
基于孪生自动编码器的深度说话人嵌入向量
2021-05-28 12:37陈杰叶瑶瑶
现代计算机 2021年10期
陈杰,叶瑶瑶
(上海交通大学微纳电子学系,上海201100)
0 引言
说话人识别(Speaker Recognition)属于生物识别技术的一种,通过从语音信号中提取声纹特征进行身份识别,也称作声纹识别。说话人识别主要分两种模式,说话人辨认(Speaker Identification)和说话人验证(Speaker Verification)。本文的研究方向为说话人验证,即验证所给的语音是否属于所声称的说话人。
近年来,为了实现更优的性能,DNN已经广泛应用于说话人识别领域[1-4]中并取得了良好的效果。通过大规模据训练的深度神经网络在大多数任务上已经超越了传统的i-vector[5]说话人识别系统,特别是在短语音上表现优异。而在诸多基于DNN[6-8]提取说话人向量的研究中,x-vector[3,6]凭借其优秀的区分性和灵活性被应用在许多任务中。
x-vector系统的原理主要通过时延神经网络(Time-Delay Neural Network,TDNN)从语音段的多个语音帧中提取出说话人嵌入向量,其主要包括3个部分:处理帧级特征的神经网络,将帧级特征池化为句级特征和处理句级特征的神经网络。通常大多数的说话人识别系统中会在后端使用概率线性判别分析(Proba-bilistic Linear Discriminant Analysis,PLDA)来对提取的嵌入向量打分。目前的主流技术框架中,为了增强嵌入向量的区分性还会在PLDA打分之前使用线性判别分析(Linear Discriminant Analysis,LDA)方法对向量降维。
近年来,为了提升x-vector系统的性能,有许多工作针对系统中的池化层提出了改进。譬如可学习字典编码的池化层[9],基于注意力机制的池化方法[10-11],基于交叉卷积层的池化方法[12]。多数研究人员普遍认为嵌入向量的区分性与池化层对帧级特征的池化能力有很大关联,于是为了改善嵌入向量的性能针对池化层做了许多研究。池化后的特征经过句级别网络的处理后失去了许多原有说话人特征,更加关注其区分性,这便造成了一部分嵌入向量的说话人信息损失。我们提出了一个新方案来解决这一问题,我们在整个网络训练完成后抛弃了第三部分的句级别神经网络,转而使用了基于孪生神经网络的自动编码器来提取说话人嵌入向量。
目前自动编码器在说话人识别领域中已经有了许多应用。例如2019年的一项研究提出使用变分自编码器通过数据增强的方式来产生更具鲁棒性的说话人嵌入向量[13],也有一项研究表明经过变分自编码器编码的嵌入向量由于更近似高斯分布,使得变分自编码器编码后的向量针对PLDA打分的方式能达到更高的精度[14]。R.Font提出了一种降噪自编码器的方法,可以用于获得更具说话人区分性能的嵌入向量[15]。自动编码器也可以用作领域自适应[16]。上述的这些研究成果大都使用自动编码器作为说话人识别系统中的后端处理器,当然也有前端处理的研究例如用作降噪[17]。不过,不同于已有的这些研究成果,我们直接使用自动编码器来提取嵌入向量。
我们提出的新方案基于x-vector系统,针对池化层的输出特征使用基于孪生网络的自动编码器编码获得更具说话人区分性特征的嵌入向量,同时尽可能地保留原有说话人特征。自动编码器可以通过训练神经网络重建输入来获得更低维度的隐变量。在我们的系统中,使用统计池化层的输出特征作为自编码器的训练数据,自编码器的中间层输出隐变量作为说话人嵌入向量。在基于x-vector的系统中,这种方案实现方式简单,同时编码得到的嵌入向量相比基线系统的x-vector更具区分性和鲁棒性。
1 基线系统
1.1 基线x-vector系统
自从Dan[6]基于深度神经网络提出了x-vector系统之后,说话人验证任务的性能取得了十分显著的提升[18,19]。在x-vector系统中,时延神经网络用作帧级别的特征提取网络,网络结构如图1所示。
系统中的t代表当前帧,TDNN中的第一层接收从t-2至t+2帧拼接而成的上下文特征;第二层接收上一层输出的第t-2,t,t+2帧的拼接特征;第三层接受第二层的输出的第t-3,t,t+3帧的拼接特征;随后的两层不包含上下文信息。统计池化层会对TDDN输出的全部帧进行池化统计,其会计算所有输出T帧的平均值和标准协方差,将会输出2×M(M=1500)维的池化向量用作句级网络训练。池化向量随后传至全连接层和输出层。说话人标签作为训练DNN网络的输出标签。训练完成之后,提取全连接层第一层的输出向量作为说话人嵌入向量,随后其余的神经网络不需要使用。在我们的实验中,训练x-vector提取器的具体实现方法参照Kaldi[20]工具完成。
1.2 LDA-PLDA系统
针对基于深度神经网络提出深度说话人嵌入向量,通常会使用一个后端处理器来补偿嵌入向量的信道差异和打分。后端处理方法可以分为:使用LDA算法对嵌入向量降维,其通过最大化类间方差与类内方差的比值来保证向量最大可分性[21];随后对LDA降维后的向量进行向量长度归一化;使用PLDA根据说话人不同话语中的类内差异性和类间差异性,在嵌入空间中建立相应的说话人子空间,并利用子空间中的相似度对不同嵌入向量的相似度打分[22-23]。在这个系统中,LDA的降维维度设置为200。LDA和PLDA的具体算法实现使用Kaldi工具完成,实现细节参照“ivectorcompute-lda.cc”和“ivector-compute-lda.cc”这 两 个程序。
2 基于孪生网络的自动编码器
2.1 自动编码器
为了增加嵌入向量中包含的说话人信息,同时去除无关噪声,我们提出了使用自动编码器提取说话人的嵌入向量。自动编码器是一种自监督学习方法,训练时无需额外提供说话人标签信息,其早在上世纪80年代[24]就已经被提出来了。自动编码器通过自监督学习的方式使得网络学习到能够重建输入的网络参数,经编码后的隐变量尽可能地保留了原有输入信息,其网络结构如图2所示。
自动编码器包含两个部分:第一部分为把输入编码为隐变量的编码器,其公式可以表示为h=f(x);第二部分为把隐变量重解码为输入的解码器,其公式为=g(h)。͂为输入x经过自动编码器重建后的输出,我们假设χ为用作训练的嵌入向量集合。为了最小化重建误差,我们使用均方误差作为网络训练的损失函数,损失函数可表示为:

其中|χ|代表样本的数量。在我们的实验设置中,自动编码器的结构为“3000-2048-1024-512-1024-2048-3000”,如图2所示。同时为了使训练过程更加稳定,我们分别在编码器和解码器的两层网络之间都使用了leaky ReLU激活函数和批标准化(Batch Nor-malization,BN)。
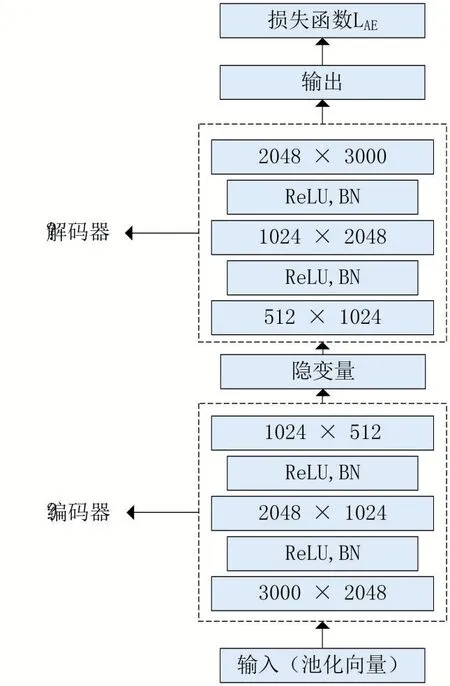
图2 自动编码器结构
2.2 孪生神经网络
孪生神经网络属于神经网络的一种,首次提出于1993年[25]并被应用于签名识别,并于2005年被应用于人脸识别[26]。大多数的工作主要集中在识别任务上,包括人脸识别、指纹识别、签名识别,等等。类似于自动编码器,孪生网络同样将输入样本映射到一个隐变量空间,使得新的隐变量同类间的距离小于不同类变量之间的距离。所以其主要想法是找到一个目标空间,这个目标空间中更能体现出输入样本之间的内在联系。当训练数据不足以包含分类样本所需的全部信息时,孪生网络能发挥出巨大的作用,很适合说话人识别任务中缺少说话人全部信息的问题。其原理图如图3所示。

