
基于决策树的三组元精馏序列结构最优合成规则识别
2021-04-09 06:49陈熙理孙国铭贾胜坤罗祎青袁希钢
化工学报 2021年3期
陈熙理,孙国铭,贾胜坤,罗祎青,袁希钢,2
(1 天津大学化工学院,天津300354; 2 化学工程国家重点实验室(天津大学),天津300354)
引 言
精馏是化工生产中应用最为广泛的分离技术,但其能耗高、投资大,同时对于多组元混合物的分离,不同精馏序列结构(简称精馏结构)的能耗与投资差别显著[1],因此如何从众多可行精馏结构中找到最优精馏结构具有重要意义[2-3]。三组元精馏是多组元精馏的基本分离单元,在工业中应用广泛,同时由于对隔板精馏塔(dividing wall column,DWC)以及多种热耦精馏结构研究的深入,三组元精馏结构的最优化合成成为了重要的研究课题[4-9]。Tedder等[10]比较了包含侧线汽提、侧线精馏在内的7 种精馏结构对不同物系的适用情况,指出进料的组成和分离因子(ease of separation index,ESI,即轻组分、中间组分之间的相对挥发度与中间组分、重组分之间的相对挥发度之比)以及进料组成是影响精馏流程结构的主要因素,并首次在三元混合物组成三角图上给出各种最优精馏结构所对应的区域。Agrawal等[11]采用热力学效率为评价指标,给出了具有最高热力学效率的三组元精馏流程结构在三元组成三角图上对应的区域。田芳等[8]针对理想三元混合物,通过严格模拟和优化,针对不同ESI值给出了具有最小年度总费用(total annual cost,TAC)精馏结构在三元组成三角图上所对应的区域。Wang 等[12]发现,除了进料组成和ESI,影响三组元最优精馏结构的还有产品纯度要求,即分离难度,进而定义了广义ESI(generalized ease of separation index,GESI),用以考虑分离难度的影响。Lin 等[13]采用三元组成三角图的方式,扩充了序列选择范围,探究3种不同隔板位置的隔板塔随物系、进料组成改变的选择。
然而,上述研究中沿用的进料组成三角图区域划分的方法具有明显的局限性。这主要在于采用ESI或GESI(即相对挥发度的比值)代表物系对最优精馏序列结构的影响存在不确定性,组分的潜热[12]、泡点温度等因素均会对最优精馏结构对应的分区有影响,导致即便ESI相同,不同的物系所对应的最优精馏结构分区会有不同。如果考虑更多的因素,三元组成三角图分区会十分复杂,导致基于这种三角图分区划分的三组元精馏结构的决策十分困难。为解决这一问题,袁野[14]以及王磊[15]均尝试通过三角图上的区域划分归纳出用于最优精馏结构决策的规则。然而,这种归纳是基于人为图形观察,由于上述不确定性的存在,归纳出的规则很难具有良好的适用性。
