
基于语义加权的引文网络社区划分研究
2021-04-08 02:27刘璐蔡永明
新世纪图书馆 2021年1期
刘璐 蔡永明

摘 要 为提高引文网络社区划分的准确性,以文档之间的语义关系以及引文之间的引用关系为基础,结合词汇在文档中的位置关系等信息,构建基于词汇语义加权的引文网络。通过GloVe模型对词汇向量化以充分利用词汇语义信息,结合WMD模型度量文献之间的相似度,把文档相似度的计算转变为在约束条件下求线性规划最优解的问题,结合文本的内容及结构特征对网络中的边进行赋权,以Louvain社区发现算法对加权后的引文网络进行社区划分,并对划分后的社区进行分析与检验,实验证明GloVe-WMD模型可提高引文网络社区划分的准确度。
关键词 引文网络 语义加权 社区划分 文本挖掘 自然语言处理 词嵌入
Abstract To improve the accuracy of citation network community division, citation network with lexical semantic weighting was constructed based on the semantic relationship between documents and the reference relationship between citations and the location relationship of words in documents and other information. The GloVe model was used to vectorize the words in order to make full use of the semantic information of the words. The WMD model was used to measure the similarity between literatures, and the calculation of the similarity of documents was transformed into the problem of finding the optimal solution of linear programming under the constraint condition. The edges in the network were weighted according to the similarity, content and structural features of the text. The citation network was divided into communities by the Louvain community discovery algorithm. The divided community is analyzed and tested. The results show that GloVe-WMD model can improve the accuracy of community division of Citation Network.
Keywords Citation network. Semantic weighting. Community discovery. Text mining. Natural language processing. Word embedding.
0 引言
學术文献是科研领域客观存在的知识载体,而参考文献作为学术文献的重要组成部分,不仅反映了学术研究的背景和依据,而且在知识生产和传播过程发挥着重要的作用。引文网络是文献间引用与被引用关系的集合[1],网络中的节点表示一篇文章,连边则表示文献间的引用关系[2]。随着知识的爆炸增长,引文网络已经形成了一个超大规模的网络系统,对指数级增长的文献,仅凭人力已经无法精确提取出人们所需要的有效信息。如何快速准确地提取出人们所需要的信息是知识管理人员以及相关研究人员需要思考的问题。聚类分析法是信息检索领域的一种重要应用[3],通过对引文网络进行聚类分析可以发现网络中的社区结构,从而揭示学术领域的传承与发展,也能够为学术研究评价提供不同的视角。为了提高引文网络划分的准确性,笔者在传统的One-Hot-Representation模型上,综合考虑文献之间的语义关系以及引用关系,结合文档的内容及结构特征,提出一种基于GloVe-WMD语义加权的引文网络社区划分方法,并以相关数据为例验证了改进模型的效果。