图3 孪生神经网络结构
孪生神经网络有两个结构相同,且权重共享的子网络,分别接受两个输入向量x1和x2,将其映射为X1和X2,计算两个向量之间的距离来判断向量的相似度。孪生神经网络使用对比损失(contrastive loss)作为损失函数,表达式如下:

其中:

代表两个样本特征X1、X2的欧氏距离,P表示样本的特征维数,Y代表两个样本的匹配标签,Y=1代表两个样本匹配,Y=0则代表不匹配,m为设定的阈值,N为样本个数。
从上述的对比损失函数的表达式可以发现,这种损失函数可以很好地表达成对样本的匹配程度,也能够用于训练提取特征的模型。
●当Y=1(即样本相似时),损失函数为:

即当样本相似时,其特征空间的欧氏大的话,损失值增加。
●当Y=0(即样本相似时),损失函数为:

即当样本相似时,其特征空间的欧氏距离反而小的话,损失值也会增加。
2.3 基于孪生网络的自动编码器
为了训练出更具说话人区分性的编码器,我们结合了自动编码器和孪生网络的优点,在尽可能保留原有说话人特征的基础上,我们利用孪生网络对自动编码器进行半监督训练,其网络结构如图4。
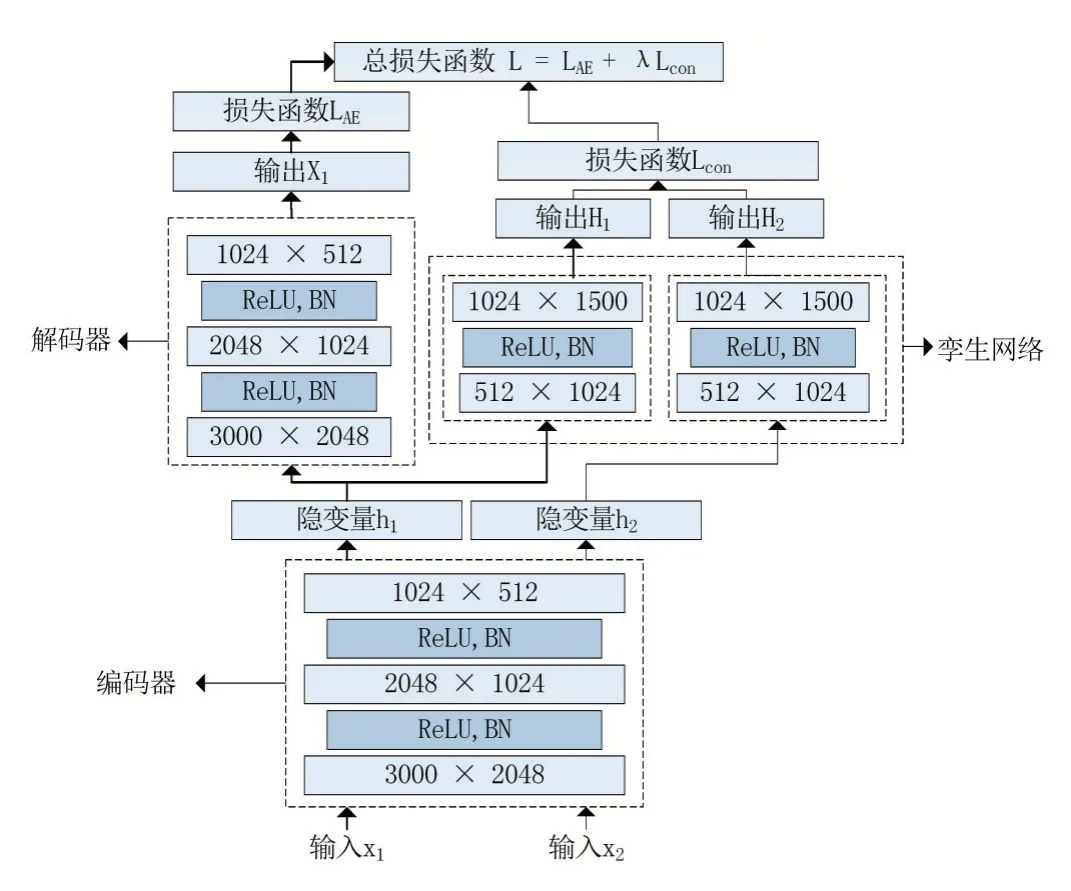
图4 基于孪生网络的自动编码器结构
我们使用TDNN和统计池化层提取出来的池化向量作为网络的训练数据,原有说话人标签作为孪生网络的监督数据。当输入池化向量x1时,系统会随机取出样本集中另一个池化向量x2。如果这对向量来自同一说话人,当距离过大时,其损失值则越大;反之,如果这对向量来自不同说话人,当距离过小时,其损失值也越大。我们综合原自动编码器和孪生网络的损失函数作为训练新网络的损失函数,其公式如下:

为了调控孪生网络对自编码器的惩罚力度,我们在总损失函数中引入惩罚系数λ。
训练阶段结束后,TDNN网络和自动编码器的结构参数将会被确定。最终说话人嵌入向量提取器的结构如图5所示。
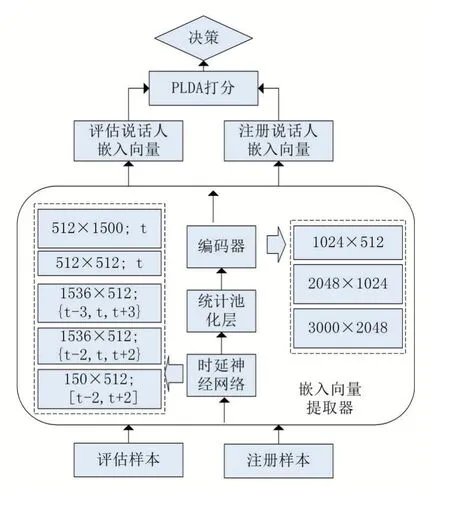
图5 基于孪生网络的自动编码器深度说话人识别系统
我们保留了基线x向量系统的前两个过程,帧级TDNN网络和统计池化层。自动编码器的编码器用来将池化向量转换成说话人嵌入向量。最后,系统根据PLDA的打分分数判决语音是否来自注册说话人。
3 实验和结果
3.1 训练数据
在本次实验中,基线x-vector系统和我们提出的系统均使用Voxceleb1[27]和Voxceleb2[28]两个数据集的数据作为训练集。在训练阶段,我们只使用两个数据集的开发集训练。Voxceleb1的开发集包含来自1211个不同说话人的148642句语音,Voxceleb2的开发集包含来自5994个不同说话人的1092009句语音,这些语音均采集自YouTube网站上的视频。LDA和PLDA的训练数据为两个数据集经过向量提取器得到的说话人嵌入向量。
3.2 测试数据
在测试阶段,我们使用Voxceleb1的TEST集来评估基线系统和新系统的性能。测试集包含4874段语音,平均时长约为8秒,采样频率为16KHz,采集自YouTube上40位不同的说话人。测试过程分为两个阶段,注册和评估。在注册阶段,每个说话人的3句语音被用作注册语音,用来提取嵌入向量,3条语音的嵌入向量在取平均值后作为代表注册说话人的说话人向量。在评估阶段,剩余的语音将会分别计算出与注册语音的相似度,根据相似度判断是否为本人。
3.3 评估指标
(1)等错误率
在说话人识别任务中,等错误率(Equal Error Rate,EER)为最常用的指标,这是一种通过调整阈值使错误接受率和错误拒绝率相等时对应的比率。调整后的阈值点可以作为实际使用阶段的阈值。
错误接受率(False Acceptance Rate,FAR):

