
面向中文基础教育知识图谱的关系抽取模型
2021-03-03 09:24单娅辉田迎张龑
湖北大学学报(自然科学版) 2021年2期
单娅辉,田迎,张龑
(1.湖北大学计算机与信息工程学院,湖北 武汉 430062;2.湖北省教育信息化工程技术研究中心,湖北 武汉 430062;3.绩效评价信息管理研究中心(湖北大学),湖北 武汉 430062)
0 引言
随着我国信息技术的发展,通过新兴技术来直接或间接影响传统教育教学方式,已成为教育信息化的新热点.2012年,Google提出“Google Knowledge Graph”后,知识图谱在各个领域受到了广泛的关注,其中教育领域知识图谱更是在近年来成为研究热点.在构建中文教育领域知识图谱的过程中,面对急剧增长的数据,中文实体关系抽取成为其中的难点之一.
传统的关系抽取方法主要包括两类,一类是基于规则匹配的方法,另一类是基于深度学习的方法.其中基于规则匹配的方法是定义了一种表达实体关系的规则模版,然后在数据中找到与该模版相匹配的实体及关系.该方式对数据要求较高且灵活性很差[1],已逐渐被深度学习的方法所取代.基于深度学习的方法目前流行的包括有监督的方法和远程监督的方法[2].其中,有监督的关系抽取方法主要是利用深度学习中的神经网络模型能够自动学习文本的特征,改善了经典方法中需要人工特征选择的缺点[3].远程监督的关系抽取方法是将大量无标注的数据自动对准已标注的知识库来自动标注数据来提高关系抽取的效率.该方法的前提是,如果两个实体间存在已定义的某种关系,那么所有包含这两个实体的文本都存在该关系[4].Mintz等[5]提出使用Freebase知识库与维基百科中的文本来对齐,获取实体及其关系的三元组.在该前提下,基于远程监督的关系抽取能够自动获取大量的训练实例,但是同时也不可避免地存在许多噪声数据.王斌等[6]用远程监督的方法进行关系抽取时,通过采用LDA(latent dirichlet allocation)模型、对比类型相似度和对关键词进行模式匹配去噪.Surdeanu等[7]提出加入多标签来减少噪声数据对关系抽取性能的影响.Lin等[8]提出在加入注意力机制在训练过程中通过动态调整各实例的权重来降低噪声数据的权重,从而减少错误实例对关系抽取模型性能的影响.
以上方式大多是基于英文语料或者中文通用语料上[9]提出的模型,而在中文教育领域,杨玉基等[10]提出在构建领域知识图谱过程中使用有监督、无监督、远程监督多种方法来进行关系抽取,最后使用大量人工标注来获取高质量数据,耗费时间精力.黄焕等[11]在构建java知识图谱的过程中采用人工定义关系类型,且在识别实体关系的过程中采用手工标注关系的方式,虽然保证了数据的准确性,但适用性不强.本研究提出的实体关系抽取模型适用于中文基础教育中的科目,将高质量的教材教辅通过文本处理成已标注的知识库,通过远程监督能够获取大量数据并自动标注,加入的句子层注意力更能有效减少噪声数据对于关系抽取性能的影响.
1 远程监督构建关系语料库
由于中文领域公开的可供使用的数据很少,而基础教育领域的就更少见,所以首先利用教育部发布的基础教育的教材教辅,将其转换成可供使用的电子文本;然后结合网络爬虫从百度百科上获取的网页数据,通过预处理得到关系实体对以及包含实体对的文本集;最后选取其中一部分数据作为训练数据对关系抽取模型进行训练,另一部分作为测试数据来检测模型关系抽取的效果.构建流程如图1所示.

