
基于云计算的社交网络安全隐私数据融合方法
2021-02-22 01:42傅江辉
济南大学学报(自然科学版) 2021年1期
傅江辉
(东华理工大学江西省放射性地学大数据技术工程实验室, 江西南昌330013)
互联网和信息化技术的迅速发展为人们的工作、学习和生活带来了翻天覆地的变化,其中最明显的变化就是人际交往方式从最开始的手写信件到通话联系,再到现在的社交网络,人们之间的交往越来越便捷、 快速。目前社交网络的典型代表有国外的Facebook、 Snapchat,以及国内的QQ、 微信、 微博等,为用户带来了全新的服务模式;但是,随着社交网络开放程度的不断加深,个人隐私信息数据量越来越大,导致社交网络无法承载,因此,伴随着云计算的兴起,社交网络后台会将隐私数据上传至云端。在此背景下,为了减少数据传送量,节约宽带,降低节点的能量损耗, 社交网络需进行数据融合[1], 因此,研究面向社交网络隐私安全的数据融合成为各大社交软件开发者共同面临的问题[2]。
目前常用的社交网络安全隐私数据融合方法多是基于加权平均法、卡尔曼滤波法、Dempster-Shafer(D-S)证据推理等随机类方法, 信息完整性以及融合精度较低。 为了实现面向社交网络隐私安全, 本文中提出一种新的基于云计算的社交网络安全隐私数据融合方法。 该方法应用社交网络隐私保护策略和智能算法, 通过k匿名技术对过滤出的隐私数据进行保护处理, 使用决策树构建数据融合模型,在实现数据融合的同时, 使数据的完整性得以保存。
1 社交网络安全隐私数据融合方法
社交网络是通过互联网来完成人际交往的平台,提供了一种新的拓宽社会关系交互性的空间,人们可以在这个空间中学习、 娱乐、 购物、 办公, 实现了多种功能于一体[3-4]。
社交网络是由各用户节点和关系组成社区以及由各社区组成群体,最后由各小群体组成的一个庞大的社交关系网络。在该庞大的关系网中,随着人们的交往程度不断加深,会有意识或无意识地在网上分享与自己相关的信息,如姓名、 年龄、 性别、 家庭住址、工作单位、实时活动位置、 社交记录、 电话、 邮箱、 社交平台号,甚至还有更重要的身份证号码,一旦某些信息被不法分子利用,将给用户造成严重的损失和危险[5]。《中国网民权益保护调查报告(2016)》显示,50%多的用户财产损失均是由社交网络带来的,因此保护社交网络中个人隐私信息不被泄露具有重要的现实意义。
云计算以一种简单、透明的方式为远程计算机用户提供动态的、可扩展的大规模计算和存储服务,已成为当今信息领域的研究热点。目前,为了解决后台隐私数据安全问题,各大社交网络纷纷将隐私数据上传至云端,不仅消耗大量流量,破坏隐私数据完整性,而且还会增加运营成本,因此数据融合技术的应用必不可少。
针对当前存在的几种数据融合方法不能满足在实现数据融合的同时保证隐私数据完整性[6]的问题,本文中面对社交网络安全隐私数据设计一种新的数据融合方法,实现过程如下: 1)过滤社交网络参与者的个人隐私数据; 2)对个人隐私数据进行保护处理;3)对个人隐私数据进行聚类,完成隐私数据按同一目标的聚类分组;4)对同一组隐私数据进行合成,得到该目标的一致性解释与描述。
1.1 社交网络参与者个人隐私数据过滤
人们在社交过程中会有意或无意地泄露个人隐私数据,因此,为了防止这些数据被非法利用,网络平台有必要对个人隐私数据进行保护。在对隐私数据进行保护之前,社交网络参与者个人隐私数据过滤工作至关重要。社交网络参与者个人隐私数据过滤主要对用户社交过程中属于隐私范围内的数据进行识别,如姓名、电话、身份证号码、家庭住址、工作单位等,主要通过构建的敏感信息过滤模型来完成,如图1所示。

图1 社交网络敏感信息过滤模型
