
基于对称注意力机制的视觉问答系统①
2021-05-21 07:22吴春雷王雷全
计算机系统应用 2021年5期
路 静,吴春雷,王雷全
(中国石油大学(华东)计算机科学与技术学院,青岛 266580)
1 引言
近年来,基于视觉和语言的跨模态任务,如视频场景识别[1]、图文匹配[2]、视觉问答[3]等,在学术界和工业界引起了越来越多研究者的兴趣.其中,视觉问答(Visual Question and Answering,VQA)可以用来测试智能机器对多模态信息的理解和推理能力,故被认为是一种评估当前机器学习模型实现程度的“视觉图灵测试”.因此,VQA 越来越受到重视,它的具体任务是给定一张图片和一个问题,通过两者的合理融合生成相应的答案.VQA 研究的重点在于如何更加全面的理解视觉内容和自然语言,如何更精准地提取和表示模态特征,以及如何更有效地融合跨模态信息.为了挖掘图像突出区域与问题文本中重要词之间的对应信息,在VQA 任务中引入了注意机制.目前主流的算法是将问题信息与图片信息经过注意力机制生成含有双边信息的特征,再将其放到答案预测器中生成结果.但是这种算法只考虑了问题和图像的双边信息,却忽略了图像信息和问题信息自身的关联性.因此,本文提出一种新的模型,该模型通过利用图片和问题的自关联性和共同注意力信息,进一步提升答案和图片的契合度.本文提出的模型在回答问题的准确率上与基线模型相比取得了一定的提升,这进一步说明了该模型的有效性.
本文中,创新点可以总结归纳为如下3 点:
(1)本文在单模态特征中增强了特征区域间的关联性,使图像中区域框之间及问题中单词之间的关系更紧密.
(2)本文提出对称注意力机制的图像问答模型,该模型可以将图像与问题文本之间的双边信息以及图像区域与问题词的自相关统一在一起,实现了较全面的语义理解与融合.
(3)在VQA2.0 上通过大量的实验对新模型进行了验证.新模型准确率比DCA[4]的模型提高了1.22%,表明了该方法的有效性.
2 相关工作
2.1 视觉问答
像图文匹配一样,视觉问答在人工智能领域作为一种综合计算机视觉和自然语言理解的任务被大家重视.与其他视觉任务(行为识别[5],目标检测[6],图像描述[7])不同,除了视觉语言基础信息外,许多视觉问答示例还需要问题或图像中未包含的其他信息,例如关于世界的背景常识.问题的答案可以分为以下几种:是/否、多选择、计数和开放式的单词/短语(关于什么、在哪里、谁、…).VQA 在大多数研究中被划分成一个分类问题,图像和问题作为输入,答案作为输出类别.目前,视觉问答的解决方案都是使用卷积神经网络(Convolutional Neural Networks,CNN)对图像进行建模,使用循环神经网络(Recurrent Neural Networks,RNN)或长短期记忆网络(Long Short Term Memory networks,LSTM)对于问题特征进行建模.
2.2 注意力机制
注意力机制建立在人脑视觉注意机制的基础上,在用于视觉问答之前,已经被用于机器翻译[8],图像描述[9]等任务.在视觉问答系统中,注意力机制与神经网络[10]结合被用来选择与问题信息最相关的图像区域.Yang 等[11]构建了一个叠加注意网络,以连续的方式生成图像上的多个注意图,目的是进行多个推理步骤.在EGCS[12]中,作者使用multi-hop 图像关注机制,目的是捕获问题中的细粒度信息.Shih[13]应用现有的区域提议算法来生成对象区域,并选择最相关的区域来预测答案.Xiong 等[14]提出了一种基于注意力的门控循环单位(Gated Recurrent Unit,GRU),以促进答案的预测.除了视觉注意力,目前Nguyen 等[4]已经提出了一种具有问题注意力的共同注意力机制.同样,本文将共同注意力机制应用于图像区域和问题关键词,但是与文献[4]不同的是,本文提出的模型考虑了问题信息和图像信息的自身关联性,独立对待句子中的每个单词和图像中每个区域框.
3 视觉问答方法模块介绍
3.1 基于LSTM和RCNN的特征构造
由于问题词具有顺序性,故使用双向LSTM 对其编码.具体来说,一个包含N个单词的问题首先被转换成一个GloVe向量序列然后将其输入到具有残差连接的单层双向LSTM (Bi-LSTM)中,过程可由如下公式表示:

创建一个矩阵T=[t1,···,tN]∈Rd×N,其中同时,为了获取输入图像的表示,将Bi-LSTM 中最后隐藏状态保存.这里的Bi-LSTM 网络参数采用随机初始化.
同理,遵循类似的过程对答案进行编码.将包含M个单词的答案转换为然后输入到Bi-LSTM,产生的隐藏层状态和.本文将答案表示为
对于图像,将其大小调整为448×448,再输入到预训练好的ResNet-152 网络中提取图像特征.同时,将ResNet-152的res5c 层的输出作为对应于14×14 空间分布区域的图像特征,用I=[i1,···,ik]∈Rd×K表示,其中K=14×14是区域总数,ik表示第k个特征向量,ResNet-152的维度是2048.
3.2 对称注意力模型
图1是本文所提出的对称注意力模型.在3.1 节中已经得到图像特征I和问题特征T:现将他们输入到对称注意力模型中,经过模型的训练最终生成相应的模态特征.

