
基于云模型与凝聚型层次聚类的失效模式与影响分析方法
2021-05-18 05:56尤建新陈雨婷宫华萍徐涛
同济大学学报(自然科学版) 2021年4期
尤建新,陈雨婷,宫华萍,徐涛
(1. 同济大学经济与管理学院;2. 同济大学外国语学院,上海200092)
失效模式与影响分析(Failure Mode and Effect Analysis,FMEA)是一种可靠性分析与风险管理中重要的理论和方法,经多年发展后现已被广泛应用于医疗、制造、航空等多个领域[1-2]。传统FMEA 方法通过计算失效模式的发生度(Occurrence,O)、严重度(Severity,S)和可检测度(Detection,D)三个风险因子的乘积得到风险优先值(Risk Priority Number,RPN),存有较多缺陷:①不同O、S 和D 值的组合可能会产生相同RPN值,但其风险影响可能完全不同,无法确定实际风险水平;②风险因子值需用精确值评估,但在实际场景中往往难以精准表述;③未考虑风险因子内部的相对重要度,实际问题中因子权重可能存在差异。目前国内外关于FMEA方法改进的研究较多,主要包括基于隶属度函数、语言符号[3]、二元语义[4]和结合多准则决策、模糊集理论等的方法,如Illangkumaran 等[5]应用模糊层次分析法建立一个群评价框架来对FMEA 方法进行改进;Braglia 等[6]提出基于模糊的逼近理想解排序的改进FMEA 方法;Liu 等[7]提出基于多准则妥协解排序的改进FMEA 方法等。近年来,将聚类技术应用于风险识别逐渐成为改进FMEA的重要方法,如Liu 等[8]提出一种基于噪声密度聚类和动态专家评价方法的改进FMEA方法;Duan等[9]基于k均值聚类和犹豫模糊语言评价改进FMEA方法等。已有研究虽然极大地促进FMEA 方法的发展,但以下方面仍有待继续深入研究:①已有风险评估信息表征方法虽在一定程度改进了语言评价的模糊性,但难以同时精准描述风险评估的模糊性和随机性;②尚未形成较为成熟的风险分类方法,而风险分类一般比排序计算更节约时间和成本;③多数聚类技术缺少考虑不同风险类别间的联系,且需事先指定聚类数。
本文基于云模型(Cloud Model)与凝聚型层次聚类算法,提出了一种改进的FMEA方法。该方法利用云模型处理具有随机模糊性语言评价的失效模式,为失效模式层次关系分析和风险等级识别提供有效途径;在线教学风险分析的应用验证新方法的有效性,分析结果为高校在线教学短板问题的改进提供决策参考。
