
利用邻域方向分布的机载激光雷达点云建筑物外轮廓提取
2021-03-25 12:23郭海涛王优扬余东行林雨准
光学精密工程 2021年2期
赵 传,郭海涛,王优扬,卢 俊,余东行,林雨准
(战略支援部队信息工程大学地理空间信息学院,河南郑州450001)
1 引 言
建筑物是城市的主要组成元素,其轮廓不仅包含建筑物的位置和形状信息,而且可作为一种先验形状信息推断建筑物结构以辅助建筑物三维模型重建,在城市规划、城市空间分析、污染建模和灾害管理等方面有着广泛应用,因此建筑物轮廓提取一直都是研究的热点[1-3,4]。传统三维建筑物轮廓主要通过立体影像采用半自动方式采集,得到的结果虽然精度高,但同时也存在成本高、周期长等问题,因此成果的现势性难以得到有效保证[5]。机载激光雷达测量(Light Detection and Ranging,LiDAR)作为近十几年发展迅猛的一种新型、高效的空间数据获取技术[6],通过其采集的点云数据已成为现阶段建筑物轮廓自动提取的重要数据源。然而,由于建筑物形状复杂多样、点云数据具有分布不规则和密度不均等特性,以及传感器扫描模式不同和场景中其他地物(如高大植被)遮挡等多种因素的影响,自动、准确地提取建筑物轮廓仍然具有较大的挑战[7]。
在过去的几十年里,针对机载LiDAR点云中建筑物的轮廓提取问题,很多学者进行了积极的探索和研究,现有的提取方法大致可以分为间接法和直接法两大类。间接法通过将点云内插为深度图像,然后利用如Sobel,Canny,Edison算法等图像领域成熟的算法提取建筑物轮廓点[8-12],这类方法需将点云从三维空间转换到栅格二维图像再提取建筑物轮廓,虽然降低了提取的复杂度,但存在难以确定合适的格网大小、提取结果的精度相对较低等不足[5]。直接法无需进行数据转换,直接作用于点云,根据提取轮廓时采用的策略,这类方法可以分为监督和非监督两种。监督的方法需要预先采集轮廓样本,然后采用机器学习算法训练模型,利用训练的模型预测得到轮廓初始提取结果,再经过后处理得到轮廓提取结果,如文献[11]采用传统的机器学习算法随机森林(Random Forest,RF)、文献[13]首次提出基于点云数据的边缘感知深度神经网络EC-Net。这种方法的优势在于可直接针对整个场景的点云进行处理,无需先提取建筑物点云,但其提取的轮廓比较粗糙(通常在局部范围内为无序分布的点簇,而不是前后相连的点链),即使通过后处理,也难以得到点链状的结果;此外,这种方法还需要预先标记大量轮廓点数据用于模型的训练,而标记轮廓点很费时。非监督的方法通常直接取点云的前两个维度,在二维平面上进行处理,包括凸包(Convex Hull)[14]及其改进算法[15-16]、凹 包(Concave Hull)算 法[7,17]、Alpha Shapes[1,18]及其改进算法[19-21]、最小外接矩形法[22-23]和其他算法[4,24-25]等。其中,凸包和凹包及其改进算法通常存在漏提取部分轮廓点的情况。Alpha Shapes算法应用最为广泛,最先由Edelsbrunner等[18]提出,沈蔚等[1,26]首次将该算法用于建筑物轮廓提取,并表明该算法十分适用于从Li-DAR点云数据提取任意形状的建筑物轮廓,具有一定的适应性。然而,Alpha Shapes算法仅通过半径α控制提取轮廓的精细程度,虽然能较好地提取密度分布均匀点云的轮廓,但对密度分布不均的点云,通常难以设置合适的α,当α设置过大时,会出现凹型区域的角点(下文简称为凹拐角点)漏提取现象。尽管已有学者对α的设置进行了研究[19-21],但这些改进算法仍对点云密度的变化比较敏感,且也存在部分关键凹拐角点漏提取的现象。最小外接矩形法的提取结果为规则的建筑物轮廓,但其难以适用于任意形状建筑物轮廓提取,局限性较大。其他算法未能得到较广泛的应用,此处不再赘述。
