
基于BERT的学术合作者推荐研究
2021-04-06 10:13周亦敏
计算机技术与发展 2021年3期
周亦敏,黄 俊
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
当今,已经形成一些学术搜索引擎,例如微软学术搜索、谷歌学术搜索和AMiner等,这使得探索诸如科学文献和研究者概况这类海量的数字学术资料更方便。数据量和种类的快速增长需要更先进的工具来帮助学术数据的研究,并且已经付出巨大的努力来开发各种高效的应用。长期以来,学术合作者推荐被认为是开发学术数据的一种有效应用,其目的是为给定的研究者找到潜在的合作者。在过去的几年中,已经提出了一些方法[1-3]来解决这样的问题。尽管取得了进步,但现有的技术只能推荐不考虑上下文关系的合作者。例如,目前的工作不能推荐合适的候选人给一个不仅包含“机器学习[4]”而且包含“推荐算法”主题的研究者。一般来说,在寻找合作者之前,研究者会先确定他要研究的主题。因此,有必要使用上下文关系为学术合作者提供推荐。
1 相关工作
1.1 问题定义
研究者:一名研究者与他发表的文献有关,这些文献揭示了他的研究兴趣和与他人的学术合作。
研究主题:研究主题是从特定文段(如标题或关键词列表中的一个词)中提取的关键词或短语;同时,一个文献包含一个或多个研究主题,这些研究主题共同反映了其潜在的范畴。
上下文:合作上下文指的是研究人员在其合作文献中共同研究的主题集。
基于以上的初步研究,对基于BERT的学术合作者推荐研究的定义如下:
BACR给定研究者r0和主题T0,从所有候选者R中找到合作者r,这些合作者将在T0上与r0一起工作,具有最高的可靠性。
1.2 数据预处理
该文所研究的学术合作者推荐主要用到两组数据:研究者和研究主题。研究者每篇学术文献都已给出,需要进行预处理的数据是研究主题,主要使用以下两个方法:
(1)词干提取:去除词缀得到词根的过程(得到单词最一般的写法)。对于一个词的形态词根,词干不需要完全相同;相关的词映射到同一个词干一般就能得到满意的结果,即使该词干不是词的有效根。
(2)停用词去除:因为在文献的标题和摘要中通常会有一些高频但无实际意义的词,如:“this”,“of”,“is”,“at”等,该文将此类词语加入停用词表过滤掉。
基于以上两个方法,从文献的标题和摘要中获取到一些词组配合文献已有的关键词生成真正的关键词组。
2 BERT模型
BERT[5],即是bidirectional encoder representations from transformers,顾名思义,BERT模型重要部分是基于双向的Transformer编码器来实现的,其模型结构如图1所示。

图1 BERT模型结构
