
基于深度学习的多视点视频编码方法综述
2021-02-14 06:23缪辰启
电视技术 2021年12期
罗 铖,缪辰启
(福州大学 物理与信息工程学院,福建 福州 350108)
0 引 言
为了提供身临其境的体验,多视点视频从不同的位置和角度捕捉视觉信息,导致了数据量的激增。如何在保证重建质量的前提下降低编码码率已经成为一个关键问题。传统的多视点视频编码(Multiview Video Coding,MVC)[1]方法通常利用混合编码框架对每个视点进行编码。当前流行的多视点加深度(Multi-view plus Depth,MVD)方法为了进一步降低编码码率,在编码时忽略中间视点,并在解码端通过深度图重建它们。然而这类方法在碰到物体遮挡和变形的情况时,很难得到精确的深度信息,所以难以重建中间视点。最近的研究工作已经证实了基于深度学习的视频编码的可行性[2],这得益于神经网络强大的非线性建模能力和大批量数据集的训练。不过现阶段学术界对基于深度学习的多视点视频编码研究较少,这仍然是一个值得继续探索的方向。
1 多视点视频的特点及应用
多视点视频是由摄像机阵列对同一场景进行拍摄所形成的一系列具有时间和空间相关性的视频[3],其采集过程如图1所示。
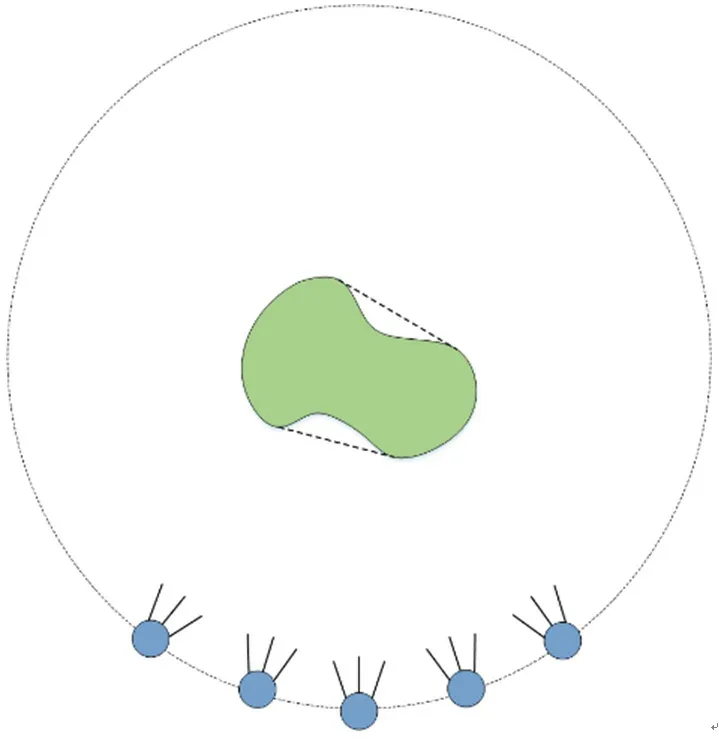
图1 多视点视频拍摄示意图
当前多视点视频在多个场景都有其巨大的应用和研究价值,比如远程控制的医疗手术、VR/AR等沉浸式体验以及体育直播中的特效制作等等。在这些场景下,用户可以基于自己所处的不同角度位置,观看自己感兴趣的内容。然而多视点视频不可避免地带来多倍的数据量,因此不得不对其进行压缩编码。
多视点视频编码可以通过消除同一视点内的时域相关性和不同视点间的空域相关性,在保证重建视频质量的同时减少编码码率,实现对多视点视频的有效压缩。根据多视点视频编码方法是否涉及深度学习技术,可以将多视点视频编码分为传统的多视点视频编码和基于深度学习的多视点视频编码两类,具体分类如图2所示。
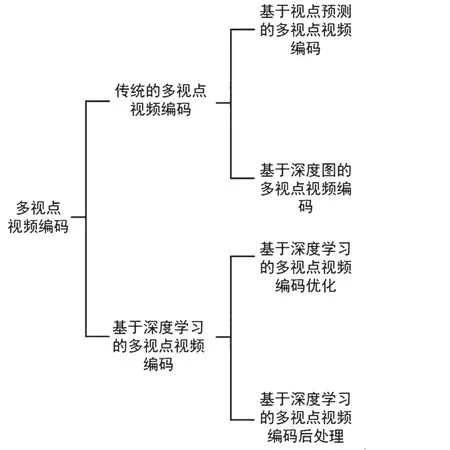
图2 多视点视频编码分类图
2 传统的多视点视频编码
多视点视频编码在高效视频编码(High Efficiency Video Coding,HEVC)标准的基础上增加了视点间预测,形成了多视点高效视频编码(Multi View-High Efficiency Video Coding,MV-HEVC)标准[4]。除此之外,它还引入了深度图的概念,其中每个视点都可以有一个额外的深度图。将基于深度图的渲染(Depth-Image-based Rendering,DIBR)技术应用在HEVC中,这种编码方法被称为MVD[5]。由此,人们将传统的多视点视频编码分为两类,即基于视点预测的多视点视频编码和基于深度图的多视点视频编码。
2.1 基于视点预测的多视点视频编码