在敏感信息过滤模型中, 有2个部分最关键, 一是敏感词库的建立, 二是敏感信息的匹配[7]。 敏感词库主要利用二叉查找树(或称二叉搜索树)建立, 二叉查找树是字典树(Trie)结构的特殊形式, 是一种有序树状的数据结构, 用于保存关联数组, 是目前信息检索领域应用十分成功的索引方法。 Trie的原理如下: 设x为二叉查找树中的一个节点, 包含关键字key, 节点x的key值记为key[x]。如果y是x的左子树中的一个节点,则key[y]≤key[x]; 如果y是x的右子树的一个节点, 则key[y]≥key[x]。 敏感信息的匹配是指对用户社交过程中所有信息与敏感词库进行对比, 从而发现用户隐私信息的一种方法。
1.2 个人隐私数据保护处理
在个人隐私信息过滤出来后, 为了保证在后期数据融合过程中隐私数据的安全, 对隐私数据进行保护处理十分重要。 个人隐私数据保护处理措施主要有属性匿名方法、 随机化扰动法2类方法[8]。 本文中选用属性匿名方法中的k匿名技术进行隐私保护处理, 基本原理是保证同一个准标识符至少有k条记录, 导致攻击者无法通过准标识符连接记录。k匿名技术的个人隐私数据保护处理流程如图2所示。
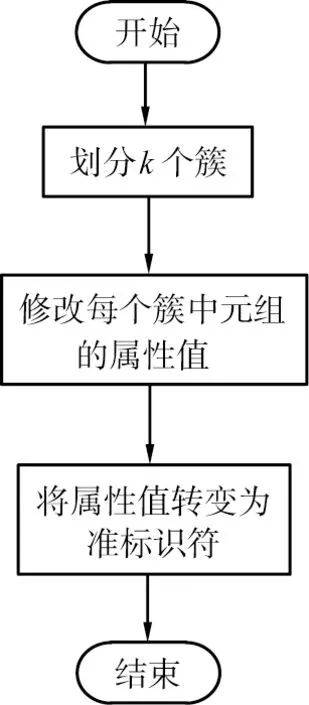
图2 k匿名技术的个人隐私数据保护处理流程
1.3 个人隐私数据聚类
聚类是数据融合的关键和核心,通过将数据进行分组,形成多个类或簇,最后在后续数据融合步骤中对属于同一类或簇的个人隐私数据实现融合。目前常用的数据聚类方法有基于最近邻算法的聚类、基于密度的聚类、基于模糊算法的聚类以及基于核方法的聚类。以上这些聚类算法均需要提取聚类中心,然后计算数据与聚类中心的相似度来实现数据分组[9];但是,聚类中心的提取过程复杂,需要大量的计算,而且不能保证提取结果的准确性,因此本文中将k均值理念引入聚类算法。k均值聚类算法是一种简单的迭代型聚类算法,原理是采用距离作为相似性指标,从而发现给定数据集中的k个分类,并且每个分类的中心是根据聚类中所有值的均值得到的,每个分类用聚类中心来描述[10]。
假定已知个人隐私数据样本集为X={x1,x2, …,xn},其中每个样本xi=(xi1,xi2,…,xin)T(i=1,2,…,n)均为n维特征向量,k均值聚类的目标是把这n个样本划分到k(k≤n)个集合中,使得组内平方和最小。换言之,k均值聚类的目标是找到聚类Gi,使得
(1)
式中: |·|为向量的模运算;pi(i=1,2,…,k)为Gi中所有点的均值。
结合最小二乘法和拉格朗日原理,聚类中心为对应类别中各数据点的平均值,同时,为了使算法收敛,在迭代过程中,应保证最终的聚类中心尽可能不变[11]。
利用k均值聚类算法进行社交网络隐私数据聚类的具体过程如下。
步骤1从采集并处理过的个人隐私数据集中随机选取3条个人隐私数据作为初始聚类中心,记为聚类中心O1(k)、O2(k)、O3(k)。
步骤2计算个人隐私数据集中其余数据与这3个聚类中心的距离,
di(k)=|xi-Oj(k)|,i,j=1, 2, 3 ,
(2)
式中:di(k)为第i个数据到其聚类中心的距离;Oj(k)为聚类中心。
步骤3按照最小距离的原则,将个人隐私数据集中到这3个初始聚类中心。
步骤4第1轮聚类之后,需要更新聚类中心以代替初始聚类中心,
di(k+1)=|xi-Oj(k+1)|,i,j=1, 2, 3 。
(3)
步骤5根据式(3)再次计算聚类中心与各隐私数据。
步骤6如果Oj(k+1)≠Oj(k),j=1, 2, 3,则返回步骤2, 重复进行迭代运算;连续迭代N次,直至聚类不再发生变化,即Oj(k+1)=Oj(k),j=1, 2, 3,则算法收敛,计算完毕。
1.4 隐私数据融合实现
在聚类结束后,将分好组的数据逐一进行分层融合。分层融合主要依据智能算法构成的分层融合模型来完成,可以依据的智能算法有神经网络、 决策树、 遗传算法等[12]。本文中采用决策树构建隐私数据融合模型,如图3所示。
