
基于随机森林的单粒玉米种子水分近红外快速定量检测
2021-02-18 05:28吴静珠李江波刘翠玲孙晓荣
中国粮油学报 2021年12期
(张 乐 吴静珠 李江波 刘翠玲 孙晓荣 余 乐
(北京工商大学食品安全大数据技术北京市重点实验室1,北京 100048)
(北京农业智能装备技术研究中心2,北京 100097)
玉米是目前我国种植面积最广、产量第一的农作物,不仅是“饲料之王”,还是重要的工业原料[1]。近年来随着美国先锋公司“单粒播”玉米种子的推出[2],以及欧美等发达国家的玉米机械化单粒精量播种技术的引入,我国传统玉米播种模式发生了深刻的改变[3]。单粒精量播种技术较传统播种模式更有利于机械化操作,省工、省种、高产,但是对每颗种子都提出了更高的检测需求,其中单粒播种的玉米种子含水量不能高于14%,否则会导致种子呼吸增大、消耗养分、活力下降[4]。根据GB 4404.1—2008[5],水分是我国农作物种子质量四大必检项目之一。因此单粒玉米种子水分的快速、高通量、无损检测对于单粒精量播种具有重要的现实意义。
GB/T 3543.6—1995《农作物种子检验规程水分测定》中规定了种子水分测量方法有低恒温烘干法、高温烘干法、高水分预先烘干法[6],这些方法测试精度高但普遍存在试样破坏性、耗时长、无法单颗测定等问题。近年来,近红外光谱(Near Infrared Spectrometry,NIR)技术以其快速、无损、绿色分析特点在种子质量检测领域展开了大量深入研究[7-9]。GB/T 24900—2010[10]用于玉米种子批水分的测定,表明近红外光谱技术在玉米种子批水分检测领域具有实际应用可行性,但是目前鲜有针对单粒种子水分近红外检测的方法或标准等。
随机森林(Random forest, RF)具有许多其他传统的机器学习方法无法比拟的优点,不需要顾虑一般回归分析面临的多元共线性的问题,便于非线性数据处理[11]。邵琦等[12]基于随机森林算法,在有效波段和纹理信息特征组合下,能充分利用高光谱图像的光谱和纹理信息,准确地鉴别玉米品种,为玉米品种的自动识别提供了一种新方法。王丽爱等[13]利用随机森林回归算法构建每个生育期的小麦叶片SPAD(Soil and plant analyzer development)值遥感反演模型,并以基于支持向量回归和反向传播神经网络算法构建的模型作为比较模型,以R2(coefficient of determination,R2)和均方根误差为指标,结果表明,RF-SPAD模型在3个生育期都表现出最强的学习能力和预测能力。李盛芳等[14]使用随机森林对不同种类的水果(苹果、梨)糖分进行预测。实验表明,对于同一种类的水果,RF和PLS(Partial least squares)的建模和预测结果均较好。但对于不同种类的水果,RF明显增加了模型的预测能力。
近红外光谱结合随机森林算法在农作物、瓜果定性鉴别以及定量预测组分浓度都具有较好的应用效果。但是近红外光谱技术结合随机森林算法鲜有应用于检测单粒玉米的水分,因此本研究重点探索将近红外光谱与随机森林算法相结合建立性能优秀的单粒玉米种子水分快速、无损检测定量检测模型,以期为玉米精量播种技术的推广和发展探索可行的检测手段。
1 材料与方法
1.1 实验材料
