
基于中智数及ε-支配的加工时间不确定IPPS问题多目标优化研究
2021-05-13 07:59金亮亮张超勇GEORGEGERSHOMCHRISTOPHER文笑雨
绍兴文理学院学报(自然科学版) 2021年2期
金亮亮 张超勇 GEORGE GERSHOM CHRISTOPHER 文笑雨
(1.绍兴文理学院 机电学院,浙江 绍兴 312000;2.华中科技大学 机械科学与工程学院,湖北 武汉 430074;3.绍兴文理学院 土木工程学院,浙江 绍兴 312000;4.郑州轻工业大学 河南省机械装备智能制造重点实验室,河南 郑州 450002)
0 引言
集成式工艺规划与车间调度(IPPS)问题是在柔性作业车间调度问题[1,2]的基础上引入序列柔性、加工柔性得到的;通过整合工艺规划及车间调度消除资源冲突、提高设备利用率[3-7],因此,更适合于多周期、小批量、个性化的生产制造模式.
IPPS问题的本质在于工艺规划和车间调度模块的有机融合.目前,IPPS问题中两大模块常见的融合方法可分为两类:(1)顺序融合模式:先生成若干备选工艺规划,在车间调度环节中根据优化目标选取最合理的工艺规划[8],但由于此模式常常无法生成全部可行的工艺规划,导致仅能得到局部最优解,同时该模式忽略了工艺规划和车间调度内在的联系;(2)集成融合模式:将工艺规划和车间调度混为一体进行建模及优化,避免了顺序融合模式中的缺陷,真正实现了集成优化.
IPPS问题的优化方法大致可分为三类:(1)元启发式方法:由于IPPS属于NP-Hard问题,因此这类方法应用较为广泛,从单目标到多目标,从静态到动态,从确定到不确定问题等都有涉及.韩国全南国立大学Kim等人使用共生进化算法求解了基于网络图的IPPS实例,Kim等人提出的测试实例也成为经典的实例[9].华中科技大学李新宇和高亮等针对Kim实例进行了相关的研究并取得了一系列成果[7-8];Lian等人基于Kim实例的特点,提出了基于网络图中OR节点的编码方式,使用新颖的殖民竞争算法对Kim实例进行了优化[10].巴黎等人研究了基于工件批量柔性划分的IPPS问题,提出了新的编码方法并使用粒子群算法进行了求解[6];Lv和Qiao提出了新的个体初始化方法及相应的遗传操作,使用混合遗传算法优化了IPPS实例并获得了较好的结果[11].近年来Zhang和Wong针对IPPS实例提出了对象编码方法,在求解Kim实例时取得了较好的效果,改进了许多已有的结果[12].文献[13]提出了一种基于变邻域搜索的文化基因算法,对于Kim的实例进行测试,得到了许多实例的最优解.此外,也有学者使用元启发式算法求解了多目标IPPS问题.例如Li等人受博弈论中的纳什平衡启发,用纳什平衡处理各个优化目标间的关系,并提出了一种混合算法求解多目标IPPS问题[14].文献[15]针对最大完工时间、机床最大负荷、机床总负荷三个指标使用多目标文化基因算法进行优化.(2)基于Agent的优化方法.这类方法优化后的结果与使用元启发式算法得到的结果有一定的差距;Wong等使用基于Agent的谈判方法求解IPPS问题并提出了工件Agent和机器Agent间的谈判协议[16].(3)其他方法:例如基于启发式规则的方法[17]及数学规划方法,前者常常无法得到较优的结果,后者无法在合理的时间内得到最优解.文献[3]建立了一个IPPS问题的集成融合模型,并进行了求解.