决策树是一种经典的机器学习方法[16-17],它以信息熵、基尼系数等指标作为判据依次对系统影响的主要因素加以判别,最终按影响因素的重要性对数据进行有效的分类。上述基于组成三角图划分的三组元精馏分析方法虽然不便于精馏序列结构的优化决策,但可提供主要影响因素与最优精馏结构的一一对应关系数据,为通过训练决策树进而获得系统化的决策方法提供了可能。本文针对三组元最优精馏结构的决策,引入分类回归树(classification and regression tree,CART)方法,采用严格模拟建立数据集,提出采用数据信息熵的方法实现影响最优精馏序列结构选择的特征识别方法,进而建立了一种可根据进料物系、组成以及分离要求等已知条件快速确定三组元精馏最优流程序列结构的决策序列,即决策树的方法。
1 数据与决策树模型
1.1 数据的产生
针对三组元精馏,通常可考虑9种序列结构,即直接序列(D)、间接序列(I)、间接序列热耦合(IS)、直接序列热耦合(DS)、直接序列反馈能量集成(DI)、直接序列前馈能量集成、间接序列前馈能量集成(II)、间接序列反馈能量集成和隔板塔(DWC)。由于直接序列前馈能量集成和间接序列反馈能量集成已被证明可操作性差,同时不具有优势[18],故本文仅考虑除这两种结构外的其他7 种作为候选的结构,即D、I、IS、DS、DI、II 和DWC。相应的精馏序列结构如图1所示。
本文数据引自文献[14-15],选择四种理想物系:异丁烷/正丁烷/异戊烷、正戊烷/正乙烷/正庚烷、正乙烷/正庚烷/正辛烷、苯/甲苯/乙苯作为对象。随机选择的分离要求如表1所示。其中混合物三个组分按挥发度从大到小依次命名为A、B 和C。针对表1 中每一种分离要求均选取34种不同的进料组成,该34个进料组成均匀分布于进料组成的三角图上,以近似涵盖所有可能的进料组成。进料流率为300 kmol/h,并规定泡点进料。GESI 是表示一个三组元混合物精馏分离特性的指标[14],由式(1)给出,定义为在全回流的条件下分别将B/C 和A/B 二元混合物分离到给定产品纯度所需最小理论板数之比,度量的是两种分离难度之比。
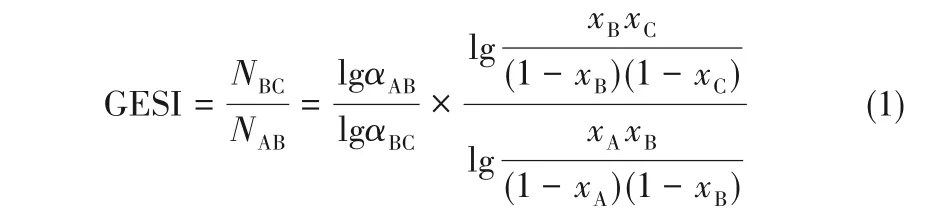
使用Aspen Plus 严格模拟软件,以表1 中6 种分离要求以及34 种进料组成(共204 个组合)作为已知条件分别对7 种精馏序列进行模拟和优化,并计算相应的TAC,计算公式参考文献[19]。通过比对7 个序列的TAC,给出对应每一组已知条件的最优流程结构,以此建立已知条件和最优精馏结构的一一对应关系。

图1 本研究考察的三组元精馏结构Fig.1 Ternary distillation sequences considered in this study
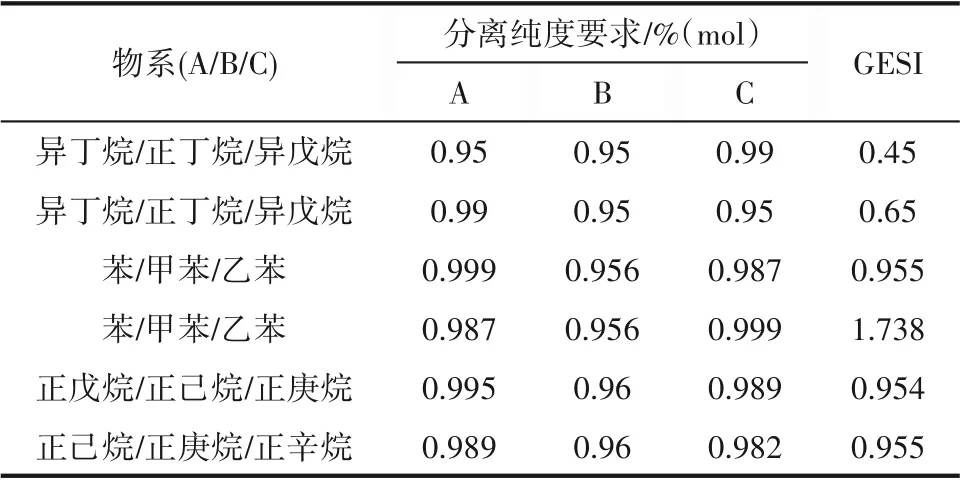
表1 三组元物系和分离要求Table 1 Ternary mixtures and separation requirement
上述已知条件包括所有物性数据、进料摩尔分率和产品纯度规定,按照已知条件与最优精馏结构的对应关系,与一个最优精馏结构对应的那一组已知条件值可被视为该最优精馏结构的特征,用实数表示,则有特征矩阵X,每一最优精馏结构所对应的那一组特征构成矩阵X 中的一行,即xi,亦称为特征行。X 中的行数N 亦称为数据X 的规模。X 中的第j列为第j 个特征。设特征总数为M,即X 的列数,则j≤M。特征行xi所对应的最优精馏结构记为yi,yi亦称为类。与所有特征行相对应的最优精馏结构组成列向量y,亦称类向量。X和y构成了数据集D,即
