
改进DCL的花卉子类细粒度分类算法
2021-03-04 11:04张立国孙胜春
计量学报 2021年12期
张立国, 刘 博, 金 梅, 孙胜春, 张 勇
(1.燕山大学 河北省测试计量技术与仪器重点实验室,河北 秦皇岛 066004;2.燕山大学 电气工程学院,河北 秦皇岛 066004)
1 引 言
花卉的识别无论在观赏还是育种上都有重要的商业价值和研究价值,尤其是针对同一类花卉不同子类的识别在花卉的培育及基因改善上有重要的应用。针对该问题,国内外科研人员一直在进行积极探索,花卉的子类识别也已成为相关领域重要的课题之一。
在基于特征的花卉分类模型中,面对像牡丹这样子类数量庞大,且存在部分子类相似度较高的情况,传统的手工特征法[1,2]和基于常规图像分类网络的微调方法[3,4]在花卉识别和区分方面能力较弱。相对而言,现有的细粒度图像识别(fine-grained visual classfication,FGVC)方法,往往能根据图像上局部特征找到可区分相似类别的特征进而实现分类。细粒度分类方法可按特征提取方式被划分为两类:一类是根据部分区域的可区分特征定位识别的强监督方法,但需要大量精细的标注如文献[5~7]。另一类则是通过注意力机制自动定位能够将不同类别区分开的局部特征,然后进行细粒度分类的方法,但是头部网络结构相对复杂如文献[8~11]。
在分类损失上,文献[12]提出了focal loss通过控制交叉熵的系数,有效地区分难易样本对损失的贡献,同时解决了训练样本不均衡的问题。文献[13,14]则采用半监督的方式结合contrastive loss实现了快速的图像检索。文献[15]提出的triplet loss则在个体级别的细粒度识别上使用取得了不错的效果。
本文详细地对既有的308类牡丹花的样本特征进行了分析说明,并根据牡丹花的多子类识别展开研究,提出了基于改进细粒度识别(fine-grained image recognition)模型破坏和构建学习(destruction and construction learning,DCL)的分类算法,该方法属于弱监督识别模型,不需要大量对细节信息的标注,同时在训练过程中,使用focal loss解决既有牡丹样本的不平衡问题,参照文献[13]使用contrastive loss结合网络本身的注意力机制扩大相似样本间的类间距,在推理过程中仅提取表示类别的高维特征向量,并将该向量映射到KNN[17]分类器,实现无训练样本数据在分类器中特征向量的自动聚合,达到对无训练样本牡丹进行分类的目的,同时也有效避免了过于复杂的头部网络结构。
2 牡丹子类样本数据分布及划分
