
基于最小规则自组织映射的入侵检测算法
2021-02-22 01:42张亦辉刘振栋单东方
济南大学学报(自然科学版) 2021年1期
张亦辉, 刘振栋, 单东方
(1. 山东职业学院 信息中心, 山东济南250104; 2. 山东建筑大学计算机科学与技术学院, 山东济南250101;3. 山东财经大学管理科学与工程学院, 山东济南250014)
网络带宽的不断增加和新型网络攻击手段的出现,使得网络环境愈发不安全,网络犯罪取证面临着大型数据集和相关证据提取等多重挑战,有关学者对此进行了许多研究。文献[1]中提出网络取证准备和信息安全框架。文献[2]中针对不同利益相关者,研究相关网络取证调查的特征构建问题。文献[3]中提出了大规模入侵检测数据集、模糊逻辑(FL)适用性等问题。文献[4]中的研究结果表明,基于自组织映射(SOM)聚类技术在小样本数据集上具有非常好的分类效果。软计算(SC)方法,特别是模糊神经网络(FNN)[5],在病毒检测、木马入侵防护等方面发挥了很好的作用。 虽然FNN可以从网络攻击数据中提取准确分类模型,但是通常需要建立非常复杂的模型,或需要很长时间来推导有效的模型。文献[6]中指出,FNN包含基于SOM模糊补丁的无监督放置和基于人工神经网络模糊规则的调整过程2个部分。文献[7]中强调了SOM的特殊性。文献[8]中提出一种 SOM图像分割算法。文献[9]中使用椭圆区域描述每个SOM节点数据,但没有给出超伪半径的定性计算方法,可能导致错误,同时,隶属度函数(MF)的构建也有难度。
鉴于此,本文中针对现有常用算法在大规模数据分析中存在的缺陷进行相应改进,提出基于最小规则自组织映射的入侵检测算法(简称本文算法),主要改进自动确定SOM的规模,并选取最佳SOM网格和高效的模糊补丁可置信值,从而更好地表征每个群集数据的路径,以满足特定标准数字取证,提高入侵检测的有效性和效率。
1 理论背景
1.1 入侵检测模型结构
参照文献[10-11]中的入侵检测算法,首先进行入侵数据库的特征选择,再从选取特征中进行最优特征选择,利用分类器算法(本文中研究主要集中于分类器设计),并根据测试集内已知的分类结果进行算法的分类性能验证和网络训练,实现特征集选取的不断更新,直到算法收敛。入侵检测模型结构如图1所示。

图1 入侵检测模型结构
1.2 SOM的规模
SOM规模确定是复杂的优化问题,需要采用启发式算法对数据集分配数据。文献[12]中利用映射拓扑结构的变化,通过添加新的节点进行迭代优化,直到满足一定的终止标准。这种方法适用于小型数据集,且无须映射重建,从而降低了计算复杂度。参考文献[12],根据Vesanto法给出SOM规模确定的有关定义。
定义1SOM节点的数量为
式中:N为对象的样本数量;e0、e1分别为样本集中第一、 第二数据最大特征值。
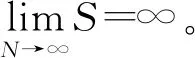
1.3 SOM的结构
SOM聚类输出可由相近实例表示[13-14]。每个集群将导致与之相应的特定类标签模糊规则,由于这些都是Mamdani类型的规则,因此,任意的模糊补丁参数πi(i∈{0,1,…,n})表示各样本特征集a={a0,a1,…,an}的映射。

考虑到补丁区域是一个简单的矩形,因此可定义对应于特定特征ai空间的长度Lai和中心Cai分别为
参考主成分分析(PCA)方法,样本集的特征值分解首先要做的是查找最大方差分量。其次,初始特征值是最长分量。这些信息可被用来找出是否需要增加SOM节点数量,来确定样本覆盖面大小。
1.4 MF的推导
MF取值区间为[0,1],用于定义样品属于特定规则的程度。三角形MF是常用的函数类型,它的参数很容易从数据中获得,因此可利用三角形MF来简化规则的推导。
定义3二维样本空间具有特定特征的三角形MF形式为
式中:x为样本集中的任意一点;c为三角形中心;p为基长度。
2 改进SOM网格算法的理论分析
2.1 最佳SOM网格大小
采用皮尔森相关系数r处理最优SOM网格大小确定问题[15],

引理1[16]在不增加额外记忆功能的前提下分析所得的规则数是有限的。这种约束条件可用来约束SOM大小,从而实现网络的可理解性,
式中:C为分类问题中的类别数量;M为规则中所有MF的组合数。当Smin=22时,计算结果对应于SOM网络的最小规模;当Smax=52时,对应于可接受计算复杂度情况下的最大SOM网络规模。


Sb=⎣Sp/Sa」 ,
式中: ⎣·」为向下取整函数; 「·⎤为向上取整函数。
2.2 模糊补丁估计方法
如2.1节中所述,椭圆的补丁配置并未提供椭圆区域完整信息。
定理1实际数据分类椭圆模糊补丁参数πi的估计可重构成参数分布χ2的特定模型拟合问题,利用高斯分布进行拟合。由于这个测试最初是为分类数据设计的,必须使用χ2对方差进行测试,因此在处理真实世界数据时必须进行初步验证,即

