
基于数据挖掘的住宅工程造价预测
2021-03-09 07:22王德美肖之鸿夏松林范淑倩崔常辉张清华
土木工程与管理学报 2021年1期
王德美, 陈 慧, 肖之鸿, 夏松林, 范淑倩, 崔常辉, 张清华
(1. 烟台大学 土木工程学院, 山东 烟台 264005; 2. 广东海龙建筑科技有限公司, 广东 深圳 518110;3. 烟台天海房地产开发有限公司, 山东 烟台 264003)
随着工程建设的高速发展,工程建设领域各相关单位都积累了大量的历史工程建设数据,但多数单位没有对数据进行充分挖掘利用,存在“数据丰富,知识贫乏”的现象。工程建设的各项数据和指标之间存在着千丝万缕的关系,利用数据挖掘技术深度挖掘隐藏在繁杂数据背后的规律,可以为快速计价和工程决策提供数据基础。
建筑工程造价预测最初是通过概算指标估算法[1],分别套用概算指标来估算投资额。然而由于项目相关数据的准确性较差,且估算指标过于统一,故投资估算的精度较低。统计分析中的线性回归方法是比较常见的回归方法,但这种方法对异常值较敏感,面对维度较大、较复杂数据集时模型性能差[2]。灰色理论可用以解决“小样本、贫信息”的问题,算法相对简单,属于一种非线性预测方法,但是受初始数据序列波动较大,对高维数据并不友好,因此预测模型的精度较低[3]。随着信息技术和机器学习人工智能的不断发展,近年来国内外逐步兴起了遗传算法、人工神经网络、支持向量机、极限学习机等机器学习算法。其中人工神经网络(Artificial Neutral Network,ANN)和支持向量机算法(Support Vector Machine,SVM)相对更适合于建筑工程造价预测建模。很多学者使用人工神经网络的方式进行建筑工程的造价预测研究[4,5],虽然ANN与传统的统计方法相比,模型预测精度有所改善,但是ANN在大样本下才能得到较优结果,且ANN容易出现局部最优的缺陷。相对于ANN,SVM在小样本预测领域有独特优势。
本研究利用历史住宅工程造价信息进行数据挖掘,并进行造价预测研究和分析。通过数据清洗和异常值筛除得到的有效样本,分别利用不同的特征指标选取方式构建SVM模型,选取更为合理的预测模型。此外,对单方造价、分部分项工程费、措施项目费等多种费用进行预测,探究何种费用项预测性高,可以用SVM方法得到良好的预测结果,进而应用于工程实际。
1 数据与指标的选取及数据预处理
在通过机器学习方法进行住宅工程各造价项的预测研究时,具备一个完备的数据集是重要前提,实际上,原始数据的搜集和预处理工作往往占整个数据分析工作的70%以上。本研究的数据来源于广联达指标网,陕西省西安市2014—2017年签约的住宅工程。拟预测的造价项包括含其他项目费的单方造价(指标名称为原单方造价),不含其他项目费的单方造价(指标名称为单方造价),以及单位建筑面积的分部分项工程费、措施项目费、其他项目费、规费、税金等,如表1输出指标所示。结合文献调研及专家访谈,本研究确定了19个特征指标作为造价预测模型的输入指标,如表1所示。输入指标又分为定性指标和定量指标。定量指标按原数值输入,定性指标按表2的编码方式处理。机器学习中定性指标的编码方式有多种,各有其优劣。本文采用特征哈希的思想,对定性指标进行编码,每种定性指标的编码为相邻的自然数,此外,为了增强哈希特征工程的可解释性,对“是否有人防”“抗震烈度”“装修类别”“外立面装饰”和“室内装饰”五个定性指标,按相应各类别造价由低到高的顺序依次进行由小到大的编码,如表2所示。