目前,IPPS问题的研究已取得了相应的进展和研究成果,但实际生产制造过程中某一工序的加工时间常常不固定,前续工序加工时间波动必将影响后续工序的加工,从而影响整个调度方案的实施,这是现有IPPS问题研究的一大挑战.因此,研究加工时间不确定的IPPS问题有现实的意义.相对于确定的IPPS问题,加工时间不确定的IPPS问题的研究尚未成熟.常见的优化方法诸如机会约束规划方法[18]无法应用于大规模优化问题.基于模糊理论的优化方法是一种较好的优化方法.Wang等人通过用模糊数表征不确定加工时间,提出了一种基于模糊数的人工蜂群算法求解柔性作业车间调度问题[19];雷德明将不确定加工时间映射为三角模糊数,在遗传算法框架下优化了最大完工时间[20].最近,Jamrus等人将加工时间用三角模糊数模拟,使用粒子群算法对柔性车间调度问题进行优化[21].笔者前期在这方面做了相关的研究[22],特别是在中智数建模的基础上使用线性加权的方法优化了IPPS实例,但这类方法无法给出最优Pareto前沿,且现有方法在表达决策者偏好方面存在一定不足.
综上,基于模糊数的方法大多将加工时间假设为三角模糊数,但现实中常常无法准确估计加工时间服从何种分布或某种规律,通常仅知晓大致的波动范围,这为传统基于模糊数优化方法的使用带来了困难.相反,使用中智数描述一个不确定量只需要知道极大和极小值即可,而不必求得具体的分布或规律,这为刻画不确定加工时间带来了方便.基于中智数的优点,本文使用中智数对不确定加工时间进行模拟并研究相应的优化方法.此外,决策者常常仅对目标空间某部分的非支配解感兴趣而非全部非支配解,然而现有文献中提出的方法大多无法利用偏好信息引导Pareto前沿趋向于决策者感兴趣的区域.因此,本文利用中智数刻画不确定加工时间,提出基于偏好的ε-支配优化算法求解多目标不确定IPPS问题,并对名义最大完工时间及鲁棒性两个指标进行优化.
1 基本概念与问题描述
1.1 中智数及其运算
中智数最早由Smarandache教授提出[23],可表示为N=a+bI,其中a和b为两个实数,I为不确定区间,满足I2=I,0·I=0.例如:N=2.2+0.3I其中I=[-0.1,0.5]等价于N=[2.17,2.35],也可表示为N=2.17+0.18I,I=[0,1].通过调整参数a和b可将两中智数的不确定部分调整为同一个I.中智数的加减法运算可表示为N1±N2=a1±a2+(b1±b2)I.对两个中智数Ni=ai+biI,Nj=aj+bjI,I=[β-,β+],则Ni≥Nj的概率可表示为[24]:
(1)
对于n个中智数,两两之间通过式(1)计算后可得到概率矩阵P=(Pij)n×n,根据(2)式计算每个中智数排序顺序值ri,则最大ri值对应的中智数即为n个中智数中最大者.
(2)
中智数的“取大”算子可定义为:

1.2 问题描述与建模
IPPS问题可定义为:给定n个工件在m台机器上加工,每个工件均含有若干道工序,通过选取合理的工序、机器、加工顺序,得到最优调度方案.如图1所示,IPPS问题中可选的工序、加工资源及加工时间可用网络图进行描述[9].图中开始节点和终止节点为虚拟节点,表示一个工件加工的开始与结束.每个普通节点代表一个工序,提供了该工序的ID、备选加工设备及相应的加工时间.若某个分支旁标有“OR”,则两个分支中只需选择一个分支上的工序即可.各工序只要满足箭头所指的先后关系(直接或间接)即可.相对于传统柔性作业车间问题,IPPS问题中存在着三种柔性:工序柔性、序列柔性、加工柔性.工序柔性是指一个工序可在任意一台备选的设备上加工;序列柔性是指同样一组工序可以有若干种排列方式,只要符合网络图中的先后顺序;加工柔性是指可以选择不同的“OR”分支上的工序来完成工件加工.参考现有的IPPS问题的数学模型[15],对中智数的确定部分和不确定部分分离,可以建立基于中智数的IPPS数学模型.
