
应用BPNN及可见-近红外光谱检测土壤有机碳
2021-05-28 12:37曾凯翔陈奕鸿黄佳丽周伟东薛秀云
现代计算机 2021年10期
曾凯翔,陈奕鸿,黄佳丽,周伟东,薛秀云
(华南农业大学电子工程学院、人工智能学院,广州510642)
0 引言
土壤有机碳是土壤养分中一项重要的指标,快速检测土壤有机碳含量是现在精准农业、测土配方施肥的关键。传统的土壤有机碳(OC)含量分析方法为实验室化学分析法,使用仪器一般为原子吸收光谱仪、色谱仪等光谱分析仪器,测量前期准备长,数据处理复杂,测量时效性差[1]。从上世纪开始,国外便有利用可见-近红外光谱分析土壤有机碳的探索研究,可见-近红外光谱分析法具有简便、快速、时效性强等优点,应用前景广泛。随着新的仪器和新的光谱分析算法出现,利用光谱分析技术对农田土壤有机碳含量进行分析的能力逐渐提高[2-3]。国内外学者利用光谱分析土壤有机碳的研究,证明了VNIRS分析技术可用于土壤有机碳的快速检测[4],从理论和工程两方面为建立较为准确的土壤有机碳含量检测模型奠定了基础。
土壤有机碳含量检测模型一般利用某一特定时间、特定地点、特定土壤类型的样本进行建模训练,而当其中某一条件变化时,土壤样本与建模样本不匹配,模型检测效果减弱。模型传递能力是目前阻碍可见-近红外光谱检测技术应用的难点[5]。本文利用BPNN建立土壤有机碳含量检测模型,并与PLS、SVM模型对比,应用GA提取光谱特征波长,通过对不同类型土壤进行建模,分析模型的传递能力。
1 材料与方法
1.1 LUCAS土壤数据库
数据采用LUCAS土壤数据进行。LUCAS数据库是欧盟在2008-2012年间开展的欧洲土地利用及覆盖统计调查所收集的数据集[6],其中包括19036个土壤样本及其相关理化性质数据,样本点分布于欧洲23个国家,土地类型耕地、林地、草地等。土壤样本的OC含量根据ISO 10694-1995干烧法进行检测,对土壤样本进行风干、过筛等预处理后,使用FOSS XDS近红外光谱分析仪对其光谱反射率进行测量,光谱波段为400-2500nm,波长间隔为0.5nm。研究选取LUCAS数据库中3个不同区域不同种类的土壤样本集进行研究分析,其中土壤样本数量分别为107(样本集1)、107(样本集2)、101(样本集3),土壤样本集中有机碳含量基本信息统计见表1。
1.2 数据处理方法
土壤有机碳含量检测模型的建立如图1所示,主要分为异常样本剔除、数据预处理、特征波长提取、建模分析四个部分。