图1中的w1,w2,…,w5表示字的文本输入,经过双向的Transformer编码器,就可以得到文本的向量化表示,即文本的向量化表示主要是通过Transformer编码器实现的。Transformer是由文献[6]提出,是一个基于Self-attention的Seq2seq模型,也就是Encoder将一个可变长度的输入序列变成固定长度的向量,而Decoder将这个固定长度的向量解码成为可变长度的输出序列。通常Seq2seq模型中使用RNN来实现Encoder-Decoder的序列转换,但是RNN存在无法并行、运行慢的缺点,为了改进它的不足,Transformer使用Self-attention来替代RNN。Transformer模型的encoder结构如图2所示。
从图2中可以看出,Encoder的输入是一句话的字嵌入表示,并且加上该句话中每个字的位置信息,再经>过Self-attention层,使Encoder在编码每个字的时候可以查看该字的前后字的信息。它的输出会经过一层Add & Norm层,Add表示将Self-attention层的输入和输出进行相加,Norm表示将相加过的输出进行归一化处理,使得Self-attention层的输出有固定的均值和标准差,其中均值为0,标准差为1。归一化后的向量列表再传入一层全连接的前馈神经网络,同样的,Feed Forward层也会由相应的Add & Norm层处理,然后输出全新的归一化后的词向量列表。
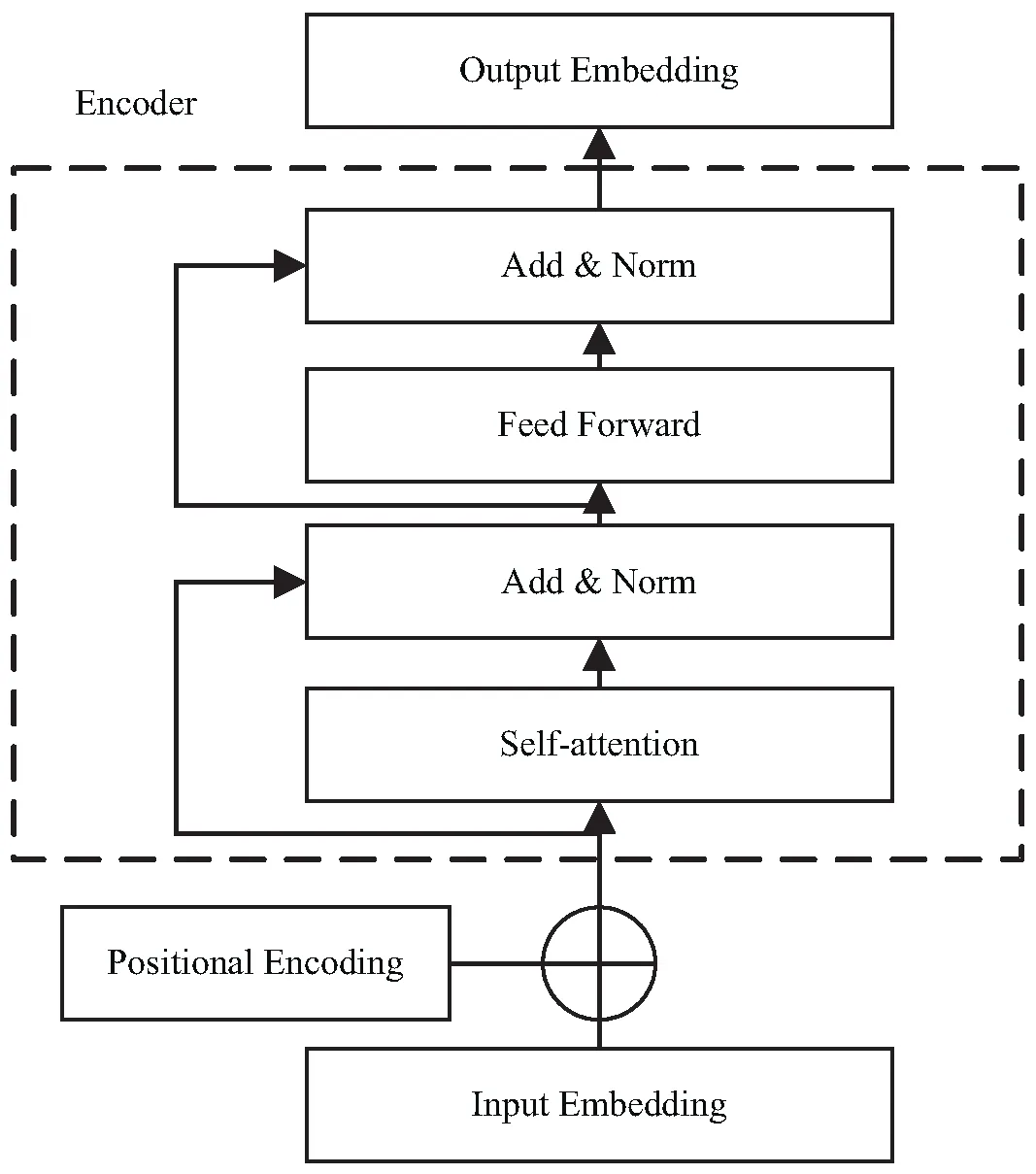
图2 Transformer Encoder结构
图1中的Embedding包含三个嵌入层分别是Token Embeddings、Segment Embeddings和Position Embeddings,如图3所示。

图3 BERT的输入表示
Token Embeddings:Token Embeddings层是要将各个词转换成固定维度的向量。输入文本在送入Token Embeddings层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头([CLS])和结尾([SEP])。
Segment Embeddings:Segment Embeddings层标记输入的句子对的每个句子,只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token,后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0。
Position Embeddings:Position Embeddings层标识序列的顺序信息,最长序列长度为512。Position Embeddings layer实际上就是一个lookup表,表的第一行代表第一个序列的第一个位置,第二行代表序列的第二个位置,以此类推。
