
基于改进DPC的青霉素发酵过程多模型软测量建模
2021-04-09 06:49刘聪谢莉杨慧中
化工学报 2021年3期
刘聪,谢莉,杨慧中
(江南大学教育部轻工过程先进控制重点实验室,江苏无锡214122)
引 言
产品质量、能耗、产物生成效率等关键性变量能够反映间歇过程的性能,但是由于测量环境、时滞、成本等原因,这些关键性变量通常无法在线测量[1-3]。随着集散控制系统在间歇过程中的普遍应用,使得大量生产现场过程数据的获得成为可能。因此,利用这些能够通过传感器在线测量的过程变量作为辅助变量来估计关键性变量的软测量技术就应运而生[4-7]。
由于青霉素发酵过程中伴随着复杂的生物、物理和化学等变化,因此,呈现出严重的非线性、时变性以及多阶段特性,单一的软测量模型难以保证系统对模型精度的要求,而解决此类问题的常用方法是基于聚类建立软测量多模型,从而较好地描述工业对象的复杂特性,提高模型的估计精度以及泛化能力[8-13]。多模型软测量建模的关键在于如何利用聚类算法对样本数据进行准确的划分,常用的聚类算法包括基于划分聚类的K-means 算法[14-15],基于密度的空间聚类(density-based spatial clustering of applications with noise,DBSCAN)算法[16],基于样本之间相似度与归属度的仿射传播聚类(affinity propagation,AP)算法[17-18]等。
密度峰值聚类算法(density peaks clustering,DPC)是Rodriguez 等[19]于2014 年提出的一种新的聚类算法,该算法简单高效,不需要迭代就能找到聚类中心点,且性能不受空间维度的影响,目前受到广泛研究与应用[20-22]。但是该算法也存在缺陷:一是阈值dc较难选取,而算法中的局部密度值ρi的计算是与dc有关的,因此dc对聚类结果有较大影响;二是样本点在分配时,当一个点错分,会导致一系列点错分[23-24]。文献[24]通过样本点到其k 个近邻的距离之和代替dc来计算局部密度(记为KNN-DPC),解决了dc选取的问题,但并未考虑样本点的分配问题。文献[25]通过引入共享近邻代替dc定义样本点的局部密度,同时对聚类中心的选择策略进行改进(记为SNN-DPC),一定程度上减少了样本点的错分。本文在DPC 算法的基础上,提出了一种新的基于改进密度峰值聚类的多模型软测量建模方法。首先,通过计算样本点的k 近邻以及样本点与其k 近邻之间的共享近邻来重新定义样本点的局部密度。同时,考虑到传统的k 近邻计算方法是通过欧氏距离定义的,难以反映样本的数据结构,因此本文进一步引入了相似度函数计算k 近邻点。然后,利用样本点之间的k 近邻关系来重新定义样本点的分配策略,从而提高聚类效果。最后,将改进后的DPC 算法对训练样本集进行聚类,基于得到的子集分别建立最小二乘支持向量机子模型,采用开关方式对新来测试样本进行估计输出。将本文方法应用于青霉素发酵过程,验证算法的有效性。
1 DPC算法
密度峰值聚类算法是一种基于密度的、简单高效的聚类算法。它基于两个假设条件,一是聚类中心的密度高于它周围的点,二是聚类中心点与比它密度更高的点之间的距离相对较大。对于给定样本集X ={x1,x2,xi,…,xn},xi∈Ra×1,DPC 算法主要可分为如下三个步骤:第一步是计算每个样本点的局部密度ρi以及距离值δi;第二步是根据局部密度及距离值绘制决策图并且在决策图上选择最佳聚类中心;第三步是将剩余的样本点分配给密度比它大且距离最近的点所属的类中[25]。DPC 局部密度ρi的定义为:

其中d(xi,xj)是样本点xi与xj之间的欧氏距离,dc表示截断距离。距离值δi定义为样本点xi到比它局部密度更高的其他所有样本点的距离的最小值,若xi为具有最大局部密度的点,则δi为样本点xi到其他样本点距离的最大值,即:

根据每个样本点的局部密度ρi及距离δi得到决策图,在决策图上找到局部密度和距离都较大的点作为聚类中心。在聚类中心选好之后,将剩余的样本点分配给局部密度比它高而且距离最近的样本点所属的类簇中。
2 改进DPC算法
原始的DPC算法[19]虽然简单,计算量小,但是也存在较大的缺陷与不足。
(1)DPC算法将dc作为全局密度阈值,因此dc值对聚类结果影响较大,而确定合适的dc值较为困难,原文是将所有样本点对之间的距离按照升序排列,排在第M×s 位的样本点对的距离值设置为dc,其中M 为样本点对的总个数,s 在1%~2%范围内取值。
(2)局部密度是DPC算法的关键,原文仅仅使用了欧氏距离来计算样本点的局部密度,而没有考虑到样本点与周围点之间的紧密程度,因此计算出的局部密度是不够准确的,不能较好地反映数据的密度分布。
(3)DPC 算法在确定聚类中心后,其分配策略是将剩余的样本点分配给密度比它大且距离最近的点所属的类,这种分配方式会导致当一个点错分时,很可能接下来的一系列点都会错分,从而影响聚类精度。
针对上述问题,本文将重新定义局部密度以及样本点的分配方式,从而有效提高聚类的质量。
2.1 局部密度的计算
DPC 算法中任意一个样本点的局部密度定义可以理解为:通过设定一个全局距离阈值dc,计算其他样本点与该点的欧氏距离,欧氏距离越小,则与该点的相似度越高,该点的局部密度即为其他样本点与它的相似度之和。但是,仅仅通过欧氏距离来定义两点之间的相似度是不够准确的,而且全局的距离阈值的选择十分困难。因此,本文考虑了全局的数据结构,通过引入样本点的k 近邻以及样本点与k 近邻之间的共享近邻来计算样本点之间的相似度,进而计算样本的局部密度。
定义1 设K(xi)表示样本集中距离xi第k 近的样本点,则样本点xi的k近邻集合可表示为:

定义2 样本点xi和xj之间的共享近邻为两个样本点k近邻的交集,可以表示为:
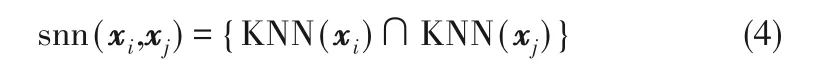
定义3 样本点的局部密度ρi:
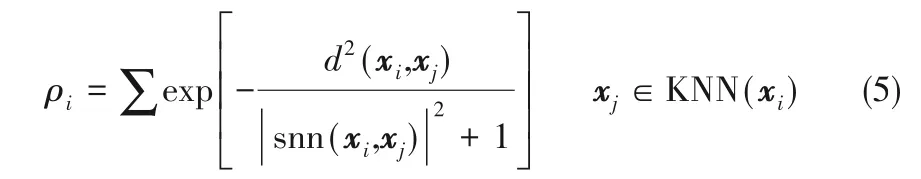
其中|snn(xi,xj)|表示共享近邻集合snn(xi,xj)中的元素个数。
由于样本点的k 近邻是计算局部密度的关键,因而k 近邻的质量对局部密度影响较大。常用的计算某个样本点k 近邻的方法是通过计算其他样本点到该点的欧氏距离后选择最近的k 个样本点,但是仅仅通过欧氏距离得到的k 近邻不能反映出样本的数据结构。因此,受文献[26]启发,本文进一步考虑引入相似度函数来计算样本点的k近邻。
定义4 样本点之间相似度函数S(xi,xj)的定义为:
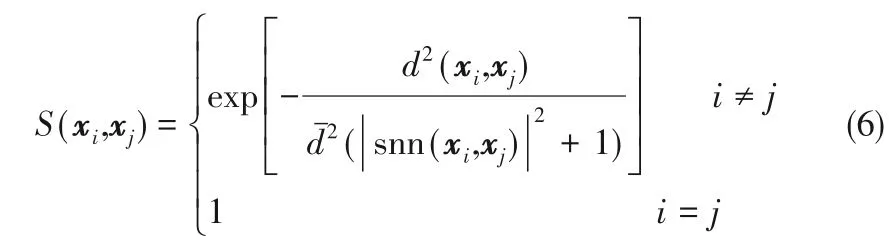

