
跨尺度代价聚合网络
2021-05-13 07:16黄怡洁周佩朱江平张建伟
现代计算机 2021年8期
黄怡洁,周佩,朱江平,张建伟
(四川大学计算机学院,成都610065)
0 引言
双目立体匹配是计算机视觉领域非常重要的课题,其关键在于找到双目立体图像对中像素点的相关性,根据三角测量原理计算出视差,根据视差计算出目标的深度信息。立体匹配可广泛应用与增强现实[1]、三维建模[2],以及机器智能[3]等领域。
传统的立体匹配算法包含代价聚合、视差计算、视差优化和视差后处理[4]四个步骤完成。近些年,很多基于卷积神经网络[5]的立体匹配算法取得较好的效果。双目立体图像对作为网络的输入,通过端到端的神经网络,可以直接预测出一张视差图。Zbontar 等人[6]提出使用块匹配结合卷积神经网络计算匹配代价,且在代价聚合模块融入半全局的方法,有助于减少遮挡区域的误差;Kendall 等人[7]在提取特征的时候,融入几何信息,构建4D 的匹配代价集,代价聚合网络中用3D 卷积进行多尺度特征融合,提高匹配的精度;Jie Zequn 等人[8]用递归的左右一致性检查模型,该模型在视差计算阶段就可进行视差一致性检查;Khamis[9]在使用Siamese 提取特征,网络先预测出低分辨率的视差图,再以色彩输出为导向,产生高精度的视差图;李航等人[10]提出沿着通道以及空间维度聚合特征信息,将3D 残差以及密集模块融入代价聚合网络;马伟等人[11]使用CNN 提取图像特征并进行区域分割,再用CNN匹配结果构建MRF 能量函数,最后通过优化能量函数计算视差;王玉峰等人[12]采用宽步长将右特征图进行平移结构建稀疏三维损失体,并结合两种损失函数训练模型。尽管以上算法取得了较好的效果,但在弱纹理区域仍然存在误匹配的问题,且3D 卷积的计算消耗过大,对实时性能有所影响。
因此,本文提出了跨尺度代价聚合网络(CSSN),在特征提取模块,使用笔者在之前研究当中的注意力模块,提取包含丰富语句信息的特征,将左右图像的特征图进行相关性操作,构建3D 的匹配代价集,在代价聚合网络部分,将不同尺度的匹配代价集进行融合产生低分辨率的视差图,再经过残差模块进行视差优化,生成了最终的视差图,减少了弱纹理区域的误匹配问题,在KITTI[13-14]数据集上取得较好的效果。
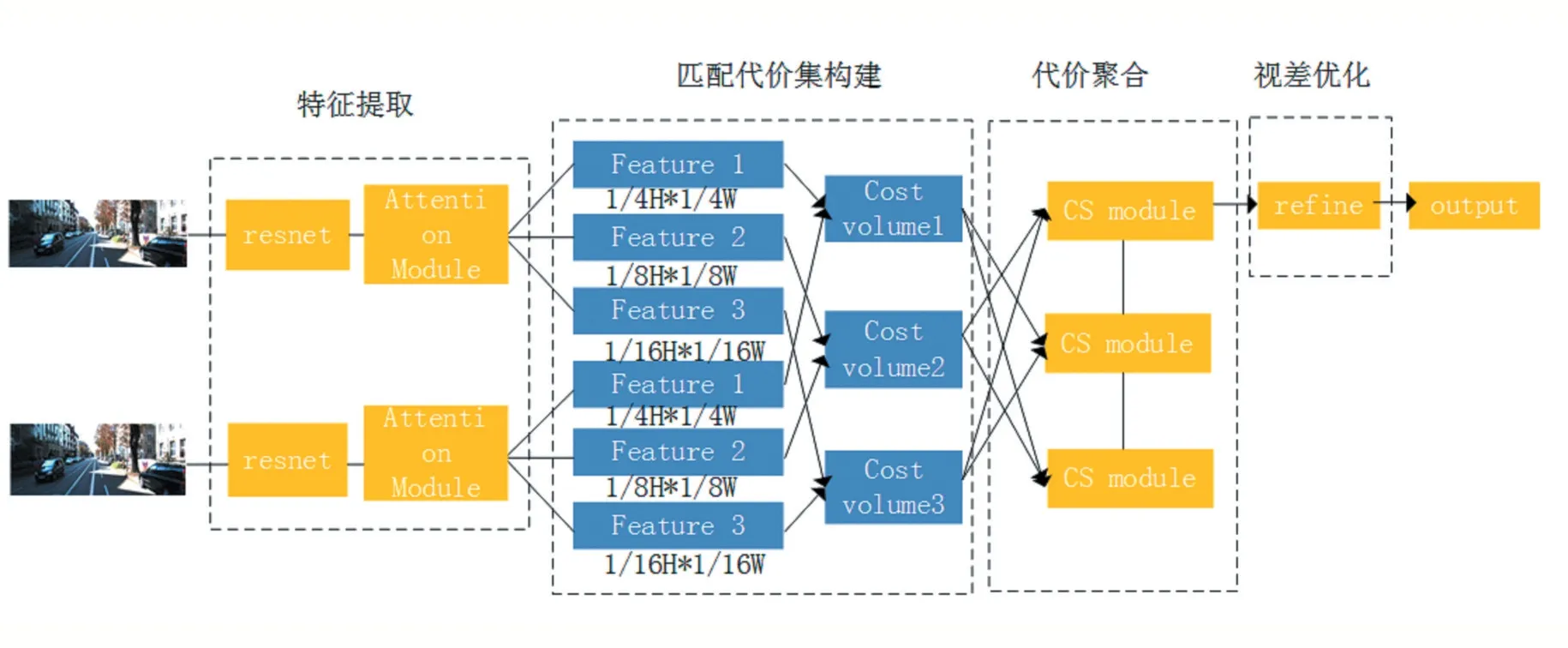
图1 跨尺度代价聚合网络结构
1 跨尺度代价聚合网络(CSSN)
1.1 网络结构