图1 对称注意力模型架构
模型的右部分是经典的共同注意力架构[4],首先对于给定的图像特征I和问题特征T,通过叉乘运算得到注意力矩阵A,再将A通过双层Softmax 生成关于问题的注意力矩阵AT和关于图像的注意力矩阵AI,最后再分别与图像特征和问题特征相乘得到含有双边信息的图像特征IR和问题特征TR.这个过程可用下面的5 个公式表示:

其中,式(3)的WR∈RN×K表示权重矩阵,注意力矩阵的维度均为d×d.
模型的左部分增强了单模态特征中特征区域间的关联性.将问题特征输入到一个全连接层,得到单词对相关联的问题特征TF,将图像特征输入到全连接网络以及dropout 得到图像区域框相关联的图像特征IF.这个过程可用下面两个公式表示:

其中,FCNet()是全连接网络,用dropout 可以让网络去学习鲁棒性更强的特征,这些特征在其它的神经元的随机子集中也存在.经过以上训练增强了图像信息和问题信息自身的关联性.
再将图像特征IF,问题特征TF通过叉乘和Softmax运算得到权重分布矩阵logits,该矩阵的维度与注意力矩阵A一致,包含了两种特征的融合信息.最后,权重分布矩阵分别与图像特征和问题特征相乘得到含有双边信息的图像特征IL和问题特征TL.这个过程可用下面的3 个公式表示:

其中,式(10)中的WL∈RN×K表示权重矩阵.最后,对于图像特征,将左部分生成的图像特征IL和右部分生成的图像特征IR融合;对于问题特征,进行同样的处理.用公式表示如下:

其中,⊕表示,两个特征的联合操作.图像特征IA和问题特征TA是对称注意力模型的输出,其维度与输入特征的维度一致.
3.3 新模型整体架构
图2是本文提出的新模型整体架构,这里所用答案预测层是目前比较常用的多层感知器(MultiLayer Perceptron,MLP)神经网络分类器,它有2 个隐藏层和1000 个隐藏单元(dropout为0.5),每一层都有tanh非线性函数.首先,对输入的图像和问题分别提取特征,图像特征和问题特征作为对称注意力模型的输入,然后生成包含双边信息的特征,再作为答案预测分类器的输入,最终选出得分高的答案.这个过程可以通过以下公式表示:

其中,att()表示对称注意力模型算法,answer()是答案预测分类器.