针对现有从建筑物点云中提取轮廓的算法存在参数难以设置、适用性不强等问题,本文提出一种利用邻域方向分布的机载LiDAR点云建筑物外轮廓提取方法。一方面,不再只是分析点与其单个邻域点之间的关系提取轮廓点,而是分析点的邻域整体分布情况,从而降低参数设置的难度,提高算法的适用性;另一方面,通过构建不规则三角网,对边进行操作,实现无需设置边长阈值即可跟踪轮廓点,能较好地保持凹拐角点,并得到有序的建筑物外轮廓提取结果,为建筑物三维模型重建等应用提供稳定、可靠的建筑物外轮廓信息。
2 方法原理
本文提出的建筑物外轮廓提取方法主要包括初始轮廓点提取和轮廓点跟踪两个步骤,其中,初始轮廓点提取利用邻域点的方向分布,计算不同方向之间的夹角,通过相邻方向间夹角的最大值判断是否为轮廓点;轮廓点跟踪通过构建不规则三角网,对边进行删除、添加等操作,然后以边为跟踪基元得到有序轮廓,再基于设计的规则进行后处理。由于跟踪后得到的轮廓点数和初始轮廓点数并不一定相等,因此轮廓点跟踪也可视为对初始轮廓点的精化。图1为方法的流程图。
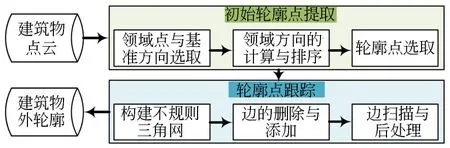
图1 利用邻域方向分布的建筑物轮廓提取流程Fig.1 Flow chart of building outline extraction based on neighbor point direction distribution
2.1 初始轮廓点提取
建筑物轮廓可定义为建筑物立面与屋顶面的交线,一般具有连通、封闭等特性[5],如图2(a)所示从影像上人工提取的建筑物轮廓线。由于机载LiDAR获取的点云数据包含建筑物立面点较少,且获取的点云具有分布不规则、密度不均匀等特性,此外还可能存在部分屋顶点云数据缺失的现象,因此很难保证仅利用机载LiDAR点云提取的建筑物轮廓会在同一直线上,也难以对点云中的建筑物轮廓进行准确定义[16]。从图2(b)和图2(c)可以看出,即使能准确地获取建筑物点云,从点云中人工提取的建筑物轮廓点也不会都在真实轮廓线上。文献[17]指出,对于给定的点集,其凸包是唯一的,但其凹包不唯一,凹包是否能作为点集的最佳描述取决于最终的应用。考虑到真实场景中的大部分建筑物轮廓为凹包,为了能尽可能多地提取建筑物外轮廓点,为后续建筑物三维模型重建提供稳定、可靠的外轮廓信息,将建筑物点云数据中所有潜在轮廓点视为建筑物初始轮廓点进行提取。

图2 建筑物影像及不同方式获取的轮廓Fig.2 Image of a building and corresponding outline by different approaches
建筑物点云中任一点与其邻域点可构成多个方向向量,本文定义潜在轮廓点为相邻方向向量之间夹角的最大值(简称最大夹角)不小于90°的点。具体地,如图3所示建筑物点云(已投影到二维平面),p0为建筑物点云中的任一点(图中黄色点),Sp0={q1,q2,…,qk}为点p0的邻域点集(图中蓝色星号点),其所有邻域点qi(i=1,2,…,k)均可与点p0形成方向向量p0qi(图中蓝色实线),其中向量p0q1和p0q2之间的夹角α0为点p0的最大夹角,从图3可以明显看出,α0<90°,因此点p0不是建筑物轮廓点(彩图见期刊电子版)。然而,对于图3中的点p1,p2和p3,其最大夹角α1~α3均不小于90°,因此这些点将被视为建筑物初始轮廓点。结合图3及本段分析可知,本文定义的潜在轮廓点可较好地描述复杂形状建筑物的外轮廓点。
