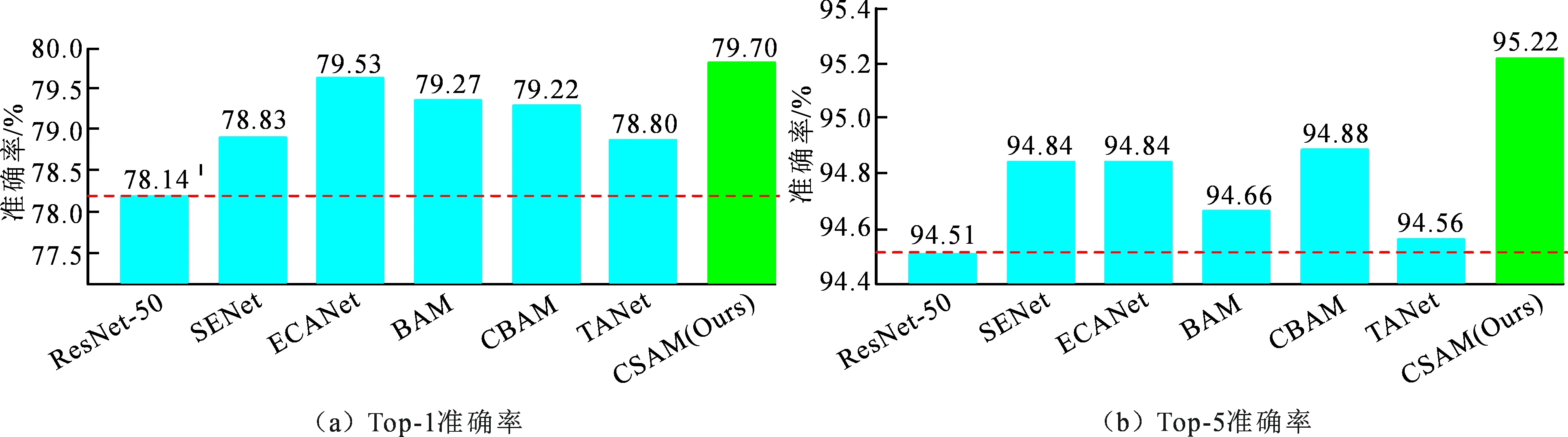
图12 ResNet-50在不同注意力模型下的准确率
2) 为进一步验证提出模型对不同骨架网络的泛化能力,使用ResNeXt作为新的骨架网络,并选择了50层和101层来对比不同深度下提出模型对骨架网络性能的提升情况。实验结果如图13所示。

图13 不同骨架网络与注意力模块下的Top-1泛化误差
实验结果表明在不同深度下,添加提出视觉注意力机制模型都能有效提升网络性能。
3) 在测试集上计算了对应模型的Top-1和Top-5准确率,其中CSAM对应的准确率分别为59.65%、83.94%和59.36%、84.24%,均优于基准线和其它注意力模型。实验结果如图14~图15所示。

