
基于聚类的文本分类算法框架研究*
2021-02-25 06:27黄细凤
计算机与数字工程 2021年1期
黄细凤
(中国电子科技集团公司第十研究所 成都 610036)
1 引言
如何对文本进行更高效和准确的分类是目前计算机领域学者们探究的热点。随着网络讯息日益增长,对文本分类任务的性能需求也在不断提升。就目前而言,广泛应用于文本分类工作的分类方法主要有人工神经网络[1~2]、KNN[3~5]、决策树[6~7]、支持向量机[8~9]以及朴素贝叶斯[10]等。
文本分类的核心思想为通过已知类别的文本,将待分类文本进行归类操作,使其从属于类别中的某一类或几类。而KNN 因其算法的理论成熟、易于理解等优点,在实际分类工作中应用广泛。针对传统KNN 在训练集样本规模宏大或样本维度较高时计算开销巨大的问题,殷亚博等[11]提出了基于卷积神经网络的文本分类算法CKNN,首先从短文本中获取更多的抽象特征值,之后再进行文本的相关分类工作。胡元等[12]提出了基于划分区域的KNN算法,首先确定待测样本与各区域的联系密切程度,其次运用KNN 对其进行相应的归类。张著英等[13]提出了基于粗糙集的KNN 算法,以属性约简的方式,对样本空间中的向量进行降维,进而提升对文本进行归类的效率。史淼等[14]提出了一种新的分类算法PCA&KNN,采用较小的邻居集来进行KNN 分类,有效降低了分类计算的复杂度。谭学清等[15]提出了一种新判定方式下的KNN 算法,待测样本所属类别由其与训练集各类别中所有文本的相似度均值来确定,使时间复杂度有效降低,得到一种适合在大数据文本分类情况下的分类算法。
可见,对算法的优化可以是多方面和多角度的。由此,本文采取将聚类与KNN 相结合的方式,形成一种新的用来对文本进行分类的算法框架,K-medoids[16]由 K-means 优化而来,简单高效且实用性强,所以,为更好地服务于后续相关分类工作,本文将传统K-medoids 聚类思想与遗传算法相融合形成新的聚类方式K-GA-medoids,再将其与KNN 相结合用于文本分类。经验证,本文提出的算法框架能够在确保分类结果的精确率的情况下,有效减少计算开销。
2 相关概念
本文主要涉及到的算法有遗传算法、K-medoids和KNN,下面分别进行简单介绍。
2.1 遗传算法
遗传算法基本框架如图1 所示,首先依据实际问题对个体进行编码表示,再进行初始种群集合的随机产生,得到多个初始可行解。种群中所有个体均有相应的适应度值,以对其优良程度进行评价。根据选优淘劣的准则,从现有的种群中挑选优秀的个体进行后续的变异、遗传等操作。对于后续产生的种群,循环执行选择、交叉及变异操作,当满足终止条件时,算法结束,得到实际问题的近似最优解。

图1 遗传算法流程图
2.2 K-medoids聚类算法
K-medoids 算法在进行聚类时始终选择最靠近簇心的样本点作为聚类中心,旨在最大限度降低各种异常点、离群点等对于聚类中心选取的影响。其算法思路:首先选取K 个初始聚类中心样本点,剩余样本则依次归类于与其距离最近的聚类中心所对应的簇。其次,选取非聚类中心样本点对当前聚类中心进行替换,根据替换所需代价,判别是否更新当前聚类中心集合,如此循环,当聚类中心集合不再发生变化时,算法收敛。