表1 住宅工程造价预测指标
原始数据集易出现混乱、不完整、有噪音、数据不一致、数据冗余、数据类型不合理等现象。数据的预处理包括数据清洗、数据类型转换、异常值处理等工作。在进行初步的数据清洗剔除无效样本后,共保留180条有效样本,并按表2的方式进行定性指标的数据类型转换。
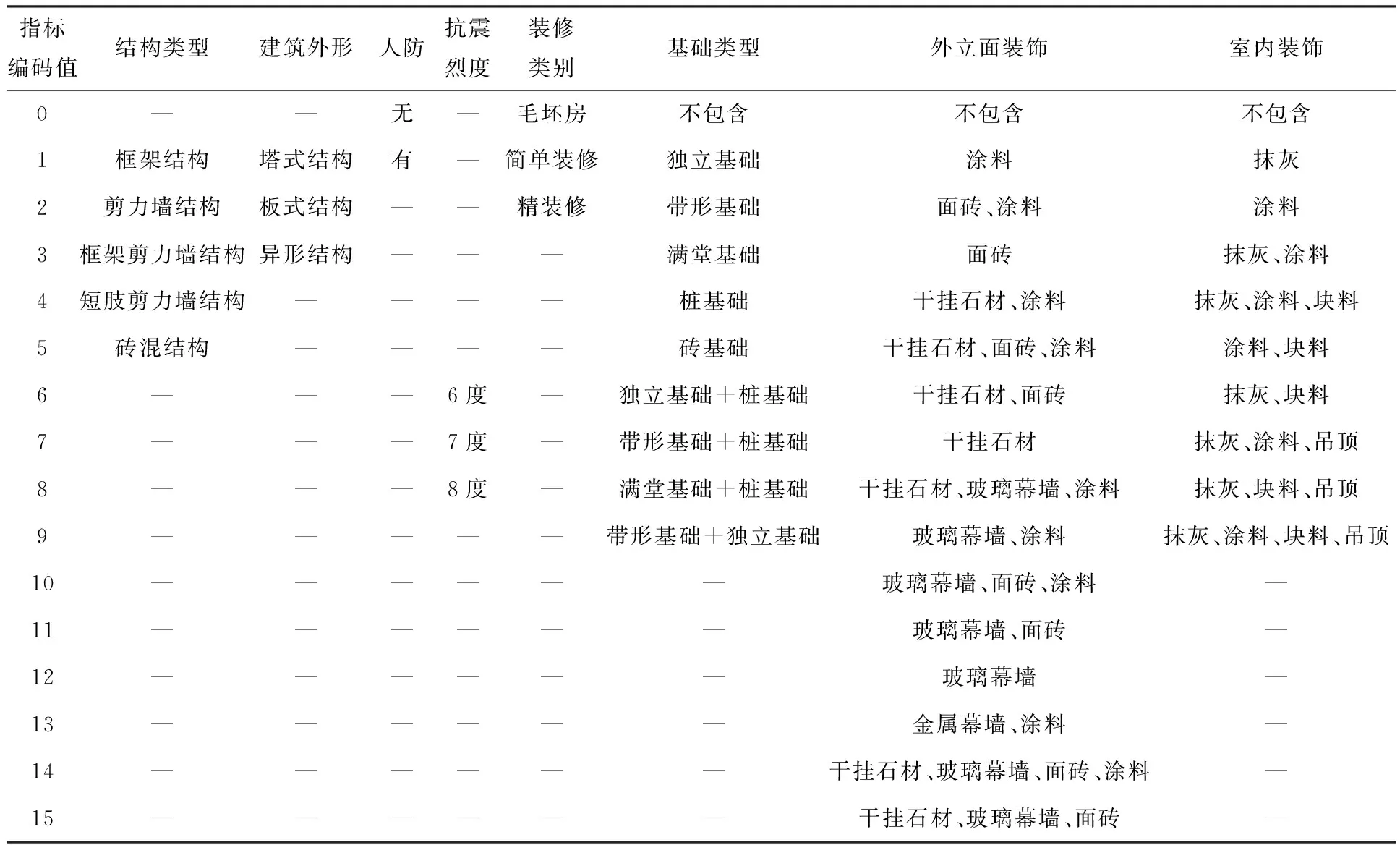
表2 定性指标编码
除此之外,数据预处理还包括异常值处理。在住宅工程造价预测样本量很少的情况下,离群点以及异常值的存在对模型性能的影响非常大。本文采用K均值聚类方法实现异常值以及离群点的识别和筛除。K均值聚类可将相似度高的样本聚在一起,将相似度差距大的样本分开,具有收敛速度快,解释性强,聚类效果好的优点。但是K均值聚类需要提前确定聚类数K值,K的取值对聚类结果影响较大,因此,在聚类数未知的情况下,合理确定聚类数K值是关键。本文借助MATLAB软件绘制拐点图的方法合理确定最优K值,实现对传统K均值聚类的改进。
如图1所示,横坐标代表聚类数,纵坐标D=组内平均距离/组间平均距离,由D的定义可知,D越小代表聚类效果越好,但是D过小,所划分的类别数过多,则其实际应用价值就会降低,故K的取值需适宜。根据肘部法则,图线突变点的位置为最优K值,由图1可知最优K值为10。K值确定后,本研究选用SPSS工具进行K均值聚类,聚类结果如表3,第2~4,7~10类样本呈零星分布状态,视为离群点,需筛除,保留样本最为集中的第1,5,6类共160条项目为最终样本。部分样本数据如表4所示。