图1 构建流程
1.1 构建信息技术知识库基于教育部发布的基础教育中信息技术学科的教材教辅,利用OCR技术将图像中的文字转换成文本格式存储,使用词频-逆向文件频率[12](term frequency-inverse document frequency,TF-IDF)算法和 TextRank[13]算法对文本集进行关键词抽取,TF-IDF算法是一个统计词语在该文件中的重要程度的方法,其核心思想是词语的重要性与它在该文件中出现的次数成正比,同时与它在语料库中出现的次数成反比.TF-IDF算法考虑了词语出现的频率等因素,但是没有考虑与其他词语的关联性,而TextRank算法就考虑到了词语之间的关联程度.TextRank算法起源于Google团队的PageRank算法,其核心思想是,如果网页节点代表一个字词,那么这个词语的重要性与连接其他词语的多少和与它连接的词语权值的高低成正比.
分别使用以上两种算法对文本进行关键词提取,得到了“数据库”“信息安全”“信息资源管理”“计算机病毒”等核心概念,但同时也得到了一些出现频率高,却不是核心概念的词,如“学生”“方法”“过程”等.结合信息技术领域专家的指导,得到最终的学科实体并且定义了基础教育领域信息技术中实体的2种属性关系:“同级”“父级”.如表1所示,构建了包括2种属性关系及其对应的3 563个实例的知识库.

表1 关系及其对应实例
1.2 构建关系实例集在远程监督构建关系实例集中,如果我们文本集中的句子包含的实体对在知识库中有对应的关系,那么我们认为该句子可以描述此关系.以关系实体对<信息技术,传感技术,父级>为例,可以在文本集中找到包含“信息技术”和“传感技术”的句子:1)[传感技术]同计算机技术与通信一起被称为[信息技术]的三大支柱;2)[信息技术]包括[传感技术],通信技术和电子计算机技术等,将这两个句子分别提取出来,作为“父级”关系的两个实例,“信息技术 传感技术 父级 传感技术同计算机技术与通信一起被称为信息技术的三大支柱”,“信息技术 传感技术 父级 信息技术包括传感技术,通信技术和电子计算机技术等”,为了方便模型训练,我们将关系实例的各个部分用空格符分割,这些关系实例构成我们使用的关系实例数据集.
2 关系抽取模型设计
本研究提出一种面向中文基础教育知识图谱的关系抽取模型,基于权威教材教辅和远程监督构建的关系数据集,转化成词向量模型供模型训练,通过双向门限循环单元获得句子上下文语义,引入句子层注意力机制来动态降低句子噪声权重,提升了关系抽取模型的准确率.模型训练算法如图2所示.

图2 模型训练流程
2.1 词向量映射训练为了将数据转换成模型可识别的形式,我们需要将文本数据向量化.Mikolov等[14]提出了分布式的词向量表征word2vec,即一个词用一个低维向量来表示,词与词之间的相似性可以通过向量之间的相关性表示,其中包括2个模型,连续词袋(Continuous Bag-of-Words,CBOW)模型和Skip-Gram模型,由于Skip-Gram模型在语义关系识别方面效果较好,所以本研究采用word2vec中的Skip-Gram模型来对词向量模型进行训练,使用知识库中所有的三元组来进行训练,其中模型参数设置的窗口数为5,向量维度为200.
2.2 BI-GRU传统的循环神经网络通过权重矩阵使神经网络具备了记忆功能,但是由于梯度爆炸和梯度消失的存在,它不能记忆太前和太后的内容.GRU 网络是由 Chung等[15]对 LSTM 网络(一种循环神经网络)进行改进得到的一种结构,由于门控机制,很大程度上弥补了梯度爆炸或梯度消失所带来的损失,同时它简化了LSTM网络,只有更新门(update gates)和重置门(reset gates)两种门结构,因此参数更少,也更容易收敛。其内部结构如图3所示.