2.3 KNN算法
KNN 是一种理论成熟且易于理解的分类算法,其核心思想为一个待分类样本类别与其K 个最邻近样本组成的样本集中占比权重最大的类别相同。即KNN 主要是通过遍历样本空间进行相似度大小的计算,得到与待分类文本相距最近的K 个样本,再根据最邻近的K 个样本对其类别进行判别的一种算法。
3 算法框架介绍
K-medoids 由K-means 算法优化而来,极大降低了噪声、异常点等对于最终聚类效果的影响,但其对初始聚类中心的选取依旧较为敏感,针对此问题本文将遗传算法与K-medoids 算法思想相融合,得到新的聚类方式K-GA-medoids,旨在更好地提升前期聚类效果,之后将其与KNN 相结合,形成一种基于聚类的新的文本分类算法框架,该框架在分类前期对训练样本集进行聚类,在分类阶段依据待分类文本与簇心之间的距离大小来对训练集进行缩减,从而克服传统KNN 算法在样本规模较大的情况下,分类效率将严重下降,缺乏有效性的问题。
3.1 K-GA-medoids算法
K-GA-medoids 由遗传算法与K-medoids 聚类核心思想相融合而成,在遗传算法的适应度函数设计部分融合K-medoids 寻找簇内中心点的思想,以距离作为适应度函数设定的核心,旨在通过遗传迭代找出更靠近簇心的聚类中心点集合,具体如下:

其中,Ci为聚类结果的第i个簇,Ni是第i个簇的大小,Mi表示簇心,|P-Mi|是样本P到簇心Mi的距离,Si为第i个簇内所有样本点到簇心的距离的平均值。

K为当前簇心选取个数,Fit为当前个体适应度值,由式(2)可知,Fit值越小,聚类效果越好,二者定义为反相关的关系。
算法迭代前首先随机生成一定数目可行解的集合作为种群初代,根据适应度函数对本代种群中的个体进行优良程度的判定,其次对本代种群中的个体执行相应遗传操作,以保证种群的不断进化和扩展,为寻找更优的可行解提供选择,具体流程如下:
1)设置参数:聚类中心个数K,初始种群大小N,选择存优比例p1,交叉概率p2,变异概率p3,最大迭代次数T,种群平均适应度变化阈值ε;
2)种群初始化:依据K值对初代个体进行编码,得到种群规模为N的初始群体;
3)根据式(2)对当代个体进行优良程度的判定,并保留迄今为止最优个体;
4)根据3)的判定结果以及参数p1、p2、p3对种群个体执行相应遗传操作,得到一轮迭代后新一代的种群;
5)判断当代种群平均适应度值与父代相比差值是否小于阈值ε,若符合,则算法终止,输出结果;否则,转向第3)步。
3.2 基于K-GA-medoids聚类样本缩减
在运用KNN 算法对文本进行归类时,采用距离公式得到的K 个最邻近文本正常来说与待测文本的类别同属或接近,若寻找最邻近文本过程中尽可能的在待测文本本身所属类别或周围类别样本集中进行搜寻,则可极大减少计算开销。对样本集的缩减力度较大时,在分类效率得到提升的同时分类结果的准确率必然会受到一定程度的影响而有所下降,缩减力度较小时则对分类效率的提升并不明显。针对此问题,本文在准确率与计算开销之间进行了折中考虑,提出了基于K-GA-medoids 聚类的样本缩减方法。