BERT模型使用两个新的无监督预测任务来对BERT进行预训练,分别是Masked LM和Next Sentence Prediction:
MLM:给定一句话,随机掩盖部分输入词,然后根据剩余的词对那些被掩盖的词进行预测。这个任务在业界被称为Cloze task(完型填空任务),它是为了让BERT模型能够实现深度的双向表示,不仅需要某个词左侧的语言信息,也需要它右侧的语言信息,具体做法是:针对训练样本中的每个句子随机抹去其中15%的词汇用于预测,例如:“加油武汉,加油中国”,被抹去的词是“中”,对于被抹去的词,进一步采取以下策略:(1)80%的概率真的用[MASK]去替代被抹去的词:“加油武汉加油中国”->“加油武汉,加油[MASK]国”;(2)10%的概率用一个随机词去替代它:“加油武汉,加油中国”->“加油武汉,加油大国”;(3)10%的概率保持不变:“加油武汉,加油中国”->“加油武汉,加油中国”。这样做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,若总是使用[MASK]来替代被抹去的词,就会导致模型的预训练与后续的微调不一致。这样做的优点是:采用上面的策略后,Transformer encoder就不知道会让它预测哪个单词,换言之它不知道哪个单词会被随机单词给替换掉,那么它就不得不保持每个输入token的一个上下文的表征分布。也就是说如果模型学习到了要预测的单词是什么,那么就会丢失对上下文信息的学习,而如果模型训练过程中无法学习到哪个单词会被预测,那么就必须通过学习上下文的信息来判断出需要预测的单词,这样的模型才具有对句子的特征表示能力。另外,由于随机替换相对句子中所有tokens的发生概率只有1.5%(即15%的10%),所以并不会影响到模型的语言理解能力。
NSP:给定一篇文章中的两句话,判断第二句话在文章中是否紧跟在第一句话之后。许多重要的自然语言处理下游任务,如问答(QA)和自然语言推理(NLI)都是基于理解两个句子之间的关系,因此这个任务是为了让BERT模型学习到两个句子之间的关系。具体做法是:从文本语料库中随机选择50%正确语句对和50%错误语句对,即若选择A和B作为训练样本时,B有50%的概率是A的下一个句子(标记为IsNext),也有50%的概率是来自语料库中随机选择的句子(标记为NotNext),本质上是在训练一个二分类模型,判断句子之间的正确关系。在实际训练中,NSP任务与MLM任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT模型的输出有两种形式,一种是字符级别的向量,即输入短文本的每个字符对应的有一个向量表示;另外一种是句子级别的向量,即BERT模型输出最左边[CLS]特殊符号的向量,它认为这个向量可以代表整个句子的语义,如图4所示。