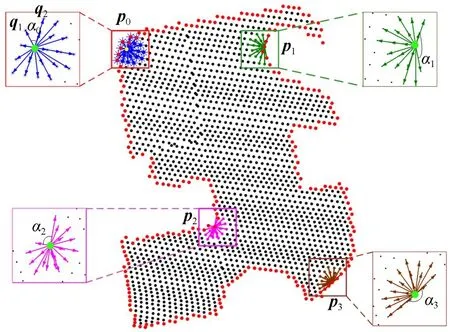
图3 建筑物潜在轮廓点及邻域方向向量示意图Fig.3 Illustration of potential boundary points and neighbor direction vectors
初始轮廓点提取的主要步骤如下:
(1)选取建筑物点云中的任一点p,记其k(取k=20)邻域点集为Sp={q1,q2,…,qk},计算其与任意邻域点qi(i=1,2,…,k)构成的方向向量pqi;
(2)记点q1为其最近邻点,选取其与点p构成的方向向量pq1为基准向量,则其余方向向量与pqi的夹角θ可通过式(1)所示的向量点乘计算;
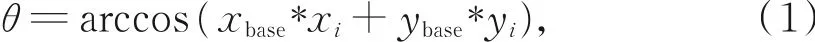
其中:i=1,2,…,k,xbase,ybase和xi,yi分别为向量pq1和pqi归一化后的坐标分量。
(3)为了得到相邻方向向量之间的夹角,需要对各方向向量与基准向量的夹角大小进行排序。由于利用式(1)计算得到的角度范围在[0,180°]之间,而部分轮廓点的最大夹角可能大于180°(如图3的点p1),因此利用式(2)所示的向量叉乘计算指示变量sign;

(4)选取由基准向量顺时针旋转的角度进行排序,即当sign=1,用360°减去原计算的角度θ(为方便叙述,相减后的结果仍记为θ),对排序后相邻夹角作差,得到相邻方向向量之间的夹角dθ;
(5)统计最大夹角dθmax,如果dθmax>90°,则认为点p为潜在轮廓点,否则不是;
(6)重复上述步骤,直到所有建筑物点云都已处理。
图3 所示建筑物点云中红色实心点为经过上述步骤提取的轮廓点,可以看出,建筑物的外轮廓点均能较好地被提取。
2.2 轮廓点跟踪
初始轮廓点的提取结果实质为散乱三维点的集合,很难应用于实际任务,因此需要对其进行跟踪,得到具有拓扑关系的建筑物轮廓。理想情况下,在提取轮廓点后,直接顺序搜索并连接各点的最邻近点就能得到有序的建筑物轮廓,但由于点云数据分布不规则、密度不均匀的特性,这种方式无法适应不同的场景。此外,建筑物点云中存在很多凹拐角点,且点与点之间并不存在拓扑关系,导致无法利用已有的影像上成熟的轮廓点跟踪算法进行点云建筑物轮廓点跟踪,也难以在不丢失凹拐角点的情况下准确跟踪所有轮廓点[27]。
文献[14]提出一种极角扫描法,但该算法无法提取凹拐角点,仅能得到点集的凸包;文献[15]借鉴了其思想,提出基于固定邻域扫描的方式,可有效提取部分凹拐角点,但存在邻域半径难以设置的问题,尤其是对于如图4(a)所示的分布不均的点云;文献[21]和文献[25]采用图论中的如深度优先搜索、Dijkstra等最短路径搜索算法实现轮廓点跟踪,这些算法首先需要构建轮廓点之间的邻接关系,但现实场景中的建筑物形状往往复杂多样,轮廓点之间的邻接关系可能很复杂(如图4(b)所示建筑物点云,红色框内的点均为轮廓点),因此即使在跟踪时严格保证每个点仅被跟踪一次,也难以得到准确的跟踪结果。为此,提出一种无需设置边长阈值的轮廓点跟踪策略,以在初始轮廓点的基础上跟踪轮廓点,得到有序的轮廓点提取结果(彩图见期刊电子版)。
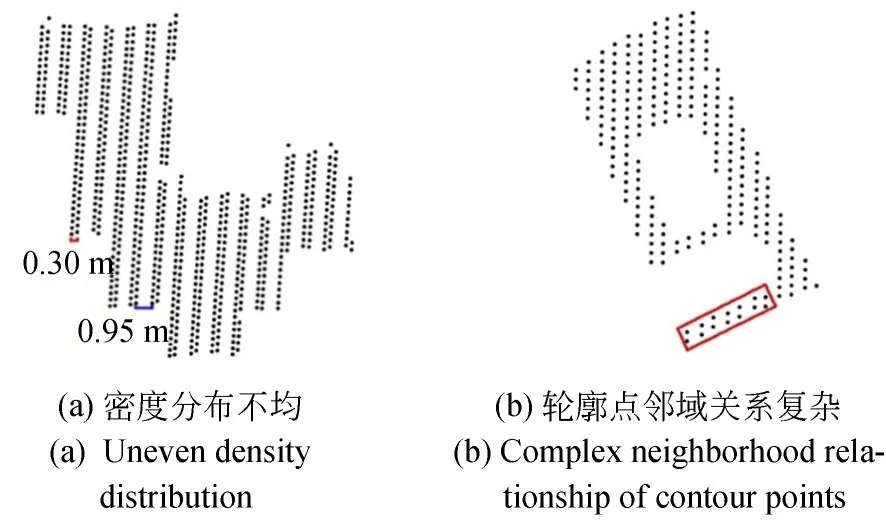