1 基础知识
1.1 云模型
云模型是李德毅等[10-11]基于模糊理论和概率论提出的一种将自然语言描述的定性指标与定量指标相互转化的理论。正态分布的云模型(高斯云)具有通用性和稳定性[12]。设定性概念C的一次随机实现(随机云滴)为x ∈U,x对C的确定度μ(x)∈[0,1]是具有稳定倾向的随机数[13],且对于∀x ∈U,有x →μ(x) 。
云模型由三个数值特征进行定性表示,记为C(E,E熵,H熵)。其中,期望值E为最典型样本,是定性云滴组的核心;熵E熵为定性概念的不确定性度量,类似于概率论中随机变量的方差;超熵H熵为E熵的二阶熵,代表云滴的凝聚力,是熵的不确定度[14]。定量论域U是由三个数值特征产生的随机云滴,以进行精确数值的定量表示。云模型的优点在于:①允许评价语言在一定论域中服从概率分布,减少个体评价带来的不确定性;②借助云集结算子减少集结评价信息时的信息扭曲问题;③同时考虑评价决策信息的模糊性和随机性。
1.2 前向云生成器算法与云大小比较
定义1设云滴(x,y)对定量论域U 的贡献为s=xy,则该云滴所在的任何云A 可以用s 期望值ŝ作为云A对论域T的总体得分。利用正向云发生器G(E,E熵,H熵,n)产生云模型的云滴样本,对云A 的期望进行数值估计,正向云发生器G随机迭代n次得到每个云滴的大小si=xiyi(i=1,2,…,n)。其中,E熵'i~N(E熵,H熵2),xi~N(E,E熵'i2)。通过计算符合云数值特征的随机云滴贡献得分的样本均值,实现不同云之间的比较。设估计值ŝ(A)≥ŝ(B),则有A≥B,则
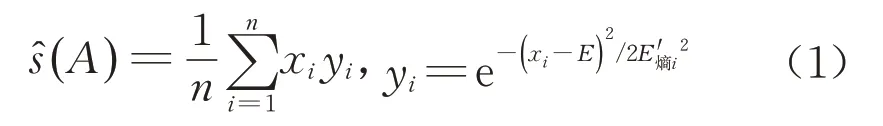
1.3 云运算算子
定 义2对 任 意 两 朵 云A(E1,E熵1,H熵1) 和B(E2,E熵2,H熵2),满足以下基本运算规则,即A+B=

1.4 评价语言映射
定义5设有限奇数粒度评价术语集H={Hi|−g,…,0,…,g,g ∈N*}是一系列正整数,满足条件:①若i>j,则Hi>Hj;②若Hi对应的评价语言为负数,则用neg(Hi)=H−i表示。设Hi有效域为[Xmin,Xmax],根据韦伯定律[16],从Hi映射到θi(i=−g,…,0,…,g)映射函数f为
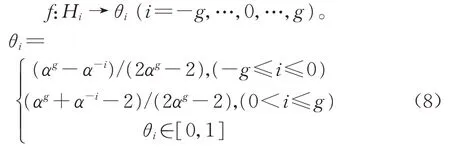
式中:α 作为经验值主要分布在[1.36,1.4]区间[17]。
