
基于嵌入并行注意力机制的YOLOv3 模型高原动物种类检测算法*
2021-05-10 03:10拉毛措安见才让拉毛杰
微处理机 2021年2期
拉毛措,安见才让,拉毛杰
(1.西藏大学信息科学技术学院,拉萨850000;2.青海民族大学计算机学院,西宁810007)
1 引 言
目标检测与识别技术是数字图像和视觉领域中的研究热点之一[1],被广泛应用于人脸识别、动物管理、植物种植、交通管理等应用领域中[2-4]。其中的YOLO 算法近年来得到了广泛的应用。但YOLO 算法将目标检测任务作为回归问题来处理,没有区分前景与背景区域的差异,从而产生了较高的误检和漏检率。Faster-RCNN 目标检测算法[5]在生成感兴趣区域时就将可能含有待检测物体的区域基本标记下来,提高了分类准确率,也节省了分类过程的处理时间。当前对目标检测算法的改进主要包括:采用含有更多特征的、功能更强的基础神经网络和融合多尺度的目标特征来进行目标检测。温捷文等人[6]移除了YOLOv2 模型的Dropout 网络层,对特征提取的网络部分进行规范化处理,从而比原来YOLO v2 模型获得了更高的检测精确率和更短的训练时间。Lin 等人[7]利用人工卷积神经网络的多尺度特征,提出了一种横向连接、自上而下的具有金字塔形状的网络结构,它融合多层的特征图,用不同的特征尺度分别进行目标检测。胡杰等人[8]提出通道注意力机制,将其分别应用到ResNet 及ResNeXt 等网络上,使在ImageNet 2012 数据集[9]上分类实验的top-1 及top-5 的错误率降低了最多1.80%和1.11%,并在基于COCO 2014 数据集[10]的实验中获得 mAPIoU = 0.5,比原来提升1.6%。Woo 等人[11]对卷积操作的通道关系和空间关系加权,更优地筛选出所需的关键特征。在YOLO v3 检测模型提取出卷积特征,但未对卷积核中不同的特征位置进行加权处理。徐诚极等人[12]提出通道注意力及空间注意力机制串行地加入特征提取网络之中,使用经过筛选加权的特征向量来替换原有的特征向量进行残差融合,同时添加二阶项来减少融合过程中的信息损失并加速模型收敛。但在实际应用场景中,图像中待检测物体的四周存在着复杂而关键的语义信息,如果对目标区域的特征加上相应信息及权重,模型将能更好地抽取待检测目标的关键定位信息。鉴于此,提出基于并行注意力机制的改进YOLO v3 算法。在网络残差连接中加入并行注意力机制,可使加入注意力后的梯度能进入更远的网络中。
2 相关工作
深度学习的训练需要大量高原畜牧业动物图像,但目前尚未有关于青藏高原畜牧动物的数据集资料公开发布过,创建工作须从头展开。模型训练前,首先要到农牧区进行实地采集不同季节、不同动物、不同草场的动物图像,并对图像进行筛选。最后用图像标注工具进行数据标注,建立青藏高原畜牧动物数据集。
图像数据采集后,每类动物有3000 多张图像,总数共计10060 余张,筛选后,图像数量还有减少。显然此类规模的数据集不算大,为提高性能和鲁棒性,在此采用数据增强技术。数据增强技术包括:旋转、平移、缩放、翻转、添加噪声、增加对比度等。
深度学习神经网络训练的数据集不但要采集真实的图像,还需要作详细的标注,并生成文件。在此使用LabelImage 标注工具,对图像中的牦牛、藏系羊和马作出详细的人工标注。对牦牛的标注情况如图1 所示。

图1 对牦牛的详细人工标注情况
3 嵌入并行注意力机制的改进模型
3.1 YOLO v3 算法
YOLOv2 算法提出了一种同时使用训练目标检测数据集和图像分类数据集的方法,并且使模型识别未曾标注过的数据。YOLOv3 具有与YOLOv2 一样的快速与精准,并且更适合小目标物体的检测和识别。YOLOv3 算法对检测对象定位不准等问题做了改进,主要包括:种类检测从单标签改为多标签,改善了分类性能;在三个尺度上充分利用图像中关键特征进行检测;使用残差连接的网络来提取特征。
YOLOv3 主要完成的工作有:①输入图像,提取特征;②检测边界框与类别;③清除置信度低的候选框;④计算分类概率与坐标误差。
3.2 YOLO v3 的核心网络
作为YOLOv3 的核心的Darknet-53 网络,是在Darknet-19 的基础上增加残差模块开发起来的,其结构见图2。图像数据在网络中传播时,每次用步长为2 的卷积核作卷积,从而使新图像的大小比原图像减小一半。

图2 Darknet-53 网络结构图
如图2 可见,经过这样的5 次卷积后,特征图大小为原来的1/32。因此,输入图像大小必须为32 的倍数,此处设为 416×416(416=32×13)。在 YOLO v3中取消了池化层和全连接层。为解决网络中可能出现梯度爆炸或消失的问题,Darknet-53 网络结构中采用了residual 结构,能够更好地控制梯度问题。
3.3 基于通道和空间注意力机制的残差结构
YOLO v3 增加了残差模块,以此缓解随着深度增加造成的梯度消失问题,效果是能够在训练成百上千的深度神经网络的同时不会伴随有错误数量的迅速提升。残差中的1×1 卷积,减少了卷积通道数、参数量和网络的计算量[13]。此处对Darknet-53采用改进的残差模块,主要考虑到要融合并行的通道注意力和空间域注意力。改进的残差单元如图3所示。