图3 GRU内部结构
其更新表达式为:
ht=zt⊗ht-1+(1-zt)⊗h′
(1)
ht-1包含了前一时刻节点的相关信息,zt表示更新门,h′表示当前时刻节点的相关信息,主要是包含了当前的输入xt.从公式中可以得到,zt能控制遗忘和记忆的信息量,它的取值范围为0~1,越接近1,代表“记忆”下来的前一时刻节点信息越多;越接近0则代表“遗忘”的越多.zt计算表达式为:
zt=σ(Wz·[ht-1,xt])
(2)
σ为sigmoid函数,这个函数使数据的取值范围为0~1来表示成门控信号,重置门rt计算表达式为:
rt=σ(Wr·[ht-1,xt])
(3)
h′计算表达式为:
h′=tanh(W·[rt*ht-1,xt])
(4)
上述公式中Wz,Wr,W为权值矩阵,用于模型训练,xt表示当前的输入信息.我们通过上一个节点传输下来隐状态的ht-1和当前输入的信息xt来得到更新门zt和重置门rt,然后使用重置门rt将重置之后的数据通过σ激活函数缩放到-1~1的范围,最后由更新门zt对原本隐藏状态的选择性“遗忘”和对当前信息选择性“记忆”.
为了能够捕获词语的前后特征,本研究采用双向GRU(Bi-GRU)网络作为模型的一部分来提高模型的性能,从而更好地进行关系抽取.Bi-GRU的结构如图4所示.
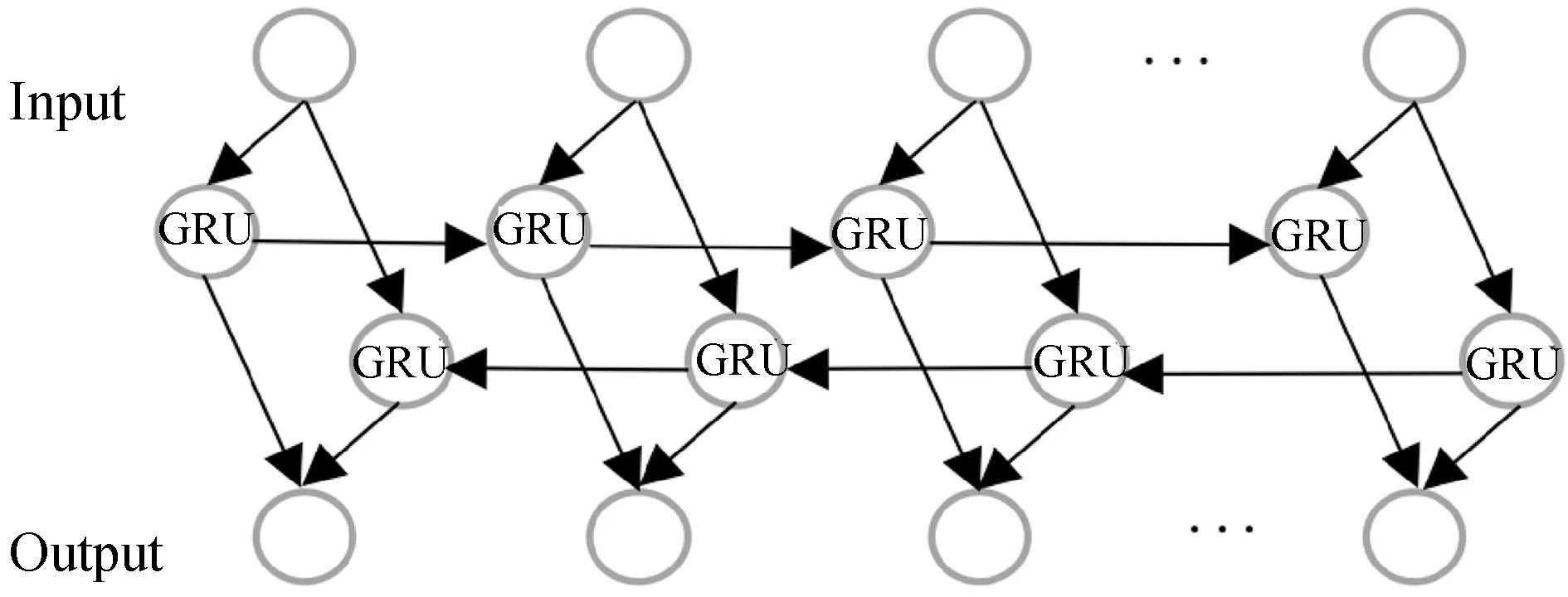
图4 Bi-GRU内部结构
在每一时刻,模型的输入数据会同时经过两个方向相反的单向 GRU,而后通过它们进行输出.
2.3 句子层注意力使用远程监督的方法构建实例数据集中,自动获取的实例有时候并不包含该关系,为了减少噪声数据的影响,本文引入了句子层注意力机制.对于含有相同实体对的m个句子向量集合s={s1,s2,s3,…,sm},si为句子向量,句子向量为s中所有句子的加权,其表达式T为:
(5)
其中,权重Ki表示句子Si与对应关系R的相关程度,其表达式为:
ki=softmax(siAr)
(6)
其中,A为初始化的加权对角矩阵,r为对应关系R的向量表示.
3 实验与分析
3.1 实验数据由于目前还没有通用和权威的针对基础教育信息技术这一领域的公开数据集,因此本研究基于教育部发布的教材教辅采用远程监督的方法构建了关系实例数据集.针对基础教育知识图谱的特性,本文中所构建的语料包含2类属性关系:“同级”“父级”,包含了106 332个关系实例.本研究实验随机选取数据集80%的关系实例数据作为训练数据,其余的20%的关系实例作为测试数据,图5为关系实例数据集片段.

