
自由选择字段的MARC数据提取工具开发实践
2021-05-15 06:48刘娉婷
图书馆学刊 2021年4期
刘娉婷
(国家图书馆,北京10081)
MARC(Machine-Readable Cataloging)是机器可读目录的简称,指利用计算机识读和处理的目录。它是文献编目内容经过计算机处理,以代码形式记载在一定载体上而形成的一种目录。MARC数据是描述文献著录项目的国际标准格式,是实现计算机处理书目信息及资源共享的基础[1]。MARC数据最早产生于美国,作为一种计算机技术发展早期形成的数据格式,这一格式在定义时比较充分地照顾到图书馆书目数据在文献形式描述、内容描述、检索等方面的需要,具有字段数量多、著录详尽、可检索字段多、定长与不定长字段结合、保留主要款目及传统编目的特点、扩充修改功能强等特点[2]。在文献数字化建设的过程中,MARC数据是数字化项目中的一项重要元数据,但MARC数据中的字段信息无法被直接使用,需要提取字段以及子字段信息,保存在可读取的数据库中。在对MARC数据的数据格式进行深入分析后,笔者开发出可以自由选择字段的MARC数据提取工具,该工具对MARC数据提取的字段信息没有限制,可以进行批量提取,笔者详细介绍了该工具的实现原理和开发实践,希望能为大家提供一定的借鉴。
1 MARC数据格式[3]
提取MARC数据的前提是理解MARC数据的格式结构,下面详细地说明一下MARC数据的格式。
1.1 总体结构
MARC数据格式是GB/T 2901(ISO 2709)的一个特定形式,规定了每一个用于交换的书目记录必须遵循的标准记录结构。MARC数据由4部分组成:记录头标、地址目次区、数据字段区和记录结束符。MARC数据的记录结构如下图1所示:

图1 MARC数据的记录结构
1.2 记录头标
根据GB/T 2901(ISO 2709)规定,记录头标位于MARC数据的开头,由24位字符组成,包含了处理MARC数据所需的数据元素,是必备的并且不能重复。记录头标中的数据元素是由字符位置标识的,字符位置起始于0,记录头标的字符位置为0到23,数据元素具体如表1所示。

表1 记录头标数据元素
1.3 地址目次区
地址目次区位于记录头标之后,含有一个或多个目次项,每个目次项描述一个字段,一个目次项包含3部分:字段标识符、字段长度和字段起始字符位置,其中字段标识符由3位数字表示,字段长度由4位数字表示,字段起始字符位置由5位数字表示,即一个目次项有12位,不允许出现其他字符。在地址目次区之后有一个字段分隔符。地址目次区的结构如图2所示。

图2 地址目次区的结构
每个目次项中的字段长度是该字段全部字符数的总和,包括指示符、子字段标识符、行文或代码数据以及字段分隔符;字段起始字符位置是该字段第一个字符在数据字段区中的位置,第一个数据字段的第一个字符的位置为0。MARC数据中的数据字段的位置完全由地址目次区决定,每个数据字段都对应地址目次区中的一个目次项。
1.4 数据字段区
数据字段区位于地址目次区之后,由若干定长和变长字段组成,每个字段之间用字段分隔符隔开。定长字段的结构图3所示。

图3 定长字段结构
变长字段的结构如图4所示:

