
融合多特征TFIDF 文本分析的汽车造型需求提取方法*
2021-03-11 03:48季曹婷马伟锋马来宾
电子技术应用 2021年2期
季曹婷,马伟锋,楼 姣,马来宾
(浙江科技学院 信息与电子工程学院,浙江 杭州310023)
0 引言
在智能制造的背景下,个性化生产是未来制造业发展的必然趋势, 用户除了对商品基本功能的要求之外,个性化定制的需求正不断地增加[1]。 汽车制造业是智能制造的典型应用行业,根据调查,我国超过七成的消费者认为汽车造型是决定购买汽车时的首要考虑因素[2],因此汽车造型能否符合用户需求是个性化汽车造型设计成败的关键[3]。 目前,汽车造型的用户需求描述主要以文本数据形式存在[4]。 自然语言处理技术是当前文本分析的主流方法,通常采用无监督方法进行自动关键词提取。 但是该算法完全基于词频,忽略了词语其他特征对关键词提取影响的问题[5-7]。 许多研究人员对此展开研究,赵晓平[8]等人提出文本结构特征与经典的TFIDF方法进行融合,应用于科技项目文本的相似度度量计算中;牛永洁[9]等人不仅考虑到词频、词跨度和位置权重特征,还考虑到词性、词长与语义关联度因素,相比经典的TFIDF 算法有所改进;然而在实际应用中,不仅要考虑到词汇本身的特征信息,而且还需要考虑应用场景的问题。 所以余本功[10]等人在解决问答社区关键词提取的问题时融合了词汇特征与社会化问答社区文本的用户关注属性来综合度量词语权重,提升了社区问答关键词提取的效果。

图1 融合多特征TFIDF 文本分析的汽车造型需求提取方法流程图
虽然上述研究均取得了一些成果,但是无法有效地对汽车造型的用户需求文本进行提取。本文利用融合多特征TFIDF 算法对用户需求文本数据进行分析, 获取有效的用户需求特征,为汽车造型设计的需求确定提供支撑。
1 方法
本文提出一种融合多特征TFIDF 文本分析的汽车造型需求提取方法,具体方法流程如图1 所示。
由图1 可知,首先基于汽车之家口碑语料库计算得到未登录词汇,结合分词工具从用户需求文本中获取修正后的分词词汇;然后计算词汇特征以及情感特征,并利用改进的TFIDF 算法量化词汇权重,获取用户需求特征候选集;最后根据实验数据确定阈值,得到有效的用户需求特征。 其中,未登录词汇获取方法和融合多特征TFIDF 算法是有效提取用户需求的关键。
1.1 未登录词汇获取方法
用户需求特征提取首要任务是分词,然而面对口语化的汽车造型风格文本描述, 存在着大量未登录词汇,如“腰线很犀利”、“整体车身流线”、“小蛮腰”等出现频率很高但传统分词工具难以区分的词汇。本文基于互信息[11]与边界自由度[12]获取未登录词汇,具体方法流程如图2 所示。

图2 未登录词汇获取方法流程图
由图2 可知,首先对语料库进行分词,然后统计分词词汇的频率信息, 并根据定义计算边界自由度和互信息, 最后根据本文自行确定的阈值确定未登录词汇。
1.2 融合多特征的TFIDF 算法
1.2.1 词汇特征因素
由于TFIDF 算法仅考虑了词频信息,没有全面地考虑词汇的本身特性,因此本文从词汇的位置信息、词汇词性、词汇跨度3 个方面进行考虑,具体内容如表1 所示。