该相似度函数不仅考虑了距离,而且引入了共享近邻,两点之间的共享近邻个数越多,表明两点之间连接得越紧密,进而两点之间越相似,因此由相似度函数选择新的k 近邻更符合样本的数据结构。
局部密度的计算步骤如下。
(1)对于每个样本点xi,通过欧氏距离选择初始的k 近邻点及共享近邻,使用相似度函数(6)计算其他样本点与xi之间的相似度,将第k 大的相似度记为Sk(xi,xj)。
(2)通过相似度大小选择新的k 近邻点以及共享近邻。
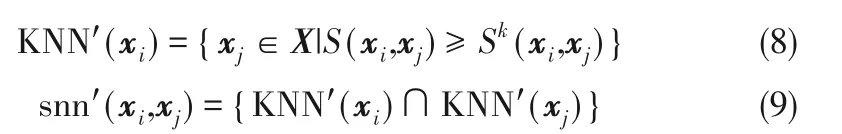
(3)基于得到的k 近邻点以及共享近邻计算局部密度。

2.2 样本点的分配策略
由于DPC 算法的分配方式是把样本点分配给密度比它大且距离最近的点所属的类别,如图1 中所示,红圈及其附近的点由于DPC 分配方式的缺陷,错分给了箭头所指的类别中,图中相同颜色的点表示其属于同一类别。
通常来说,如果样本点属于同一类,它们之间是可以通过点与点之间的k 近邻相互连接的,任意两个样本的k 近邻连接如定义5 所示,可以看出图1中红圈与箭头所指类别的点是不能通过k近邻相互连接的。因此,本文利用k 近邻关系对原始方法样本点的分配方式进行改进。
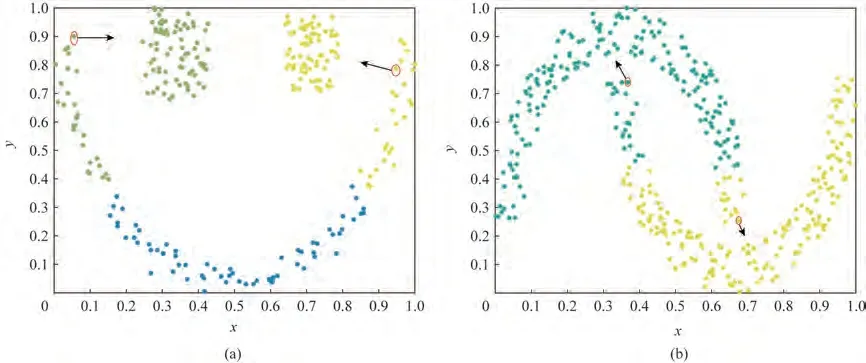
图1 DPC错分图Fig.1 The wrong allocation results for DPC
定义5 k 近邻连接:对于任意一个样本点,先通过相似度大小即式(6)~式(8)搜索它的k近邻,然后继续搜索这k 个近邻点的k 近邻,重复搜索,直到搜索得到的所有k近邻点组成的集合不发生改变,该集合记为Z。如果两个样本点xi和xj对应的Zi和Zj有交集,则认为它们能够通过k近邻连接。
改进后的分配策略流程框图如图2 所示,其中,对任一待分配样本点xi,将密度比它大的点通过距离由近到远分别记为xi1,xi2,…,xil,…,xiq,其中q表示密度比xi大的点的个数。令l = 1,判定待分配点xi与xil之间是否能够通过k 近邻连接,如果是则将该点分配给xil所属的类别,否则,令l = l + 1,继续寻找密度比它大并且与它能够通过k 近邻连接的点。
3 基于改进DPC 的多模型软测量建模
多模型软测量建模方法流程图如图3所示。
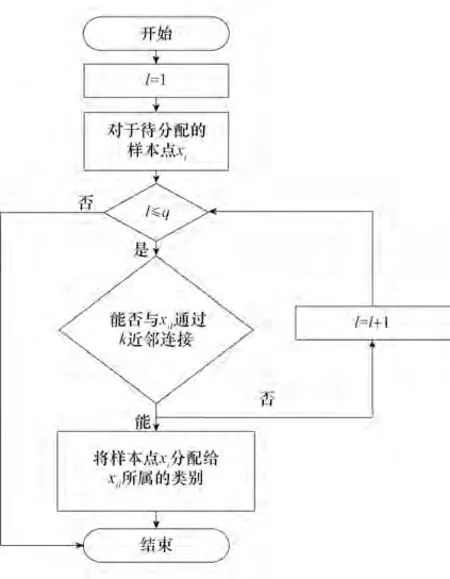
图2 分配策略流程图Fig.2 The flow chart of allocation strategy

