
一种基于深度学习的多曝光高动态范围成像方法
2021-04-25 05:24刘震
现代计算机 2021年6期
刘震
(四川大学计算机学院,成都610065)
0 引言
在数字图像领域,动态范围(Dynamic Range)是指所拍摄场景中最大亮度与最小亮度的比值,即最大像素值与最小像素值之比。对于传统的低动态范围(Low Dynamic Range,LDR)图像,每个像素值用8 位二进制数表示,最大只能表示256 个灰度等级,因此图像所能表示的动态范围有限。相较于LDR 图像,高动态范围(High Dynamic Range,HDR)图像中每个像素值具有更高的位深,能够更加准确地记录和展示真实场景中的亮部与暗部细节,从而获得更好的视觉效果。
随着智能手机与超高清电视等电子设备的普及,HDR 成像与显示技术的需求日趋旺盛。同时,HDR 在卫星气象、遥感探测、医疗等诸多方面也具有广泛的应用前景。受限于成本,目前绝大部分智能手机的摄像头传感器只能拍摄LDR 图像。目前获得HDR 图像的方式主要有两种,一种是用专用的设备直接拍摄与存储HDR 图像,但是这种方法成本过高,无法普及[1]。另一种方法则是拍摄多张LDR 图像,通过算法后期合成为HDR 图像,这种方法无需特定设备,预期成本低,因此在近些年受到很多研究人员的关注[2-5]。
在本文中,我们针对动态场景下的多曝光高动态范围成像技术进行研究。在同一场景中,不同曝光值(Exposure Value,EV)的LDR 图像包含的图像细节不同,例如,高EV 图像中整体亮度较高,场景暗部细节更丰富,低EV 图像整体偏暗,场景中亮部细节更多。跨曝光HDR 融合问题就是需要将不同EV 的LDR 图像融合成一张具有丰富的亮、暗部细节的HDR 图像。对动态场景来说,由于手持相机抖动或者被拍摄目标物的运动,经常会在融合后产生鬼影问题,导致最终融合的结果图效果不好。
针对上述问题,本文基于深度神经网络,提出一种特征融模型,用于动态场景下的多曝光HDR 成像。该模型由特征编码器、特征融合模块以及后处理模块组成。特征编码器负责提出多个尺度的LDR 图像特征,特征融合模块利用融合掩码(mask)对每一个尺度的特征进行融合,最后使用一个后处理模块优化融合的特征,产生最终的HDR 结果。本文做了大量的测试与对比实验,实验结果表明我们的方法在HDR 效果与鬼影去除能力上均要优于传统方法。
1 相关工作
1.1 HDR成像技术
目前通过LDR 合成HDR 图像主要有两种形式:通过单一曝光或者多重曝光。对于单一曝光HDR 成像,其思路是直接学习LDR 图像到HDR 图像的映射,这种方法由于只需要对输入图像进行一次曝光,因此不存在鬼影问题,但是需要算法具有能够有效恢复出饱和区域的细节的能力。另一种更为常见的形式则是通过多张不同曝光的LDR 图像融合产生最终的HDR结果。此类方法通过融合不同曝光图像中的良好曝光区域(如高曝光图像中的暗部以及低曝光图像中的亮部),因此通常能够获得更好的图像细节。Sen 等人[4]和Hu 等人[5]先后提出基于块匹配的方法,这种方法在静态场景下能够获得较好的结果。对于手持相机,由于手的抖动或者前景目标运动,导致不同曝光的LDR 图像内容存在没有对齐的区域,直接融合会导致鬼影现象。本文主要针对动态场景进行研究。
1.2 深度神经网络
近年来,随着计算机硬件的发展,深度神经网络(Deep Neural Networks,DNN)逐渐成为主流方法,在人脸识别[6]、目标检测[7]、医疗影像[8]等领域取得了巨大成功。DNN 获得成功的一个重要原因是其拥有传统方法无法比拟的数据表征能力。与传统方法不一样,DNN是基于数据驱动的学习方法,能够更好地挖掘数据中的信息。在本文中,针对传统方法在动态场景多曝光HDR 成像任务中表现不佳的问题,我们引入DNN,旨在设计一个高性能的神经网络,用于合成高质量、无鬼影的HDR 图像。
2 特征融合网络
2.1 算法流程
与传统块匹配方法或者基于图像尺度的DNN 方法不同,本文从特征尺度出发,提出一个特征融合网络。算法的整体流程为:输入三帧动态场景下拍摄的LDR 图像Il、Ir和Ih,通过我们提出的特征融合网络进行训练,输出HDR 图像IH,即:

其中f 表示本文提出的特征融合网络,θ表示网络需要优化的参数。
2.2 网络结构
如图1 所示,我们的特征融合网络的结构主要分为三部分:特征编码器、特征融合模块以及后处理模块。特征编码器用于抽取输入三张LDR 图像的四级尺度特征,即:
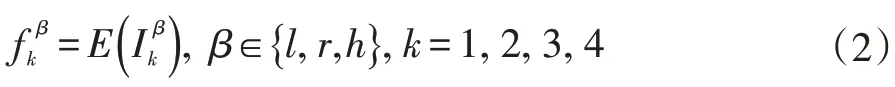
E 表示特征编码器。我们的出发点是,在多尺度特征上进行由粗糙到精细的融合要比在单一尺度上容易获得更好的融合效果。与此同时,为了能够适应性的选取亮帧和暗帧LDR 图像中相对应的细节区域,同时有效地去除鬼影,我们将输入图像Il和Ih拼接起来送入一个mask 生成器,输出相对应尺度的mask:
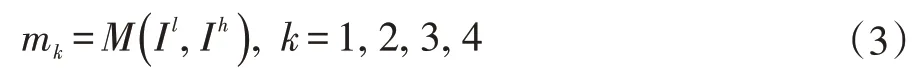
M 表示mask 生成器,这里我们同样生成四个尺度的mask。
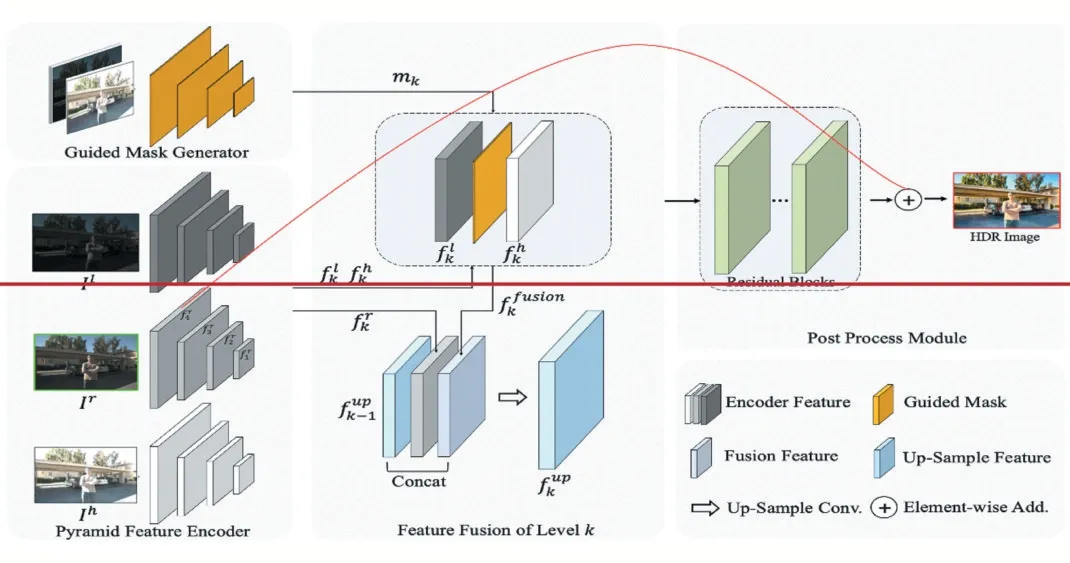
图1 网络结构图
在获取了多尺度特征和mask 之后,我们对每一个尺度的特征进行融合,如图所示,对于第k 个尺度,特征融合过程如下:

同样的,对于四级尺度特征的融合也是一个由粗糙到精细的过程,在获取一个尺度的融合特征fkfusion之后,我们将其与上一级输出特征fk-1up以及中间帧的特征fkr拼接起来,作为当前尺度融合模块的输出,即:
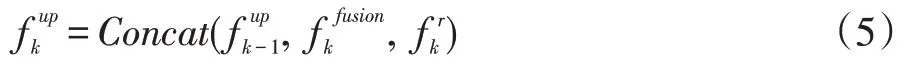
最后,在获得最高级融合特征f4up之后,我们将其送入后处理模块进行优化,获得最终的HDR 结果。后处理模块由一系列残差模块组成。为了网络更好的训练与优化,我们采用了残差连接(图1 红色实线所示)。
3 实验
3.1 数据集与实验环境
本文提出的模型使用Kalantari[9]提出的数据集作为训练数据。该数据集具有74 组训练样本和15 组测试样本,每一组样本包含三张LDR 图像作为输入以及一张HDR 图像作为标签。每一张图片的尺寸为1500×1000。为了提升硬件利用率以及更好的优化模型,我们不是直接输入原图,而是在训练过程中随机裁剪出256×256 的图像快作为输入,同时我们随机对输入图像块进行随机翻转和旋转等数据增强。
本文中所有的实验均在Linux 操作环境下进行,使用NVIDIA RTX 2080Ti 显卡训练模型,训练代码使用PyTorch 框架实现。在实验过程中,使用Xavier 初始化函数对模型参数进行初始化,初始学习率设为1x10-4,每训练100 轮,学习率减半,一共需要训练300 轮收敛。我们使用L2 损失作为模型的目标函数,使用Ad⁃am 优化器优化模型。
3.2 评价指标
为了评价生成HDR 图像内容的质量,我们使用PSNR(Peak Signal-to-Noise Ratio)和SSIM(Structure SIMilarity)作为实验结果的评价指标。PSNR 用于计算图像的峰值信噪比:

其中MAXI2表示图像可能的最大像素值,对于8位图像来说就是255,MSE 表示图像的均方误差。SSIM 是计算图片结构相似性的一个重要指标。除此之外,我们还记算了HDR-VDP-2 作为评价HDR 效果的指标,HDR-VDP-2 用于衡量HDR 图片质量。这三个评价指标的值均是越大越好。
3.3 实验结果分析
在模型训练收敛以后,我们在测试集上对模型进行测试。对于测试结果,我们进行了客观评价指标分析和主观结果对比。如表1 所示,我们记算和对比了两个传统方法和我们方法测试结果的PSNR、SSIM 和HDR-VDP-2 等指标。从表中数据可以看出来,本文方法在这三个指标上均大幅超过传统方法,证明本文方法恢复出来的HDR 图像在图像质量以及HDR 效果上均要优于传统方法。
除了客观指标,我们还从主观结果图上进行了对比分析。如图2 所示,左边展示了动态场景下输入的三张不同曝光值LDR 图像,右边分别为Sen 的方法[4]、Hu 的方法[5]、本文方法和真实标签结果。从图中可以看出来,由于输入场景中人的手臂运动,导致Sen 和Hu 的方法在融合之后产生了鬼影(背景墙壁处),而本文方法的结果则能够有效的去除鬼影且融合的HDR结构质量更好,更接近真实标签结果。综上可知,本文基于深度神经网络的特征融合模型要优于传统方法。

表1 客观评价指标对比

图2 主观结果对比图
4 结语
本文针对传统HDR 成像技术在动态场景中效果不佳和存在鬼影的问题,利用深度神经网络,提出一种用于多曝光HDR 成像的特征融合模型。该模型由特征编码器、特征融合模块和后处理模块组成,分别用于多尺度特征提取,特征融合和融合特征的优化。实验结果表明,本文提出的模型在PSNR、SSIM、HDR-VDP-2 等指标上高于传统方法,且主观视觉效果更好。然后,由于训练数据中缺乏极度过曝/欠曝场景,导致模型在极限场景下的表现不佳。在未来的研究工作中,我们将致力于更好地恢复极限场景中饱和区的细节。
猜你喜欢
卫星应用(2022年7期)2022-09-05
社会科学战线(2022年7期)2022-08-26
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
环球慈善(2019年6期)2019-09-25
初中生世界·九年级(2018年12期)2018-12-22
读者(2015年9期)2015-05-04
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
初中生世界·八年级(2014年2期)2014-03-15