证明:考虑非转化展开方程,得到方程
样本数方差S2可视为在特定数据簇中所有元素的方差, 标准偏差σ2作为这个集群的理论偏差, 则通过选取一定的置信区间, 使可置信值β趋近于1, 可得χ2=α2, 因此, 通过引入β, 可实现对数据的控制, 避免数据离群机会。 图2所示为简单矩形补丁算法、 普通椭圆补丁算法和本文中算法离散性的差异。

t1、 t2—按简单矩形补丁算法选取的矩形。
在特定数量规则情况下,应该减少具体算法分类的模糊区域,并减少不确定性重叠区域。综上所述,可利用χ2查找参数值α2,这里给出的是椭圆补丁参数调整模型。
2.3 相关数据的改进高斯函数
简单矩形补丁、文献[7]中普通椭圆补丁不适合改进高斯函数构造,原因是它们不包含构造椭圆模糊补丁的所有可用信息。此外,高斯函数还应依赖于补丁的旋转和与中心间矩。
定理2在最小组合情况下,用径向基高斯函数代替三角形MF,为旋转椭圆模糊补丁规则提供一个更适合的数据拟合。
证明:利用最小原则对旋转椭圆模糊补丁规则μr进行定义,表示为笛卡尔乘积组合形式
μr=μ0(x)∧μ1(x)∧…∧μN-1(x) 。
利用高斯函数对特征的三角形MF进行替换,μi=siexp{-1/2[(xi-ci)/pi]2},其中xi为样本集第i维的任意样本,ci为第i维的三角形中心,pi为第i维的基长度,尺度因子si∈(0,1]为缩放常数,其他参数是在每个特征空间相应的特性。由此,考虑到不同样本集合,可对整体的隶属度进行描述。
μr=s0exp{-1/2[(x0-c0)/σ0]2}∧…∧
sN-1exp{-1/2{(xN-1-cN-1)/σN-1]2}=
其中尺度因子si是未知的。设定si=1,然后利用椭球的广义方程导出近似高斯函数。
上述过程给出了如何将三角形MF替换为改进的高斯函数,获得μr。
3 模糊椭圆补丁SOM算法结构
本文中算法主要包含2个过程: 1)利用尺寸参数对SOM初始化,并利用SOM对数据样本进行分组; 2)模糊规则由模糊聚类的参数提取形成,利用单层人工神经网络技术调整各模糊规则的权重。参考文献[17-18],算法描述如下。


fuzzyPatchesParameters←clustersToRules(clusters-Confing);
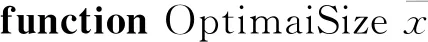
Smin=22,Smax=52,nC←2;

Sopt←Smin+(Smax-Smin);
retum Hgrid,Wgrid
endfunction
functionclustersToRulesclustersConfig
forallclusters extracted from SOMdo

FuzzyPatchesμ=centroids(cluster);
FuzzyPatchesμ=(Cov-1);
endfor
endfunction
functionProposed MF,sample
mahalanobisD←(sample-μ)T
∑-1(sample-μ);
χ2←contingencytable(DF)|φ
ifmahalanobisD≥χ2then
else
endif
returnmf
endfunction
上述算法中,第1行描述了该算法正确运行所必需的初始参数的分配情况,其中φ为椭圆模糊补丁伪半径,SOMepochs描述了在第1阶段SOM训练代数,NFepochs描述了在第2阶段训练代数,BA为自引导聚合中使用的初始数据集的数据样本比例。第2行中,OptimalSize用来估计SOM的最佳尺寸,见2.1节中所述。第3行中,SOMtraining为SOM的常规参数训练。第4行中,clustersToRules将聚类数据转换成相应的模糊补丁参数,用于形成模糊规则,见2.2节中定理1。
4 实验
4.1 实验设置
在算法验证环节,使用标准的KDD CUP 1999数据集,该数据集具有典型的不平衡特性,是一组网络入侵实验数据集。表1所示为KDD CUP 1999攻击地址。测试集内的数据共有4个不同的攻击类型数据,即DoS、U2R、R2L、Probe。对于上述攻击类型,攻击数据具有不均匀的分布特征,例如在DoS中有的样本数量非常大,而U2R、R2L和Probe具有的样本数量较少。