图5 关系实例片段
3.2 评估标准本研究使用准确率(PPrecision)、召回率(RRecall)、F值(F1-score)作为模型的评估标准,来评估关系抽取模型的效果.其计算公式如式(7)~(9)所示:
(7)
(8)
(9)
其中,TP(true positive)表示测试集中该关系的正例被匹配到的数值,FP(false positive)表示测试集中该关系的正例未被匹配到的数值,FN(false negatives)表示测试集中该关系的负例被错误匹配的数值.
3.3 实验结果及分析为了验证本文中方法的有效性和适用性,设置3组实验进行对比.
实验一:在远程监督构建数据的实验上,加入的句子层注意力机制能够减少噪声数据,为了验证去噪数据和未去噪数据关系抽取效果,对于两种关系类型,采用BIGRU与BIGRU+Attention模型进行对比实验.实验结果如表2所示.

表2 BIGRU与BIGRU+Attention模型实验结果
从表2可以看出,加入了句子层注意力机制后,模型的实验结果指标均有提高.主要原因是句子层注意力机制能够减少训练语料的噪声数据,更有效地捕捉句子的特征,使得模型训练得更好,故关系抽取效果更好.
实验二:通过神经网络进行远程监督的关系抽取模型中,PCNN+ Attention模型通过加入句子层注意力来减少噪声标注,对于两种关系类型,采用BIGRU+Attention与PCNN+Attention模型进行对比实验.实验结果如表3所示.

表3 PCNN+Attention与BIGRU+Attention模型实验结果
从表3可以看出,在同样加入句子层注意力机制的远程监督方法中,相比于PCNN神经网络,BIGRU神经网络模型有着更高的准确率和召回率,模型提高了5%左右,这表明BIGRU模型能够提升关系抽取的效果.
实验三:由于中文教育知识图谱的实体关系不同于通用领域的实体关系,目前已知的一些中文教育领域知识图谱实体关系使用支持向量机(SVM),条件随机场(CRF)进行关系抽取,为了验证本文中关系抽取模型对于构建中文教育知识图谱的适用性,在相同条件下,采用SVM和CRF模型进行对比实验.实验结果如表4所示.

表4 SVM、CRF与本文中模型实验结果
从表4可以看出,本研究所提出的关系抽取模型在中文基础教育数据中的关系抽取的F值更高,模型性能更好,适用性更强.主要原因是本研究加入的句子层Attention机制能够减少数据中的噪声问题,同时双向GRU能够解决SVM模型在关系抽取的过程中丢失了词语位置信息的缺点.
4 结束语
本研究针对中文基础教育知识图谱中的实体关系,提出一种基于注意力机制的远程监督关系抽取模型,为验证模型的性能,本研究以信息技术知识图谱为例,构建基于中文信息技术教材教辅的知识库并进行了对照试验,实验结果表明,相比于已知的知识图谱中实体关系抽取方法,基于注意力机制的关系抽取模型能有效提高关系抽取的准确率.后续工作将尝试使用该模型参与中文基础教育知识图谱的构建,提高知识图谱构建效率及准确率,由于中文基础教育领域的公开数据较少,数据前期处理工作量较大,本研究使用的数据不够全面,模型还未达到理想的抽取效果,后期将考虑采用更多更全面的数据,结合更丰富的人工特征,如词性等来改进模型.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中国报道(2009年12期)2009-01-15