图4 难以跟踪的建筑物点云示意图Fig.4 Illustration of hard-to-trace building point cloud
本文提出的轮廓点跟踪策略主要有四个步骤,即初始边集的获取、虚假轮廓边的剔除、真实轮廓边的增补和建筑物轮廓边的跟踪与后处理。下面对轮廓点跟踪的具体步骤进行详细描述。
2.2.1 获取初始边集
在跟踪轮廓点前,需要确定点之间的相邻关系,考虑到轮廓点跟踪结果实质也是边的集合,且建筑物点云数量通常较少,因此采用构建平面不规则三角网(Triangulated Irregular Network,TIN)确定点之间的拓扑关系,并以包含两个初始轮廓点的边构成的集合为初始边集,如图5(a)所示建筑物的TIN,图中红色点和线段分别为初始轮廓点和初始边(彩图见期刊电子版)。
2.2.2 删除虚假建筑物轮廓边
从图5(a)可以看出,初始边集中存在大量虚假建筑物轮廓边,这些虚假建筑物轮廓边主要包括长度较长的边和潜在轮廓点相对的边两种,为此定义两种删除操作。
在计算初始轮廓点时,选取了各点k邻域计算最大夹角,如果某一点为潜在轮廓点,其非k邻域点与其构成的边必然不会为真实轮廓边,因此利用这个特点删除部分虚假轮廓边(即第一种删除操作),结果如图5(b)所示。由于在凹拐角点附近,其k邻域点之间也会构成边(如图5(b)中蓝色箭头所指边),这些边的长度通常较短,但难以通过设置合适的长度阈值进行删除,观察图5(a),(b)可知,这些边均为TIN中某一包含潜在轮廓点的三角形的边,且边所对的顶点为潜在轮廓点。由2.1节提取初始轮廓点的原理可知,如果某一点为潜在轮廓点,则在TIN中必然存在一个包含该潜在轮廓点的钝角三角形,反之则不一定成立。因此,利用这个特性,删除此三角形中该潜在轮廓点相对的边(即第二种删除操作),其结果如图5(c)所示,从图中蓝色箭头所指的边可知,单独利用第二种删除方式,也难以得到较好的结果。因此,综合利用两种删除边的操作,其结果如图5(d)所示,从中可以看出,虚假建筑物轮廓边被较好地删除。
2.2.3 增补真实建筑物轮廓边
在后续跟踪时,选用的基元为边,因此需要保证每个点至少有两条边与之相连。由于在删除虚假轮廓边时,没有考虑与各轮廓点相连的边数,会导致部分边被错误删除,使部分轮廓点没有边与之相连(如图5(d)中蓝色矩形框所示),为此需要增加被误删除的真实建筑物轮廓边。此外,由于点云离散、分布不规则的特点,在初始轮廓点提取时,可能会存在误提取的点以及漏提取的真实轮廓点,误提取的轮廓点也可能没有边与之相连(如图5(d)中蓝色圆圈所示),但不应该增加与这些点相连的边,而对于漏提取的轮廓点,则需要增加与之相连的边。

图5 虚假建筑物轮廓边的删除Fig.5 Removal of false building outline edge
综合考虑,对于没有边相连的初始轮廓点,搜索其一定半径内的邻域点(半径为与该点相连的所有边长均值的两倍),如果存在其他轮廓点,则连接,否则在后续跟踪时不再考虑该点;对于仅有一条边相连的轮廓点,搜索所有与该点构成边的非轮廓点,搜索包含此非轮廓点的边,判断边的另一端点是否为仅有一条边相连的轮廓点,如果是,则连接两条边,并增加该非轮廓点为轮廓点,否则仍搜索其一定半径内的邻域点(半径设置方式与第一种情况相同),连接长度最短的边。
2.2.4 跟踪建筑物轮廓边与后处理
为了跟踪建筑物轮廓,首先对所有轮廓点的最大夹角按从大到小的顺序排序,然后依次遍历,如果当前遍历点满足仅有两条边与之相连,则将其作为起始跟踪点。