图1 最优K值确定

表3 改进的K均值聚类结果

表4 样本造价数据分布节选
2 支持向量机(SVM)
2.1 SVM原理
支持向量机(SVM)理论是从线性可分情况下的最优分类线发展而来的[6],作为机器学习领域的经典算法,可应用于多分类以及回归问题。为了提高SVM的适应性,使用软间隔支持向量机,引入松弛变量。SVM的关键在于核函数,低维空间向量集通常难于划分,解决的方法是将它们映射到高维空间。核函数的存在使得SVM算法既能找到最优低维向高维的映射方式,又能巧妙降低模型的计算复杂度。本文选取的核函数为非线性支持向量机常用的径向基核函数(Radial Basis Function,RBF),此外,利用SMO(Sequential Minimal Optimization)算法进行模型优化,以降低模型训练时间和计算过程的复杂化[7,8]。SVM引入了结构风险最小化原理和核函数,特别适合小样本工程造价预测。
2.2 SVM在住宅工程造价预测中的应用
本研究利用上述160条样本构建SVM模型预测单方造价,模型样本分为训练集和测试集。预测集数量较小时,容易产生过拟合问题,但是在小样本的前提下,预测集数量较多又可能造成测试集“浪费”太多的训练数据,出现欠拟合。因此,选取其中127条数据(占比79%)为训练集,33条数据(占比21%)为测试集。
模型结果分别如图2,3所示。此处的R2衡量的是回归方程整体的拟合度,表示预测精度。训练集的R2为0.90141,测试集的R2为0.92836,均为高水平,模型良好。

图2 SVM训练集单方造价预测结果对比

图3 SVM测试集单方造价预测结果对比
造价预测模型初步建立好之后,通过启发式方法进行指标的二次确认,依次将单个特征指标(如建筑外形)和组合指标(如地上建筑面积和地下建筑面积)删除后,重新运行程序对比预测结果的精度,发现任何单个指标或组合指标的删除都会或多或少降低模型精度,尤其是删除基础类型指标,或是删除地上地下层数,这两种指标的删除都会导致模型精度大幅降低,因此现有的指标需要全部保留。
3 偏最小二乘回归(PLSR)与偏最小二乘回归支持向量机(PLSR-SVM)
3.1 PLSR与PLSR-SVM的原理
为了提高训练和预测效率,降维也是数据挖掘分析的重要环节,主成分分析(Principal Component Analysis,PCA)是常用的降维方法,通过正交变换的方式将原始变量线性组合成几个互不相关的综合变量,再选出其中少数几个有代表性的综合变量作为主成分,实现对高维变量空间的降维。然而PCA应用在回归中的降维仅仅根据自变量系统选取出主成分,并不考虑对因变量的影响程度,导致会出现在自变量系统中贡献率低而对因变量有着重要影响的指标会被误删,而在自变量系统中贡献率高却对因变量解释能力差的指标反而被选为主成分等问题。偏最小二乘回归(Partial Least Squares Regression,PLSR)巧妙解决了这个问题,PLSR在主成分分析的基础上引入了多元线性回归分析以及典型相关分析,建立起自变量系统和因变量之间的联系,要求所提取的主成分必须对因变量有最强的解释性[9,10]。PLSR可用于回归,也可仅用于指标降维。
因此,针对目前有学者在研究建筑工程造价预测时,使用PCA降维后的指标构建SVM预测建模的PCA-SVM方法[11,5]。本文提出一种改进算法,使用PLSR降维后的指标构建SVM造价预测模型,即PLSR-SVM。