图4 变长字段结构
001和005字段仅由数据和字段分隔符组成,其他字段由两个字段指示符、一个或多个子字段以及字段分隔符组成,每个子字段的开头是子字段标识符,由1位子字段分隔符和1位子字段代码组成,子字段代码一般为英文字母或数字,子字段标识符之后是代码数据或正文数据。MARC数据中的字段和子字段原则上是可以重复的。这里要注意的是,字段标识符保存在地址目次区,在数据字段区是不存在的。
1.5 记录分隔符
MARC数据中存在着一些特殊字符,用于分隔和控制MARC数据的格式,以便机器正确的识读和处理MARC数据,MARC数据中的特殊字符主要有下面几种:
(1)字符集中的IS1,即子字段分隔符,用作子字段标识符的第一位字符,标志着子字段的开始,在双八位编码表中用001F表示,在格式文本中用$表示。
(2)字符集中的IS2,用作地址目次区的结尾和数据字段的分隔符,以隔开相邻的数据字段,在双八位编码表中用001E表示,在格式文本中用*表示。
(3)字符集中的IS3,即记录结束符,置于每条记录的结尾以表示该记录结束,在双八位编码表中用001D表示,在格式文本中用%表示。
图5是一条MARC数据,这里将不能显示的特殊字符用可显示的字符替代,其中IS1用$表示,IS2用*表示,IS3用%表示。
2 MARC数据提取
2.1 MARC数据提取工具开发意义
MARC数据作为一项重要的元数据,在文献数字化建设的过程中是必不可少的。从MARC数据的格式来看,字段和子字段的信息并不能够直接使用,当数据量比较大时,手工录入并不现实,需要进行提取保存到可读取的数据库中。不同载体类型的数字化项目需要提取的MARC数据的字段信息是有差异的,同时要考虑到字段或子字段重复的情况,笔者没有发现合适的工具来满足MARC数据的提取需求,一般是自己开发提取工具,笔者针对中文图书、民国报纸、民国期刊、音视频等不同的载体类型开发了多个工具。这些工具只能提取固定字段的信息,灵活性差,当提取字段有变更时需要更新工具,不具备通用性,于是笔者萌生了开发一款可以自由选择字段的MARC数据提取工具的想法,并最终完成了该工具的程序实现。
2.2 MARC数据提取原理
以图5中的MARC数据为例,详细地介绍MARC数据提取原理,具体提取流程如下:
(1)读取MARC数据,每次读取一行,假设现在读取到的是图5中的MARC数据。

图5 MARC数据
(2)计算地址目次区中目次项的数量。该MARC数据的起始24个字符为记录头标,即“00911nam0 2200265 450”,记录头标的第12-16位为数据基地址,也就是数据字段区的起始位置,这里是“00265”,即在该条MARC数据中数据字段区起始于第265个字符。数据基地址减去记录头标的24个字符和地址目次区结尾的1个字段分隔符,就得到了地址目次区的总长度,这里是240。每个目次项的长度为12,用地址目次区的总长度除以12就得到了地址目次区中目次项的数量,这里是20。
(3)获取地址目次区中所有目次项的字段标识符,按照顺序存储在数组中。每个目次项的前三位数字为字段标识符。图1中的MARC数据的地址目次区如图6所示,每一行是一个目次项,有标记的前三位数字为字段标识符。

图6 地址目次区
(4)获取数据字段区的每一个数据字段,按照顺序存储在数组中。这里要用到字段分隔符IS2,使用字段分隔符IS2将MARC数据进行分割,去掉记录开头的记录头标加地址目次区和记录最后的记录结束符,将得到全部的数据字段内容。图5中的MARC数据的数据字段区如图7所示,每一行是一个数据字段。目次区中目次项的顺序和数据字段区中字段内容的顺序是一致的,所以字段标识符数组和数据字段数组中的内容是一一对应的,至此就获得了MARC数据中全部的字段信息。