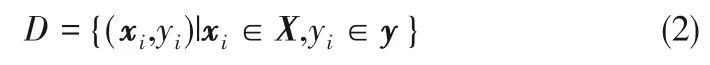
若将X 视为集合,xi为其中的第i 个元素,类似地,y 为集合,yi为其中第i 个元素,则X 中某些元素的组合Xs为X的一个子集,即Xs⊆X,对应地,ys⊆y,其中s为子集的说明符。于是可定义D的子集
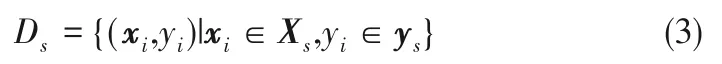
且有Ds⊆D。由子集Xs的定义可知,如果Xs和ys分别包含X 和y 的所有元素,则D 可以被视为它本身的一个子集,即Ds=D。
1.2 分类回归决策树模型
分类回归树,简称CART 决策树[17],是一种经典决策树模型[20-24]。通过CART 算法得到的决策树称为CART决策树。CART决策树呈二叉树形结构,其结构如图2 所示,包括位于顶部的一个根节点(开始节点)、若干个中间节点以及终端节点,亦称叶子节点。
CART 决策树在每一个非叶子节点上选择影响最大的特征及其对应的分割点,从而将当前节点的数据集Ds划分为更“纯”的左、右两个子集。一个数据集Ds的纯度,即ys中类的一致性,可用数据集的信息熵(Shannon entropy)E(Ds)[25]衡量,其定义式为
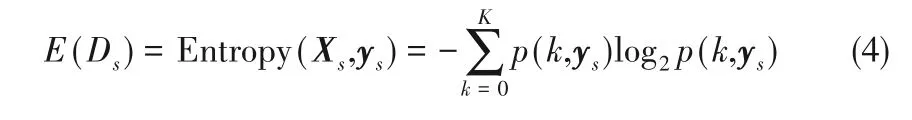

图2 CART决策树结构示意图Fig.2 A CART decision tree classifier
其中,K 为ys中出现的精馏结构种类的总数,k为种类的序号,p(k,ys)表示在向量ys中第k 个种类的数量与ys中所有种类的总数之比。由上述定义可知,与热力学熵相类似,信息熵值越大,ys中的种类越多样,越不纯,反之则ys中的元素类趋于同种类。对于数据集Ds,CART 的分类是指在Xs中挑选一个特征j,即Xs中的第j 列,以实数tj为分割点将数据集Ds划分为由式(5)给出的左、右两个子集DsL和DsR

其中,xij为Xs中第i 行第j 列元素。CART 中对j和tj的选择遵循分类最有效原则,即挑选能够实现最有效分类的j*和tj*。对分类的有效性则采用信息熵增益IG(information gain)作为判别准则。一次分类的信息熵增益被定义为

其中,|Ds|表示集合Ds中元素的数量。熵增益代表了分类的有效程度,即分类后各个子集中的类越纯,则熵增益越大,因此j*和tj*由式(7)给出

当数据集被划分为左、右子集后,各自可以按照相同原理递归继续划分各自的左、右子集,直到决策树生长到足够的深度或得到子集无法继续分割。
2 三组元精馏系统合成算例
2.1 影响因素与特征
本文选择三组元混合物中各组元的进料组成F1、F2、F3以及广义分离因子GESI[12]作为特征(即已知条件),即在矩阵X 中共有4列;X 中的每一行xi对应一个特征组合,以此为已知条件分别对7 种精馏结构进行最优化并通过比较选出最优精馏结构,该最优精馏结构名称为yi,即类向量y 中的第i 个元素。1.1 节采用的204 组已知条件构成X 中的204 行,每组行对应的最优精馏结构的名称构成y。
2.2 决策树的构建与分析