定义6将区间云模型距离[18]进行简化,根据汉明距离,云y1与云y2之间的距离为

2 改进FMEA方法
本文提出的基于云模型与凝聚型层次聚类的改进FMEA 方法(见图1),主要包括3 个阶段:①失效模式风险评估,进行失效模式语言评估信息收集,获取语言评价风险评估矩阵;②云模型评价信息集结,采用云模型表示专家评价语言,集结专家风险评价信息;③失效模式关联发现与风险聚类,进行凝聚型层次聚类,计算失效模式之间的关联度,确定失效模式风险等级。
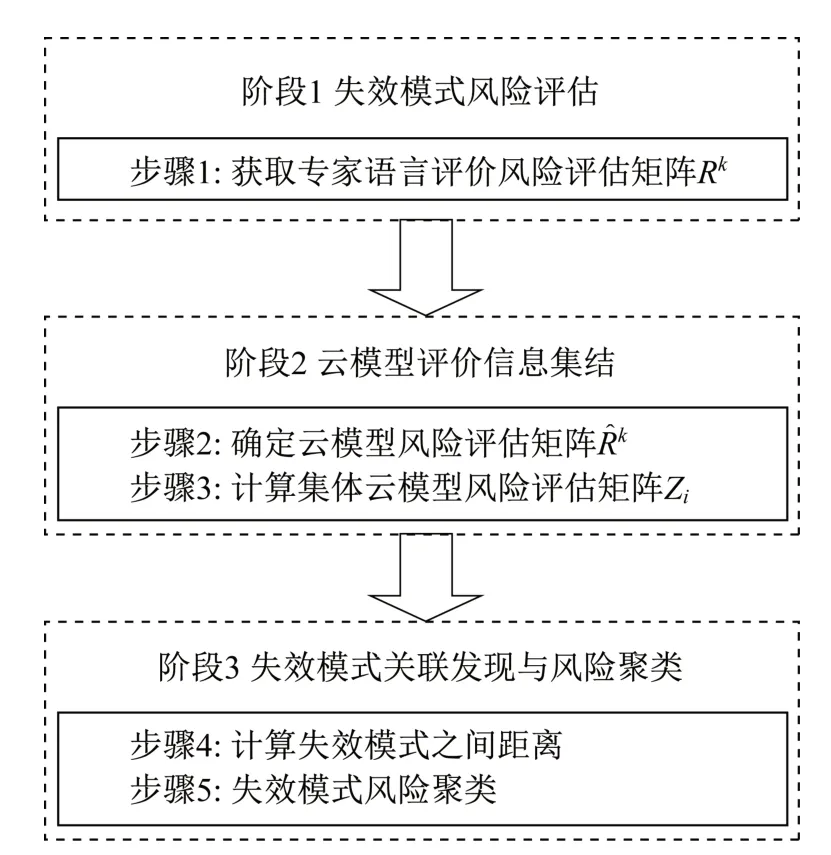
图1 改进FMEA方法框架流程图Fig.1 Flowchart of the improved FMEA method
2.1 失效模式风险评估


2.2 云模型评价信息集结
步骤2确定云模型风险评估矩阵R̂ k
将定量语言映射到云模型的“数值信息”,即期望值E 上,进一步确定云模型的定性表示Yi(Ei,E熵i,H熵i)。
根据定义5 确定映射函数f,计算评价语言映射值θi。根据θi计算均值Ei,E熵i,H熵i可得


2.3 失效模式关联发现与风险聚类
凝聚型层次聚类算法是一种易发现类层次关系和无需事先指定聚类数的经典无监督算法[19]。
步骤4计算失效模式之间距离
根据定义6 得到由集体云模型风险评估云距离表示的临近度矩阵,如计算失效模式FM1与FM2的距离:
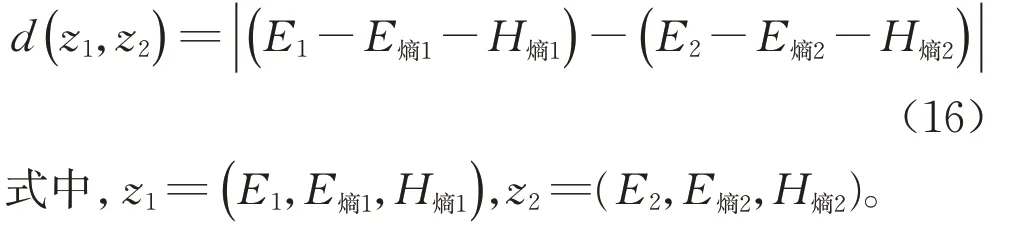
步骤5失效模式风险聚类
根据凝聚型层次聚类算法,每次合并最相邻的两个簇后更新临近度矩阵,重复这一过程,直至仅剩下一个簇时结束。最后,根据聚类结果对失效关联关系和风险等级进行进一步分析。
3 案例分析
疫情后在线教学的大规模实施,虽在一定程度上保证教学的持续性,但仍存在较多不足和问题,亟需查找短板、改进质量。基于已有研究[20-21],通过高校学生群体的问卷调查及专家访谈,确定15 项常见在线教学失效模式,失效模式表现及因果分析如下(见表1)。
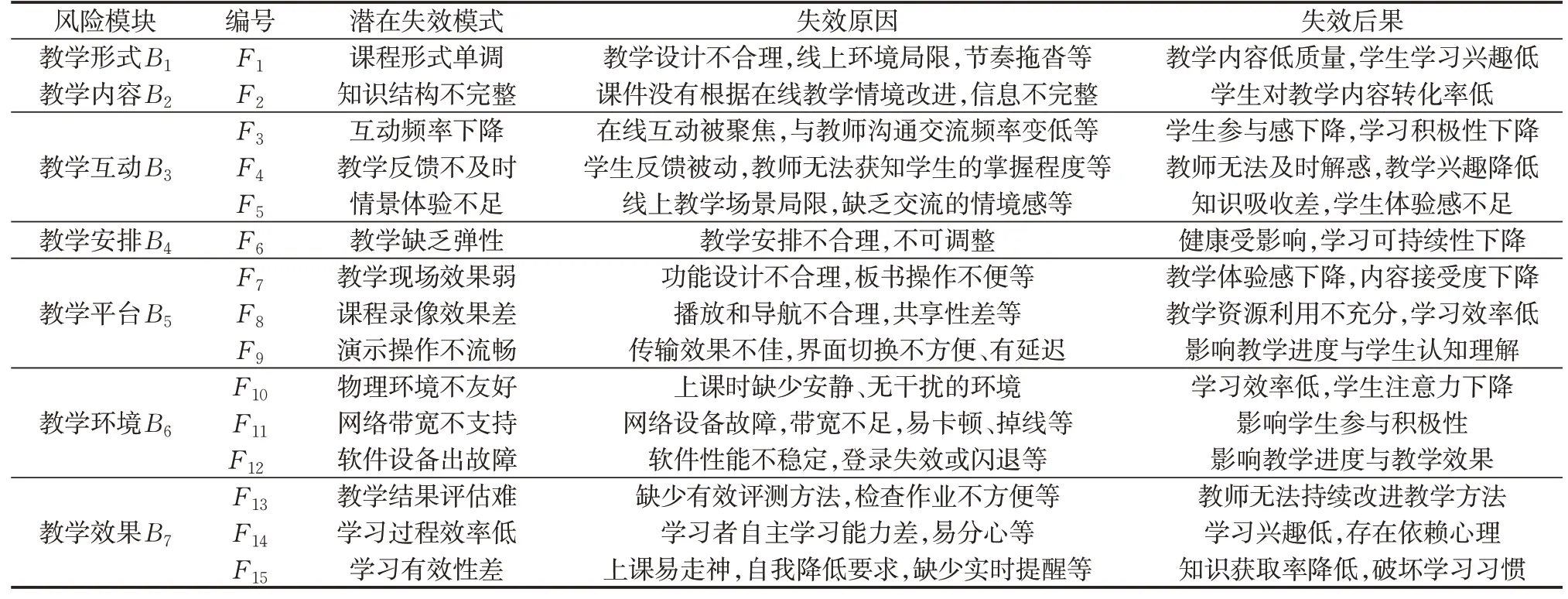
表1 在线教学常见失效模式及因果分析表Tab.1 FMEA analysis of E-learning system
3.1 失效模式风险评估