由于弱纹理区域包含的信息较少,需要通过下采样提取到包含有效信息的特征,而在网络的深层细节信息的感知较差,因此大尺度的特征恢复空间细节信息,因此,代价聚合网络进行跨尺度的匹配代价集的聚合,可以预测出更加准确的视差图。本文网络主要分为四个部分,特征提取、匹配代价集构建、跨尺度代价聚合以及视差优化。网络结构如图1 所示。
特征提取网络:特征提取网络中先用残差模块,将图像分别下采样到1/4H*1/4W、1/8H*1/8W、1/16H*1/16W,提取不同尺度的特征,并在第三个残差模块后加入笔者在之前研究中使用的注意力机制模块,提取包含丰富语境特征的信息。细节将在1.2 小节当中介绍匹配代价集构建:将左右图像提取的多尺度特征分别进行相关性操作,构建3D 匹配代价集,其大小为D*H*W。建立三个不同尺度的匹配代价集,用于跨尺度代价聚合。
跨尺度代价聚合:代价聚合阶段的特征需要包含空间细节信息且在弱纹理需要采样得到更多的信息,因此进行不同尺度的代价聚合。首先将匹配代价集采样到与其他匹配代价集相同的尺度,再通过卷积操作进行融合,生成三个低分辨率的视差图,将在1.4 小节中详细介绍。
视差优化:将代价聚合网络中低分辨率的视差图上采样,并利用残差模块,产生与输入图像相同尺度的视差图,进一步提高了视差预测的精度。
1.2 特征提取网络
由于在弱纹理区域、遮挡区域等信息较少,易发生误匹配的问题,因此,提取的特征中包含丰富的上下文语境信息至关重要,本文在特征提取网络使用了改进的ResNet50[15]提取局部特征以及笔者之前提出的注意力机制模块,从空间维度和通过维度分别捕获语境信息。注意力模块由通道和空间注意力模块组成,通道注意力模块学习通道图之间的相关性,增强了特征图之间的依赖关系;空间注意力模块某位置的特征融合了其他位置的特征信息,捕获大范围的语境信息。
特征提取网络的结构图如图2 所示。首先,将图像下采样到大小为1/2H*1/2W 的尺寸得到特征Fdown,再将其输入到改进的残差网络ResNet50 中,提取多尺度的特征Fs=1,2,3,4,该残差包含四层,每一层包含的残差块的数量分别为4、6、5、4。给浅层中分配更多的模块,使特征中融入浅层特征中包含的细节信息。最后,F2,F3经过3*3 的卷积层,F4经过注意力模块,得到特征提取网络最终的输出,大小分别为1/4H*1/4W、1/8H*1/8W、1/16H*1/16W。
1.3 匹配代价集
在GCNet[7]等研究中,将左右特征图沿着视差搜索范围串联起来,构成D*C*H*W 的4D 匹配代价集,从而使用在代价聚合网络中使用3D 卷积,3D 卷积会使计算量增加并且增加网络中的参数。因此,为了减少网络的负担,加快网络推理速度,本文算法将左右特征图进行相关性操作,构建3D 匹配代价集,把特征提取网络提取的不同尺度特征分别进行点乘操作,形成多尺度匹配代价集CVs,s=1,2,3,用于跨尺度代价聚合。