定义训练样本集为S,包含C1、C2,C3,…,Cm共m个类别M个文本。在分类前首先采用K-GA-medoids 算法将其划分为n个簇,Oi表示对应簇的簇心(0 <i≤n),样本之间的相似度距离定义为D(si,sj),缩减步骤描述如下。
1)设定K-GA-medoids 相应参数,首先对训练样本集S执行聚类操作,将其划分为指定的n个簇,之后对每个待测文本d执行如下2、3、4)操作;
2)计算d与Oi(0 <i≤n)之间的相似度距离大小,遍历簇心进行计算并记录最大距离Dmax及最小距离Dmin;
3)折中计算获取待测文本d的样本缩减度量距离Dend=(Dmax+Dmin)/2;
4)定义当前待测文本d缩减后训练集为Snew,若d与Oi的相似度距离Di≤Dend,则说明d与Oi对应簇内的文本较为相似,将其内文本纳入Snew,否则,将对应簇予以舍弃。
3.3 改进聚类与KNN结合的算法框架
在进行正式KNN 分类工作之前,采用K-GA-medoids算法对训练样本集进行聚类得到多个簇,在分类阶段,根据各待测文本与各簇心之间的相似度距离大小获取对应样本缩减度量距离,从而缩减训练集,减少计算开销。相应算法框架流程及图示如下。
1)读取训练集及测试集样本数据,本文所涉及数据均为英文文本,对其进行分词、去停用词以及统计词频工作;
2)采用TF-IDF计算方法来计算各个特征词的权重大小,得到未降维的文本向量;
3)采用信息增益方法对文本特征向量进行降维,保留增益值较大的特征项;
4)对训练空间中的文本向量执行K-GA-medoids聚类操作,将其划分为内聚度较高的多个簇;
5)对于测试空间中的每个待测文本d,采用3.2 节样本缩减方法对训练空间进行缩减,得到与其对应的新的训练空间Snew;
6)采用KNN 算法对待测文本d进行分类,在Snew中查找其K 个最邻近样本,并将d归属于占比权重最大的样本类别。
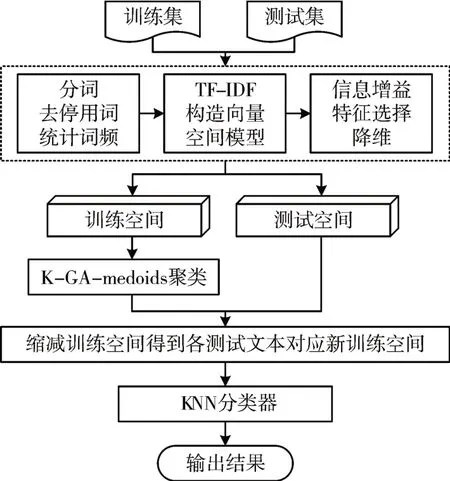
图2 分类算法框架流程图
4 实验结果及分析
本节所有实验均是在配置2.20GHz Intel Core i5、8GB 内存的 PC 上进行,操作系统为 Win7,算法程序采用Python 语言进行编写,在Python3 中编程实现。实验结果所涉及到的评价指标包括精确率(precision)、召回率(recall)以及F 值,相应计算公式定义如下:
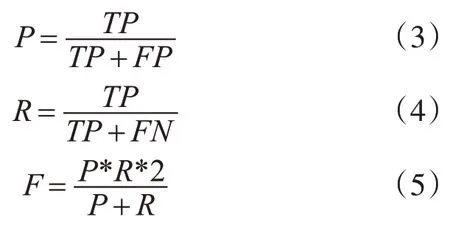
其中TP表示预测为正且实际为正的数目,FN表示预测为负但实际为正的数目,FP表示预测为正但实际为负的数目。
4.1 K-GA-medoids聚类效果分析
为验证K-GA-medoids 聚类的有效性,本文将对K-medoids 和K-GA-medoids 在同等数据集上做实验对比。实验采用的是经典的文本聚类集合mini_newsgroups,共包括 20 个大类共计 2000 个数据文本。在实验前,对文本执行预处理操作,包括去停用词、TF-IDF 权重计算、特征选择等,进而得到文本特征矩阵。最后针对不同测试集Group 在K-medoids 和K-GA-medoids 算法上进行实验。本实验相关参数设置如下:初始种群规模N为测试集总数的0.1,选择存优比例p1为0.1,交叉概率p2为0.6,变异概率p3为0.1,最大迭代次数T为300,种群平均适应度变化阈值ε为0.05,实验测试集相关说明及具体实验结果如下。