根据风险因子(O、S、D)建立七级粒度语言评价标准集H,进行失效模式风险评价。根据发生频率增加、影响程度变大、被检测到难度递增的原则,H={Hi|i=−3,−2,−1,…,+3} 依 次 为“极 低(VL)、低(L)、较低(ML)、中等(M)、较高(MH)、高(H)、极高(VH)”,如VH代表“频繁发生、影响极大、极难被检测到”。设FMEA 评价专家团由5 位成员组成,专家权重λ=(0.15,0.15,0.25,0.15,0.30),风险因子权重ω=(0.45,0.30,0.25),专家语言评价风险评估结果见表2。
3.2 失效模式云评估信息集结
首先,将语言变量转化为云模型。定量论域[Xmin,Xmax]=[0,10],根据式(8),取经验值α=1.4,分别得到七粒度语言集的θi,Ei,E熵i和H熵i的值,其中θ−3至θ+3的值依次为0,0.225,0.385,0.500,0.615,0.775和1。7个语言变量Hi按式(10)~式(13)转化为7朵评估云,得到云模型风险评估矩阵形成七朵云Yi分别为Y-(30,2.959,0.125),Y-(22.248,2.655,0.226),Y-(13.853,2.100,0.411),Y(05,1.922,0.470),Y+(16.147,2.100,0.411),Y+(27.752,2.655,0.226),Y+(310,2.959,0.129)。
其次,根据风险因子评价形成失效模式的综合评价。根据式(14)集结Fi的风险评价,得到专家k对Fi的云模型综合评价Z ik。然后根据式(2)、式(3)得到lλkZ ik(i=1,…,15;k=1,…,5,l=5)的计算结果。
最后,用正向云发生器比较lλkZ ik大小,依据式(6)、式(7)和式(15),使用级别词对中“极端”原则,设参数 (a,b)=(0.15,0.95),得到w=(0.063,0.250,0.250,0.250,0.188),最终得到Fi集体云 模 型 风 险 评 估Z i(i=1,2,…,15) 依 次 为z1(5.102,2.224,0.349),z(24.832,2.175,0.340),z3(4.912,2.358,0.331),z(45.052,2.178,0.388),z5(5.373,2.364,0.305),z(62.527,2.532,0.245),z7(4.159,2.259,0.363),z(84.143,2.311,0.327),z9(3.421,2.292,0.327),z1(03.572,2.378,0.298),z11(4.158,2.232,0.379),z1(24.223,2.314,0.325),z13(5.321,1.996,0.408),z14(5.652,2.308,0.319),z1(56.800,2.476,0.260)。