本实验玉米样本购于种子市场,共计购买55组样本,品种包括中地77、沈玉29、中地168、强硕68、奔诚15和春育8。从每组样本中分别选取2个玉米籽粒,共计110份玉米样本。首先采用单籽粒采样附件扫描近红外光谱后, 再使用HB43-S卤素水分测定仪测定每组样本水分。
表1为110份玉米样本的含水量统计信息。按照3∶1的比例随机进行划分训练集和测试集,其中训练集样本82份,测试集样本28份。

表1 样本集统计信息
1.2 光谱采集
本实验采用VERTEX 70傅立叶变换红外光谱仪,及直径为 2. 5 cm 的单籽粒采样附件采集单粒玉米种子光谱。为减少装样引起的干扰,放样本时统一将样本胚面朝下,样本尖端朝向一致。仪器参数设定如下:波数范围为4 000 ~ 12 500 cm-1,分辨率为8 cm-1,扫描次数为64次。样本近红外光谱如图1所示[15]。由于不同颗粒的玉米种子表面平整度不一且种子形态、种皮性质均存在明显差异,导致光谱采集过程中光反射、散射影响程度不同,从图1中也可以看出,样本集近红外光谱在整个谱区范围内离散度较大。但是所有样品的光谱趋势基本一致,玉米近红外光谱在波数为8 400、7 000、5 000 cm-1附近有3个明显的特征峰。水分子由两个氢原子和一个氧原子结合而成的结构使得水分子具有多个原子键振动能级,水的近红外吸收谱分布较宽。其中波数为7 000 cm-1处的特征峰主要为氢氧键伸缩振动的一级倍频,8 400 cm-1处的特征峰为氢氧键伸缩振动的一级倍频和合频,5 000 cm-1处的特征峰也为氢氧键伸缩振动的合频[16],这些特征峰均明显地反映了玉米种子中的水分子对不同波长的近红外光的吸收程度。
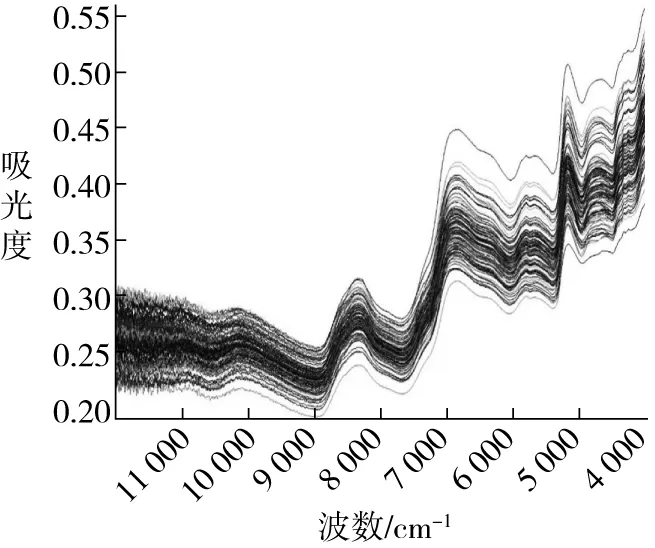
图1 样本集近红外原始光谱
1.3 数据处理方法
1.3.1 光谱预处理
由于复杂样品光谱信号往往会受到杂散光、噪声、基线漂移等因素的干扰[17],样品粒径是影响光谱测量的一个重要参数,随着样品粒径的增加,所测光谱的重现性变差,光谱的变动性随粒径的增加呈指数形式增加。每颗玉米籽粒形状、直径都不相同,所测光谱差异性变大,造成测量误差无法消除[18],从而影响最终的定量分析结果。因此为了降低由种子形态等引起的光谱噪声干扰,采用合适的光谱预处理方法提升光谱质量是必要的。选用Savitzky-Golay卷积求导法 (SG7_2)、均值中心化(mean centering, MC)、归一化(Normalization,NOR) 、标准正态变量变换(Standard normal variate transformation,SNV)、多元散射校正(Multiplicative scatter correction,MSC)方法分别进行数据预处理。
1.3.2 光谱降维
在实际应用中,近红外光谱数据量通常较大,具有一定冗余性,因此对近红外光谱降维就变得尤为重要,本研究采用主成分分析和去噪自编码器两种光谱降维消噪算法在预测模型上的效果。
主成分分析(Principal Component Analysis,PCA)是一种常用的数据分析方法,通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,这些主要特征分量就称之为主成分,常用于高维数据的降维[19]。然而,PCA作为一种线性算法,不能有效地降低非线性数据集的维数。PCA的线性特征组合会丢失原始数据中的大量有用信息[20]。