在确定跟踪起始点后,采用边的顺时针扫描,具体步骤如下:
(1)记起始点为p1,与其相连的两个轮廓点分别为p2,p3,任意选取与起始点p1相连的另一轮廓点(以选取p2为例),借鉴Alpha Shapes算法的思想,利用式(3)计算两个圆心:
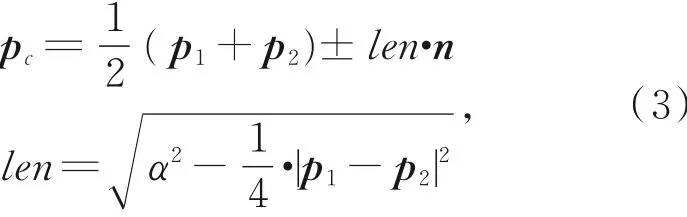
其中:pc为计算的两个圆心;α为半径,设置为3倍平均点云间距;n为与边垂直的单位方向向量。
(2)统计两个圆心构成的圆内点云的数量,选取具有较少点数的圆心(记为pc1,该圆心必然在建筑物轮廓外,如图6下方矩形框放大区域所示),利用式(4)计算其与轮廓点p1,p2构成的向量及向量叉乘crs,得到已跟踪轮廓点集edge_sq:

(3)记edge_sq中最后两个点为plst1,plst2,搜索初始轮廓点集中与plst1相连的边(除去其与plst2构成的边),如果仅有一条边,则直接将边的另一个端点加入轮廓点集,否则计算由点plst1,plst2构成的边到所有边的顺时针扫描角度,将具有最小扫描角度的边的另一端点加入轮廓点集中(如图6左上角放大区域所示,由于αn<αm,故选取的下一点为pn);
(4)重复步骤(3),直到加入轮廓点集中的点等于轮廓点集的第一个点。
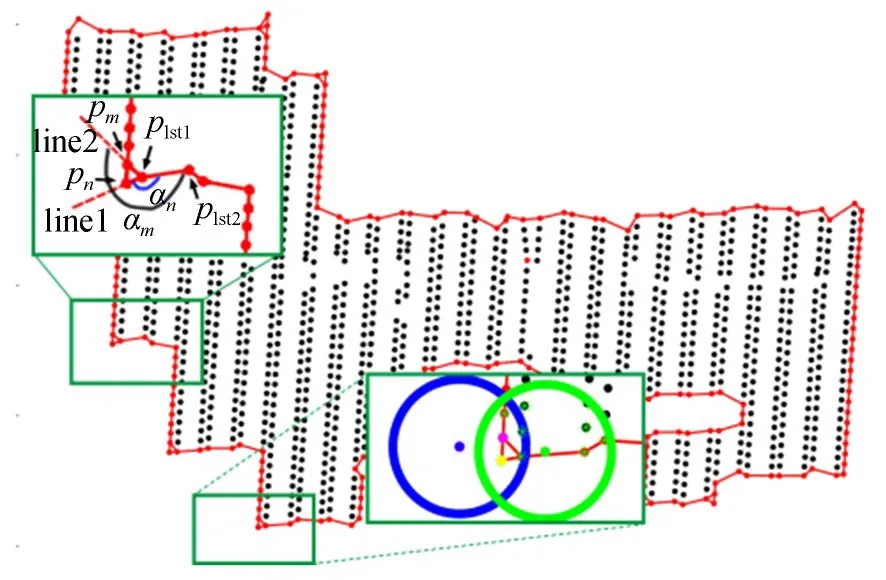
图6 建筑物轮廓边跟踪示意图Fig.6 Illustration of building outline edge tracing
本文在初始轮廓点提取时以尽可能多地提取建筑物外轮廓点为目的,这对于如建筑物三维模型重建中屋顶面拓扑关系的构建等任务十分有利,但也会使跟踪的建筑物轮廓存在如图7所示的锯齿状(图中灰色区域代表建筑物内部,角度α*代表相邻边顺时针扫描的角度,p*代表对应顶点),导致跟踪的轮廓向内凹陷较大。考虑到很多实际应用需要平滑的建筑物轮廓,因此在跟踪建筑物轮廓后,针对图7中三种锯齿状轮廓,设计下面规则对进行处理(为了尽可能保留关键凹拐角点,角度阈值θth均设置为10°):

图7 锯齿状轮廓示意图Fig.7 Illustration of zigzag building outline edge
(1)对于情形A,pi为轮廓中的任一点(下同),如果其角度αi>270+θth,则删除其前后点pi-1,pi+1角度小于180°的点;
(2)对于情形B,如果pi的角度αi(90+θth,90+3θth),且其前后点pi-1,pi+1的角度均在180°~270°之间,则删除pi;
(3)对于情形C,pi的前后点为pi-1,pi+1(同理pi+2,pi+3),如果pi和pi+2的夹角均小于90+3θth,则删除pi和pi+2。

图8 基于规则处理前后建筑物外轮廓对比(蓝色和红色线段分别代表处理前后的轮廓)Fig.8 Result of building outline before and after rulebased process(The blue and red line segments represent the contours before and after processing)
利用规则(1-3)处理图6所示建筑物轮廓的对比如图8所示,从中黑色箭头可以看出,规则(1-3)虽然简单,但能有效地剔除向内凹陷较大的轮廓点,得到的建筑物轮廓更加平滑,且能较好地保留关键凹拐角点。
3 试验与分析
3.1 试验数据