表2 专家语言评价风险评估矩阵表RkTab.2 Evaluation of failure modes Rk
3.3 失效模式关联发现与风险聚类
根据式(16)计算云的临近度,将失效模式“F1~F15”分别用数字“0~14”顺序索引进行凝聚型层次聚类,以树状图表示层次聚类结果(见图2)。图中纵坐标表示为簇间云距离,横坐标为失效模式索引,若有多个距离相近的失效模式聚类簇,则用所含失效模式的数量表示,如图2(a)中的“(5)”表示包含五个距离相近失效模式的聚类簇。聚类结果显示,“F15”、“F1,F2,F3,F4,F5,F13,F14”、“F7,F8,F11,F12”、“F9,F10”、“F6”的风险等级依次为“VH-H-M-L-VL”。
根据聚类结果可知,在线教学失效模式“知识获取率降低(F15)”的不良影响明显超出其他失效模式,是在线教学质量改进的重点。失效模式教学形式单调(F1)、知识结构不完整(F2)、互动频率下降(F3)、教学反馈不及时(F4)、场景体验不足(F5)、教学结果评估难(F13)、知识回顾效率低(F14)风险层级较高。从风险模块来说,教学形式(B1)、教学内容(B2)、教学互动(B3)与教学效果(B7)这四个风险模块相关项需要引起重视。层次聚类结果与先前设置的风险模块内容一致,有助于从风险所属模块角度对风险进行识别。教学效果(B7)是其他六个风险模块等潜在风险综合作用的结果,特增加该类子项表示用户感知学习质量的重要性。
该改进FMEA方法不仅识别出在线教学“VH、H、M、L、VL”5类风险,从下至上的聚类过程还增强了风险模块内部关联关系的可解释性。图2c横坐标中:“6~10”表示出“教学现场性减弱(F7)”与“网络带宽不支持(F11)”这两个失效模式的关联性,说明的是在教学质量中由于受到网络带宽、演示设备等硬件的限制,教师的知识传达与学生的知识接收受到影响;“8~9”代表“演示操作不流畅(F9)”和“物理环境不友好(F10)”,两者均影响学生的情感学习环境,受影响者的学习积极性下降。“12~13”显示“教学结果评估难(F13)”与“学习过程效率低(F14)”这两个“学习效果(B7)”子项与“F1~F5”相关,即“教学形式、教学内容与教学互动(B1~B3)”对教学过程的师生双方起到的影响更突出,是需要被着重调整与改善的关键质量短板;而“教学平台(B5)”与“教学环境(B6)”的风险影响较弱,需要长期的持续改进。