去噪自编码器(denoising auto encoder,DAE)是由输入层、隐藏层和输出层三层结构组成的神经网络。在自动编码器(Auto Encoder,AE)的基础上,通过向输入中注入噪声,然后利用含噪声的样本去重构不含噪声的输入,这种训练策略也使得DAE能够学习到更能反映输入数据的本质特征。DAE在训练过程中,采取无监督学习机制和有监督微调的方式,它使用了反向传播算法,通过逐层训练,使输出值与输入值相等。DAE的意义在于学习的最中间的隐层,这一层是输入向量的良好表示,可以用于原始数据的降维,起到特征学习的作用。
1.3.3 随机森林回归
随机森林是一种基于分类树的算法,它使用观测数据的子集和变量的子集来建立一个决策树,再建立多个这样的决策树并集成,提高了模型更稳定的预测能力。随机森林的决策树选择的是CART算法,即利用基尼指数最小化准则进行特征选择,CART既可以处理分类,也可以用于回归。最优特征选择原则是采用和方差度量,度量目标是对于划分特征A,对应划分点s两边的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小。表达式为:
(1)
式中:c1为D1的样本输出均值;c2为D2的样本输出均值。
随机森林模型中的生成决策树数目(ntree)和选择分裂属性个数(mtry)直接影响结果的准确性,通常对ntree和mtry的选择采用尝试方法,从而获得比较适合的值[21]。
RF算法的优点体现在:学习过程较快;对于大规模数据集,是一种高效的处理算法,且对数据集中的噪声有较强的鲁棒性;不需要另外预留部分数据做交叉验证;相对于偏最小二乘法、多元线型回归法等方法,随机森林回归方法对非线性数据的解析能力较强[14]。
2 结果与讨论
2.1 基于不同预处理方法的全波段光谱的建模对比
采用 Matlab 2018b 软件进行数据处理及建模。由于采集单粒玉米种子光谱时,引入了颗粒形态等噪声的非线性干扰,因此本研究选用随机森林回归方法建立预测模型,利用Matlab软件中的RandomForest 工具箱,根据经验及多次实验,确定模型中ntree、mtry这2个参数分别取100和4。结果见表2。
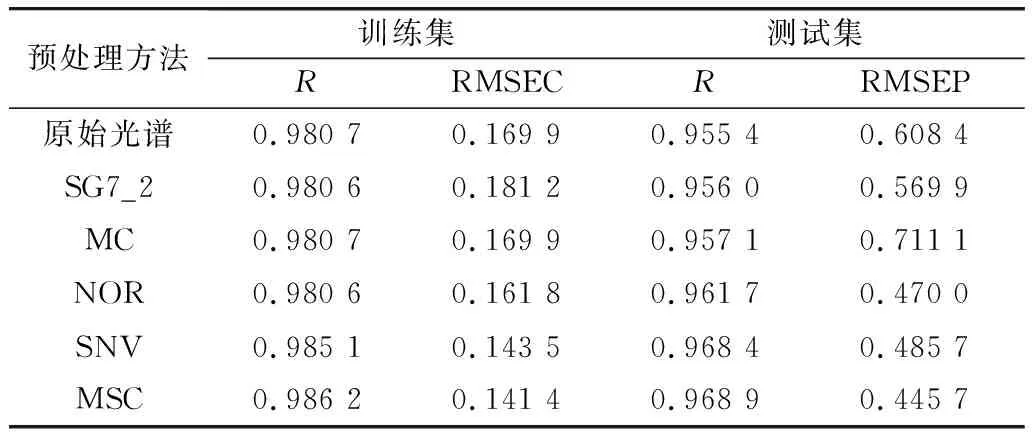
表2 基于不同光谱预处理的RF模型预测效果比较
由表2可以看出,经过不同预处理后的光谱建模结果有所差异。卷积求导并不适用于单粒玉米种子光谱数据预处理,单粒种子光谱本身含有的噪声较大,求导更加剧了噪声的引入,因此大大降低了模型的准确性;多元散射校正可以有效消除近红外漫反射光谱中由于样品的镜面反射及不均匀造成的噪声[23],消除光谱的基线漂移现象及光谱的不重复性,多元散射校正方法是现阶段多波长标定建模常用的一种数据处理方法, 经过散射测试后得到的光谱数据可以有效地消除散射的影响, 增强了与成分含量相关的光谱吸收信息[24],因此基于多元散射校正相对其他预处理方法而言,建立的单粒种子水分模型性能较好,其训练集的相关系数为0.986 2,训练集均方根误差(Root Mean Square Error of Correction Set,RMSEC)为0.141 4;测试集的相关系数为0.968 9,测试均方根误差(Root Mean Square Error of Prediction,RMSEP)为0.445 7。