1 引文网络的社区划分研究概述
引文网络的社区划分主要利用文献的标题、摘要及关键词作为主要信息源组成短文本对引文网络进行处理,目前大都采用BOW→TF-IDF→VSM/LSA的体系来实现,也就是俗称的One-Hot-Representation,又被称为0-1编码或者独热编码,它把所有的文档表示为向量形式,通过计算向量之间余弦值作为相似度对引文网络的边进行赋权。
BOW(Bag-Of-Words)[4],也称为词袋模型,是自然语言处理和信息检索领域的重要模型之一,它省略了文本的语法、语序等要素,把文本当成若干个词汇的集合,使用词汇来表示文本;Gerard Salton等[5]提出的向量空间模型(Vector Space Model,VSM)是一种经典的机器学习模型,一篇文本被表示为一个向量,向量的维度表示文本特征词的权重,所有的文本向量构成一个向量空间,文本内容即可转换为易于数学处理的向量形式,文本内容的处理转化为向量空间中的数学运算;TF-IDF(Term Frequency- Inverse Document Frequency)算法是自然语言处理领域中使用最广泛的特征词权重赋值方法之一,它利用TF和IDF可以剔除文本中高频但区分度较低的词。魏建香等[6]基于此利用关键词和摘要提出加权引文网络聚类的方法;谢翠香 、刘勘等[7-8]根据上述体系进行改进,对文本进行区域划分,根据词汇出现的不同位置分布分别赋予权重,给出了含有位置关系的新的权重计算方法;肖雪等[9]在前者的基础上提出了一种基于样本加权的引文网络社区发现方法,结合了文本的内容及位置结构对引文网络进行划分。
上述加权引文网络都旨在强调特征词对文本的代表能力及提取方法,而忽略了词汇本身包含的语义。由此,廖开际等[10] 考虑了特征项在文本中的重要程度以及特征项之间的语义关系,提出基于文本特征项的加权语义网模型计算文本之间的相似度。该方法虽然包含了文本的语义联系,但对短文本分析时无法避免矩阵的稀疏性造成的信息丢失及维度灾难[11],也没有考虑到文献之间的引用关系,并不适用于引文网络。目前对引文网络的加权研究着重改进特征词权重的计算,强调更准确地提取特征词或者改进特征词对于文献的表示能力,而对于词汇本身的联系关注甚少。而且,上述体系在对短文本分析时存在一个弊端,短文本的“文档-词汇”矩阵通常是高度稀疏的[12],如果文本特征词选择不当,随后在使用余弦相似度计算文本相似性时,文献经过向量化,两个文献没有重复词语,则会被认定为完全不相关。基于此,研究者们需要一种词向量技术来处理词汇语义关系,从而发现词语之间的内在联系。
词向量表示技术是将自然语言中的每一个词语通过编码方式转换为稠密向量形式,也称作词嵌入(Word Embedding)。1998年Hisao Tamaki[13]提出了LSA(Latent Semantic Analysis)模型,利用词汇的潜在语义进行分析,可有效收集词汇的全局统计信息,但LSA模型不能捕捉到词的上下文信息,导致词汇语义表达能力欠缺;Mikolov [14]等在2013年提出了 Word2Vec 模型, 精简了神经网络的隐藏层[15],使词向量训练效率比传统的神经网络模型得到了大幅的提升, 但此模型基于局部窗口信息训练词汇,并没有考虑词汇全局的统计信息;斯坦福NLP(Natural Language Processing)小组[16]在2014年提出一种新的词汇表征方法——GloVe(Global Vectors for Word Representation)模型, 它结合了Word2Vec以及LSA模型的优点,训练出的词汇向量不仅可以有效捕捉到词汇的语义特性,比如词语间的相似性、类比性等,而且能兼顾词汇在全局的统计信息,使得表达更加准确。