现有牡丹花的总体样本数如图1,横坐标表示样本数量的区间范围,纵坐标表示该区间范围内的类别数,参照细粒度识别数据集[18]的划分方法,样本量少于80的不参与训练,从图中可以看出,样本量少于80的子类数仅有9类,这也符合实际中的花卉品种分布情况。所以在数据集划分时,少于80个样本的9个子类仅能用于构成无训练样本的子类的测试集。从数据的整体分布来看,可用于训练的子类类别数量分布极其不均衡,样本量在200~400间的居多,少于200的较少,因此除在损失中使用特定的损失函数,按照以下区间划分设置实验确定样本划分使分类器达到最佳效果也是必要的。
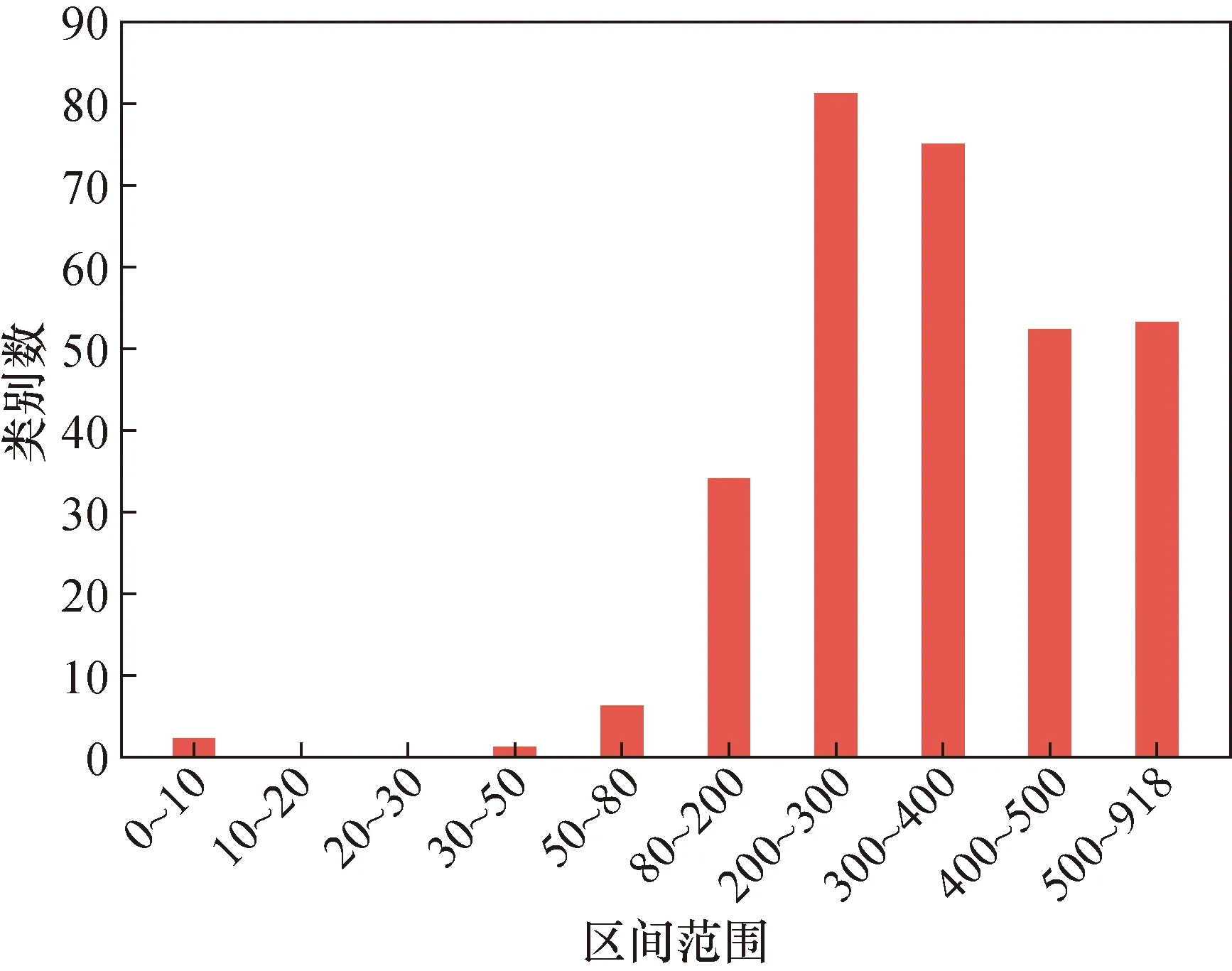
图1 牡丹子类样本数据分布Fig.1 The training samples size diagram
3 DCL细粒度识别算法
3.1 RCM机制
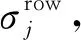
(1)
(2)


图2 RCM前后的八千代椿图Fig.2 The diagram of ba-qian-dai-chun peony before and after RCM
3.2 DCL网络
DCL具体的网络结构如图3所示。首先将原始图像送入骨干网络(classification network蓝色部分),之后用全连接层实现分类。对于RCM之后的图像,同样使用骨干网络提取特征再按照原始图像的标签分类,但由于经过RCM之后直接分类会有部分注意力集中在像素块的边缘,这样会带来噪声,所以引入对抗网络(adversarial learning network)来减小因像素块边界信息带来的噪声。在实际训练过程中,可以将原始输入图片和经RCM解构后的图片同时送入该网络结构模型,在头部网络的分类分支,即classification network,损失为
Lcls=-∑I∈Il·log[C(l)C(Ø(l)]
(3)
式中:Lcls为分类损失;l为类别标签;I表示原始输入图像; Ø(I)表示经RCM解构之后的图像;C表示经过骨干网络和分类网络生成的类别预测。而对于对抗网络分支最后得到的分类结果预测可以写成:
D(I,θadv)=soft max(θadvC(I,θcls))
(4)
式中:C(I,θcls)是从骨干网络中提取的特征样图;θcls是骨干网络学习的参数;θadv是头部网络中对抗网络分支,即adversarial learning network的学习参数,D(I,θadv)是对抗网络分支生成的类别预测,可以得到对抗网络的损失如下:
Ladv=-∑I∈Idlog(D[I])+
(1-d)log[D(Ø(I))]
(5)
式中:d表示图片是否进行了解构,d为0表示图像被解构,d为1表示没被解构;所以当d为1时,Ladv表示对原图进行对抗分支的损失计算,而当被解构时,则只有被解构图的对抗分支损失。

图3 原DCL网络结构图Fig.3 The structure of origin DCL diagram