表1 词汇特征表
由表1 可知,词汇位置信息考虑到首句、末句两个因素,因为文本的首句往往最能体现全文的主题,末句往往是全文的总结性文字描述;词汇词性考虑到名词、形容词和动词3 个因素,因为在关键词分布中一般以名词或名词性短语、形容词、动词为主。词跨度反映了描述词汇的描述范围,跨段数越多反映该词越重要,全局性越强。 |li|为文档di中包含词汇的句子总数量,|L|为文档di的分句总数目。
1.2.2 词汇情感特征因素
根据汽车造型设计任务主要是对正向情感文本描述进行用户需求分析的实际要求,提出一种基于语义规则的情感特征计算方法,核心思想是基于汽车造型情感词典,利用词语搭配规则与句型分析规则计算词汇的情感强度,其中情感词典是基于知网词典与BosonNLP 词典,并结合本文的实际需求,构建了情感词典、否定词典与程度副词词典,详细计算方法与定义如表2 所示。
1.2.3 算法步骤
TFIDF 算法是基于统计的自动关键字提取最具代表性的方法之一,其核心思想是提取某一文档内容的关键字候选集以及对应的权重[13]。 如果某关键词出现在某一文档的频率越高, 同时出现在其他文档的频率越少,表明该词具备本文档与其他文档区别的能力。 TF 为某个词出现在一篇文档的次数,IDF 是该词区别于其他文档的能力。TF 与IDF 具体计算方法如式(1)所示,融合多特征的TFIDF 方法具体定义如式(2)所示。

表2 基于语义规则的计算方法

表示所有文档中关键字出现的次数之和;|D|为语料库中的文档总数,|Di|为包含关键词ti的文档总数目。

权重Wij反映了关键字ti在文档dj占比,数值越大,反映了关键词所占比重越大。 其中,Wspan为词汇跨权重,Wloc为词汇位置权重,Wseepch为词性权重,Mij反映了关键词ti在文档dj中的情感权重。 具体算法步骤描述如下:
(1)对用户需求文本描述进行文本预处理,将文本dj划分为n 个句子。 并载入人工构建的词典、未登录词汇和停用词去除重复词汇和停用词,对分句s 进行分词,形成相应的词汇集C。
(2)记录每个分词Ci的词汇信息与在句中的位置Iindex,并以字典形式存储。
(3)若Ci为情感词汇,在情感词表中寻找情感词,以每个情感词为基准,向前依次寻找程度副词、否定词,并作相应分值计算。
(4)判断该句是否为感叹句,是否为反问句,并作相应分值计算。 获得该词汇所在分句的情感强度,即词汇Ci的情感特征权重Mij。
(5)计算词汇Ci的位置特征权重Wloc、词性特征权重Wseepch与词跨度权重Wspan,并根据式(2)量化词汇权重Wij,利用改进的TFIDF 算法分别得出用户需求特征的关键词候选集k 及其权重w。
2 实验与结果分析
2.1 数据集
为了验证本文方法的有效性,选取来自汽车之家网站的用户口碑语料库进行实验对比与分析,并选取2 952篇口碑汽车造型评价数据作为验证集,人工标注合计9 351 个关键词标签。 关键词标签数据主要描述了用户属性(如用户性别、年龄阶段、用途和工作性质)和汽车风格属性(如时尚、霸气、硬朗等),实验命名这个数据集为PUBLIC-PRAISE。
2.2 实验结果分析
实验采用准确率[14](precision)、召回率[15](recall)和F1值[16](F1-Measure)来评价关键词提取的效果。
2.2.1 融合不同特征的TFIDF 效果对比
为了验证获取未登录词汇方法与融合多特征TFIDF方法的有效性, 在PUBLIC-PRAISE 数据集合上进行不同组合的实验效果对比,具体实验结果数据如表3 所示。

表3 不同特征组合的TFIDF 效果对比
对表3 分析可知,相比于经典的TFIDF 算法而言,本文方法在关键词提取效果上有明显提升,原因在于:(1)引入未登录词汇方法解决了用户需求文本描述中出现传统分词工具不能识别的词汇,一定程度上提升了传统分词工具的分词能力;(2)引入词汇特征解决了经典的TFIDF 方法仅考虑词频信息的问题,从词性、词位置与词跨度角度考虑能够提升关键词提取能力;(3)由于包含负面情绪的文本数量较少,因此引入情感特征准确率稍有提升,也说明引入情感特征符合本实验的实际需求,能够去除文本中负面情绪的相关词汇。 总体上,本文的方法相比于经典的TFIDF 方法在关键词提取效果上有所提升,不仅解决了仅考虑词频信息的问题,而且考虑到了正向情感的用户需求分析的实际问题。
为了提升本文方法的关键词提取的性能,分别设置不同关键词提取个数进行探索,实验结果如图3 所示。