聚类是寻找社会网络中社团结构的算法,它基于各个节点之间连接的相似性或者强度,把网络自然地划分为各个子群[2],目前聚类分析的主要方法可以概括为两大类:一类是层次聚类算法和派系过滤算法,如Newman快速算法[17]和GN分裂算法[18],另一类是基于图论的算法,如随机游走算法、谱评分法等。在复杂网络的社区划分中,应用最为广泛的是基于模块度优化的社区发现算法,Newman快速算法和GN分裂算法为其中经典的代表,但这两种算法在处理大规模社区网络时,效率往往不高。Vincent D. Blondel等[19]在2008年基于Newman快速算法進行修改,提出了基于模块度优化的启发式Louvain算法,有效提高了社区划分的效率和准确性,该算法也成为大多数知识图谱网络分析软件的基础算法。
2 基于GloVe-WMD语义加权的引文网络社区划分基本思想
引文网络假设是一个多学科交叉的大型社区网络,不同领域的文献虽然存在着引用关系,但内容相似度较低,而同领域的文献内容相似度较高。传统的引文网络把文献之间的链接关系看作是等价的,利用文献之间的相似度并结合它们之间的链接关系对网络中的边进行赋权,通过社区发现算法可以提炼出有价值的簇。
基本思路可以分为以下4个阶段:①搜集原始数据,把文献的标题、摘要及关键词组成短文本并进行文本预处理。②利用Glove模型得出全局词汇的n维词向量(度量词汇之间的相似性);由BOW(词袋模型)汇总每一篇文档词汇的词频,利用TF-IDF以及文本的内容及结构特征对词汇赋权(表示其重要性程度),构建VSM(向量空间模型)。③通过WMD计算出文献的相似度作为权重代入引文网络。④利用Louvain算法对加权后的网络进行社区发现与评估。具体流程如图1所示。
3 GloVe-WMD语义加权模型的实现
GloVe词汇模型结合了全局“文档-词汇”矩阵分解方法(LSA算法为代表)以及局部文本框捕捉方法(word2vec为代表)二者的优点,利用全局词汇共现矩阵作为训练数据,将每个词映射成 n维实数向量,通过设置文本信息框的宽度,可获得词汇数据更加深层次的特征表示[20]。其GloVe模型的核心思想是利用词与词之间共现的统计数据来构造词向量。
3.1 GloVe全局词汇向量模型
3.2 词汇赋权方法
在构造向量空间(VSM)时需要对词汇进行赋权,传统的布尔值赋权法选择用词频信息作为词汇的权重,但会忽略词汇的内在性质,无法区分出对文档真正具有代表性的词汇。本研究选择时下流行的TF-IDF(Term Frequency–Inverse Document Frequency)加权方法,它可以有效衡量词汇对文档的区分能力。TF表示词汇在文档中出现的频率,IDF表示词汇对文档的重要程度,其方法的基本思想为,词汇的重要程度与它在文档中出现的频率呈正比,但同时与其在全局词汇库中出现的次数呈反比。TF-IDF权重法能够有效过滤掉生活中的常用噪声词汇,而给真正对文档具有代表能力的词汇赋予更高的权重。TF-IDF权重值由两部分乘积所得,目前常用的有效公式为:
在学术文献中,词汇的重要程度与其出现的位置关系十分紧密,文献的标题、摘要及关键词在某种程度上可以表达文献的核心内容,为了简化计算,提升模型效率,只考虑词汇在这三种位置不同的重要程度。研究表明,标题是文献内容的高度概括,重要程度一般为最高,关键词是作者对整篇文献核心的提炼,重要程度次之,摘要为文献内容的简练表达,重要程度放在最后,综上所述,对三个位置出现的词汇分别进行如下加权处理:
3.3 构建语义加权引文网络
引文网络是根据文献之间的引用关系构建,而网络中边的关系权重是由文献之间的相似度确定的。DOI(Digital Object Unique Identifier,DOI)为文献的唯一标识符,在收集的原始数据集中,对每篇文献的DOI及引用的参考文献的DOI进行匹配,从而可以确定文献之间的引用关系,而文献之间的引用关系涉及到知识流动的方向,故本研究默认引文网络为有向的加权网络。