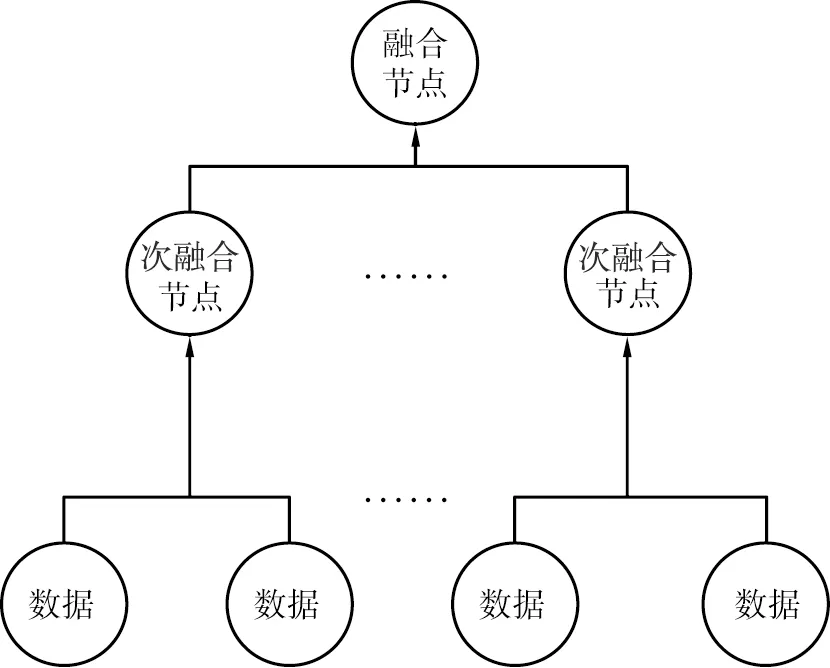
图3 隐私数据融合模型
该数据融合模型主要由融合节点、叶子节点以及融合规则3个部分组成,融合节点代表融合目标,叶子节点代表各隐私数据,融合规则代表融合所应遵守的条件。在这3个部分中,融合规则的制定是核心。为个人隐私数据融合制定的3条准则如下:
准则1在已完成的聚类中寻找聚类数目大于条件k的聚类,并将此作为初代融合数据。
准则2当满足准则1的聚类个数达到2或2以上时,寻找满足条件k-1的聚类,并将其作为二代融合数据。
准则3当所有聚类不满足上述2个准则时,需要调整融合规则,直至所用聚类融合完毕。
2 仿真测试验证
数据融合在保护社交网络隐私数据安全过程中起到了重要作用;但是,如果融合精度不足,就会不可避免地对隐私数据造成影响,使得数据完整性遭到破坏,因此,为了保证方法的有效性,需要对隐私数据进行仿真测试。
为了突显本方法的优越性,仿真测试实验除了本文中提出的方法外,还采用其他3种数据融合方法进行比较,包括基于加权平均法的隐私数据融合方法、基于卡尔曼滤波法的隐私数据融合方法以及基于D-S证据推理的隐私数据融合方法。仿真测试的基础实验数据选定某社交平台上1 000名注册用户的隐私数据,如表1所示。
利用实验平台输入表1中的数据,然后分别利用基于云计算的社交网络安全隐私数据融合方法、基于加权平均法的隐私数据融合方法、基于卡尔曼滤波法的隐私数据融合方法以及基于D-S证据推理的隐私数据融合方法进行融合精度测试和数据完整性测试。

表1 1 000名注册用户的隐私数据
2.1 个人隐私数据融合精度
个人隐私数据融合精度测试结果如图4所示。从图中可以看出,随着个人隐私数据量的增大,数据融合精度逐渐下降,二者呈现负相关的趋势,而且当个人隐私数据多于400条后,本文中提出的基于云计算的社交网络安全隐私数据融合方法的融合精度均大于其他3种方法的融合精度。同时,本文中提出的方法的融合精度最大值为98.4%,最小值为93.2%,精度跨度为5.2%;而基于加权平均法、卡尔曼滤波法和D-S证据推理的隐私数据融合方法的精度跨度分别为5.2%、 5.0%和10.1%,表明本文中提出的方法的融合精度高,性能更好。
2.2 隐私数据完整性
数据完整性越高,说明数据融合效果越好。为了验证本文中提出的方法的隐私数据融合效果,基于仿真实验环境,对表1中的数据进行融合后,分析隐私数据完整性,并与其他3种方法进行比较,结果如表 2所示。 从表中可以看出, 采用本文中提出的方法,个人隐私数据平均完整性为96.7%,明显优于其他3种方法,说明该方法更能保证数据完整性,性能更优越。

表2 不同隐私数据融合方法的数据完整性结果
3 结语
为了使社交网络平台更好地保护个人隐私数据,减少上传能耗,提高上传速度,对个人隐私数据进行有效融合具有重要意义。本文中提出的基于云计算的社交网络安全隐私数据融合方法解决了目前已有的数据融合方法存在的问题,该方法的创新点在于将智能算法应用其中,提高了数据融合的精度,同时保证了融合后的数据完整性,为隐私数据的上传与保护提供了有效的技术支持。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年8期)2022-08-31
一重技术(2021年5期)2022-01-18
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
科学大众(中学)(2019年2期)2019-04-08
小学生必读(中年级版)(2018年4期)2018-07-05
互联网天地(2016年1期)2016-05-04
互联网天地(2016年1期)2016-05-04
华人时刊(2016年16期)2016-04-05