首先对模型中所需的相关符号、变量等进行定义.
n:工件集合
M:机器集合
Ti:工件i的所有工艺规划集合
NOil:工件i的第j个工艺规划所有工序集合
Rijl:工序Oijl的可用机器集合

A:一个很大的正整数
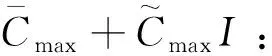

Xil:=1,若工件i的第l个工艺规划选中;=0,否则
Zijkl:=1,若工序Oijl在机器k上加工;=0,否则
Yijli′j′l′:=1,若工序Oijl直接或间接地在工序Oi′j′l′之后加工;=0,否则
优化目标:
(3)
(4)
约束方程:
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)

1.3 ε-支配与多目标优化
多目标优化算法中,常得到一组折中解(非支配解),而不是全局最优解,以便决策者从中选取较为合理的方案.具有代表性的算法为Deb等人提出的NSGA-II多目标遗传算法[25].然而,现有多目标进化算法常将算法得到的非支配解全部呈现于决策者,而无法在进化中融入决策者的偏好信息,因此可以在算法中融入偏好信息,引导算法的搜索过程集中于感兴趣的区域.本文通过目标空间中的一控制点引入偏好信息,将目标空间划分为偏好区域和非偏好区域,提出基于偏好及中智数的ε-支配多目标进化算法.
定义1:设p和q为群体中任意两个个体,则当fi(p)≤fi(q),∀i且fj(p) 定义2:若一个个体p没有被当前所有个体支配,称p为非支配解;群体中所有非支配解构成Pareto前沿. 在ε-支配中先将目标空间划分为若干尺度为εj的格子,通过格子间的支配关系决定个体间的支配关系.通过控制格子的尺度进而控制非支配解的分布. IPPS问题为NP-Hard问题,整数线性规划难以对其求解.本研究由于引入了中智数,导致模型更加复杂,求解更加困难.故本文提出一种ε-支配多目标遗传算法.以下介绍算法的编码、选择交叉等操作并给出该算法的流程图. 如图2所示,一个个体中包含调度串、工艺规划串、工序串.调度串采用基于工序的编码方法,数字i第j次出现对应工序为工件i工序串中第j个位置的工序,调度串中含有的格子数恰好为实际一个调度问题中最大可能的工序数.工件i的序号在调度串中正好出现|NOil|次,当各工件实际工序数之和小于各工件最大可能的工序数之和,则在调度串多余位置用数字0补足.图2a)中各工件分别有3,2,4个工序,因此,无须在调度串中补零.工序串反映了工艺规划的信息,每一个格子代表一个工序,括号内分别是工序ID及对应的机床.例如,图2a)中第一个工件三个工序加工顺序为3,1,2且分别在机床2,1,4上加工.工艺规划串仅含一位数字,代表该工件所选择的工艺规划(工序组合)代号.对于图1中的工件,根据“OR”节点,分为两个工艺规划(工序组合):工序1-11、14和工序1-8、12-14. 图2 编码方案与遗传操作 传统调度问题采用主动调度方法进行解码并生成甘特图,相对于半主动调度,基于主动调度的解码方法能够生成更优的调度方案.但本研究中工序加工时长和最大完工时间均为中智数,无法直接使用现有的解码方法.改进的解码方法主要步骤如下: (N3为机床k上空余时间段结束时间)时可将当前工序安排到机器上当前空余时间段. (3)若无法在空余的时间段内插入工序,只能将工序安排到相应机床的当前末尾的位置,工序开工时间为: (4)按照个体调度串中的序号,重复上述步骤,逐个处理完所有工序. 考虑到非支配解的数量多少以及个体进化的快慢,本文提出的算法部分参考了NSGA-II算法及现有的ε-支配多目标算法,算法包括的遗传操作主要有交叉和变异操作.图2b)为交叉操作的过程,选取两个父代个体P1、P2中被选中的工序串与工艺规划串并复制一份分别放到两个子代个体O2、O1对应位置;将P1(P2)中未选中工件的工艺规划串和工序串复制一份到O1(O2)相应位置.由于同一工件不同工艺规划包含不同数目的工序,需要调整两个个体的调度串.