文献间的相似度的主要计算方式为WMD模型,WMD(Word Movers Distance)是Matt J. Kusner[21]在2015年提出的一种文本相似度量方法,通过计算一篇文档所有的词汇“移动”到另一篇文档所有词汇的最小距离总和表示词移距离,转移示意图如图2所示。
利用上节中得到的词汇向量计算词汇之间的距离,记为distance,根据示意图,文档1到文档2的距离为:distance(词汇1->词汇5)+distance(词汇2->词汇7)+…但实际情况中,词汇往往不是一一对应的,为了解决这一问题,WMD采用文档的每个词汇以不同的权重转移到另一篇文档中的所有词汇中的方式,由另一篇文档中的所有词负责分配该词的权重,那么“词汇1”转移到文档2的距离则变为:
4 社区划分方法及评估
Louvain社区发现算法[19]是基于Newman快速算法改进而来,其核心是层次聚类,目标是最大化社区网络的模块度。社区网络的模块度是衡量社区划分优劣的一个重要指标,其取值在[-1,1]区间内,在实际应用中模块度的取值一般在0.3~0.7之间,其主要思想是测量社区内节点的链接密度与社区之间的链接密度。其公式定义为:
Lovain算法的基本流程如下:①所有的节点视为一个社区;②依次尝试把节点i划分到相邻的社区,分别计算前后的模块度值,用分配后的模块度值与分配之前的模块度做差得到 ,如果 ,即差为正值时,则接受此次划分,否则拒绝;③重复第二步直至所有的节点不再变化;④把第三步划分的社区重新视为一个节点,继续执行②-③,直至社区结构不再改变。
5 数据验证及测评结果分析
5.1 获取原始数据及文本预处理
为了验证基于GloVe-WMD语义加权的引文网络的社区划分效果,本文选取WOS(Web Of Science)核心库中收录的期刊文献作为原始数据,检索以“5G”为关键词的论文,以“领域中的高被引论文”及“领域中的热点论文”为过滤条件,时间跨度为2011—2019年,共检索出有相互引用关系的论文2095篇。保留文献记录文件的DI(DOI),TI(题目),DE(关键词),AB(摘要),CR(参考文献)五个字段,DI与CR中的DOI依次匹配可得到论文的引用关系,TI、DE和AB三个字段组成短文本,作为文献的信息来源。剔除无摘要,无关键词及无引用关系的孤立点,剩余文献1591篇,共存在11 519条引用关系。
在进行文本分析之前,首先建立词袋模型(Bag Of Words,BOW),然后对文本进行预处理,包括分词、大写转小写、去停用词以及词干提取。部分处理结果如表1所示。
5.2 训练词汇向量及文本相似度计算
通过词袋模型建立“文档-词汇”矩阵和词汇共现矩阵,然后利用GloVe模型训练词汇向量,研究表明,词汇向量的维度在100~280维之间,可以高效准确的表达词汇的语义,但随着维度的增大,模型的效率会大幅下降,故在考虑准确性的同时,兼顾模型的计算效率,本文设定词汇向量的维度为200维,经过50次迭代计算得出词汇向量。
文本相似度的计算同样是借助“文档-词汇”矩阵,根据矩阵构建VSM模型,结合“TFIDF-位置参数”对VSM模型加权,每个文档组成一个向量空间,利用WMD模型计算文献之间的相似度,并作为权重对引文网络中的边赋值。
5.3 社区划分结果及分析
5.3.1 文本相似度分析
在相同的數据集上,分别采用传统的基于TF-IDF加权的One-Hot-Representation模型(图3a)以及基于GloVe-WMD语义加权模型(图3b)计算文本之间的相似度。
由分布图可以看出基于TF-IDF加权的One-Hot-Representation模型求出的文档之间的相似度大部分集中在0~0.2之间,相似度为0的成对论文在1500对以上。经过分析,主要是由于短文本的“文档-词汇”矩阵的高度稀疏性,在利用该模型计算文本之间的相似度时,如果两篇文档之间词汇重复度非常低或者没有重复词汇,即使表达的是相同的语义,也会被认为完全不相似。而基于GloVe-WMD语义加权模型求得的相似度分布大多集中在0.3~0.6之间,接近正态分布,由于原始文本数据通过检索某一关键词所得,所以后者的文献相似度分布更接近实际情况。
5.3.2 社区划分分析
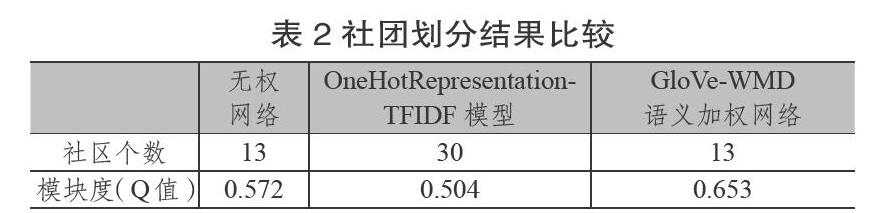