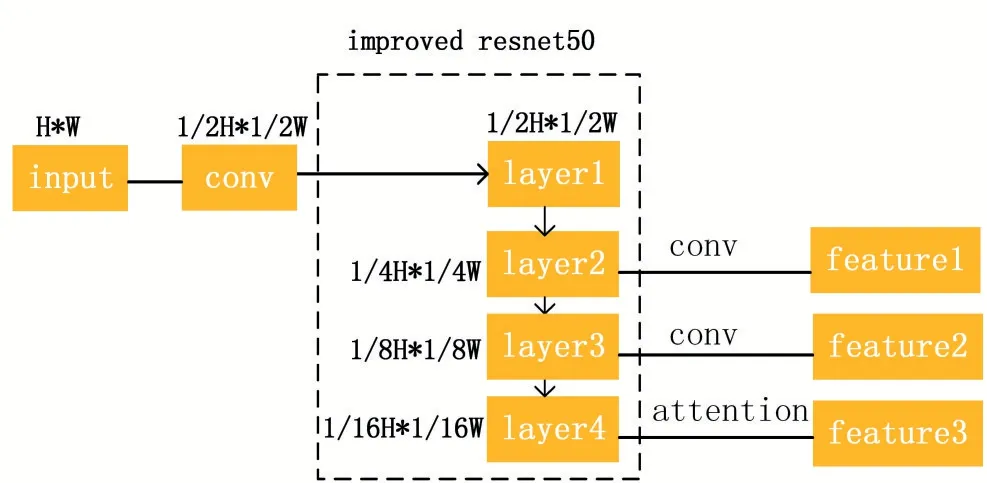
图2 特征提取网络模块
1.4 跨尺度代价聚合
在弱纹理区域,包含的信息较少,因此需要下采样,提取出具有辨识度的特征,而网络的一些细节信息,需要在高分辨率的特征中获取[16]。进行不同尺度的代价聚合,聚合后的特征当中不仅包含细节信息,还包含丰富的语境信息,有助于减少弱纹理区域的误匹配问题。在之前的研究中,许多学者在代价聚合模块使用3D 卷积,但3D 卷积计算消耗大且会降低网络推理速度,因此,本文算法使用2D 卷积进行代价聚合,减少内存消耗以及计算代价。跨尺度代价聚合模块的结构如图3 所示。
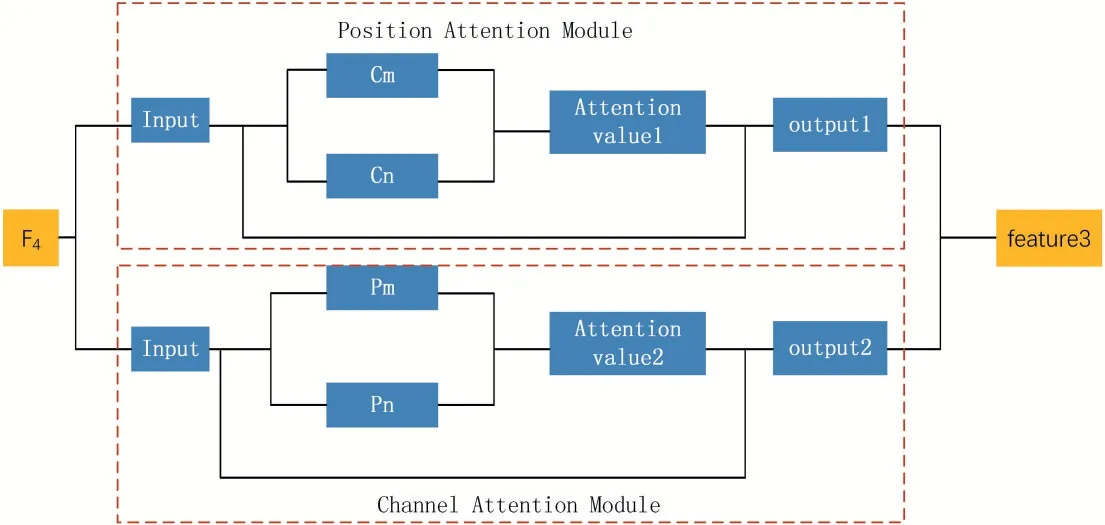
图3 跨尺度代价聚合模块
如图2 所示,首先,将大小为1/4H*1/4W、1/8H*1/8W 和1/16H*1/16W 的匹配代价集,分别进行上采样,下采样操作,再将相同尺度的特征图通过3*3 的卷积层进行特征融合,得到该模块最终输出。该模块类似于AANet[16]中提出的跨尺度模块,但有两点不同,一是不同尺度匹配代价集进行融合,采样使用的卷积操作不同,AANet[16]中使用双线性差值的方法进行采样,本文使用反卷积进行上采样,特征融合时AANet[16]中直接相加,本文算法利用卷积操作实现融合;二是匹配代价集的分辨率以及通道数不同。本文算法代价聚合网络共使用6 个跨尺度聚合模块,最终通过视差计算预测出三张视差图。
1.5 视差优化
在代价聚合网络生成了低分辨率的视差图,为了进一步提高立体匹配的精度,在代价聚合网络后增加视差优化模块,使视差实现从粗到细的优化。视差优化网络先将低分辨图像上采样到输入图像相同的分辨率,再经过残差模块将低分辨率视差图进一步地优化,使得在细节处,边缘处的匹配更加精度。在网络训练阶段,将网络输出的三张视差图加权求和进行误差计算,权重分别为0.5、0.7、1.0。测试阶段,将最大尺度的视差图上采样得到的高分辨视差图作为最终预测的视差图。
2 实验过程及结果分析
在SceneFlow[17]以及KITTI[13-14]数据集上分别对本文提出的算法进行评估,2.1 小节是对数据集的介绍,在2.2 小节中对实验的实现细节,参数设定等做详细的介绍,2.3 小节对算法在不同数据集上的实验结果进行定量分析。
2.1 数据集介绍