将个体P1(P2)调度串中未被选中个体的ID按照原位置填入O1(O2)调度串对应位置中,将个体P2(P1)调度串中被选中个体的ID依次填入O1(O2)调度串对应空位中.所有工件的工序均填入调度串后空缺位置用数字0填充.图2b)中由于P1、P2中第三个工件分别有3、4个工序,交换后个体O2的调度串中需要补充一个数字0.此外,为充分利用IPPS网络图中序列柔性,如图2c)所示,设计了工艺规划间的单点交叉操作. 变异操作包含三种:随机交换调度串中两个任意位置的数字;为某工序随机选取不同的机床;为某工件重新生成一新的工艺规划.算法运行变异操作时在三种变异中随机选取一种. 对于决策者给定的点P(坐标为(Pf1,Pf2)),最小化问题中偏好区域即为坐标原点与点P围成的矩形,如图3所示.除偏好区域外的其余目标空间为非偏好区.将两部分区域划分不同尺度的网格,ε-支配即为网格间的支配.显然,偏好区网格较非偏好区更密,这表明偏好区域能够容纳更多的非支配解,而在非偏好区由于网格尺度较粗,仅能容纳少量的非支配解,这样引导算法的非支配解更多地分布于偏好区. 图3 ε-支配示意 随机产生初始个体后,构造普通Pareto支配的非支配解集合:将初始个体利用NSGA-II类似算法得到非支配个体(此时可能有不止一个个体处于同一格子中),按照第一个指标f1的数值由小到大排列各个非支配解,依次将排列后的非支配解按上述定义3的方法放入指定的格子中,从第二个非支配解开始,判断若当前处理的个体与前一个个体均处于偏好区或非偏好区则进一步按以下处理: 1)若当前个体C(如图3)在已有个体A下方,则删除个体C上方所有个体; 2)若当前个体B(如图3)在已有个体B右方,则删除当前个体B; 3)若当前个体E(如图3)和已有个体D在同一格,则只保留距离该格子左下角顶点欧氏距离最短的点(图中为E点). 否则接受当前个体. 这样,处理完所有非支配解后得到了初始归档集.初始归档集中的个体相互间均不构成ε-支配关系.之后算法按照选择、交叉、变异进行优化,但传统ε-支配多目标优化算法中每次仅进行单个个体间的交叉操作,效率与优化效果较差.此外,为提高偏好区域中的个体被选入下一代的概率,对选择操作进行了改进,具体如下: 1)任取两个个体若均在非偏好区,则去掉非支配的个体,保留另一个个体; 2)若两个个体均在偏好区,则同时接受这两个个体; 3)若两个个体所属区域不同,确保处于偏好区的个体被选中,若另一个体支配处于偏好区的个体,则也被选中进入下一代; 4)重复以上步骤直到所选个体数目达到规定要求. 为改善个体多样性,选择操作中允许一小部分新生成的个体代替老的个体.算法每一轮进化后允许15%的新生成个体代替老的个体. 归档集更新主要考虑用当前群体中的非支配解更新原归档集中的ε-非支配解.因此,先将当前群体中非支配解和归档集中的个体合并,并按照第一个指标f1的数值由小到大排列各个体,参考初始归档集生成方法,得到当前更新后的归档集.需要注意的是:若前后两个个体均处于(非)偏好区,按ε-支配关系决定是否保留个体,若前后两个个体处于不同区域的直接按普通的Pareto支配关系决定是否保留个体. 本文使用中智数来模拟现实中不确定的加工时长及完工时间,定义了两种不同的工序加工时长波动范围:1)小范围波动:工序加工时长最大波动量为其名义值的±5%;2)较大范围波动:工序加工时长最大波动量为其名义值的±15%.算法主要流程如图4所示. 图4 算法流程 本文主要考虑两个优化指标:名义最大完工时间指标及鲁棒性指标.由于实际的最大完工时间是一个中智数,完工时间存在围绕名义值上下波动的情况,故本文中鲁棒性指标定义为最大完工时间上下波动的最大偏差.显然,完工时间波动的偏差越小则鲁棒性越好. 计算实例来自Kim等人提出的一组实例[9],共有24个实例.工序加工时长精确到小数点后三位.名义最大完工时间和鲁棒性指标分别对应目标空间中的横、纵坐标.