
基于深度学习的围栏跨越行为检测方法①
2021-02-23 06:30房凯
计算机系统应用 2021年2期
房 凯
(中国石油大学(华东)计算机科学与技术学院,青岛 266580)
1 引言
针对视频行为分析技术[1]的应用可以有效的提升公共场所的管制水平,对维护社会稳定和人身安全有着重要意义.而将针对视频的行为分析技术运用在安防领域[2]中,不仅可以降低人工监控的程度以减少人力物力,还可以避免因人力因素导致的重要监控信息的遗漏,有效提高工作效率,从而达到对重大事故的预警及监控作用,避免事故的发生,因此具有重要的研究意义.
围栏作为施工现场实行封闭式管理的重要工具,在建筑施工作业中,是明令要求必须提前设置的.在作业现场对一些存在安全隐患的地方安装围栏隔离起来,最大程度的为施工安全提供保障,减少不必要的损失和伤害[3].但目前施工现场中对围栏跨越的监管大多依赖人工监察,而且施工场地普遍存在作业面广、施工人员管理困难,安监人员难以及时准确了解现场人员的分布和作业情况,加之工地中各单位安全责任划分不明确,通常导致安全监督检查力度不够,所以这种人工监察的方式效率非常低下.而且尽管围栏按照要求设置,但存在多数人员安全意识不强,对围栏跨越的危险性意识不到位.
在这种背景下,如果能设计一种智能化的围栏跨越违规检测算法,可以大大提升对于非施工人员跨越围栏情况的监管效率,实现智能化的安全管理,及时发现跨越围栏人员并发出警报,为人员的安全做出了一定的保障.
2 相关工作
近年来,深度学习[4]在计算机视觉中得到了广泛的应用,基于深度学习的动作识别[5]是一种端到端的方法,使用深度网络从原始视频中自动学习特征[6]输出分类结果.根据深度学习网络的结构的不同,基于深度学习的动作识别方法[7–9]主要分为基于双流卷积网络的动作识别和基于三维卷积网络的动作识别.
2.1 基于双流卷积网络的动作识别
视频的处理相对于单帧图像来说更为复杂,主要原因在于单帧图像仅仅包含空间位置信息,而视频不仅具有单帧图像的空间特征,还包含帧与帧之间的时序特征[10].因此,在视频处理方面,需要同时考虑空间和时间两大部分,这就要求深度网络具备同时处理不同维度特征的能力[11].
但是,上述的空间流和时间流卷积神经网络均为2D 卷积,Two-stream 双流卷积神经网络的基本网络架构如图1所示.

图1 Two-stream 双流网络结构图
在双流卷积神经网络提出之前,动作识别的相关研究主要是从处理单帧图像的角度出发,通过结合分析关键帧中人体运动姿态及其背景实现动作识别.这种方法的主要问题是没有利用视频本事特有的时间特征,仅分析每一帧图像中的空间特征,因此识别效果有限.双流卷积神经网络正是为了解决此问题而提出,相比于仅处理单帧图像,双流卷积神经网络可一次性输入两帧图片,这样在处理空间信息的基础上还考虑到了一个动作本身持续性的时间变化特征,通过综合利用两部分特征[13–16]极大地提升了动作识别的准确性.
2.2 基于三维卷积网络的动作识别
二维卷积仅可以用来处理单帧图像,对于视频本身的时间维度上的信息难以处理.因此三维卷积的作用就显现出来,它可以看作是对二维卷积的直接扩展,在原本处理单帧图像空间特征的基础上,多了一个维度来捕获时序信息.3D CNN 架构由Ji 等[17]提出,3D 卷积通过堆叠多个连续的帧组成一个立方体,然后使用3D 卷积核进行处理.2D 卷积与3D 卷积的本质区别在于,处理视频数据时2D 卷积操作后生成的特征图还是二维的,相应的多通道信息被完全压缩,而3D 卷积操作后生成的特征图仍然是三维的,因此保留了视频时间维度上的信息.Tran 等[18]在前者的基础上提出了一种 C3D (Convolutional 3D)的现代深层架构,如图2所示,C3D 网络包含8 次卷积操作,其中卷积核大小均为3×3×3,步长为1×1×1,5 次最大池化操作,除第一层池化的池化核大小和步长为1×2×2,其余均为2×2×2,最后网络经过两次全连接层和Softmax 层输出最终结果.实验结果表明,此C3D 方法在视频动作识别精度上要优于之前的方法,并且其不需要额外的计算光流,直接可以完成空间信息和时序信息特征的提取操作.