SceneFlow[17]数据集:大型的合成数据集,包含Monkaa、Driving 以及Flyingthings3D 三个数据集。数据集中包含双目立体图像对以及视差图ground truth。共有39824 组数据,其中35454 组为训练集,4370 组为测试集。图像分辨率为960*540,该数据集常用于网络的预训练。
KITTI[13-14]数据集:是在真实场景中生成的数据集,包含车辆、街景、路灯、路标以及树木等物体,共有KITTI2012[13]以及KITTI2015[14]两个数据集。KITTI2015[14]中包含200 组训练数据以及200 组测试数据,KITTI2012[13]中包含194 组训练数据以及195 组测试数据。KITTI[13-14]数据集训练集中包含双目立体图像对以及视差图ground truth(由Lidar 生成),测试集当中仅包含双目立体图像对,图像分辨率均为1242*375。
在SceneFlow[17]数据集上,使用EPE(预测的视差与视差真值差的绝对值的平均值)评估误差。KITTI[13-14]数据集上,3 像素(预测视差与视差真值间误差大于3像素的点占总像素数的比例)误差为评估标准。
2.2 实验细节介绍
本文实验是在Ubuntu 18.0 进行,用PyTorch 框架搭建跨尺度代价聚合网络(CSSN)。在训练过程中,使用Adam[18]优化器,参数设置为β1=0.9、β2=0.999。训练网络使用两张NVIDIA 1080Ti。
网络预训练阶段使用SceneFlow[17]数据集,共训练64 个epoch,前32 个epoch 学习率设置为0.001,后32个epoch 学习率设置为0.0001。网络输入大小为960*540 的双目图像对,经过网络预测出一张同样大小的视差图。KITTI[13-14]数据集在SceneFlow[17]数据集预训练的模型上进行微调,在KITTI2015[14]上训练1000 个epoch,前600 个epoch 的学习率设置为0.001,每隔200个epoch,学习率减半。KITTI2015[14]共200 组数据,160组作为训练集,剩下40 组作为测试集。KITTI2012[13]中包含194 组数据,其中160 组作为训练集,34 组作为测试集。
2.3 实验结果分析
本文算法在KITTI[13-14]数据集上进行评估,与之前一些性能较好算法相比有一定的优势,如MCCNN[6]、Displets V2[19]、DRR[20]、SGM-NET[21]和PBCP[22]等,在速度上较有优势,可将其用于实时系统中。