图3 不同关键词提取个数效果对比
对图3 分析可知,当关键词个数K ≤25 时,随着关键词个数的增加,提取效果呈现不断上升的趋势;当K>25 时,提取效果呈现趋于平稳的趋势。 所以,选取K=25 作为关键词提取个数。
2.2.2 与两种改进的TFIDF 方法对比
根据文献[10]提出的基于多属性线性加权的TFIDF与文献[9]提出的融合多因素的TFIDF 两种关键词提取方法,基于PUBLIC-PRAISE 数据集合,引入未登录词汇,并统一关键词提取个数K=25,将两种改进的TFIDF 方法与本文改进的关键词提取方法进行实验对比,具体实验结果如表4 所示。
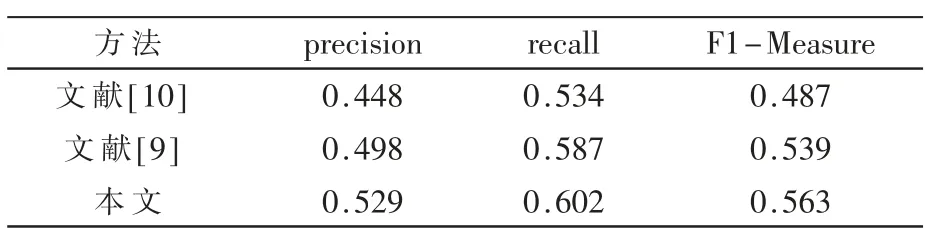
表4 本文方法与改进的TFIDF 方法对比
对表4 分析可知,本文方法相比于两种改进的算法,在准确率、召回率与综合评价指标的F1 值上提取效果有了明显的提升。 原因在于:(1)本文基于文献[10]的思想,引入词频、词性特征以及用户评论数、赞同数和浏览数用户关注属性特征。 根据实验结果分析可知,引入用户关注属性对关键词提取意义不大。 (2)文献[9]仅考虑了词汇本身的特征,如词频、词性等特征,而本文需要提取出正向情感的用户需求特征,因此该方法不适用于本文研究的实际情况。
为了对比3 种方法应用于不同文本数量的效果,分别随机选取500、1 000、1 500、2 000、2 500 条文本集,引入未登录词汇,并统一关键词提取个数K=25,进行关键词提取,得到的实验结果如图4 所示。

图4 不同文本数量下3 种方法对比
对图4 分析可知,文献[10]随着本文数量的增加提取关键词的能力变弱,文献[9]的方法随着本文数量的增加提取关键词的能力趋于平稳,而本文方法的综合指标F1 值不仅明显大于其他两种方法, 而且呈现增长的趋势,反映了本文方法具备良好的性能。
总体而言,本文方法相比于现有基于TFIDF 改进的方法效果有所提升,并取得了一定的实验效果。
2.2.3 用户需求特征提取
以3 位用户的汽车造型风格评价文本描述为例,利用本文方法进行用户需求特征提取,获取文本描述的关键词以及对应的权重,具体文本描述和关键词提取结果如表5 所示。
由表5 可知,用户1 仅包含正向情感的用户需求文本描述,而用户2 和用户3 不仅包含正向情感的用户需求文本描述,而且存在负向情感的文本描述。 所以设置阈值P=0,筛选出大于阈值的用户需求特征,根据用户需求特征提取结果可知,用户3 中去除了无效的负向情感词汇,得到了有效的用户需求特征。

表5 用户需求文本特征提取结果
3 结论
本文基于统计思想的关键词提取方法,综合考虑词汇特征与情感特征,提出适用于汽车造型设计领域的用户需求文本特征提取方法,相比于经典的无监督提取方法和现阶段研究的无监督关键词提取方法性能有所提升。结果表明,该方法能够有效获取用户需求特征,且辅助汽车造型设计师完成用户需求分析的任务。 当然,该方法还存在不足之处:仍需要人工构造词汇集和人工筛选未登录词汇的手段,确保关键词提取的有效性,且该方法采用的词汇特征和情感特征不能完全反映文本的的语义信息,所以该方法的关键词提取性能仍需进一步提升。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
校园英语·月末(2021年13期)2021-03-15
当代陕西(2020年17期)2020-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
人大建设(2018年5期)2018-08-16
信息安全研究(2016年4期)2016-12-01
应用科技(2015年5期)2015-12-09