图2 C3D 网络结构图
为了优化3D 卷积本身神经网络层数的限制,进一步提高使用三维卷积进行视频动作识别的研究水平,Carreira 等[19]沿时间维度重复使用在ImageNet 上预先训练的二维滤波器,将用于图像分类非常深的网络拓展为空间-时间特征提取器.Qiu 等[20]提出了另一种构建深度三维卷积网络的方法:伪三维残差网(Pseudo-3Dresidualnet,P3D ResNet).
三维网络相比于双流网络更加简单直接,可以更直观的捕捉短时间内的时间动态,但三维网络通常考虑比较短的时间间隔,因此无法捕获长期的时间信息.
3 基于深度学习的围栏跨越行为检测
针对作业现场围栏跨越违规行为检测问题,本文从计算机视觉角度提出一种智能化的检测与识别方法.考虑到二维卷积可以用来解决空间定位问题,而三维卷积在处理视频时相对传统的双流网络更加简单直接.因此提出此方法,通过结合二维卷积及三维卷积,其中三维卷积用于提取输入剪辑中的时序特征,输出特征维度为C′×H′×W′;二维卷积则提取当前帧空间特征,解决定位问题,输出特征维度为C′′×H′′×W′′.
本文拟采用的三维卷积架构为3D-SE-ResNext-101,在3D-ResNext-101 的基础上引入SE 模块,相同深度的情况下提升了精度;采用Darknet-19 作为二维卷积架构,提取视频中的空间位置特征;最后将得到的特征进行通道融合,然后分类回归,实现围栏跨越行为检测与识别.具体流程如图3所示.
装配式项目4D模型构建采用的是Navisworks Management和Microsoft Project软件工具组合进行。

图3 围栏跨越行为检测流程图
3.1 3D-SE-ResNext-101
三维卷积不仅可以在空间维度上,而且可以在时间维度上应用卷积运算来捕获运动信息.众所周知,残差网络可以有效解决神经网络随深度增加而出现训练效果变差的问题,其内部多个残差块使用跳跃连接,可以有效解决梯度消失现象.3D-ResNext 基本block 单元如图4所示.