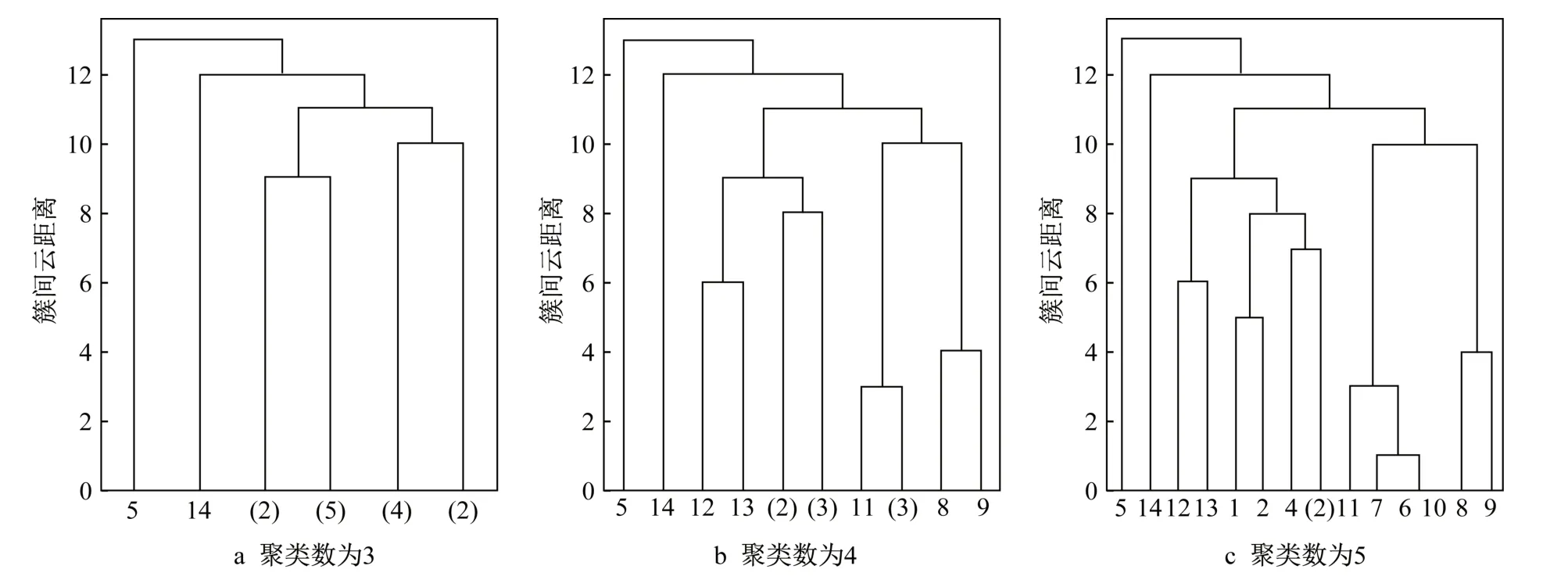
图2 凝聚型层次聚类树状图Fig.2 Agglomerative hierarchical clustering dendrogram
3.4 比较分析
为证明方法的有效性,将云模型聚类改进的FMEA 方法计算结果与传统FMEA 的RPN 算法进行比较(见表3),两者对失效模式风险级别计算结果整体一致,但具体排序存在差异,体现了改进FMEA方法对评价的模糊性与随机性。如“教学现场性减弱(F7)”在传统RPN 排序9,但在改进方法中排序11,因为对不同的教学参与者而言,该类失效是随机发生的,且学习者个体适应性不同,处理该类型失效模式的能力也不同。与其他失效模式相比,该失效模式的随机性更强,在改进方法中的风险等级下降。基于改进FMEA 方法结合现实情况的随机不确定性,提高了对各层次风险识别的客观性。

表3 3种方法的风险优先排序与等级比较表Tab.3 Risk ranking or level results by three kinds of methods
4 结语
基于云模型和凝聚型层次聚类算法的改进FMEA方法特点主要表现为:①更真实地反映了专家的评价信息,用云模型处理风险因子评价信息,考虑了专家语言评价的模糊性与随机性;②无需事前指定风险类别数量,利用凝聚型层次聚类算法进行失效模式的风险等级分类与内部层次关系识别,在实践中更易操作。在未来研究中,可进一步拓展本方法以处理更复杂的动态风险分析问题,如对方法中涉及的权重进行时间序列的动态调整,对云模型距离的计算方法进行比较改进等。
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
大学(2021年2期)2021-06-11
文苑(2020年4期)2020-05-30
现代计算机(2018年27期)2018-10-25
小学生作文(中高年级适用)(2018年3期)2018-04-18
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
少儿科学周刊·少年版(2015年4期)2015-07-07
浙江人大(2014年5期)2014-03-20