图1 检测模型结构
(1)异常样本剔除
在光谱获取以及土壤有机碳含量检测的过程中,光谱仪本身误差或人为测量误差等会造成个别土壤样本光谱数据或土壤有机碳含量与其他正常样本存在较大误差,剔除此类异常样本能有效提升模型的检测精度[7]。主成分分析法(PCA)是一种常用降维算法,能有效保存原始光谱信息的同时对数据进行降维,从而易于判断出异常样本。
图2为对样本集3的光谱数据进行PCA后的效果图,设置0.95的置信区间,超出置信区间的样本判断为异常样本;土壤有机碳含量数据异常样本利用3倍标准差法进行剔除。对异常样本进行剔除后,获得原始样本集。
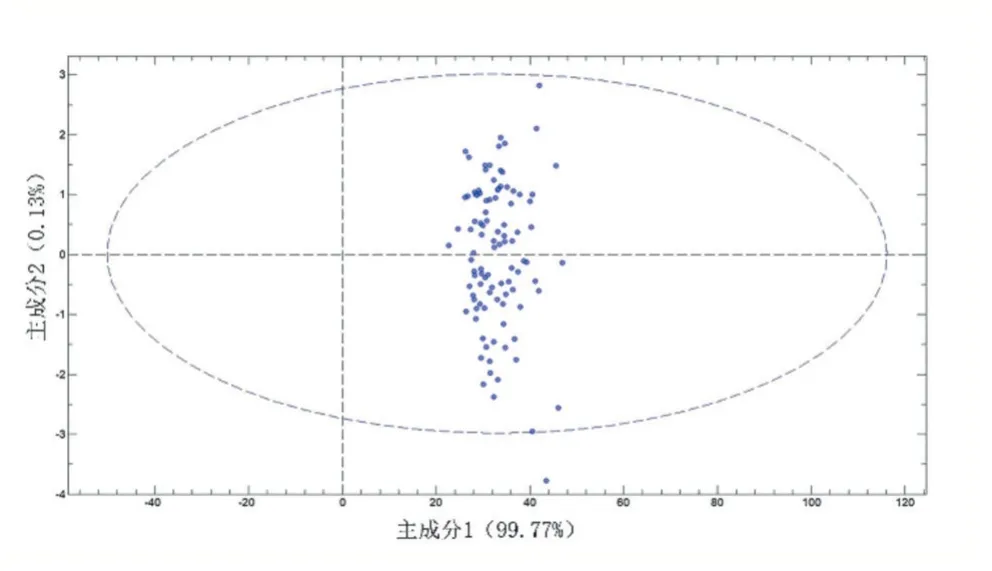
图2 PCA效果图
(2)数据预处理
有机碳含量模型检测精度与光谱信息的质量密切相关,环境因素的影响、土壤本身的结构状态和光谱仪的工作质量都会对光谱信息产生影响,光谱的预处理能够有效减轻这些影响[8]。光谱的预处理主要针对三个方面:随机噪声、基线漂移与谱峰重叠、光散射。
Savitzky-Golay滤波(SG平滑)是针对随机噪声的一种常用算法[9],SG平滑方法本质上是利用一个局部多项式回归来确定各个数据点的平滑值,能够有效地保留光谱数据的谱峰高度和宽度等特征。一阶微分算法可以消除光谱测量背景的干扰,解决基线漂移与谱峰重叠的问题,同时增强光谱数据的特征信息。
(3)特征波长提取
光谱仪在收集光谱数据的过程中冗杂数据也被加以收集,光谱数据特征波段的提取是为了找出波长中与待测土壤有机碳含量变化最为敏感的波段,避免冗杂数据对建模精度与效率带来影响。常用的特征波长提取算法有连续投影算法(SPA)、竞争性自适应重加权算法(CARS)、遗传算法(GA)等。
本文采用遗传算法(GA)进行特征波长提取。遗传算法是一种模拟自然进化选择过程随机搜索最优解的方法,可以有效地选取出与目标组分最具相关性的波段,降低建模难度与模型复杂度,提高建模精度与建模效率。
(4)模型建立方法
多元校正计量学方法是可见-近红外光谱分析技术常用建模方法[10],其中包括多元线性回归(MLR)、主成分回归(PCR)、偏最小二乘法(PLS)、机器学习算法最小二乘支持向量机(SVM)、人工神经网络BPNN等。
本文采用BPNN算法对土壤样本的光谱数据进行检测模型建立,并通过与PLS、SVM对比分析模型效果。最后利用交叉检测的方法分析模型的传递能力。
(5)模型评价方法
模型评价指标包括决定系数(R2)和均方根误差(RMSE),其中决定系数(R2)越接近1,说明模型的检测能力越强,均方根误差(RMSE)越小,说明模型检测效果越好[11]。本文采用交叉验证的方法对模型进行验证并得出评价指标。
2 结果与评价
2.1 土壤光谱数据分析
计算3种样本集的平均谱,由图3可知,土壤平均光谱曲线整体趋势相似,但由于土壤类型不同,样本集光谱吸光度存在一定差异,光谱曲线间存在交错。