图4 3D-ResNext 基本单元
SE 模块主要包括Squeeze 和Excitation 两个操作,可以适用于任何映射:
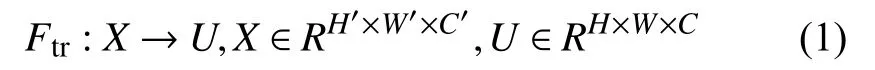
以卷积为例,卷积核为V=[v1,v2,···,vC],其中vc表示第c个卷积核.那么输出U=[u1,u2,···,uc]:
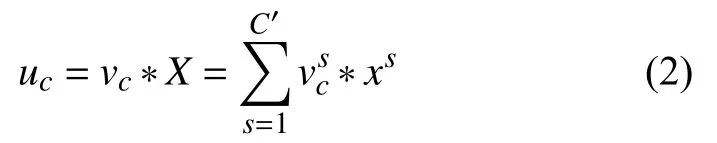
3.2 Darknet-19
为了解决空间定位问题,并行提取当前帧的二维特征.我们采用Darknet-19 作为基本架构,因为它在准确性和效率之间取得了很好的平衡.如表1所示,包含19 个卷积层和5 个最大池化层,同时使用batch normalization 来加速收敛.
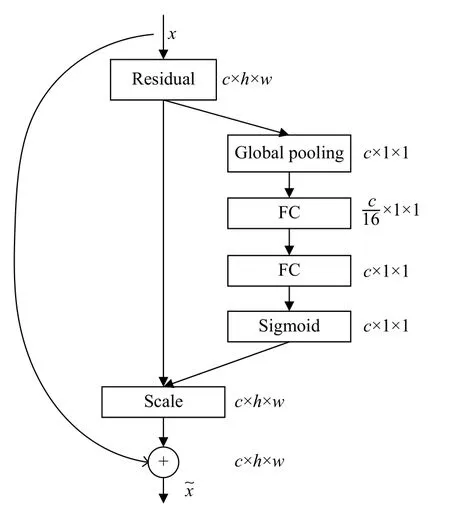
图5 3D-SE-ResNext module
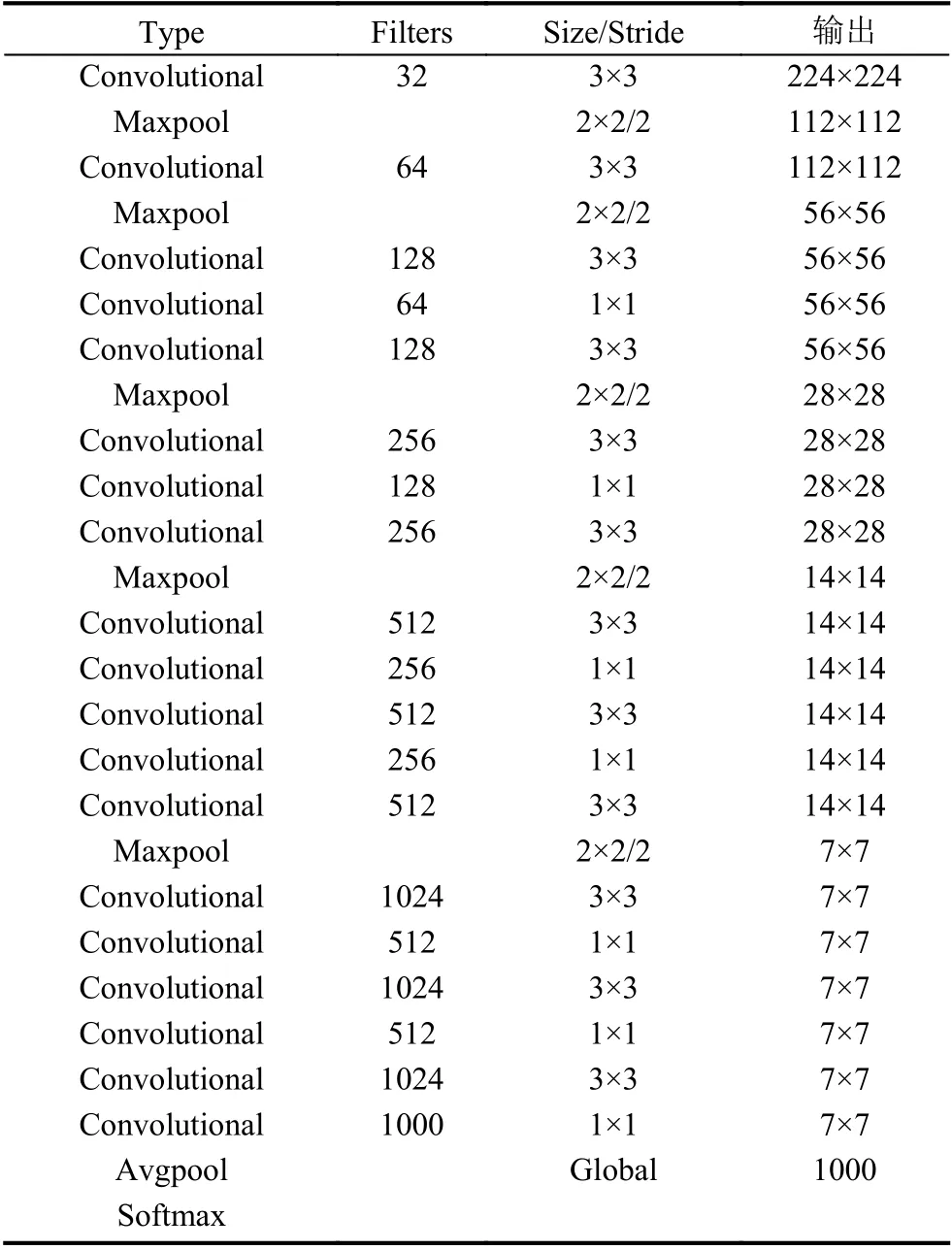
表1 Darknet-19
3.3 损失函数设计
对于最终输出特征图尺寸H′×W′中的每个网格单元(gridcell),用K-means 方法事先选择5 个先验框,因此最终输出大小为[(5×(NumCls+5))×H′×W′],其中NumCls表示行为分类得分个数,还有4 个坐标和1 个置信度得分.对于训练集中的ground truth,中心落在哪个cell,那么该cell 的5 个Anchor box 对应的边界框就用来预测它,最终选择IOU值最大的边界框负责预测;与ground truth 匹配的先验框负责计算坐标误差,置信度误差以及分类误差,而其它4 个边界框只计算置信度误差.损失函数计算公式如下:

式中,W,H分别指的是特征图的宽与高;A指的是先验框数目.L1,L2,L3如式(4)~式(6)所示.