本文使用1.1 节模拟优化得到204 个数据点作为训练集D,在Python/Scikit-learn[26]平台上构建CART 决策树模型,并使用Graphviz[27]绘制出树状格式进行表示。
基于数据集D 形成的CART 决策树如图3(a)所示。以图3(a)决策树根节点为例,其中的信息说明如图4所示。第一行代表在该节点由式(7)计算得到的xij为特征GESI,tj值为0.802,并以此为判据将数据集D 划分为左右两个子集,即满足判据的特征行及其对应的类被划分到左子树,形成左子集,不满足的数据被划分到右子树,形成右子集;entropy 表示当前节点的信息熵;samples 代表当前节点的数据量,即D 中的元素数;value 代表sample 中属于不同类别的数据数量;在本例数据集D 的构建中,严格模拟、优化计算表明,表1 给出的物系和分离要求,以及34 种进料组成所对应的最优精馏结构仅有SS、DWC 和DI,即数据集D 中的类向量y 中有3 种精馏结构,value 中的三个数据分别给出了这3 种精馏结构在本节点的数量;class返回的是在value中值最大数据对应的类别,即DWC。图3(a)表明,在根节点如果选择xij为GESI且tGESI=0.802对根节点204个数据进行分类,即满足GESI ≤0.802 的数据进入左子树,否则进入右子树,则可以获得最大的信息增益,由式(6)可知这一最大信息增益为0.4159。在分类过程中信息增益为正,表明分类后的信息熵下降,表明子集数据纯度增加。
节点信息中的class 可视为当前节点可优选的精馏结构分类,其依据是该分类在value中对应的数量最多。例如根节点的优选分类为DWC,因为在数据集D 的204 个数据中有92 个以DWC 为最优精馏结构,占45%(92/204)。亦即,对于表1 中的物系在任何情况下如果选择DWC 精馏结构,则有45%的概率是正确的。而这一正确率随着决策树分类的进行逐步提高,例如,图3(a)中第3 层各节点优选精馏结构(即class 的值)的正确率从左至右分别为93%、96%、91%和64%,这是信息熵逐层下降的结果。将该层最左边的节点继续分类,其左子节点的class 值为IS,其正确率提高到了95%(38/40);右子节点选择DI的正确率为50%,但这一不确定性仅涉及在2 个数据点中选取1 个,其对总误差的贡献率为0.5%。如考察图3(a)所有末端节点,其总误差为11.8%,即该决策树用于预测表1所示的三元物系最优精馏结构的准确率为88.2%。
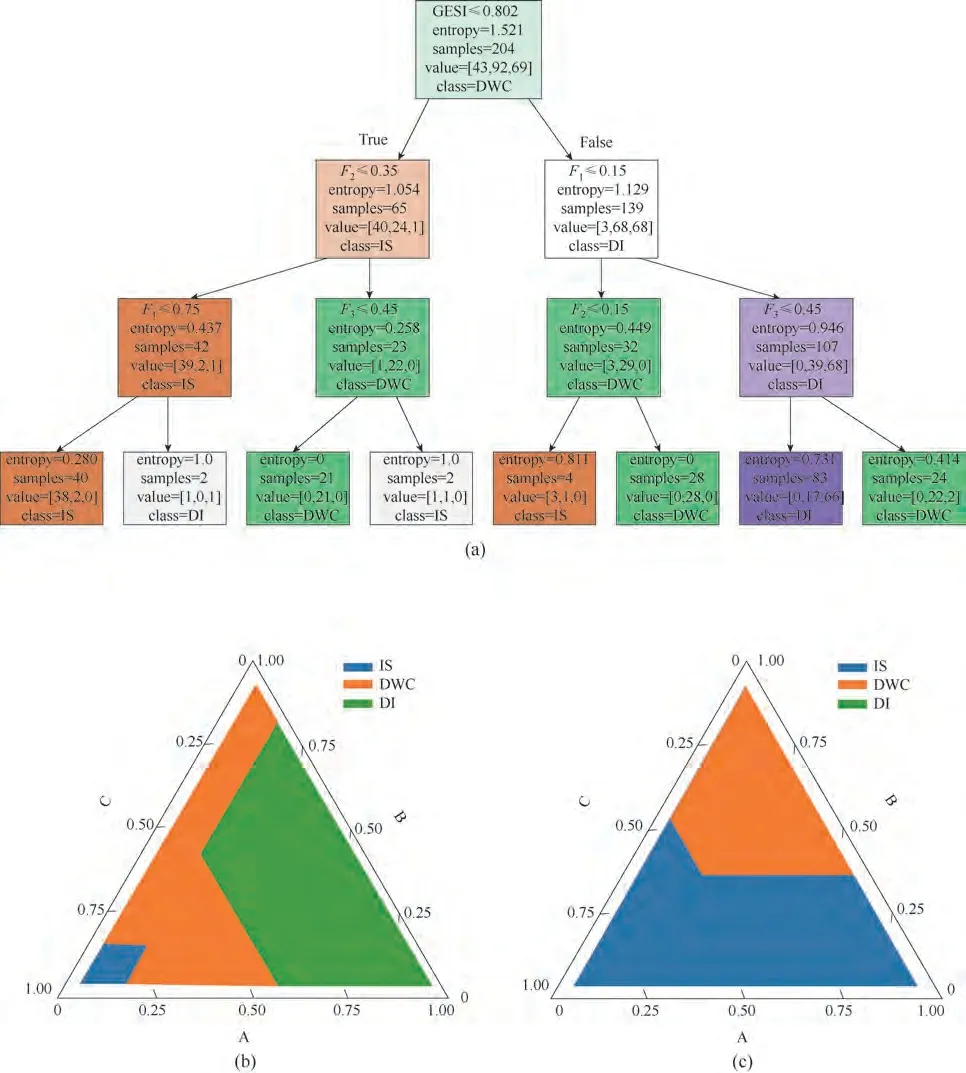
图3 算例的CART可视化图(a),CART左子树(b)和右子树(c)可视化三角图Fig.3 The visualization of CART for case(a),the left subtree branch(b)and the right subtree branch(c)of CART

图4 CART决策树节点信息指示Fig.4 Introduction for node in CART decision tree