图7 数据字段区
(5)按照需求提取字段内容。将需要提取的字段标识符和子字段标识符存储在一个数组中,依次在第(3)、(4)两步获取的数组中进行查找,即可得到对应的字段内容。提取字段内容时需要用到子字段分隔符IS1,利用IS1将数据字段进行分解,通过子字段标识符定位到对应的子字段内容。这里要注意001和005字段是没有子字段分隔符的。在图6中,第一行是001字段,第二行是005字段,第三行是010字段,取001和005字段的内容,直接读取图3中的第一行和第二行的内容,取010$a字段,需要将图7中第三行的内容进行分解,以获取到“978-7-5013-5978-3”。
(6)将字段内容存储在Microsoft Office Excel文件中,每一个子字段的内容存储为一列。选择Microsoft Office Excel进行存储是因为其具有灵活性,列数可以动态调整,符合自由选择字段的需求,也可以方便的转换为Microsoft Office Access等其他数据格式。
3 MARC数据提取开发实践
3.1 开发环境
程序开发的硬件环境为普通PC机,操作系统是Windows 7,开发平台是Microsoft Visual Studio 2010,目标框架使用的是.NET Framework 2.0,使用的编程语言是C#,PC机上必须安装Microsoft Office Excel 2007和Microsoft Office Word 2007或更高版本。
3.2 程序功能
自由选择字段的MARC数据提取工具的界面如图8所示。该工具有两个主要功能:MARC数据提取和说明文档展示,这里主要介绍MARC数据提取的功能。

图8 程序界面
MARC数据提取中主要包括字段间隔字符选择、字段选择、MARC数据查看和MARC数据提取4个功能,下面详细地介绍一下这些功能:
(1)字段间隔字符选择,间隔字符分为重复字段间隔字符和重复子字段间隔字符。在MARC数据中存在着字段重复和子字段重复的现象,该工具会将重复的字段和子字段全部提取,存储在一个Excel单元格中,这就需要设置间隔字符将各个字段和子字段间隔开来,以免造成阅读困难。笔者将重复字段的间隔字符默认设置为“;”,重复子字段的间隔字符默认设置为“,”,用户也可以根据需求设置间隔字符,如果没有设置间隔字符则使用默认的设置。
(2)字段选择,包括添加字段、删除字段、清空字段列表、导入字段和导出字段的功能。
点击“添加”按钮,弹出添加字段对话框,按提取需求填写字段名称和子字段名称,如图9所示。这里需要注意三点:①子字段代码只需要填写英文字母或数字,不需要填写子字段分隔符;②子字段代码的英文字母大小写需要与MARC数据保持一致;③001和005字段不需要填写子字段代码。字段标识符和子字段代码填写完成后,点击“确定”按钮,字段将显示在“已选字段”列表中,如图10所示,用户需要依次将提取的字段添加。
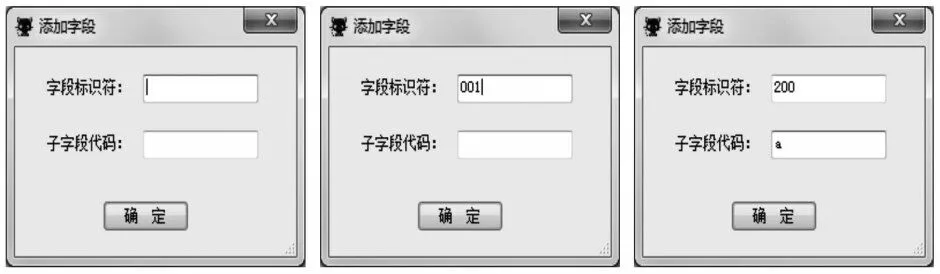
图9 添加字段

图10 已选字段
单击“已选字段”列表中的某一行,点击“删除”按钮,可以将该字段删除,也可以双击该行进行删除操作。点击“清空列表”按钮,“已选字段”中的内容将全部清除。
用户添加完提取字段之后,为方便以后使用可以将字段列表导出。点击“导出”按钮,可以将“已选字段”列表中的内容导出为后缀为“.list”的文本文件。在下一次使用时,点击“导入”按钮,可以将该文本文件导入,不需要再一一添加字段内容。
(3)MARC数据查看。首先选择MARC数据文件的编码方式,根据文件的实际编码方式选择,否则可能会显示乱码;然后选择要查看的MARC数据文件,点击“查看”按钮,显示结果如图11所示,这里将子字段分隔符用蓝色方框代替,以方便查看。用户可以点击“上一条”“下一条”按钮来查看上一条和下一条MARC数据,也可以输入指定的数字,点击“跳转”按钮跳转到指定的MARC数据。