图4 主成分贡献率

图5 PLSR测试集预测结果

图6 PLSR-SVM训练集预测结果
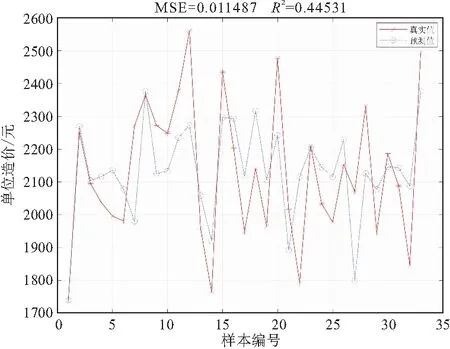
图7 PLSR-SVM测试集预测结果
3.2 PLSR与PLSR-SVM在住宅工程造价预测中的应用
在用上述样本做PLSR时,当主成分数量为10时,PLSR的预测精度能达到最高,为0.29456,如图4,5所示,此时的累计方差贡献率接近100%,远大于85%,可提取。利用得到的10个综合指标构建 SVM模型,得到PLSR-SVM的预测结果,如图6,7所示,训练集和测试集的R2分别为0.97496和0.44531。SVM和PLSR-SVM的R2高于PLSR,可看出单独利用PLSR方法做造价预测是不可取的,因为输入指标与输出指标之间并不是单纯的线性组合关系。故接下来不再单独考虑PLSR方法进行回归建模,而是进行SVM与PLSR-SVM的进一步对比分析。
4 预测模型结果对比分析
4.1 基于SVM和PLSR-SVM的单方造价预测结果分析
将上述基于SVM和PLSR-SVM两种方法的单方造价预测结果汇总于表5,各模型评价指标汇总于表6。其中MSE为损失函数,是衡量平均误差的指标,值越小代表预测的精度越高。由对比结果可知,相对误差和绝对误差的极差与误差平方和SSE,均是SVM模型更优,故SVM鲁棒性优于PLSR-SVM模型;SVM模型的R2和MSE性能更优,故SVM模型精度优于PLSR-SVM模型。因此,SVM模型的鲁棒性和预测精度更优。PLSR-SVM模型唯一优于SVM的一点在于运行时间更短,但是笔者认为,在实际应用过程中,几秒钟的时间差的影响是微乎其微的。故综合考虑预测精度、鲁棒性以及运行时间,SVM明显优于PLSR-SVM。