选取三组点云数据(分别记为数据集1-3)进行试验以验证本文方法的性能,三组点云数据的直观展示如图9所示。其中,数据集1包含5个不同形状、不同点云密度的模拟点云数据(记为Bs1-Bs5,分别代表C形、M形、S形、圆形和复杂形状的建筑物,Bs4和Bs5由真实点云数据降采样得到,其影像如图9(a)最右侧所示);数据集2和3为由不同传感器获取的机载LiDAR点云数据,数据集2为文献[20]的试验数据(由原文作者提供),包含不同地区的9栋建筑物,B1-B5和B6-B9由不同传感器获取,具有不同的点密度(B1-B5虽为同一传感器获取,但不同建筑物点云的密度差别也较大,详见文献[20]);数据集3为ISPRS官网公布的一组区域点云数据,包括10栋建筑物,点云密度差别也较大,但其点的分布与B1-B5的分布不同。需要说明的是,尽管B15与B6对应的建筑物相同,但B15去除了较多女儿墙上的点,因此存在较多空洞,相对于B6点云的分布更加复杂, B15与B6对应的点云如图10所示。

图9 三组点云数据的相关信息Fig.9 Illustration of the three point clouds
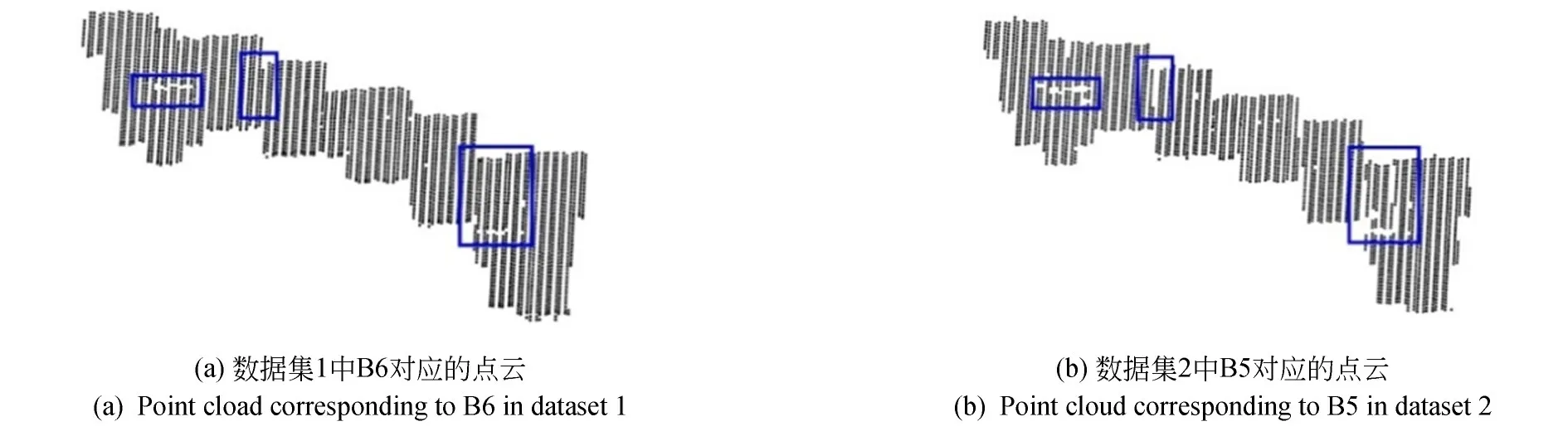
图10 B5和B15建筑物对应的点云Fig.10 Corresponding building point clouds of B6 and B15
3.2 参数k的影响
初始轮廓点提取是后续跟踪和最终轮廓提取结果的基础,在初始轮廓点提取时,本文方法需要设置邻域点数k以计算方向向量夹角,为了探究k对初始轮廓点提取结果的影响,选取密度很不均匀且存在较多空洞的B19建筑物点云数据,通过设置不同的k值进行多次试验,得到的初始轮廓点提取结果如图11所示(彩图见期刊电子版)。
对比图11(a~f)在图11(a)中的蓝色矩形区域可知,不同的k值对建筑物内轮廓点的提取影响较大,如果k设置太小,邻域的k个点可能都位于同一侧,导致计算的最大夹角较大(近似180°),从而造成部分非轮廓点被错误提取(如图11(a)左下角椭圆区域内的红色点);相反,如果k设置太大,部分邻域点会位于内轮廓的另一侧,导致计算的最大邻域向量方向夹角均较小,从而造成轮廓点漏提取。从图11(a)的左下角标注的点云间距可知,B19建筑物点云在横向和纵向两个方向上的间距差别很大(0.34 m和1.02 m),但对比图11(a~f)可知,即使设置了不同k值,本文方法提取的B19建筑物外轮廓点也都完全相同,且几乎不存在丢失凹拐角点的情况,证明了本文方法的参数易于设置,具有较好的适应性。

图11 不同k值下初始轮廓点提取结果(红色点代表提取的初始轮廓点)Fig.11 Extraction results of initial building boundary points by setting different value of k(Colored by red)
3.3 结果与分析
3.3.1 轮廓提取效果分析
为了直观地分析本文方法的有效性,与应用最为广泛的Alpha shapes及其改进算法(自适应阈值的Alpha shapes算法[20])进行对比,考虑到Alpha shapes算法α的设置对提取结果有较大的影响,本文按文献[1]和[21]的建议分别设置α为1.5和2倍平均点间距进行试验(平均点间距为所有点与其最近邻点的距离均值)。由于篇幅有限,在提取轮廓后,仅选取部分具有代表性、轮廓复杂程度和点云密度分布不同的建筑物轮廓提取结果进行直观对比分析,如图12所示,1.5_alphs,2.0_alphs和adp_aphs分别代表半径设置为1.5倍、2.0倍平均点云间距的Alpha shapes算法和自适应阈值的Alpha shapes算法(下同)。