计算各个预测框和所有ground truth 之间的IOU值,若最大值也小于阈值,则标记此为background.

计算先验框与预测框的坐标误差.

这一部分计算与ground truth 匹配的预测框的坐标损失,置信度损失以及分类损失之和.
4 实验与分析
本次实验自建围栏跨越数据集,共采集视频70 段,将每段视频按帧截取并分别保存到不同文件夹,共包含图片7000 余张.使用LabelMe 软件标注包含此动作的一系列帧生成相应JSON 文件,编写程序实现将多个JSON 文件转化为训练所需的txt 文件格式,并汇总到trainlist 文件中以开始训练.
实验显卡配置NVIDIA GeForce RTX 2080Ti,处理器为Intel i7.学习率初始化为0.0001,并在30 k,40 k,50 k 和60 k 次迭代后分别降低0.5 倍.
4.1 效果展示
训练12 个epoch 后选取视频测试,实验选取不同场景下的围栏跨越违规动作模拟视频以验证该方法的泛化性,实际测试效果如图6所示.
从图中可以看出,在不同的场景下使用此方法可以较为准确的检测出视频中的围栏跨越行为,具有一定的泛化能力.当处理实时监控时,使用OpenCV 不断获取视频监控截图,将连续帧组成的剪辑作为输入,经格式化处理后输入到训练好的模型中,若检测到当前帧存在违规动作,使用红色方框标记并预警,避免事故的发生,从而达到智能化管理.
4.2 对比实验
本次实验使用Frame-AP 作为评价指标.对所有包含预测框的帧,计算每一个预测框与真实框间的IOU值,若超过阈值(预先设置为0.5),则记为TP,否则为FP,漏检记为FN;当出现多个预测框同时匹配一个真实框的情况时,则只保留IOU值最大的预测框,记为TP,其余均为FP.相应得出准确率(Precision)及召回率(Recall).

为探究输入剪辑长度以及下采样率对围栏跨越检测模型的影响,选取剪辑长度为8 帧和16 帧,下采样率d=1,2,3 进行对比实验.具体结果如表2所示.比较后,本次实验选取输入剪辑长为16,下采样率d取1.
探究不同3D backbones 对结果的影响(16-frames,d=1).如表3所示.从表3中可以看出,在3D-ResNext-101 基础上加入SE 模块后,达到最好效果,因此将其作为本文三维卷积backbone 使用.
探究本文(3D-SE-ResNext-101+Darknet-19)方法与其他方法在围栏跨越行为检测上的效果,测试结果如表4所示.
从结果可以看出,在保证Frame-AP 的情况下,本文方法在实际测试围栏跨越违规行为时处理速度可以达到43 fps,实时性更强.
5 结论与展望
针对围栏跨越违规行为检测问题,本文从计算机视觉角度出发,提出一种基于视频的智能化检测与识别算法,使用三维卷积提取时序特征,同时在二维卷积上提取空间特征,解决定位问题.通过设置对比试验以寻找最优方法.实验测试结果表明,该方法可以较为准确的检测出视频中的跨越行为,具有较高的准确性和鲁棒性,大大提升了监管效率,实现智能化管理.未来将会考虑在此基础上加入目标检测模块,重点检测围栏区域范围内的动作,以消除无关区域动作干扰,使围栏跨越违规检测与识别方法更加成熟.

图6 不同场景下的实际测试效果

表2 输入长度及下采样率对结果的影响 (IOU=0.5)

表3 3D Backbone 对结果的影响 (IOU=0.5)

表4 不同方法测试效果(IOU=0.5)
猜你喜欢
现代经济信息(2022年22期)2022-11-13
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
中小学校长(2022年7期)2022-08-19
当代县域经济(2022年5期)2022-05-09
计算技术与自动化(2022年1期)2022-04-15
作文大王·低年级(2022年2期)2022-02-28
红蜻蜓(2020年12期)2020-06-20
上海师范大学学报·自然科学版(2019年5期)2019-12-13
好孩子画报(2019年8期)2019-09-19