图11 MARC数据查看
(4)MARC数据提取。在选择MARC数据文件编码方式和MARC数据文件之后,选择要保存的Excel文件,点击“提取”按钮,会根据已选字段将MARC数据中的相应字段内容提取到Excel文件中。以提取001、200$a、200$f、210$a、210$c、210$d这5个字段为例,提取结果如图12所示。该工具界面简洁、易于操作,能够满足工作中对MARC数据提取的各种需求,已经被多人使用了多年,为工作提供了便利。

图12 MARC数据提取结果
3.3 技术要点与实现
程序开发的关键点在于Excel文件的操作和MARC数据字段内容的提取。
(1)Excel文件操作
Excel文件操作包括Excel文件的创建、写入和保存,笔者使用Office的Excel组件来操作Excel文件,先引入Excel组件,在COM组件库中找到Microsoft.Office.Interop.Excel,将其添加到引用中。Excel文件操作的关键代码如下所示:
//定义一个COM中空类型的对象
object missing=System.Reflection.Missing.Value;
//创建Excel对象
Microsoft.Office.Interop.Excel.Application app=new Microsoft.Office.Interop.Excel.Application-Class();
app.Application.Workbooks.Add(true);
//添加新工作簿
Microsoft.Office.Interop.Excel.Workbook book=(Microsoft.Office.Interop.Excel.Workbook)app.Active-Workbook;
Microsoft.Office.Interop.Excel.Worksheet sheet=(Microsoft.Office.Interop.Excel.Worksheet)book.ActiveSheet;
//设置单元格格式为文本格式
Microsoft.Office.Interop.Excel.Range myrange=sheet.get_Range(sheet.Cells[1,1],sheet.Cells[cols_line.Count+1,al_field.Count+1]);
myrange.NumberFormatLocal="@";/
/给单元格赋值
sheet.Cells[1,1]="序号";
//保存Excel文件
book.SaveCopyAs(file_xls);
//关闭工作簿
book.Close(false,missing,missing);
//退出Excel
app.Quit();
(2)MARC数据字段内容提取
首先根据记录头标计算出MARC数据中字段的个数,然后按照在MARC数据地址目次区中出现的顺序,将所有的字段标识符和数据字段内容分别存储,最后与提取字段进行匹配来提取字段内容。MARC数据字段内容提取的关键代码如下所示:
//根据记录头标计算出MARC数据中字段的个数
data_pos=int.Parse(line.Substring(12,5));
address_len=data_pos-24-1;
address_num=address_len/12;
//将字段标识符存储在al_label中

//使用字段分隔符将MARC数据分隔,数据字段内容存储在al_content中

//要提取的字段标识符存储在al_field中
//根据al_field中的字段标识符依次寻找对应的字段内容
//001、005字段和其他字段内容需要分别处理
//如果MARC数据中有相应字段,提取字段内容填入单元格中,如果没有单元格为空



4 结语
MARC数据在图书馆中应用广泛,是图书馆描述数据、存储数据、处理数据的基础。随着图书馆事业的不断发展,MARC数据始终作为元数据的标准之一,具有非常重要的作用。笔者开发的MARC数据提取工具为MARC数据的查看和提取提供了便利,在工作中的多次实践证明了推广该工具的可行性。目前该工具的功能还比较简单,未来笔者将增加字段的修改、增加、删除功能,将该工具的功能做进一步的完善,以便为工作提供更多的便利。
猜你喜欢
计算机应用(2022年8期)2022-08-24
电脑爱好者(2021年23期)2021-12-08
台湾农业探索(2020年4期)2020-10-29
汉字汉语研究(2020年2期)2020-08-13
计算机系统应用(2020年8期)2020-03-22
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
台湾农业探索(2019年5期)2019-09-10
办公室业务(2019年13期)2019-08-01