图4 BERT模型输出
图4中,最底端中的[CLS]和[SEP]是BERT模型自动添加的句子开头和结尾的表示符号,可以看到输入字符串中每个字符经过BERT模型后都有相应的向量表示,当想要得到一个句子的向量时,BERT模型输出最左边[CLS]特殊符号的向量,该文应用的就是BERT模型的这种输出。
3 逻辑回归模型
经过上节的处理后,有了研究者和研究主题的向量表示,该文要做的是推荐学术合作者,故此巧妙设置二分类判断输入样本是正类的概率,输出此概率,最后按照概率的大小做出推荐。在此引入逻辑回归模型[7](logistic regression),它属于广义线性模型。
假设有训练样本集{(x1,y1),(x2,y2),…,(xm,ym)},其中xi∈Rn,表示第i个训练样本对应的某篇学术文献里的研究者研究主题向量,维度为n,共m个训练样本,yi∈{0,1}表示第i个训练样本是否是正类。假设预测函数为:
hθ(x)=g(θTx)
(1)
其中,x表示特征向量,g表示一个常用的Logistic函数(Sigmoid函数):
g(z)=1/(1+e(-z))
(2)
其中,e是欧拉常数,z表示曲线陡度。
结合以上两式,构造的预测函数为:
hθ(x)=g(θTx)=1/(1+e(-θTx))
(3)
由于g(z)函数的特性,它输出的结果不是预测结果,而是一个预测为正类的概率的值,预测为负例的概率就是1-g(z),函数表示形式如下:
(4)
由式(4)可知,hθ(x)预测正确的概率为:
P(正确)=((g(xi,θ))(yi)*(1-g(xi,θ))(1-yi)
(5)
其中,yi为某一条样本的预测值,取值范围为0或者1。一般进行到这里就应该选择判别的阈值,由于该文是做出推荐,实际上是输出正类概率,最后筛选出前k个即为推荐的合作者,故不需要设定阈值。
此时想要找到一组θ,使预测出的结果全部正确的概率最大,而根据最大似然估计[8],就是所有样本预测正确的概率相乘得到的P(正确)最大,似然函数如下:
(6)
上述似然函数最大时,公式中的θ就是所要的最好的θ。由于连乘函数不好计算,因此对公式两边求对数得到对数似然函数:
(7)
得到的这个函数越大,证明得到的θ越好,所以对求l(θ)的最大值来求得参数θ的值,由于在函数最优化的时候习惯让一个函数越小越好,故此将式(7)做了以下改变得到逻辑回归的代价函数:

(1-yi)log(1-hθ(xi))]
(8)
对于以上所求得的代价函数,采用梯度下降的方法来求得最优参数θ。梯度下降过程如下:
Repeat{
}

(9)
其中:
而又因为:
则:
因此:
故:
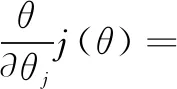