考虑到相关区域之间的联系,使用另一个分支去学习区域之间的相关性,即使用区域还原网络(region alignment network)对解构的图片进行重构;给定图片和其相关的解构图片Ø(I),同时位于原图(i,j)处的区域R(i,j)应该和位于解构图中相同位置的Rσ(i,j)一致,区域还原网络分支同样和前面提及的分类头部分支和对抗网络头部分支共享骨干网络特征提取参数,之后使用一个1×1卷积层将特征图降为两通道,然后将两通道的特征图通过一个relu函数和平均池化得到新的大小2×N×N的特征图,可得到表达式:
M(I)=h(C(I,θcls),θloc)
(6)
式中:M(I)为该位置在原图中行和列的坐标;h为区域还原网络;θloc是区域还原网络分支的参数。
现在定义解构图中位置Rσ(i,j)在原图I中的位置索引为Mσ(i,j)(Ø(I)),而R(i,j)在I中的原始位置索引为Mi,j(I,i,j),区域还原损失定为
(7)
式中:Lloc为预测位置坐标和原位置坐标L1距离,该损失能有助于骨干网络学到有效局部信息。
最后通过线性加权系数平衡上述介绍的损失函数,在训练过程中公式通过端到端的训练,最小化以下损失函数即可得到细粒度分类结果。
Lmin=αLcls+βLadv+γLloc
(8)
式中:α为类别损失平衡系数;β为对抗损失平衡系数;γ为区域还原损失平衡系数。
4 网络改进
在第2节中提到牡丹数据特征和样本量特征有诸多不适用于DCL网络之处。
首先,因训练样本是不均衡的,将会严重影响分类效果,故引入Focal Loss来代替分类网络和对抗网络中的交叉熵分类损失;再通过平衡系数平衡因样本量不同带来的损失,使难以区分的样本加大损失,容易区分的样本降低损失:
(9)
式中lone为该类标签的one-hot形式。
其次,由于部分牡丹子类没有样本参与训练,且数据随着牡丹新品种的培育会有新的类别产生,如果按照原DCL网络的形式,不仅无法预测没有训练样本的子类,且在随着新牡丹子类的产生更新预测类别时会过于繁琐不够灵活,即如果新培育出一个子类,那么就要重新训练网络将最后分类层新加1个神经元,以适应新的分类网络。所以本文对此提出如下改进,首先在训练时,将骨干网络生成的特征图自适应全局池化后的特征向量级连全连接层实现特征向量的降维,并将这个固定的向量作为分类的依据。其次为了加大不同子类别提取的特征距离,让同一类别内特征距离足够较小,训练时在头部网络的分类分支和对抗网络分支同时加入contrastive loss:
(10)
式中:θcon是从分类特征图到向量的参数;N是训练过程中送入网络Batch的大小;b表示一个Batch内样本之间是否一致标签;m为常数大于最远距离。