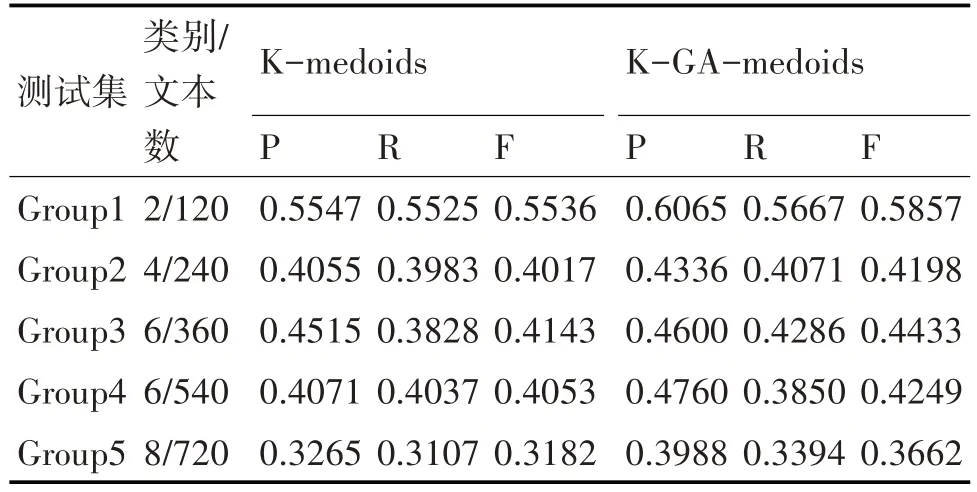
表1 测试集说明及聚类实验数据
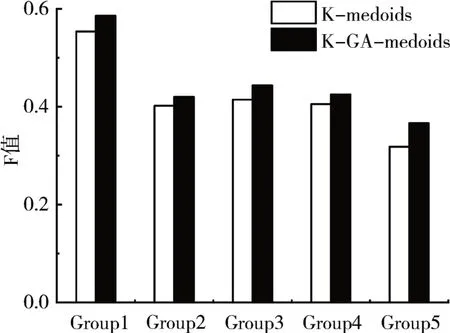
图3 聚类效果F值对比
以上实验所得数据均为多次实验求得的均值,由结果可知,K-GA-medoids 算法在聚类效果的精确率、召回率及F 值上较一般K-medoids 算法均有较为明显提升,五次实验F值平均提升2.94%,在进行文本聚类时表现更佳,说明本文将GA 与K-medoids 算法思想相融合衍生出的全新聚类方法K-GA-medoids在实际应用中是客观有效的。
4.2 文本分类算法框架效果分析
为验证本文算法框架的有效性,本节将其与传统KNN 算法在相同数据集上进行实验对比。由于mini_newsgroups数据集单个类别样本数较少,无法较好的保证分类工作前期训练集的多样和全面性,所以本小节实验数据集采用网络爬取的5 类新闻文本数据,测试时将其划分为不同的测试集Group,K-GA-medoids算法参数设定同4.1节,实验测试集相关说明及具体实验结果如下所示。

表2 测试集说明及分类实验数据
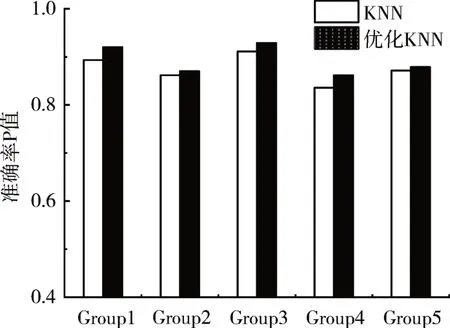
图4 分类效果P值对比
由以上图表可得,本文算法框架较传统KNN算法而言,在5个测试集实验中,精确率P值同比平均增长1.72%,文本分类效率平均提升7.29%,说明本文提出的算法框架在保证分类精确率有所提升的前提下,有效加快了文本的分类效率,较传统KNN 算法而言,在分类效果上表现更佳,具备优越性。
5 结语
本文针对KNN 在进行文本分类时,需遍历样本空间做相似度计算,导致计算开销巨大的问题,提出采用聚类算法与KNN 相结合的方式形成新的文本分类算法框架,目的在于对训练样本集进行合理的缩减以降低计算开销。与此同时,为更好地提升前期对于训练集文本的聚类效果,本文将遗传算法与K-medoids 算法思想相融合,形成新的聚类算法K-GA-medoids,实验表明,其聚类效果较传统K-medoids而言有较为明显提升,将其与KNN 相结合形成的分类算法框架在分类表现上较KNN 算法而言更佳且效率更高。但是对样本集进行缩减的方式也不可避免地造成了样本信息的损失,所以如何更有效地对训练集样本进行缩减仍是我们今后需要进行探索和研究的方向。
猜你喜欢
今日农业(2022年15期)2022-09-20
包装工程(2022年11期)2022-06-20
汽车工程(2021年12期)2021-03-08
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
智富时代(2018年4期)2018-07-10
智富时代(2018年4期)2018-07-10
中学生物学(2018年8期)2018-03-01
科学家(2016年13期)2017-09-29
微型计算机(2009年4期)2009-12-23