图12 部分建筑物外轮廓提取和跟踪结果(不同颜色的线段代表跟踪的不同轮廓)Fig.12 Results of outline extraction and tracking of some buildings(Line segments with different colors represent different traced outlines)
从图12(a)中不同算法的轮廓提取结果可知,当单个建筑物点云密度分布均匀时,不同算法的提取效果较好,但也存在少数不好的情况:从Bs1的蓝色方框放大区域可以看出,尽管adp_aphs算法通过在平面构建TIN,利用每个点较大邻域范围内三角网中的边(邻域范围均按原文作者的默认值设置,即3 m),为每个点计算一个α值以改进Alpha shapes算法,但其提取结果中存在明显的跟踪错误、提取到了多个轮廓的问题。对比Bs2中蓝色箭头所指凹拐角区域可知,α较小时(即1.5_alphs),Alpha shapes算法提取效果较好,随着α的增大(即2.0_alphs),凹拐角区域的轮廓点被平滑;adp_aphs算法为每个点计算一个α值,从而有效地提取了凹拐角区域的轮廓点;由于凹拐角区域最内侧轮廓点的邻域点几乎分布于其周围各个方向,导致计算的最大夹角较小,因此本文方法提取Bs2的结果虽然相对2.0_alphs较好,但漏提取了最内侧轮廓点。对比Bs3、Bs5的蓝色方框放大区域可知,2.0_alphs的提取结果相较于1.5_alphs更加平滑(观察图12中所有提取结果均能得到此结论),adp_aphs算法存在轮廓跟踪错误,相较而言,本文方法的提取结果更好。
对比图12(b~d)中不同算法的提取结果可知,当单个建筑物点云密度分布不均匀时,Alpha shapes及其改进算法都无法较好地适用,当α设置较小时,Alpha shapes算法存在较多的误提取,而增大α,虽然能在一定程度上改善误提取,但造成无法提取直角区域的轮廓点;adp_aphs算法虽然在一定程度上消除点云密度不均造成的影响,但仍难以适应密度分布变化较大的建筑物,其提取结果的优劣仍然较大程度上受点云密度的影响;而本文方法可以较好地提取图12(b~d)中密度分布不均匀的所有建筑物的外轮廓。
分析图12(a~d)不同算法的提取结果可知,当单个建筑物点云密度变化较小时(如Bs1-Bs5),图中所有算法均能相对较好地提取建筑物轮廓;随着单个建筑物点云密度变化程度的增加,Alpha shapes及其改进算法的提取效果明显变差,本文方法虽然也存在一些不足,如无法提取Bs2的锐角区域内侧轮廓点、跟踪到B19的内部,但对于具有不同形状复杂度和点云密度变化程度的建筑物点云设置相同参数(即邻域点数k,k=20)的情况下,均能得到较好的外轮廓提取结果,表明本文方法具有较好的适应性,且从直观上来看,本文方法的提取结果更好。
3.3.2 定量评价与分析