图2 模型整体架构
3.4 总结
和现有的方法相比,本文摒弃了只采用一个注意力特征矩阵来融合特征的方法或者将两模态特征简单连接的方法.本模型通过已有的Faster RCNN和Bi-LSTM的方法构建了图像和问题的特征提取网络,采用注意架构将两模态信息巧妙融合在一起,既实现了对双边信息的理解,又增强了图像区域特征的关联性和问题单词对之间的关联.
4 实验
4.1 数据集和实验细节
本文使用最流行的数据集VQA 2.0[15]来进行实验.VQA[16](也称为VQA 1.0)包含来自MS COCO 数据集[17]的204 721 张图像上的人工注释的问答对.预先将数据集分为train、val和test(或test-standard)3 个部分,它们分别由248 349 个问题、121 512 个问题和244 302 个问题组成.所有的问题都被分为3 种类型:是/否、计数和其他,每个问题都有10 个自由回答的答案.VQA 2.0是VQA 1.0的更新数据集,与VQA 1.0 相比,它包含的样本更多(train 数据集有443 757 个,val 数据集有214 354 个,test 数据集有447 793 个),在语言方面更加均衡.本文使用具有挑战性的开放式任务的VQA2.0 数据集评估提出的模型.
与其他工作一样,本文选择出现8 次以上的正确答案作为候选答案集.根据之前的研究,本文在train+val分支上训练模型,并在test-standard和test-dev 进行测试.
4.2 实验细节
本文所有实验均基于PyTorch 框架,并在装有一个Nvidia Tesla P100 GPU的计算机上进行实验.使用的优化器的参数是α=0.001,β1=0.9,β2=0.99.在训练过程中,使VQA2.0的学习率(α)以0.5的速率每7 个迭代下降一次.所有的模型都在VQA 2.0 上分别训练了24 个迭代.为了防止过拟合,将每个全连接层的dropout 设为0.3、LSTM dropout 设为0.1.批次大小为400,隐藏层大小为1024.
4.3 实验分析
本文采用准确率来评测模型的质量和训练情况.在图3中,绘制了准确率随迭代次数变化而变化的折线图,可以看出本文提出的方法模型的准确率折线快速收敛,不断提高.再与图4的直方图结合观察,可以看出随着迭代次数的增加,模型的准确率也在不断提升,迭代次数为24 时效果最佳,最高可以达到66.34%.通过图3,不难看出在超过24 个迭代的时候,由于模型出现了过拟合现象,模型的准确率会有小幅度的下降.在表1中,列举了其他模型(VQA team[15],MCB[18],MF-SIG-T3[19],Adelaide[20],DCA[4])和本文提出的模型在VQA2.0 测试数据集上的准确率,通过对比发现,本文建立的模型具有较好的结果.
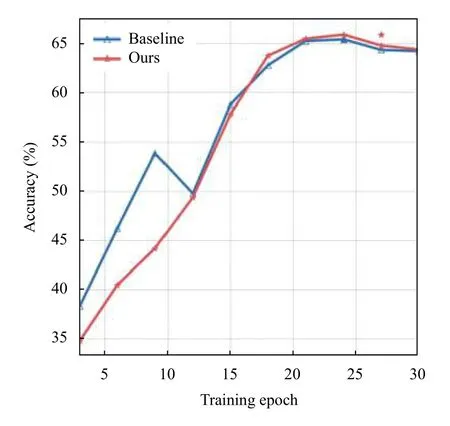
图3 Overall 准确率损失变化
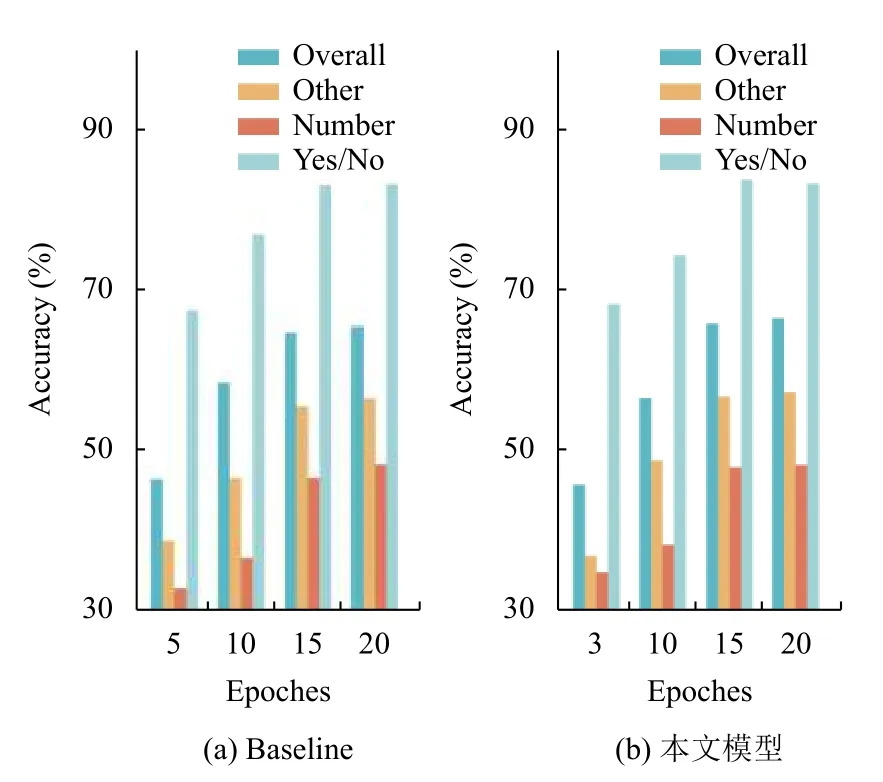
图4 准确率柱状图
由表1可以看出,本文提出的模型准确率优于基线模型.新模型的Overall 问答准确率比baseline 在Test-dev 数据集上提升了1.22%,Other 问答准确率提升了0.72%,Number 问答准确率提升了0.9%,Yes/No问答准确率提升了0.38%.这些数据证明:本文提出的模型可以在较少的训练迭代次数下收敛,基于对称注意力机制的模型有效的提升了视觉问答的质量.相比于传统的特征融合等方法,对称注意力模型可以通过融合不同模态的信息,增强问题信息和图像信息的自身关联性来大幅度提升答案分类的准确率.

表1 与其他方法的实验结果比较(%)
5 结论与展望
本文提出了一种对称注意力机制的图像问答模型,并在VQA2.0 数据集上取得优异的成绩.该算法的亮点在于使用全连接网络来挖掘图像区域之间的相关性,联合基于共同注意力机制生成的双边信息特征,达到更加精准的分类效果.和DCA 相比,本文考虑了图像和问题的全面语义理解和融合,较好地利用了自相关信息.在未来的工作中,将进一步探索视觉(短视频)问答系统和知识图谱对于答案分类的影响.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
读与写·教育教学版(2017年10期)2017-11-10
第二课堂(课外活动版)(2016年2期)2016-10-21
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