经过以上改进,牡丹花的分类网络既能够依靠原有的DCL网络的主体部分提取细粒度特征,同时依靠类间距增大损失使较为相似的子类能够取得较好的分类结果,也能将未经训练的牡丹子类和新培育的牡丹子类进行准确分类。训练时头部网络的分类分支、对抗网络分支和区域还原网络分支都要进行计算,不同的是在原始的DCL网络头部,网络的分类分支和对抗网络分支仅需计算交叉熵损失进行分类即可,而改进之后的DCL网络转而使用focal loss来平衡不同类间样本数量和contrastive loss增加类间距,缩小类内距。
训练完成后将所有类别的训练集进行前向推理,保存经过骨干网络和全连接层得到的固定维度的特征向量。

图4 改进DCL的推理模型结构Fig.4 The inference model structure of DCL is improved
5 实验及结果分析
对样本的牡丹子类进行了一系列的评估,环境的配置:i5-9400F CPU和 GeForce GTX1080Ti;ubuntu16.04,PyTorch1.0和Python3.8;网络输入图片大小为488×488,其中具体的实验包括:
(1) 在保证不过拟合的情况下,样本数能够满足训练要求的类别数;
(2) 改进网络最后的向量提取维度实验,即向量维度为多少时可以保证较高的准确度;
(3) KNN的设置kn为多大能保证较优的准确度。kn表示最近邻居的数量,如果为3则其归类为距离最近的3个向量的投票结果类别;
(4) 改进前后的模型精度及与其他模型的对比试验。
对模型进行验证时,参考文献[19,20]的训练识别流程和多目标识别判别基准,主要选取以下指标作为分类好坏的判别基准:
•Acc:准确率,被分类正确的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
•F1:F1分数同时考虑精确率和召回率,让两者同时达到最高。
对训练样本数量的类进行评估,从图1中选择不同的阈值作为实验的依据,基于经验的考量,本文不考虑80个样本以下的用作训练,实验结果见表1。当以80张作为子类参与训练和不参与训练的临界点时,会出现某些类别训练子本较少导致被其他训练数据“淹没”的情况,所提及的网络不能从这些样本量较少的训练集中学习这类公共特征信息,所以Acc和F1值较低。当选取大于300的样本数量时,可用于训练的子类会急剧减少,这会导致KNN分类器生成的样本空间较为稀疏,且子类间距分布不够均匀,导致分类效果不佳。
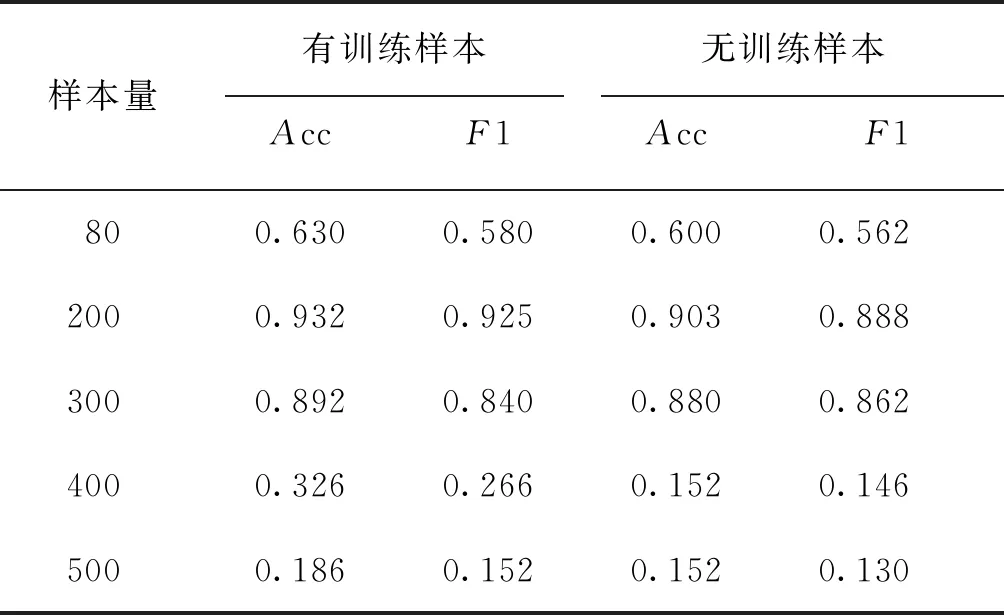
表1 训练样本数据量阈值设置对比Tab.1 Setting and comparing the threshold value of training sample data
在评估向量提取维度数量时,可以满足在不降低准确度的情况下取得最佳效果,本文采用3种维度进行评估,因为既有类别样本的不均衡性,以及Acc不能较好的反应方法的有效性,所以仅用F1作为评价指标,其结果如表2所示。