图3 3种样本集的平均光谱
将光谱数据进行SG平滑处理,通过对比不同的窗口宽度与多项式阶数对模型的精确度的影响,选择窗口宽度为11和多项式阶数为3作为最终平滑参数。对平滑后的光谱数据进行一阶微分处理,得到一阶微分光谱。取光谱800nm-1200nm进行放大,由图4、图5对比可以看出,经过一阶微分后的光谱特征变得明显,土壤有机碳含量越高,吸光度变化趋势越大。将处理后的光谱数据作为原始光谱进行建模。

图4 局部波段平均谱
2.2 校正模型建立及其对比
对预处理后的光谱数据利用PLS建立校正模型,通过选用不同的潜变量(LVs)进行对比,得到各样本集校正模型的最佳潜变量个数,采用最佳潜变量个数的3种样本集PLS模型效果如表2所示。样本集的PLS模型交叉验证效果如图6所示。

图5 局部波段一阶微分谱

图6 PLS模型效果图
SVM、BPNN模型以PCA主成分作为输入变量。将预处理后的光谱数据利用主成分分析算法(PCA)进行降维,得到主成分变量。取光谱数据PCA前7个主成分进行SVM、BPNN建模训练。SVM模型采用径向基核函数(RBF kernel function)作为核函数进行模型训练,选用不同的SVM模型惩罚系数C和γ进行建模,将精确度最高的一组C和γ作为模型的最佳参数。通过对比,最终选择C=100;γ=0.01进行SVM建模训练。BPNN模型训练函数选择trainlm函数,采用5层BP神经网络进行模型训练,激活函数选择tanh函数,设置模型最大迭代系数为10000次、模型学习率为0.125。不同样本集的SVM、BPNN模型效果如表2。各样本集的SVM、BPNN模型交叉验证效果如图7、图8所示。
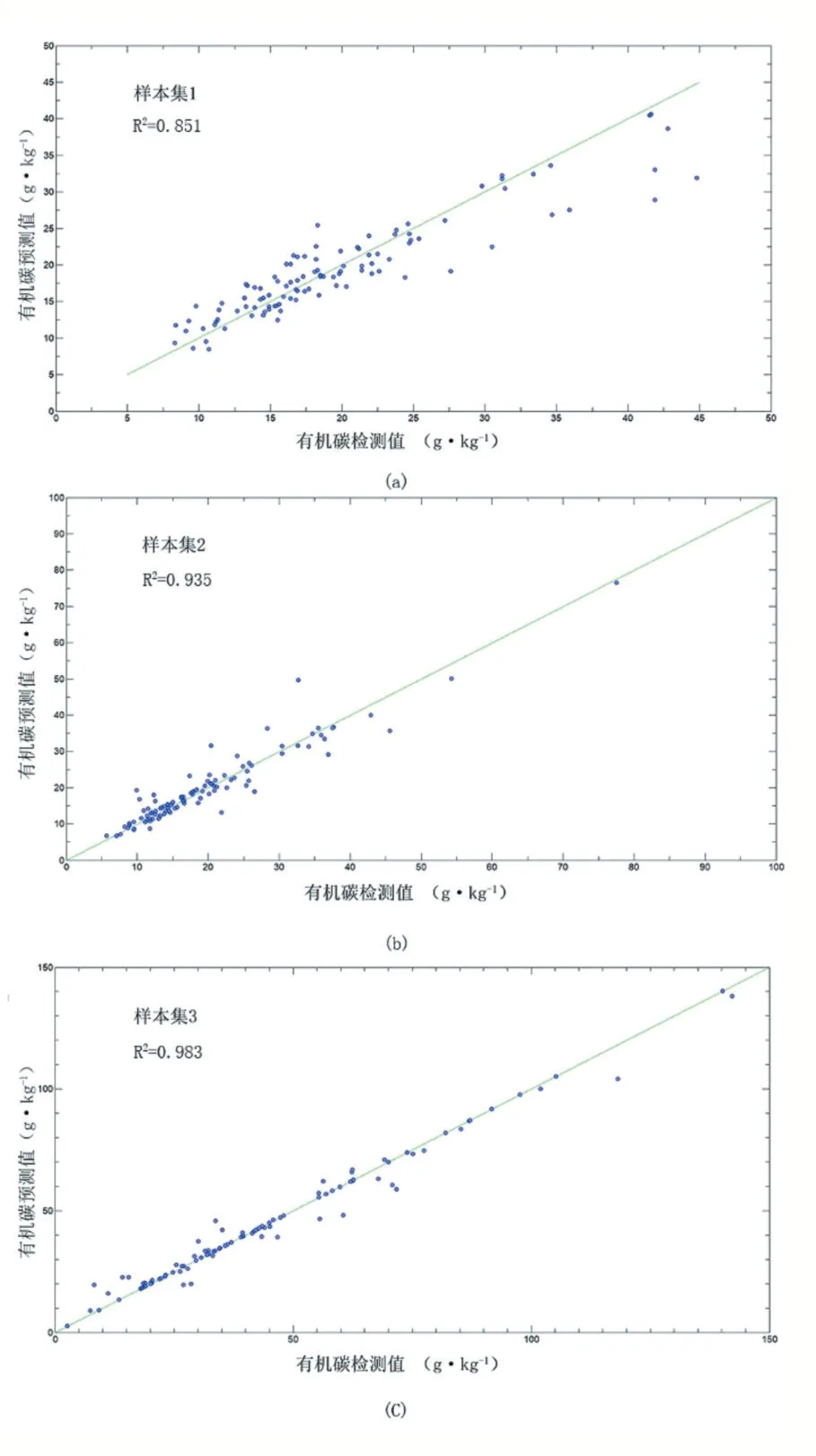
图7 SVM模型效果图