Gephi是基于JVM开发的一款开源免费的社区网络分析工具,基于Louvain算法,适用于各种网络和复杂系统的社区划分和可视化。为了进一步验证模型的有效性,利用Gephi分别对无权重的引文网络、基于TF-IDF的One-Hot-Representation的引文网络以及基于GloVe-WMD语义加权引文网络进行社区划分,并比较三者的模块度(Q函数值),对比结果如表2所示。
由表2可知,OneHotRepresentation-TFIDF模型社区划分与其他两个差别明显,社区个数达到30个,主要是因为该模型在计算文本相似度的过程中,没有重复词汇的文档之间相似度为0,而把相似度作为权重代入引文网络,则会造成大量的权重为0的引用关系被忽略。对比发现,原始的无权网络与基于GloVe-WMD的语义加权网络在社区划分的个数上没有变化,但模块度值由0.572上升到0.653,聚类效果提升明显。
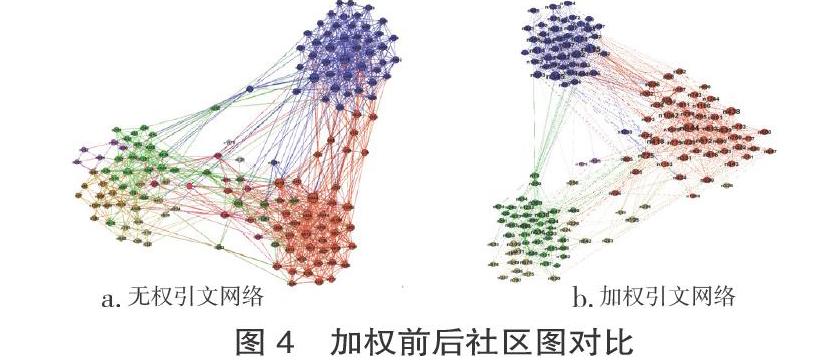
为了深入验证模型具体效果,选取具有代表性的节点观察前后变化。度,代表网络中与节点直接相连的边的数目,是衡量单个节点重要性的指标。为了便于观察分析,本研究选取度为30以上的节点进行展现,OneHotRepresentation-TFIDF模型造成大量引用关系丢失,不具有参考价值,故只对无权引文网络和基于GloVe-WMD语义加权引文网络进行对比。加权前后的社区划分如图4所示。
图4中每个节点代表一篇文献,密集的节点组团代表一个社区,由图4可以看出社团大致结构基本相似,但具体的节点在社区归属上产生了改变,由于截选了度大于30的节点展现网络图,所以图4中每个点的变化都会引起全局网络图中大量与该点相连的节点社团归属发生相应的改变。为了验证模型的可靠性,通过主题、关键词共现得出每个社团的高频词分布,并随机选取5个前后变化的节点进行分析,部分展示结果如表3、表4所示。
再进一步通过人工分析,发现节点n73、n183、n302、n480和n642在两种不同的网络模型所处社区发生改变。由表3得知,社区1主要涉及领域为5G通信、毫米波、信道以及移动网络;社区2为物联网和智能设备的应用和可靠性研究;社区3的主题为云计算、雾计算和边缘计算等相关技术;社区4是对第五代通信技术NOMA(非正交多址接入)的技术研究;社区5主要集中了第五代通信技术的应用,包括NOMA、中继网络、中继选择和功率传递等技术的优化,社区6为5G编码及相关算法优化的集合。对比表3和表4不难发现,文献n73和n480的主题是移动边缘计算的优化及应用,理应划分到第3个社区;文献n183和n642是关于边缘计算、云计算等技术在物联网及智慧家居方面的应用,应该划分为社区2;n302是关于毫米波在非正交多址系统中的应用,侧重于毫米波的研究,故应划分为社区1。
综上所述,基于GloVe-WMD语义加权模型在进行社区划分时更加准确,模块度也有所提高,而且不受文本长短的制约,适用范围更广泛,无论从定量分析和定性分析两方面都比传统的模型更有优势。
6 结语
基于GloVe-WMD语义加权模型对比传统的无权引文网络以及基于OneHotRepresentation-TFIDF模型加入了词汇语义这一重要信息,并综合考虑了词汇的位置信息,提高了模型在短文本分析中的適用性以及社区划分的准确度。
引文网络可以很好地反映学科的研究背景、热门领域以及未来的学术发展方向,随着社会的发展,技术及知识更新日新月异,引文网络的应用将变得更加广泛。当前涉及到引文网络的社区划分仍然存在很多值得探讨的问题,比如,本文提出的GloVe-WMD语义加权模型仅仅局限于词汇这一层面,但一篇文献词汇、句子与段落的语义关系都是相互关联的,如何更好地处理三者之间的关系也是值得探讨的研究方向;其次,文献作者在知识图谱中也包含丰富的信息,如果能对文献作者进行准确的划分并与引文网络相结合,不仅可以提高准确度,而且有利于对学科发展进行更深层次的研究。
CHUNG F.Graph theory in the information age[J]. Noticesof the American Mathematical Society,2010,57(6):726-732.