表2 向量的维度对F1值的影响Tab.2 The effect of vector dimensions on F1 values
由表2可知,当维度降到64维时F1值下降较严重,虽然一个64维的向量可以表示种类别,但由于现有的向量距离度量方式在相近子类中不能取得好的效果,所以低维度的向量不能很好的完成细粒度分类任务。如果选用256维的向量作为KNN分类器的分类依据,由于维数较高,往往需要大量的样本来构成KNN分类器,否则会出现欠拟合导致分类F1分数降低,最终选取128维向量作为特征提取的维度。
需要对KNN分类中最近邻投票向量个数kn进行设置,图5给出了kn从3至10所有子类分类F1分数的统计结果。从图5中可见kn对精度几乎无影响,最终选择kn是为了减小计算量。

图5 F1随kn变化曲线图Fig.5 Curve of F1 with kn
为了评估最终的改进效果,对改进前后的DCL算法模型进行了评估,并以RA-CNN[9]和B-CNN[21]模型作为参照基准评估F1分数,实验中设置200个样本数量作为参与和不参与训练子类的临界值,同时设置提取的特征维度64,对kn=3几种不同的模型进行对比,其中改进后的DCL网络的F1分数评估是所有样本的分类得分最高的,评估对比结果见表3。
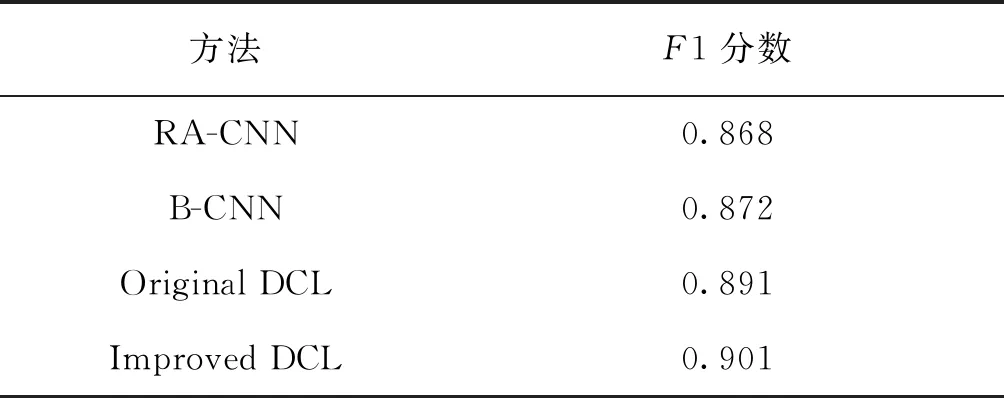
表3 改进后的模型与其他模型的对比结果Tab.3 Comparison of the improved model with other models
6 结 论
本文在细粒度识别网络DCL的基础上,结合KNN分类算法实现了对308种牡丹花的子类进行分类,解决了部分子类因缺少训练样本无法进行识别的问题,同时通过contrastive loss和focal loss解决了训练过程中某些子类较为相似导致分类精度下降和类别不均衡带来的过拟合问题。
实验结果表明:改进算法后有训练样本不仅能够实现无训练样本的子类的分类,而且有较高准确度和F1值,为新培育牡丹子类的识别奠定了良好的基础。后续工作将以从元学习出发,探索如何依据现有的牡丹花样本构建支撑集和询问集,使训练模型能够对有限的新样本自动学习完成牡丹花子类分类任务。
猜你喜欢
红外技术(2022年11期)2022-11-25
高技术通讯(2021年1期)2021-03-29
数学年刊A辑(中文版)(2021年4期)2021-02-12
安阳工学院学报(2020年2期)2020-06-05
科技创新与应用(2020年6期)2020-02-29
数学物理学报(2018年1期)2018-03-26
华中师范大学学报(自然科学版)(2016年6期)2016-12-22
信息安全研究(2016年3期)2016-12-01
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