MV-HEVC是当前最先进的多视点视频编码标准,它启发了许多对其框架内模块改进的工作。HANNUKSELA等人[4]对HEVC的多视点扩展做了阶段性总结,并描述了多视点视频编码的标准做法,为未来的工作树立了一个重要的里程碑。ROODAKI等人[6]在MV-HEVC的基础上提出了一种视点级的率失真(Rate Distortion,RD)模型,他们推导出一个将视点间和视点内的差异考虑在内的RD模型,以更准确地估计每个视点的总体码率。为了解决运动矢量(Motion Vector,MV)预测效率低下的问题,LEE等人[7]提出了一种基于相邻两个视点间几何相互关系的帧内MV预测,这些几何相互关系来源于对极几何、相似度和仿射变换。与传统的质量失真/质量码率(Quality Distortion/Quality Rate,QD/QR)模型不同,LI等人[8]提出了一种基于基础视点和依赖视点之间精确目标码率关系的多视点码率分配方法。为了降低编码复杂度,JIANG等人[9]提出了一种帧间预测方法,通过感知失真阈值模型,揭示模式选择与编码失真阈值间的关系。
2.2 基于深度图的多视点视频编码
针对深度图序列,人们从不同角度提出了各种编码方法,如深度图的率失真优化、增强、码率分配及虚拟视点合成等。MÜLLER等人[10]通过改进运动补偿模块来编码深度图序列,进而提出了一种基于视点间预测的深度图HEVC扩展方法。通过对中间视点的深度图和相邻视点的纹理图进行合成,大大节省了编码码率。该方法在MVC的发展中树立了一个重要的里程碑。为了解决合成中间视点边界质量下降的问题,RAHAMAN等人[11]使用高斯混合模型来分离前景,以填补合成视点中的空洞。此外,通过帧插值的方式可以进一步减少视频传输的数据量。在文献[12]中,YANG等人利用深度图和视点间的相关性提出了一种帧插值方法,该方法将帧分解成多个层,利用相邻的视点和深度图重建遮挡区域。这种方法在显著提高插值帧质量的同时,进一步减少了MVD传输的数据量。考虑到深度图在中间视点构建中的应用,改进MVC的一个可行方法是获取准确的深度图。YANG等人[13]提出了一种跨视点多边滤波方案,利用不同间隙的相邻视点的颜色和深度先验来提高深度图的质量。
研究人员研究的另一个问题是纹理和深度图之间的码率分配。在传统的率失真优化中,深度图是不需要呈现给用户的。由此GAO等人[14]提出了一种联合信源编码和信道编码方法来优化码率分配。为了降低编码模式选择的复杂度,ZHANG等人[15]提出了一种基于深度直方图投影和允许深度失真的高效MVD方案。除此之外,LIN等人[16]提出了一种基于视觉感知的多视点深度快速编码方法,提升了编码效率。
3 基于深度学习的多视点视频编码
随着深度学习热潮的到来,很多方法将深度学习引入到多视点视频编码中,并大大改善了性能。这些工作包括基于深度学习的多视点视频编码优化和基于深度学习的多视点视频编码后处理。其中,基于深度学习的多视点视频编码优化指的是基于深度学习对多视点视频编码框架中的某一模块进行优化;基于深度学习的多视点视频编码后处理指的是在多视点视频编码框架外对解码后的视频进行增强。然而迄今为止,还没有开发出端到端的深度多视点视频编解码器,所以暂不讨论。
3.1 基于深度学习的多视点视频编码优化
基于深度学习的多视点视频编码优化方法将深度学习引入多视点视频编码框架的特定模块中,用于提升编码效果。JIA等人[17]将生成对抗网络(Generative Adversarial Network,GAN)与传统的编码框架相结合,合成高质量的视点并提高编码效率。此外,多视点视频编码通常利用视点内的帧间相关性来实现更有效的压缩。GU等人[18]提出了一种光场压缩方法,将光场图像看作MV-HEVC编码框架下的多视点序列,利用神经网络合成虚拟帧并为设计的分层编码结构提供额外参考。LEI等人[19]提出了一种用于多视点视频编码的深度参考帧生成方法,通过视差引导的生成网络转换不同视点之间的视差。LIU等人[20]提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的多视点深度快速编码方法,利用可学习的边缘分类网络降低编码复杂度。