由以上分析可以得到梯度下降过程如下:
Repeat{
}
其中,i=1,2,…,m表示样本数,j=1,2,…,n表示特征数。由此方法求得θ,得到预测函数hθ(x),即可对新输入的数据输出为正类的概率。
4 基于BERT的学术合作者推荐算法
综上2,3,该文提出基于BERT的学术合作者推荐算法,其具体流程可以描述如下:
算法1:基于BERT的学术合作者推荐算法。
输入:初始研究者研究主题训练集T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi为每条研究者研究主题,yi表示每条训练样本是否为正类,i=1,2,…,N;
输出:学术合作者推荐模型M。
步骤1:使用第1节中的方法对训练集T进行预处理,得到预处理后的训练集T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi为预处理后的每条研究者研究主题,yi表示预处理后的每条训练样本是否为正类,i=1,2,…,N;
步骤2:使用第2节中介绍的BERT预处理语言模型在训练集T上进行微调,采用如图4所示的BERT模型输出,得到训练集T对应的特征表示为V=(v1,v2,…,vN),其中vi是每条研究者研究主题xi对应的句子级别的特征向量,i=1,2,…,N;
步骤3:将步骤2中得到的特征表示V输入第3节中介绍的逻辑回归模型进行训练,输出学术合作者推荐模型M。
5 实验与评价
5.1 实验设置
5.1.1 数 据
在该实验中,采用在文献[9]中的Citation数据集进行数据分析,该数据集共包含629 814篇学术文献和130 745名来自数据库和信息系统相关社区的研究者。通过预处理后共获得13 379个关键字,每个关键字都被视为一个独特的主题。选取其中的600 000篇学术文献,按照8∶1∶1的比例进行训练集、验证集以及测试集的划分。
5.1.2 评价目标
针对以下目标进行实验:
主题受限的合作者推荐:评价BERT在确定特定主题下推荐合作者的有效性。该文是基于二分类做出的推荐,分类问题最常用的评价指标包括精确率P、召回率R以及F1值,它们的计算需要用到混淆矩阵,混淆矩阵[10]如表1所示。

表1 分类结果的混淆矩阵
其中行代表真实值;列代表预测值;0表示negative;1表示positive。如果预测的是0,真实值是0,就为TN;如果预测为1,真实值为0,就为FP;预测为0,真实值为1,就为FN,预测为1,真实值为1,就为TP。
(1)精确率P是指分类器预测为正类且预测正确的样本占所有预测为正类的样本的比例,计算公式如下:
(10)
(2)召回率R是指分类器预测为正类且预测正确的样本占所有真实为正类的样本的比例,计算公式如下:
(11)
(3)F1值是兼顾P和R的一个指标,一般计算公式[11]如下:
(12)