为定量评价建筑物轮廓提取结果,采用F1分数和PoLiS度量[28]两个评价指标对不同算法进行评价,其中F1分数基于提取的面积计算,值越大代表提取结果越好,PoLiS度量基于提取的轮廓多边形计算,值越小代表提取结果越好,两种评价指标的具体计算方式参见文献[19]。评价时,数据集2的参考轮廓数据由文献[20]提供,数据集3的参考轮廓数据从ISPRS公布的建筑物三维模型重建结果中提取,评价结果如表1和图13所示。需要注意的是,由于Alpha shapes算法无法有效地提取部分建筑物的轮廓,因此未对其进行评价(如1.5_alphs提取B4,B18和B19建筑物的结果),即表1中不包含对这些结果的评价(以“-”表示),对应的PoLiS度量在图13中直接置为1 m以便于对比。

表1 不同算法提取建筑物外轮廓的精度统计结果Table 1 Building outline extraction accuracy statistics results of different algorithms
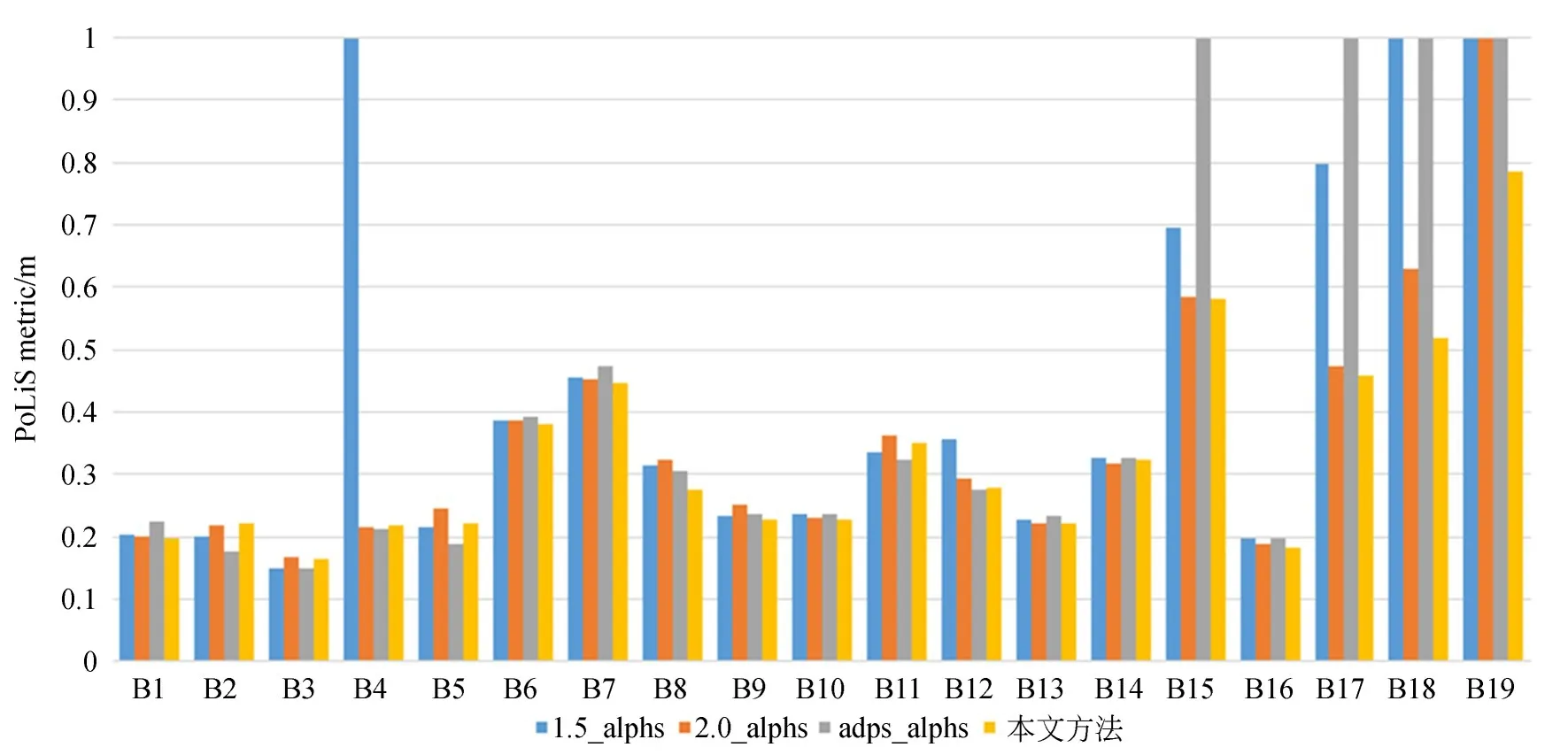
图13 采用PoLiS度量评价两组数据集建筑物轮廓提取结果图Fig.13 Evaluation of two dataset building outline extraction results using PoLiS metric
从表1可以看出,尽管本文方法提取B2,B4和B5建筑物轮廓的F1分数相对较低,但与最高F1分数相差在0.1%以内,且本文方法提取其余建筑物轮廓结果的F1分数均为最高,说明方法可以较好地兼顾建筑物轮廓提取的完整率和正确率。从图13可以看出,整体上,本文方法提取轮廓的PoLiS度量值较低,尤其是对于轮廓相对复杂、点云密度变化相对较大的建筑物B10-B19,说明方法提取的轮廓与参考轮廓更相似,且能更好地适用于提取具有不同形状、密度分布的建筑物轮廓。
综合分析图11~图13和表1可知,Alpha shapes及其改进算法无法有效地适用于不同密度分布的点云,本文方法参数易于设置,可有效地提取建筑物的凹拐角点,并能提取具有不同点云密度变化程度、不同形状复杂度建筑物的轮廓,适用性较强。
4 结 论
提出了一种利用邻域方向分布的机载Li-DAR点云建筑物外轮廓提取方法,利用模拟点云数据以及不同传感器获取的、具有不同点云密度变化程度和形状复杂度的真实建筑物点云数据进行试验,结果表明,相较于Alpha shapes及其改进算法,本文方法的建筑物外轮廓提取结果精度高(F1分数优于90.88%),可较好地提取具有不同点云密度变化程度和形状复杂程度建筑物的外轮廓,适用性较强。此外,方法仅需要设置邻域点数一个参数即可自动提取建筑物外轮廓,且针对模拟点云数据,以及不同传感器获取的多组建筑物点云的外轮廓提取,设置相同邻域点数,得到的提取结果均较好,结合邻域点数对提取结果影响的分析可知,该参数易于设置。本文关注的重点是建筑物外轮廓提取,但真实场景中存在很多具有内轮廓的建筑物,因此在今后工作中需进一步研究如何有效地提取建筑物内轮廓,以进一步提高方法的适用范围。
猜你喜欢
中学生数理化·七年级数学人教版(2020年12期)2021-01-18
考试与评价·七年级版(2020年4期)2020-10-23
语数外学习·高中版上旬(2020年8期)2020-09-10
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
西南石油大学学报(自然科学版)(2018年4期)2018-08-02
美文(2017年4期)2017-02-23
周口师范学院学报(2016年5期)2016-10-17
广西电力(2016年5期)2016-07-10
小雪花·初中高分作文(2016年5期)2016-05-14