图3(b)为根节点的左子树精馏结构在进料组成三角图上的分布,从图中可看出,对于划分到左子树的数据点,仅有2种序列是占优的,根据其进料组成不同,在IS 和DWC 两种结构中选择,即对于异构烷烃物系,其余的5 个候选序列始终不占优[28]。根节点的右子树可以按照相同方法总结另外三条规则:当F1≤0.15 且F2≤0.15 时,IS 结构占优;当F1≤0.15且F2>0.15时,DWC占优;当F1>0.15且F3≤0.45时,DI 结构相比其他序列更具有经济性。图3(c)为决策树右子树的可视化,可以清晰地看出对于苯物系和正构烷烃物系,在不同的条件下,7 个候选序列仅有3 个序列分布在三角图中,这表明其余的4 个序列是始终不占优的,仅需从IS、DWC、DI三个序列中做选择即可进行最优精馏序列选择。此外,IS 的区域要远小于DWC 和DI各自的区域,仅在轻组分、中间组分含量均很小的时候才会占优;与之相反,DWC 和DI 近似均分了三角图剩下区域,这说明对于大多数分离任务,DWC 和DI 序列都具有更好的经济性[29-30]。
3 结果与讨论
基于图3(a)所示的CARD 决策树,可以提取出用于最优精馏结构设计的决策序列。决策树中的每一个结点均对应一条规则,例如根节点的规则即为GESI≤0.802 时,应考察F2≤0.35 是否满足,若满足应进而考察F1≤0.75是否满足,如满足则应该采用IS精馏结构,否则采用DI;当F2≤0.35 不满足时则应考察F3≤0.45 是否满足,如满足则采用DWC 为精馏结构,否则采用IS;当GESI≤0.802 不能满足时则应考察F1≤0.15 是否满足,若满足应进而考察F2≤0.15 是否满足,如满足则应该采用IS 精馏结构,否则采用DWC;当F1≤0.15 不满足时则应考察F3≤0.45 是否满足,如满足则采用DI为精馏结构,否则采用DWC。
由于CART 决策树会在每一个非叶子节点选择一个特征将数据集划分为更纯的两个子集,该特征使得在该节点进行分类信息熵下降最多,即在该节点影响最大的特征。类比三组元精馏结构选择问题,一个特征造成信息熵在分类过程中下降的程度可视为该特征对最优精馏序列选择影响的重要性。在分类中特征的重要性可以由FI 因子(features importance)定义,特征的FI 因子定义为该特征在决策树学习过程中使数据集的信息熵下降累加的归一化值,FI 因子可以定量给出不同特征对序列选择的影响。本模型中CART 决策树训练过程中得到的FI 因子如图5 所示。从图中可以看出,选择的四个特征中,对三组元序列选择影响最大的是GESI 指标,即不同的分离难度会显著影响序列选择。此外,三个组分进料组成对序列选择的影响并不相等,中间组分进料流率占比(F2)对选择的影响要高于其他两个组分。

图5 基于信息熵的变量重要性(FI)Fig.5 Feature importance(FI)measurements on entropy