此时F是P和R的加权调和平均,α>0度量了R对P的相对重要性,通常取α=1,此时是最常见的F1,也即:
(13)
其中,0≤F1≤1。当P=1且R=1时,F1达到最大值为1,此时精确率P和召回率R均达到100%,这种情况是完美状态,而由文献[11]知实际中很难达到,因为P和R是一对矛盾的变量,当P较高时,R往往会偏低;当R较高时,P又往往偏低。因此,在使用F1值评估性能时,其值越接近1,说明分类器的性能越好。由于F1值是对P和R两个评价指标的综合考虑,可以更加全面地反映性能,因此它是评价实验效果的主要评价指标。
5.1.3 评价方法
为了评估BERT在主题限制的情况下推荐合作者的性能,采用以下基于Network Embedding的具有代表性的方法进行比较。
(1)深层网络结构嵌入(SDNE)。SDNE[12]代表为编码实体及其关系的结构信息而设计的方法[13]。当应用于BACR问题时,研究者被视为实体,在特定主题中的合作被视为上下文关系。由于主题的组合,BACR中实际上存在无限数量的上下文关系,因此不能直接采用像[13]这样的常规方法。
(2)特定任务嵌入(TSE)。针对作者识别问题,在文献[14]中提出了TSE。简单来说,TSE由三个层次构成:第一个层次用嵌入学习方法表示上下文关系的每个来源(如关键词、场所),如文献[15-16];在实验中,这些嵌入是为研究者和研究主题独立学习的。在第二层,对所有源的提取嵌入进行不同权重的集成;最后,在集成嵌入的前提下,第三层学习特定分类任务的模型参数。
在以上比较方法中共享嵌入维数Dim。在该实验中,Dim的范围为{10,20,30,40,50,60}。粗体表示Dim有效性的比较的默认值,其他用于评估参数灵敏度。而该文使用的BERT预训练模型是Google提供的BERT-Base模型,Transformer层数12层;隐藏层768维;采用了12头模式;共有110 M个参数;其他的训练参数如表2所示。该文使用逻辑回归用于所有的比较方法,评价指标主要采用F1值。

表2 BERT模型训练参数
5.2 主题受限的合作预测
5.2.1 BERT的有效性
所有比较方法的性能总结为表3,其中维数Dim设置为20、40和60;而推荐人数K设置为5、10、15和20。根据所呈现的结果,BERT证明了其在预测主题受限的合作者方面的优势,因为所产生的F1明显高于其他人。
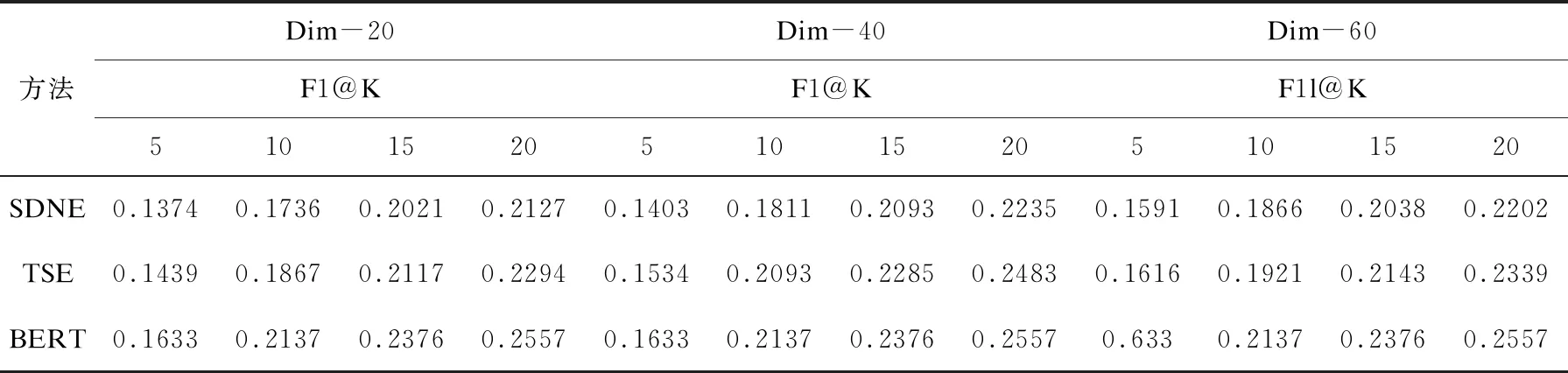
表3 主题受限的合作者预测表现
给定不同主题研究者倾向于与不同研究员合作,使得有必要使推荐算法考虑研究者主题依赖关系。通过对实验结果的进一步分析,可以得出以下三点:
首先,与SDNE相比,BERT和TSE都具有更好的性能。这些方法中最显著的区别在于,BERT和TSE都在训练推荐模型的同时提取上下文关系。因此,将上下文关系引入到推荐模型中是十分必要的。