3.2 基于深度学习的多视点视频编码后处理
将深度学习应用于多视点视频编码框架的后处理阶段,不仅可以提高多视点视频的质量,还能有效地消除压缩伪影。ZHU等人[21]提出了一种用于3D-HEVC的视点合成增强方法,将压缩伪影去除视为图像恢复任务,并以此重建无失真的合成图像。JAMMAL等人[22]提出了一种多视点质量增强方法,在没有传统深度信息的情况下直接学习低质量视点和高质量视点之间的映射关系。CHEN等人[23]提出了一个残差学习框架,该框架利用视点间的相关性及多模态先验来恢复目标视点的深度视频。最近,HE等人[24]提出一种基于图神经网络(Graph Neural Network,GNN)的压缩伪影去除方法,通过融合相邻视点信息和抑制误导信息来减少压缩伪影。
4 总结与展望
传统的多视点视频编码方法衍生出MV-HEVC和3D-HEVC两类标准。MV-HEVC在HEVC的基础上增加了视点预测,而3D-HEVC又在其基础上引入了边信息的概念,将深度图作为边信息,以提高多视点视频的编码效率。但是,由于遮挡和变性问题,深度图难以精确地反映原始视点的信息,导致重建视频的质量偏低。
基于此,许多工作结合着传统多视点编码框架进行。深度学习浪潮的到来,进一步提高了这种混合编码框架的效果。一类方法是将框架内的模块用基于深度学习的模块进行替代,另一类方法则是在解码端对重建视频进行增强。引入深度学习后的这两类多视点视频编码方法虽然对提高编码效率和提升重建质量有一定效果,但是由于其本质是依赖于传统多视点视频编码框架的方法,并不是端到端进行优化,因此没能充分挖掘出大批量数据集的潜能。
因此,基于深度学习的端到端多视点视频编码方法研究工作非常有必要展开。这类方法可以通过端到端优化及数据驱动的方式,有效去除传统多视点视频编码框架内模块的性能冗余,达到更进一步的率失真性能。
5 结 语
多视点视频作为实现元宇宙的重要载体,在虚拟现实场景等方面起着重要作用,在深度学习蓬勃发展的今天,正成为研究的热点问题之一。本文介绍了多视点视频的特点及应用,讨论了多视点视频编码的分类,并根据编码方法是否涉及深度学习,详细介绍了传统的多视点视频编码和基于深度学习的多视点视频编码现有的工作进展。其中,传统多视点视频编码方法可分为基于视点预测的和基于深度图的多视点视频编码方法,基于深度学习的多视点视频编码方法可分为基于深度学习的多视点视频编码优化和多视点视频编码后处理。最后对现有方法进行了总结,并结合深度学习背景,对多视点视频编码的未来发展方向给出了一些看法。
猜你喜欢
上海师范大学学报·自然科学版(2021年4期)2021-09-23
科学技术创新(2021年2期)2021-01-21
桂林电子科技大学学报(2020年1期)2020-12-18
工程设计学报(2020年2期)2020-05-25
计算机应用(2019年3期)2019-07-31
计算机应用(2018年7期)2018-08-27
软件导刊(2016年9期)2016-11-07
电信科学(2016年9期)2016-06-15
科技视界(2016年2期)2016-03-30
宇航学报(2014年2期)2014-12-15