图14 ResNeXt-50在不同注意力模型下的准确率

图15 ResNeXt-101在不同注意力模型下的准确率
2.4 Grad-CAM络可视化
为了能够定性地分析本文所设计模块性能的优越性,使用来自CIFAR-100验证集的图像,将Grad-CAM[30]应用到不同的注意力机制网络。Grad-CAM作为一种网络可视化的方法,通过计算梯度的方式来定位图像在空间位置中的重要性,有助于进一步理解模型的判别依据。通过查看可视化后的聚焦区域来定性的比较CSAM与基准线网络和其它注意力模块之间的区域感知或聚焦能力。实验挑选了在ResNet-50骨架网络下可视化效果不够好的图片作为参考依据,实验可视化的结果如图16所示。
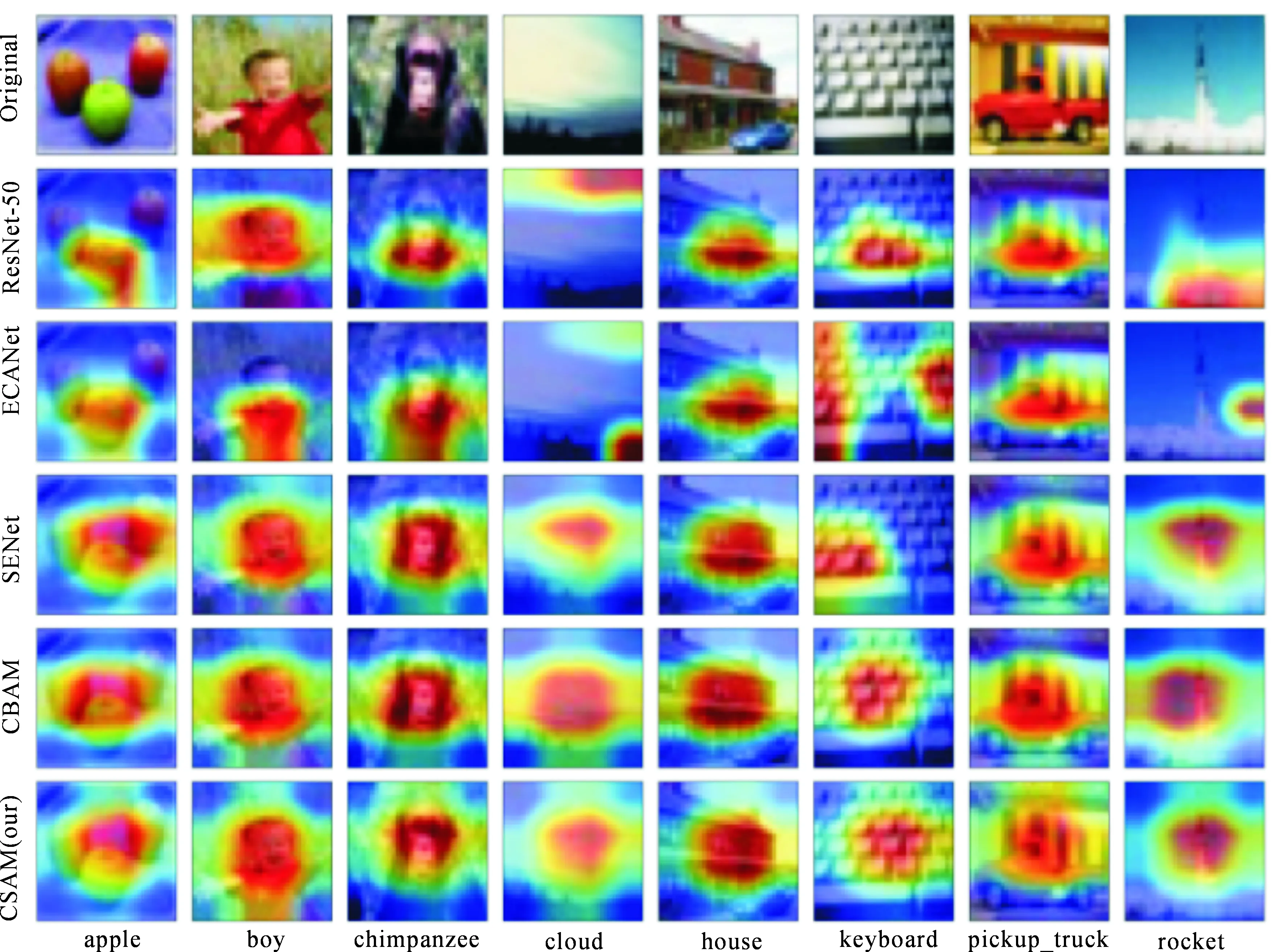
图16 Grad-CAM可视化
由图16可以看出,原始的ResNet-50网络所判别物体的感知区域不够聚焦,或者聚焦了一些冗余的信息,并将这些信息作为最后的判别依据。而其它注意力机制模块,如CBAM和SENet尽管对物体区域感知更加聚焦,但还是存在一些冗余的信息。此外,改进的ECANet尽管有较好的分类准确率,但在可视化所感知的区域明显差于其原模型SENet。但本文提出的CSAM模型,既能够聚焦于感知目标在图像中的区域位置,又能够减少对冗余信息的捕捉,进一步验证了提出模型性能的优越性。
3 结 论
探索并发现图像更加丰富的表达能力是CNN的主要目的之一。从视觉注意力机制的角度出发,提出了一种基于池化的双维度视觉注意力机制。通过在不同维度上优化池化方法获取有效注意力信息的方式,使网络既能知道“看什么”,又能知道“在哪看”。
结果表明,模型在分类任务(CIFAR-100)上表现良好,与主流的视觉注意力模型对比:SENet、CBAM、ECA,BAM和TANet,分别提升Top-1准确率0.87%、0.48%、0.17%、0.43%和0.90%,并通过Grad-CAM可视化,证明提出模型能准确对图像中的目标区域进行聚焦和感知,明显地提升了CNN骨架网络的性能。然而,使用了维度扩展来完成特征融合,其代价是一定程度上增加了空间复杂度,不可避免的会出现一定程度的信息冗余,因此,选择合适的融合方式将作为下一步的研究方向。
猜你喜欢
计算机应用(2022年9期)2022-09-25
农业工程学报(2022年12期)2022-09-09
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
智能计算机与应用(2018年2期)2018-05-23
第二课堂(课外活动版)(2016年2期)2016-10-21
中学英语之友·高一版(2008年10期)2008-12-11