其中FP代表错误接受样本数,TN代表正确拒绝样本数。
错误拒绝率(False Rejection Rate,FRR):

其中TP代表正确接受样本数,FN代表错误拒绝样本数。
当通过调整阈值确定等错误率后,EER=FAR=FRR。
(2)最小检测代价
最小检测代价(Minimum Detection Cost Function,minDCF)是美国国家标准与技术研究说话人识别评价(NIST SRE)中定义且常用的一种性能评定方法。其定义为:

其中CFR代表错误拒绝的惩罚系数,CFR代表错误接受的惩罚系数,Ptarget代表真实说话测试的先验概率,可以根据实际环境分别设定它们的值。实验中我们设定CFR=10,CFA=1,Ptarget=0.01。
3.4 实验设置
系统的输入特征我们设置为30维的梅尔频率倒谱系数,采用帧长为25ms和帧移为10ms的滑动窗口对语音信号进行分帧,同时使用基于能量的语音端点检测方法去除语音中的静音帧。基线系统中x-vector提取器的实现方法参照Kaldi中SRE16/V2样例实现。提取的x-vector维度为512维,池化向量维度为3000维,自动编码器提取的嵌入向量维度为512维。训练时使用单张NVIDIA RTX 2080TI显卡。
3.5 实验结果
我们针对3种不同结构的说话人识别系统,在Voxceleb1的TEST数据集上进行了测试,其实验结果见表1。

表1 在Voxceleb1数据集中不同说话人识别系统性能的表现
由表1可知,我们提出的自动编码器提取出的说话人嵌入向量相比基线系统提取的x-vector向量性能得到了提升。在引入孪生神经网络训练后,系统的等错误率进一步下降。说明我们的方法提取出来的说话人嵌入向量更具区分性和鲁棒性。
为了进一步探究λ取值对自编码器性能的影响,我们通过改变λ来验证其效果,其中我们设置阈值m=10,实验结果如表2所示。

表2 λ对基于孪生网络的自动编码器说话人识别性能的影响
实验表明λ权重对系统性能有着比较显著的影响,实际应用的时候调整合适的λ参数需要经过详细的测试,本实验中选取λ=0.1作为最后的实验方案。可以看出,增加孪生网络的自动编码器相比原本的自动编码器的性能有了更大的提升。
4 结语
本文针对最新的基于x-vector说话人识别系统进行了改进,在原有框架的基础上更改了向量提取器的结构,增加了自动编码器作为说话人嵌入向量的提取器。随后对自动编码器进行了优化,使用了孪生神经网络监督训练自动编码器,使得到编码器对说话人更具区分性,提升了说话人识别系统整体的性能。作为说话人识别系统的新架构,本文对自动编码器的优化还未能达到最佳,在后续的研究中还需要对自动编码器的结构进行进一步的优化。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
煤气与热力(2022年2期)2022-03-09
软件(2017年6期)2017-09-23
科技与创新(2017年5期)2017-03-28
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
电子设计应用(2004年6期)2004-07-27