应该指出,图3(a)所示的决策树是基于表1 中的三元物系的训练结果,所得准确率也是针对这些物系而言的。因此若将本文结果用于其他物系则准确率会有所下降,特别对于非理想物系误差可能较大。但提出的训练过程的意义在于它为建立三组元精馏设计最优决策提供了一种有效的方法,通过在数据集中增加新的数据增加决策的正确率。通过应用规则进行决策是三组元精馏结构最优化设计的快速、高效的方法,然而传统的经验规则虽然也具有这些优势,但存在多条规则之间矛盾、规则运用顺序不确定性等显著弱点。由决策树产生的规则可有效避免上述弱点,同时随着决策树的提出,通过数据集的不断补充、积累,准确、有效、确定的三元精馏结构最优决策规则型设计将成为可能。
4 结 论
(1)本文针对三组元精馏结构最优合成,采用决策树的方法提出了一种基于数据驱动的决策模型,该模型具有可视化性、可解释性,且可以实现复杂的三组元最优序列选择。
(2)提出的决策模型可以在决策的同时输出决策规则。在算例演示中,使用该方法找出了一套三组元精馏结构最优合成规则,且发现的规则与传统经验规则相比具有确定性。
(3)提出了一种基于信息熵降的衡量不同特征对三组元精馏序列选择的定量化指标FI 因子。FI因子越大特征对于序列选择影响越大,反之,对序列选择的影响越小。
(4)提出的方法是一种数据驱动的方法,相比于前人依赖工程师经验的主观分析,不仅不会因为待分析的数据量增加而处理困难,反而会随着数据规模的日益扩大,得到更多、更准确的决策规则。
值得指出的是,目前提出的方法仅在理想物系的算例上验证了方法的有效性,针对更普适的最优精馏序列选择,仍需通过添加数据,涵盖更多的考察物系以及分离要求进一步分析。由于决策树方法是数据驱动的,依赖于精准高效的数据,因此快速高效地产生充足且质量高的训练数据,这也将是今后应解决的问题。
符 号 说 明
D——数据集
Ds——数据集D子集
DsL——Ds的左子集
DsR——Ds的右子集
E(D)——数据集D的信息熵
ESI——分离因子
GESI——通用分离因子
j——X矩阵第j列(第j个特征)
j*——决策树节点最优划分特征
K——类别总数
k——类别序号
N——数据集D样本数
NAB——分离A/B二元混合物所需的最小理论塔板数
NBC——分离B/C二元混合物所需的最小理论塔板数
p(k,y)——第k 个种类的数量与y 中所有种类的总数之比
TAC——年度总费用
tj——第j个特征对应的分割点
tj*——最优划分特征对应的最优分割点
X——分离任务矩阵
Xs——X矩阵子集
xi——X矩阵中第i个元素
xij——Xs中第i行第j列元素
y——最优精馏序列向量
yi——y矩阵中第i个元素
ys——y向量子集
αAB——轻组分、中间组分间相对挥发度
αBC——中间组分、重组分间相对挥发度
猜你喜欢
昆钢科技(2022年4期)2022-12-30
中州大学学报(2022年4期)2022-09-13
军民两用技术与产品(2022年1期)2022-06-01
科学家(2022年3期)2022-04-11
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
化工装备技术(2021年4期)2021-08-21
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
雷达学报(2017年6期)2017-03-26