KITTI2015[14]上的评估结果如表1 所示,all area 表示整个图像的范围,Noninclude area 表示图像去掉遮挡区域的范围,最右边的一列表示的是预测出一张视差图所需的时间。D1-bg、D1-fg、D1-all 分别表示图像的前景、背景以及整个区域。
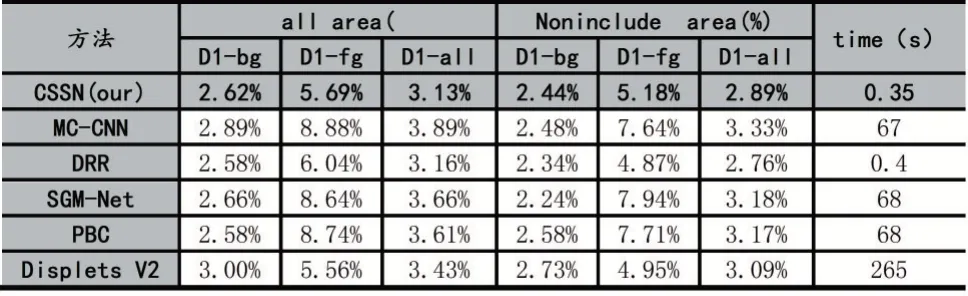
表1 KITTI2015 评估结果
从表1 当中,可以看出本文算法在整个图像区域的误差较小,整体的匹配精度较高。与Displets V2[19]相比,匹配误差减小了9%,与MCCNN[6]相比,误差减少了24%。在时间性能上,本文算法生成一张视差图仅需要350ms,比DRR 算法速度快约14%,且速度比MCCNN[6]算法快约190 倍。但在图像的前景区域,由于包含有的树木、路标等物体,在路标细节处易发生误匹配的问题。
本文算法在KITTI2012[13]上的评估结果如表2 所示,Out-Noc 表示的是非遮挡区域,Out-All 表示整个图像区域,Avg-Noc 表示非遮挡区域的平均误差,Avg-Noc 展示整个图像区域的平均误差,最后一列是算法的运行时间。表2 中展示的是3 像素位置、非遮挡区域和整个图像区域上的误差,并与目前已有一些算法如Displets V2[19]、SGM-NET[21]、PBCP[22],以及SsSMnet[23]等优秀算法的实验结果对比。
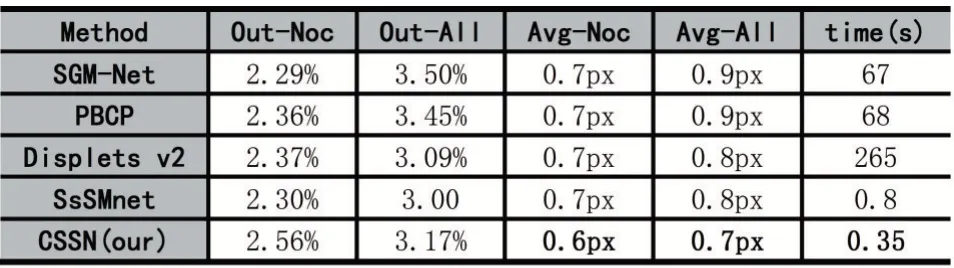
表2 KITTI2012 评估结果
从表2 中可以看出,本文算法在一些指标如非遮挡/整个图像区域上的平均误差、算法运行时间上有一定的优势,在非遮挡区域的平均误差,本文算法的精度比Displets V2[19]精度提升了16.7%,整个图像区域上精度提升12.5%。同时,算法运行速度缩小至SsSMnet[23]的46.5%,运行速度大大减少,可以将本文算法用于实时系统当中。
3 结语
本文提出了跨尺度代价聚合网络,使用笔者之前研究中的注意力机制模块,分别从通道和空间维度捕获信息,获取上下文语境信息,在代价聚合网络中,将多尺度的匹配代价集进行聚合,得到不同尺度的视差图通过融合采样得到最终网络输出。本文算法在速度上和精度上均实现较好的性能,提高了弱纹理区域的匹配精度。但在遮挡区域以及前景区域等存在误匹配问题,未来的研究重点将提升遮挡区域的匹配上。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
语文世界(初中版)(2018年10期)2018-11-06
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