图3 多模型建模框图Fig.3 The framework of multi-model soft sensor
设训练样本集为D ={(xi; yi)},i = 1,2,…,n,xi∈Ra×1为a 维输入变量,yi∈R1×1为一维输出变量,多模型软测量建模步骤如下。
(1)样本聚类:采用本文改进的DPC算法对训练样本集的输入数据进行聚类划分,得到K 个子数据集{D1,D2,…,DK}以及各子集聚类中心。

图4 不同聚类方法在UCI数据集上的聚类评价指标Fig.4 Evaluation indexes on UCI datasets for different clustering methods
(2)建立子模型:采用最小二乘支持向量机[27-29]对得到的各个子数据集建立相应的子模型{m1,m2,…,mK}。
(3)待测样本类别划分:对于待测样本xtest,计算其到各个聚类中心的欧氏距离,将xtest划分到与其最近的聚类中心所属的类别r(r = 1,2,…,K)中。
(4)采用“开关切换”融合方式,基于xtest计算对应子模型mr的输出ypr,并将其作为最终软测量模型的预测输出ytest。
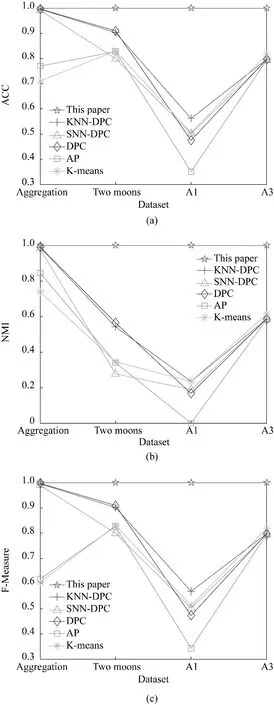
图5 不同聚类方法在人工数据集上的聚类评价指标Fig.5 Evaluation indexes on synthetic datasets for different clustering methods
4 仿真验证
为了验证本文方法的有效性,首先在UCI 真实数据集以及常用人工数据集上对改进DPC 聚类算法的有效性进行仿真验证。进一步将改进的DPC聚类算法应用于青霉素发酵工业过程中,通过聚类建立软测量多模型对青霉素产物浓度进行估计。
4.1 UCI真实数据集聚类
本 文 选 取Iris、Seeds、Wine、WDBC、Zoo、Ionosphere 共6 个不同属性和样本个数的UCI 数据集[23,25]进行仿真实验,并将本文算法与KNN-DPC[24]、SNN-DPC[25]、DPC[19]、AP[30]和K-means[31]进 行 比 较。采用准确率(accuracy, ACC)、标准化互信息(normalized mutual information, NMI) 和F 值(FMeasure)[24]三种指标对聚类结果进行评价,评价指标如图4 所示。三种评价指标的取值范围均为[0,1],值越大表示聚类效果越好。
从图4 的三个评价指标可以看出本文方法在6个UCI数据集上的效果均优于其他聚类算法以及两种改进的DPC 算法,并且相较于原始DPC 算法效果有较大提高,验证了本文所提算法的有效性。
4.2 人工数据集聚类
本文选用了Aggregation、Two moos、A1、A3 共4个常用人工数据集[23,32](二维)对不同算法进行实验比较,相应的ACC、NMI 和F-Measure 如图5 所示。从图5可以看出,本文方法的聚类评价指标最优,为了更加直观地体现本文方法的优越性,将其与KNN-DPC 和SNN-DPC 两种改进DPC 算法的聚类结果进行对比,如图6~图9 所示。从图6~图9 可以看出,只有本文方法能够对4 个人工数据集进行完全正确地聚类,其他两种改进DPC 聚类算法都存在错误聚类的情形。
4.3 青霉素发酵过程软测量建模
为了验证本文方法的有效性,选取青霉素发酵过程作为研究对象。所用数据通过Pensim 仿真平台获取,该平台以Birol 模型为内核,充分考虑了多种物理量和生物量,是一个能够全面反映青霉素发酵过程且常用的仿真平台,具有较高的权威性与实用性[33-35]。