图8 BPNN模型效果图
从不同样本集有机碳含量检测模型可以看出,PLS、SVM、BPNN三种模型均有较好的检测效果,能够对土壤有机碳含量进行较为精确的定量检测,其中PLS的R2分别为0.832、0.924、0.968,RMSEV分别为3.36、3.74、5.53;SVM的R2分别为0.851、0.935、0.983,RMSEV分别为3.30、3.49、4.12;BPNN的R2分别为0.866、0.950、0.980,RMSEV分别为2.99、3.04、4.37。总体而言,BPNN模型检测效果较佳,能够有效地提高土壤有机碳含量检测模型精度、降低模型的RMSEV,SVM模型效果仅次于BPNN;相比SVM,BPNN在样本集1和样本集2中表现更好,而SVM在样本集3中表现更好,这是不同种类土壤间存在的差异所造成的,说明不同种类土壤样本的最佳检测模型会有所不同。具体建模过程中,由于BPNN、SVM需要进行模型迭代训练,算法更复杂、运行速度较慢;PLS模型检测效果相对较差,但相比BPNN模型和SVM模型算法,PLS具有算法更简单、运算速度更快的优势,在对检测精度要求相对较低而时效性要求更高的前提下,PLS模型优势明显。相比于土壤样本集2、3,土壤样本集1的精度较差,RMSEV却更低,这是由于土壤样本集1中的土壤有机碳含量数值更为集中。