表1 KDD CUP 1999攻击地址
算法计算平台名称为MATLAB 2012a。计算机配置如下:内存容量为8 GB,内存型号为DDR4-2400,处理器型号为i5-7500HQ,操作系统为Windows 7旗舰版。DoS、 U2R、 R2L和Probe这4种不同攻击类型的训练样本数(测试样本数)分别是8 435(123 166)、 1 126(16 189)、 3 000(4 011)、 52(288)。 测试指标如下。
式中:P为检测精度;Tp为定性为入侵的行为;Fp为错误判定为攻击的网络行为。
式中:R为召回率;Tr为定性为正常的网络行为;Fr为错误判定为正常的网络行为。
式中:W为稳定性;Tn为定性为成功训练样本数量;Tm为总训练样本数量。
4.2 结果与分析
为了实现对所提算法进行有效性验证,选取对比算法为普通椭圆补丁算法、决策树算法、简单矩形补丁算法。其中,普通椭圆补丁算法和简单矩形补丁算法均以模糊神经网络算法为基础,实验对比结果如表2所示。
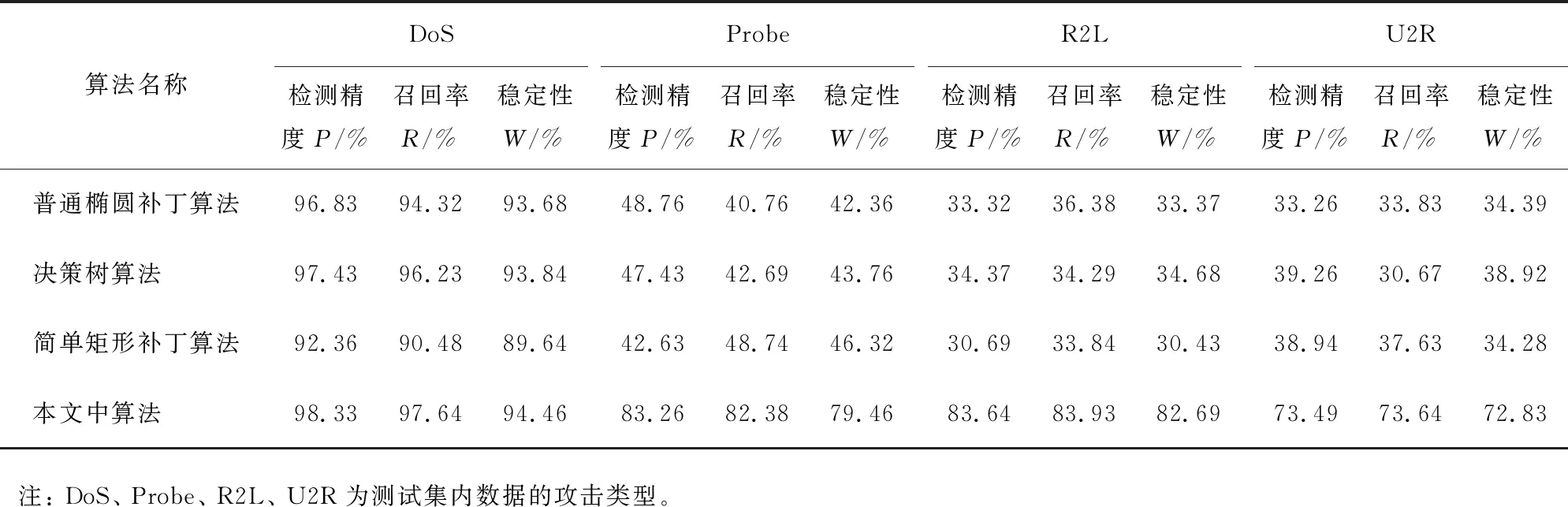
表2 不同算法的实验结果对比
根据表2中的实验数据,在DoS类型网络攻击中,普通椭圆补丁算法、决策树算法、简单矩形补丁算法和本文中算法的检测精度、召回率以及稳定性指标均可达90%,表明DoS类型的攻击检测较简单,本文中算法优于选取的普通椭圆补丁算法、决策树算法、简单矩形补丁算法。召回率、检测精度和稳定性最差的对比算法集中在R2L、U2R攻击类型中,只有30%左右,说明用这几种对比算法检测攻击数据的效果很差,但是本文中算法对各类恶意攻击的检测率大于70%,表明该算法相对于对比算法具有更好的异常网络行为攻击检测性能。同时,从普通椭圆补丁算法、简单矩形补丁算法以及本文中算法在上述测试集上的规则数生成数量对比情况看,本文中算法所需的规则数量远少于普通椭圆补丁算法和简单矩形补丁算法的,体现了选择的最小规则方法的有效性。
通过算法测试时间统计可以比较各种算法的计算效率,不同算法的计算效率对比如图3所示。从图中可以看出,本文中算法所需要的时间与决策树算法极为接近,两者都要少于普通椭圆补丁算法和简单矩形补丁算法的,体现了本文中算法较高的计算效率。

图3 不同算法的计算效率对比
5 结语
本文中提出了一种基于最小规则自组织映射椭球模糊补丁投影隶属度函数的入侵检测模型算法,给出了基于改进高斯隶属函数估计的椭圆模糊补丁构造方法,以及相关数据的改进高斯隶属度函数计算方法,实验结果验证了算法的有效性。
下一步研究方向主要包括硬件设备的实现问题、更多入侵数据集的性能测试、算法的并行化计算系统设计。
猜你喜欢
诗选刊(2022年6期)2022-05-25
中学生数理化·八年级数学人教版(2020年4期)2020-10-29
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
学与玩(2018年5期)2019-01-21
文苑(2018年18期)2018-11-08
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
福建中学数学(2016年4期)2016-10-19
电影故事(2015年16期)2015-07-14
电脑爱好者(2009年13期)2009-07-07