图3 Darknet-53 改进的残差单元
算法需要做全局平均池化和全局最大池化。设通道全局平均池化和全局最大池化的输出分别为CAtt avg及 CAttmax,且 CAttavg∈R1×1×c,CAttmax∈R1×1×c。一维的权重向量CAttavg可以筛选出图像中目标物体的全局信息,CAttmax可以筛选出图像中目标物体的显著特征。设X=[x1,x2,...,xc],其中xc表示的是第c 个卷积核的参数,详细如下式:

接着,设有:
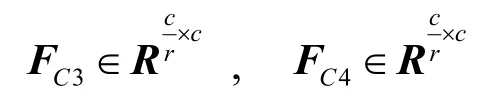
分别为两个全连接层的共享参数,其中r 为降维比例,取r=16。则通道注意力模块的输出为:

同时,并行注意力机制的空间注意力又需要将xc输入到模块中。
设空间域全局平均池化和全局最大池化的输出分别为 SAttavg及 SAttmax:
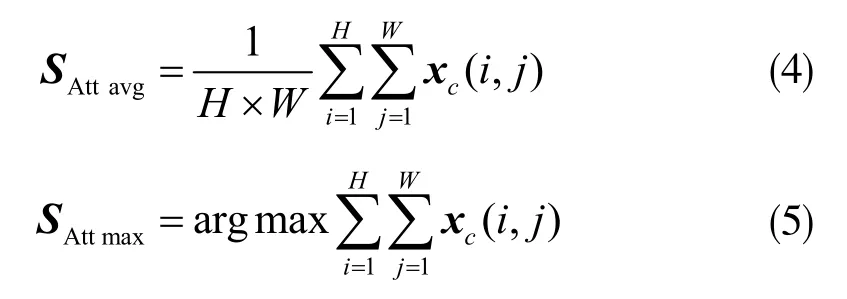
接着,对特征SAttavg和SAttmax进行拼接,并做全连接处理,则空间域注意力模块部分的输出为:
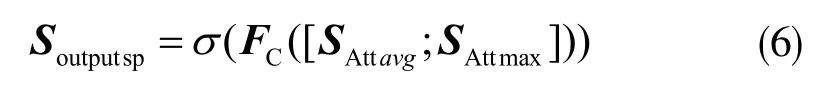
进一步对通道注意力特征Aoutputch和空间注意力Soutputsp进行拼接,接着做全连接处理,得到最终融合通道和空间注意力的权重:

再次,通过输入矩阵xc和注意力权重矩阵Aoutputatt做内积完成对输出矩阵xc的加权操作:

最后,并行注意力机制模块的输出为:

此处输出模块的特征向量的维度与输入的维度一致,没有对YOLOv3 的Darknet-53 网络结构进行大幅度的修改,而只对残差模块做了调整。由于改进后的网络结构较复杂,运行速度较原网络稍慢。
3.4 多尺度与动物种类预测
输入一张符合尺寸的图像并且分成S×S 网格,在改进的YOLOv3 上运行得到特征图,卷积层进行三次支路预测,输出为:y1:(13×13),y2:(26×26),y3:(52×52)。在每个分隔的图像网格上预测bounding box(边界框)及其confidence(置信度),每个 bounding box 都会产生中心坐标(x,y)及宽高坐标(w,h)。置信度具体计算如下:
其中,IOU表示真实框和边界框的交集与并集之比。Pr(·)为预测网格上是否有目标,计算方法如下:

在改进YOLOv3 中不但检测边界框和置信度,还要检测种类概率Pr(·|·)。当网络模型训练完而进行测试时,边界框的类别概率乘以置信度的值得到边界框的种类置信度,如下式所示:

边界框的动物种类置信度大于阈值0.5,那么该边界框的目标就属于该种类。
4 实验结果与分析
为验证所提出的改进YOLO v3 模型对高原牦牛、藏系羊和马等动物图像识别准确率,抽取531张图片作为测试集,其中牦牛213 张,藏系羊200张,马108 张,采用mAP 值作为评价指标进行实验。实验结果如表1。可见,改进的YOLOv3 网络模型的mAP 为89.4%,与原来相比,提高了1.6%。

表1 动物识别实验结果
5 结 束 语
融合并行注意力机制的改进YOLO v3 目标检测识别算法继承了YOLOv3 的优点,并在模型提取的特征向量上引入并行通道和空间域注意力机制,进行有重点的关注和修正,使整个网络能更好地检测和识别动物种类。该模型对畜牧业动物图像中动物检测、种类识别准确率有一定提高,在数据集上的实验表明,在没有增加太多参数量的情况下,改进YOLOv3 算法比原始算法具有明显优势。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小型微型计算机系统(2022年4期)2022-05-09
小雪花·成长指南(2022年1期)2022-04-09
核科学与工程(2021年4期)2022-01-12
北京航空航天大学学报(2020年10期)2020-11-14
机电产品开发与创新(2020年2期)2020-05-07
自动化学报(2019年6期)2019-07-23
计算机应用(2018年5期)2018-07-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