表2 3种样本集建模效果
2.3 GA提取特征波长及其效果
将原始光谱数据作为输入利用GA进行特征波长选取,GA主要参数设置为:最大繁殖代数100,交叉概率0.5,变异概率0.01。由于GA作为一种全局概率搜索算法在运算过程中依赖随机数的产生,本文利用GA进行多次特征波长选取,以消除随机性对选取效果的影响,最终获得提取特征变量后的光谱数据。
GA在提取过程中对原始光谱各波段的选取频率如图9所示,对筛选后的光谱数据分别进行PLS、SVM、BPNN建模,模型效果如表3所示。由结果分析可知,提取特征波段后的光谱数据量仅为原始光谱数据量的25%,极大地减小的模型的复杂度,提高计算机运算效率;同时,GA不仅能将原始光谱中的冗杂波段剔除,对模型的效果也有所提升,其中GA-PLS的R2分别为0.835、0.942、0.971,RMSEV分别为3.32、3.24、5.25;GA-SVM的R2分别为0.860、0.987、0.985,RM-SEV分别为3.19、1.65、4.01;GA-BPNN的R2分别为0.875、0.965、0.984,RMSEV分别为2.89、2.52、3.93。经过GA提出光谱特征波段后,检测模型的R2提高,RMSEV减小,精度提升效果明显。
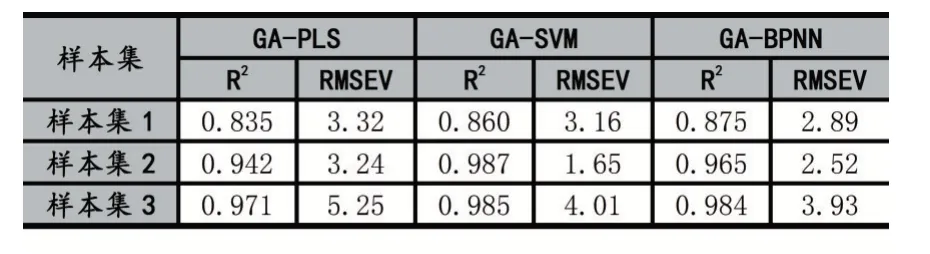
表3 提取特征波长后建模效果

图9 GA对各波段的选取频率
2.4 模型传递能力分析
为了研究检测模型对不同种类土壤的有机碳含量是否同样具有检测能力,分析检测模型的传递能力。利用土壤样本集的PLS、SVM、BPNN模型对剩余两个土壤样本集的有机碳含量进行交叉检测,检测结果如表4所示。

表4 交叉检测结果
由结果分析可以看出,由于不同地区土壤的类型、性质等不同,原土壤有机碳含量检测模型对其检测能力较差。BPNN模型相对于SVM、PLS模型适用性更高,模型传递能力更强,说明模型的传递能力与原模型的精度有关,原模型的检测能力越强,模型的传递能力也相对越强。研究表明,根据具体种类的土壤光谱数据进行建模分析,是获得高精度、误差小的土壤有机碳含量检测模型更为有效的方法。
3 结语
过去的相关研究中,利用可见-近红外光谱检测土壤有机碳含量存在研究样本种类单一、模型传递能力研究不足等问题[12]。本文利用土壤种类丰富的LUCAS数据库,对可见-近红外光谱检测土壤有机碳含量及其模型传递能力进行研究,主要结论如下:
(1)恰当的光谱预处理能有效提高对土壤有机碳含量的检测精度。其中,SG平滑算法结合一阶微分算法对光谱数据进行预处理效果良好,能够有效地降低光谱的随机噪声,突出光谱特征信息。
(2)BPNN、PLS、SVM模型对土壤有机碳含量的检测均有较好效果。SVM、BPNN作为机器学习算法,在检测能力上优于PLS,而在模型复杂度与运算速度上,PLS优于SVM、BPNN。
(3)GA算法可以有效地提取出光谱的特征波长,在大量降低光谱数据量、减小建模复杂度的同时,有效提升模型的精度,减小检测误差。
(4)PLS、SVM、BPNN模型传递能力不佳,对于不同种类的土壤有机碳含量均难以获得良好检测效果。BPNN、SVM由于本身模型精度较高,传递能力优于PLS,模型传递能力与原模型精度相关。根据具体土壤类型光谱数据进行建模分析是获取精度更高、误差更小的土壤有机碳含量检测模型的有效方案。
猜你喜欢
农业工程学报(2022年8期)2022-08-08
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
课程教育研究(2021年27期)2021-04-13
初中生世界·九年级(2020年2期)2020-04-10
科学24小时(2019年6期)2019-09-05
光学仪器(2016年6期)2017-04-24
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