在偏好区,横、纵坐标的偏差εj分别为0.005和0.004;在非偏好区,横、纵坐标的偏差分别为0.05和0.04.个体总数设置为800个,迭代次数800次,交叉和变异概率分别为0.7和0.08.所有计算在一台装有I5-9600(3.7GHz)CPU及16GB内存的计算机上进行. 首先求解Kim实例中最复杂的第24个实例,该实例中含有18个工件,在15台机床上加工.比较在工序加工时长处于较小波动范围时得到的非支配解;图5为相应的Pareto前沿,本例中偏好区域为0≤f1≤650及0≤f2≤20围成的矩形区域.由图可知,初始非支配解经过不断进化形成了最终的Pareto前沿,并且大多数ε-非支配解集中于偏好区域(图中方框内区域为偏好区域).此外,非偏好区域内的非支配解只有一个,这说明提出的ε-非支配多目标算法确实能够根据决策者偏好获得较多的非支配解.图6为相同条件下,偏好区域为0≤f1≤550,0≤f2≤35时的非支配解分布.显然,对于不同的偏好区域,ε-非支配解分布的区域不同且随偏好区域改变而改变.本例中ε-非支配解仍然集中于偏好区且只有两个非支配解处于偏好区之外,因此,这表明提出的算法确实能够使非支配解尽可能集中于偏好区. 图7为当加工时长在较大范围波动下第24个实例的Pareto前沿.对比前几个图可以发现当加工时间的波动范围增加时,得到的最大工期波动范围也随着增加,但对名义最大工期影响不是很大.此外,大多数非支配解均分布于给定的偏好区域(0≤f1≤600,0≤f2≤45). 图5第24个实例小波动范围非支配解分布 图6 第24个实例小波动范围非支配解分布(不同偏好区域) 图7第24个实例较大波动范围非支配解分布 图8为图7中偏好区域内某非支配解对应的甘特图(名义加工时间).图9为第12个实例优化前后的非支配解分布(加工时间较大范围波动下),优化后非支配解数量增加且主要分布于偏好区内. 选取Kim实例中第1、12、24三个实例(此三个实例分别代表典型的小、中、大规模实例),得到每个实例5次计算时长的平均值并将该平均值与Kim实例相应实例的计算时长进行比较,相关结果列于表1中. 图8 第24个实例的甘特图 图9第12个实例的非支配解分布 表1 计算时长对比 由表1可知,求解大规模实例时,本文提出的算法所需计算时间较短.说明本文算法在求解这类实例时具有较高的效率,能快速找到合理的非支配解.同时,对于中小规模的实例,文献[9]的算法计算较快,这是由于本文使用了中智数模拟不确定加工时间,在解码等过程中中智数的运算增加了计算量.此外,为得到偏好区与非偏好区内的非支配解,特别是保留并增加偏好区中的非支配解,本文提出了较为复杂的非支配排序方法,这也使得计算过程变得相对复杂,因此增加了计算时间. 工序加工时间的不确定性给调度的鲁棒性带来了挑战,鉴于中智数在描述不确定信息方面具有优势,本文将其引入集成式工艺规划与调度问题的优化中,建立了基于中智数的数学模型,提出了基于ε-支配的多目标优化算法.通过控制网格尺度及参考点的设定控制非支配解的分布.算法对名义最大完工时间及鲁棒性两个指标进行了优化,计算结果证明了算法的有效性,大多数非支配解集中于偏好区域.
2 算法设计
2.1 编码方案

2.2 解码方法


2.3 遗传操作
2.4 选择操作与算法流程


3 计算实例及分析
3.1 参数设置
3.2 计算结果与分析






4 结语
猜你喜欢
山东冶金(2022年3期)2022-07-19
昆钢科技(2022年2期)2022-07-08
意林(2021年9期)2021-05-28
石材(2020年4期)2020-05-25
建材发展导向(2019年10期)2019-08-24
时代英语·高一(2019年1期)2019-03-13
自动化学报(2017年2期)2017-04-04
Coco薇(2016年8期)2016-10-09
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