表5 基于SVM和PLSR-SVM模型的预测效果对比
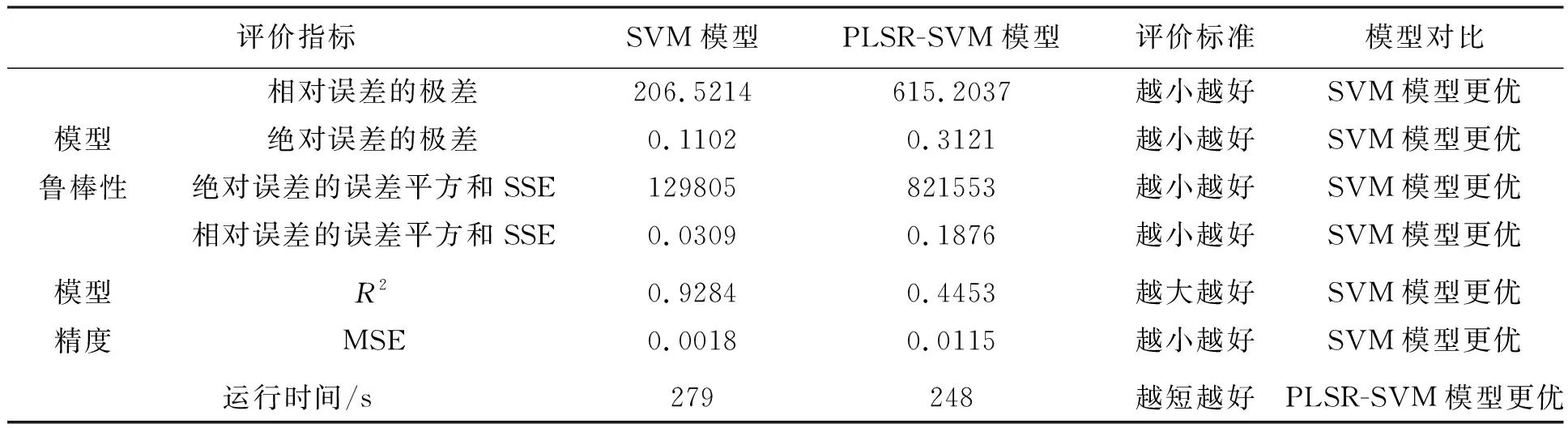
表6 基于SVM和PLSR-SVM模型评价
分别利用SVM和PLSR-SVM两种方法,对单方造价、原单方造价、分部分项工程费和措施项目费等进行预测,结果汇总于表7。通过纵向对比发现,利用PLSR-SVM的预测精度普遍低于SVM。正如前文所述PCA方法降维的弊端,本研究使用性能更优的PLSR方法进行降维,却发现PLSR-SVM的预测性能依然远不如原SVM模型,说明无论是PCA还是PLSR进行指标降维,都是一种线性的指标综合方式,而实际的特征指标与造价之间是一种复杂的非线性关系,故而将特征指标进行降维后再建立SVM非线性回归模型,反而使得特征指标与输出指标的关系更混乱,对预测精度及鲁棒性造成了恶劣的影响,因此,这样的特征指标降维处理不适用于工程造价的预测。
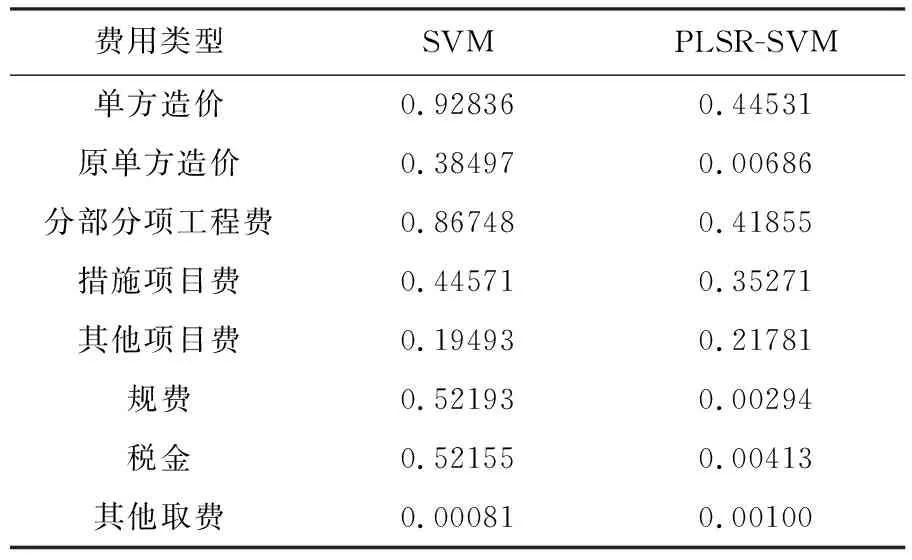
表7 各费用项预测结果对比
4.2 工程造价其他费用组成部分造价预测对比析
通过上述分析,原始特征指标构建的SVM模型更适用于住宅工程造价预测,故进一步对表6的各费用项的SVM预测精度进行对比分析。单方造价的R2能达到93%,而原单方造价仅能达到38%,差距较大。究其原因,本文定义的原单方造价中其他工程费和其他取费是包含在里面的,而其他项目费主要包括暂列金额、计日工和总承包服务费,这些费用项都是施工合同签订时暂定或暂估的费用项目,具有很强的主观性,规律性差,可预测性差,由表7也可证明利用SVM进行其他项目费和其他取费的预测精度极低,在0.2以下。故本文将对原单方造价减去其他项目费以及其他取费后得到的单方造价进行分析,结果可靠。
此外,分部分项工程费的预测精度较高,接近0.9,而措施项目费、规费、税金的预测精度为0.5左右,精度较低。这是因为分部分项工程费是指构成工程实体的费用,与工程特征指标之间具有很强的相关性,而且在当今建筑市场竞争激烈的情况下,分部分项工程费的调价空间非常有限,因此,分部分项工程费的规律性强,可预测性较好。而措施项目费是非实体费用,是投标报价中调价最主观的费用项目,因此,在同样的特征指标下,措施项目费的预测精度远远低于分部分项工程费。而规费和税金是以分部分项工程费、措施项目费、其他项目费之和按费率取费的,故规费与税金的可预测性亦较低,不适用于造价预测。
分部分项工程费在建安工程费中占比较大且相对稳定,也再次证明工程造价的可预测性,进而证明利用机器学习方法进行工程建设数据挖掘分析的可行性。
5 结 论
本研究通过进行一定的数据预处理,以及对各造价预测模型结果进行对比分析得到以下结论:
(1)本文提出的改进的K均值聚类进行异常值识别和筛除是有效的,对其他研究的异常值处理有一定的借鉴意义;
(2)PLSR是一种很好的线性指标降维方法,但并不适用于利用SVM方法进行住宅工程造价预测时的指标构建过程,利用原始特征指标构建的SVM模型,预测性能更优;
(3)措施项目费、其他项目费等可预测性相对较差,这与工程差异性大,费用主观性强等原因有关。而剔除其他项目费的单方造价与分部分项工程费两个费用项的可预测性强,可用SVM方法得到良好的预测结果,进而用于工程实际。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
车主之友(2022年4期)2022-08-27
党员生活·下(2022年3期)2022-04-23
中国现代医生(2022年6期)2022-04-23
汽车实用技术(2022年4期)2022-03-07
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
互联网天地(2016年1期)2016-05-04