图6 算法在Aggregation数据集上的聚类结果Fig.6 Clustering results on Aggregation
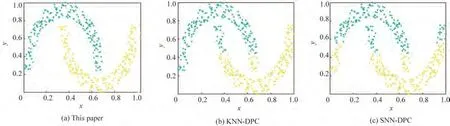
图7 算法在Two moons数据集上的聚类结果Fig.7 Clustering results on Two moons

图8 算法在A3数据集上的聚类结果Fig.8 Clustering results on A3
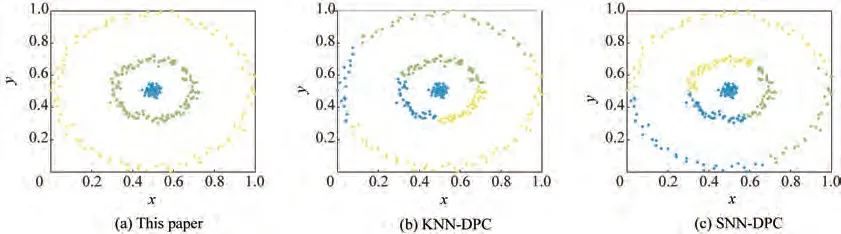
图9 算法在A1数据集上的聚类结果Fig.9 Clustering results on A1
本文以难以在线测量的青霉素产物浓度作为输出变量,选取与其密切相关的11个过程变量作为软测量模型的输入变量,包括通风速率、底物流加速率、底物浓度、溶氧量、底物流加温度、培养液体积、CO2浓度、反应热、pH、反应罐温度、碱流加速率。
通过设定不同的初始条件,产生7 个批次的样本数据,并设定每个批次的发酵时间和采样间隔分别为400 h 和1 h。将其中的5 个批次作为训练数据,剩余2 个批次作为测试数据。考虑到实际发酵过程中可能受到环境的影响,因此给测量数据加入了信噪比为35 dB的高斯白噪声。
首先,运用本文改进后的DPC 算法对训练集的输入数据进行聚类划分,得到各个子集以及聚类中心,然后对得到的子集分别建立最小二乘支持向量机(least squares support vector machine,LSSVM)模型,对于测试批次数据,根据其到各个聚类中心的距离,将其划分到与其最近的聚类中心所属的类别中,采用相应的子模型进行估计输出。测试数据的划分结果如图10所示,改进后的DPC算法将青霉素发酵过程划分为四个阶段,分别对应于滞后期、快速生长期、合成期和死亡期。该分段结果与实际青霉素发酵过程的阶段划分相吻合,表明了本文提出的改进DPC算法的有效性。
为了进一步验证本文方法的有效性和优越性,将本文所提基于改进DPC 聚类多模型软测量建模方法与LSSVM 单模型方法,以及基于未改进DPC聚类的LSSVM 多模型方法(记为DPC-LSSVM)进行仿真比较,2 个测试批次的青霉素浓度预测结果分别如图11 所示。为了定量评价各个软测量模型的效果,本文采用均方根误差(root mean square error,RMSE),最大误差(max error,MAXE)以及平均误差(mean error,ME)[11]来对不同方法进行比较,结果如表1所示。