BOWER D F.Six degrees:the science of a connected age[J]. Reflections,2005,61(1):93.
章成志,师庆辉,薛德军. 基于样本加权的文本聚类算法研究[J]. 情报学报,2008,27(1):42-48.HINRICH SCHüTZE. Automatic word sense discrimination[J]. Computational Linguistics,1998,24(1):97-123.SALALTON G . Automatic text analysis.[J]. Science,1970,168(3929):335-343.
魏建香,苏新宁.基于关键词和摘要相关度的文献聚类研究[J]. 情报学报, 2009, 28(2):220-224.
谢翠香.基于改进向量空间模型的学术论文相似性辨别系统设计[J]. 电脑知识与技术,2009,5(19):5103-5105.
刘勘,周丽红,陈譞.基于关键词的科技文献聚类研究[J]. 图书情报工作,2012,56(4):6-11.
肖雪,王钊伟,陈云伟,等.基于样本加权的引文网络的社团划分[J].图书情报工作,2016,60(20):86-93.
廖开际,杨彬彬.基于加权语义网的文本相似度计算的研究[J].情报杂志,2012,31(7):182-186.
RUMELHERT D E , HINTON G E , WILLIAMS R J . Learning representations by back propagating errors[J]. Nature, 1986, 323(10):533-536.
蔡永明,长青.共词网络LDA模型的中文短文本主题分析[J].情报学报,2018,37(3):305-317.LANDAUER T K , FOLTZ P W , LAHAM D.An introductionto latent semantic analysis[J]. Discourse Processes, 1998, 25(2):259-284.
MIKOLOV T,CHEN K,CORRADO G, et al. Efficient estimation of word representations in vector space[J]. Computer Science,2013,65(9):78-94.
吉久明, 施陈炜,李楠,等. 基于GloVe词向量的“技术:应用”发现研究[J]. 现代情报, 2019, 39(4):14-23.
PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation[C]// Conference on Empirical Methods in Natural Language Processing,2014: 1532-1543.
NEWMAN M E J . Fast algorithm for detecting community structure in networks[J]. Phys Rev E Stat Nonlin Soft Matter Phys, 2003, 69(6 ):66-87.
GIVAN M, NEWMAN M E J. Community structure in social and biological networks[J]. Proc Natl Acad Sci USA,2002,99(1),21-26.
BLONDEL V D , GUILLAUME J L , LAMBIOTTE R , et al. Fast unfolding of communities in large networks[J]. Journal of Statistical Mechanics: Theory and Experiment, 2008, 78(10):56-69.
林江豪,周咏梅,阳爱民,等.结合词向量和聚类算法的新闻评论话题演进分析[J].计算机工程与科学,2016,38(11):2368-2374.
KUSNER M J, SUN Y, KOLKIN N I, et al. From word embeddings to document distances[C]// International Conference on International Conference on Machine Learning. 2015.
猜你喜欢
软件导刊(2016年12期)2017-01-21
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
商(2016年34期)2016-11-24
中国远程教育(2016年9期)2016-11-19
电脑知识与技术(2016年10期)2016-06-16
语文教学之友(2016年5期)2016-06-15
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
电脑知识与技术(2016年5期)2016-04-14