其次,通过观察,BERT的表现甚至比TSE更好。与研究者和研究主题的特征是独立训练的TSE不同,特征训练在BERT中是一起训练的。通过这种方式,研究者和研究主题的上下文关系自然得以保留,从而有助于更准确的推荐。
最后,在所有的比较方法中,SDNE的性能最低。很明显的原因是SDNE没有考虑到研究者和研究主题之间存在的上下文关系,不同的研究主题下,研究者倾向于与不同的研究者合作。如研究者A倾向于与B在“推荐算法”上合作而不是C,但却倾向于与C在“机器学习[4]”上合作而不是B。
5.2.2 超参数对推荐算法的影响
图5(a)和(b)分别演示了超参数Epoch和Learning Rate的影响。根据给出的结果,当Epoch=3和Learning Rate=1e-5时,获得了优越的性能。此外,很显然,Learning Rate对BERT的性能影响更大,因为生成的结果因Learning Rate不同而差异很大。较大的Learning Rate使梯度下降的速率更快,但也可能导致错过全局最优点;因此,需要通过网格搜索仔细选择适当的值。
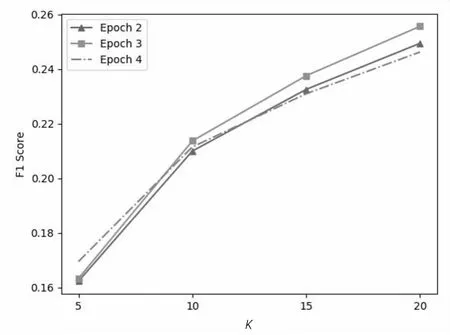
(a)Epoch对F1值的影响
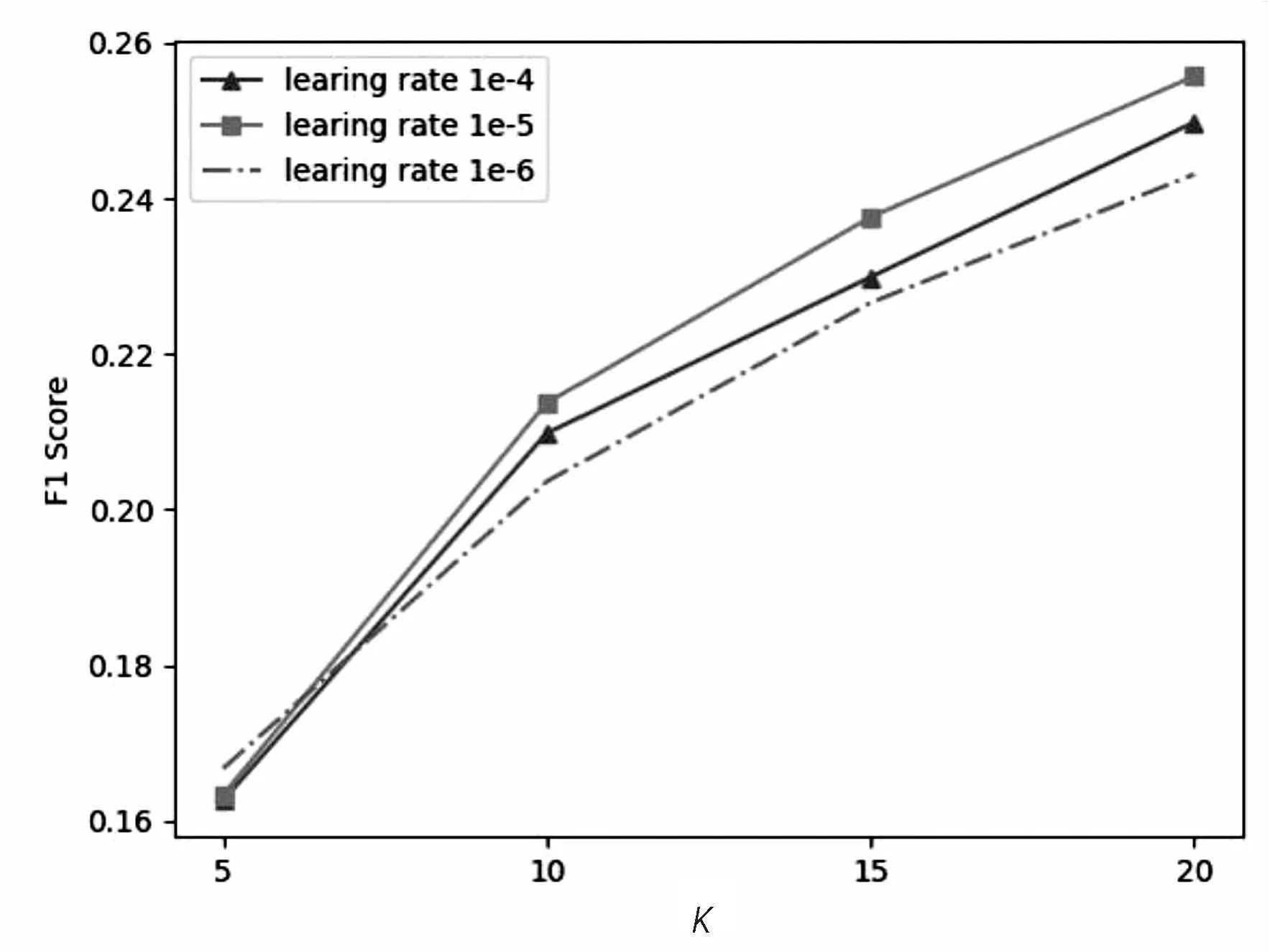
(b)Learning Rate对F1值的影响图5 超参数的影响
5.3 实验结论
综上可知,基于BERT的学术合作者推荐充分考虑了研究者和研究主题间的上下文关系,对比以往的方法显著提高了性能,相较于TSE最高提高达到了6.45%,最低提高2.10%;而相较于SDNE最高提高则高达18.00%,最低也提高了13.52%,这也充分展示了BERT的优越性能。
6 结束语
在解决学术合作者推荐的问题中,使用BERT模型进行研究者和研究主题的向量表示,提出了一种基于BERT模型的学术合作者推荐算法,并与SDNE、TSE两个模型进行对比,实验结果表明BERT模型在研究者研究主题向量的表示上能达到很好的效果,在一定程度上提升了推荐算法的准确性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
领导文萃(2021年19期)2021-11-05
文萃报·周五版(2021年10期)2021-09-13
爱你(2019年21期)2019-06-21
意林(2018年20期)2018-10-31
作文评点报·初中版(2018年32期)2018-10-20
中华手工(2018年6期)2018-07-17
中国新闻周刊(2016年32期)2016-10-27
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