表1 不同模型的预测误差比较Table 1 Comparison of prediction errors of different models
从图11 及表1 可以看出,在初始条件不同也即发酵过程不同的两个测试批次上,本文方法的预测效果最好,三个误差评价指标比DPC-LSSVM 及LSSVM 单模型都要小很多。在RMSE 指标上,DPCLSSVM 相较于LSSVM 单模型分别提高了13.9%及8.2%,而本文方法分别提高了36.2%及30.9%,这是由于青霉素发酵过程自身的时变性、非线性及阶段特性造成LSSVM 单模型的估计精度有限,而多模型的估计精度更高,性能更优越。本文所提方法在原始DPC 聚类算法上进行改进,能对样本数据更加合理地聚类,因此,相较于DPC-LSSVM 具有更好的预测能力和泛化能力。

图10 DPC改进前后的分类结果Fig.10 Classification results for the original DPC and improved DPC
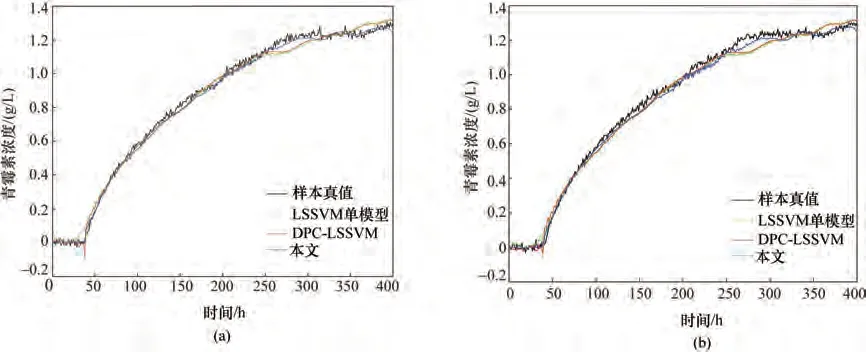
图11 两个测试批次的青霉素浓度预测结果Fig.11 Test sample simulation results of two batches for product concentration
5 结 论
针对青霉素发酵过程中的时变性、非线性、阶段性以及关键生物参数青霉素浓度难以在线测量的问题,提出了一种基于改进密度峰值聚类的多模型软测量建模方法。该方法通过引入相似度函数代替欧氏距离,得到更加符合数据分布的k 近邻以及共享近邻并利用其重新定义局部密度,然后通过点与点之间的k 近邻关系来重新定义样本点的分配策略,能够获得更合理的聚类,从而提高软测量多模型的估计精度。基于UCI真实数据集以及常用人工数据集的仿真结果表明,本文提出的改进DPC 算法相对于原始DPC 算法性能有很大提高,且优于用于对比的两种改进DPC 算法以及其他聚类算法。进一步将改进的DPC 算法应用于青霉素发酵工业过程,建立软测量多模型对产物浓度进行估计,仿真结果表明,相较基于原始DPC 方法建立的模型,本文方法建立的模型估计精度更高,且泛化能力更好。
猜你喜欢
中华书画家(2021年12期)2022-01-06
家庭医药(2021年16期)2021-12-02
家庭医药·快乐养生(2021年8期)2021-08-30
散文诗(2020年1期)2020-07-20
祝您健康·文摘版(2019年10期)2019-10-14
雷达学报(2017年6期)2017-03-26
东方艺术·国画(2016年3期)2017-02-08
文理导航·科普童话(2016年7期)2017-02-04
发明与创新(2016年38期)2016-08-22
互联网天地(2016年1期)2016-05-04