2.2 基于光谱特征的RF建模分析
由近红外全波段 RF建模结果可知,全波段光谱对单粒玉米种子水分具有较好的预测效果,但由于其光谱数据量庞大,含有较多的冗余信息和共线性变量,影响模型的预测能力和高效性。因此将经过MSC预处理后的110份样本近红外光谱,每份样本光谱包含的2 074个波段,分别作为PCA、DAE光谱降维消噪算法的输入变量,去掉自变量之间具有强线性相关的冗余变量。最后,基于重新组合的特征变量分别建立随机森林回归模型,并对模型进行检验分析,结果见表3。

表3 基于不同变量筛选方法的RF模型预测效果比较
研究结果表明,在光谱降维消噪方法分析中,DAE-RF模型效果比PCA-RF更好,DAE-RF测试集的R较全波段RF模型提升了1.39%, RMSEP较全波段RF模型降低了5.63%, 对比PCA-RF测试集的效果反而不如全波段RF模型。这是因为PCA 是输入空间向最大变化方向的简单线性变换,而自动编码器可以对相对复杂的非线性关系进行建模。并且PCA将变量降维到四维,仅占原特征变量数的0.19%,可能遗漏了原始数据中的大量有用信息,而最佳光谱降维消噪方法DAE重新组合了100个光谱特征,占原特征变量数的4.82%。由DAE的算法原理与特点可知,这种方法在降维的基础上,既能保留原始输入数据的信息,又能确保获得一种有用的特征表示[24]。因此在处理引入了非线性干扰的单粒玉米种子水分近红外数据时,去噪自编码器效果更好。
3 结论
本研究首先采用多种光谱预处理方法消除单粒种子采集光谱时由于颗粒形态等引起的噪声干扰,然后比较建立了基于RF模型的单粒玉米种子水分近红外检测模型。随后利用2种光谱降维消噪方法PCA、DAE选出与玉米种子水分相关的波段,并建模比较预测效果。实验结果表明,相对其他预处理方法而言,多元散射校正处理后建立的单粒种子水分模型性能较好,其训练集的R为0.986 2,RMSEC为0.141 4;测试集的R为0.968 9,RMSEP为0.445 7。进一步对比光谱降维消噪方法,基于DAE的模型效果更好,其训练集的R为0.988 5,RMSEC为0.175 31;测试集的R为0.982 4,RMSEP为 0.420 6。本研究将近红外光谱技术、光谱预处理、光谱降维消噪和RF算法相结合,可以有效降低单粒玉米种子近红外光谱采集时引入的非线性干扰,有助于提升单粒玉米种子水分近红外快速无损检测实际应用可行性,有望为玉米精量播种技术的推广和发展提供可行的检测手段。
猜你喜欢
农业知识(2022年9期)2022-10-13
车主之友(2022年4期)2022-08-27
四川蚕业(2022年1期)2022-06-06
种子科技(2022年24期)2022-02-11
中国食品(2021年21期)2021-11-07
四川蚕业(2020年4期)2020-02-10
海峡姐妹(2019年12期)2020-01-14
现代农业(2016年5期)2016-02-28
火控雷达技术(2016年1期)2016-02-06
燕山大学学报(2014年1期)2014-03-11
