
基于模型在环仿真的自动驾驶虚拟测试平台
2021-06-16 06:31花威史庭俊吕强
电子技术与软件工程 2021年8期
花威 史庭俊* 吕强
(1.扬州大学信息工程学院 江苏省扬州市 225127 2.纽劢科技(上海)有限公司 上海市 201210)
1 引言
2020年6月1日,一辆行驶中的开了高级辅助驾驶功能的特斯拉Model 3 直接与一辆侧翻的货车相撞,自动驾驶汽车的测试显得尤为重要,不仅是对车辆进行测试,还有对自动驾驶系统[1]。伴随着高级驾驶辅助系统(ADAS)和高等级自动驾驶系统的开发和应用,产生了很多新的测试需求[2]。
硬件在环(Hardware-in-the-Loop,HiL)仿真结合数学模型与物理硬件设备在模拟车辆动力学及稳定性控制时引入重力、阻力、摩擦力等关键物理参数,用于提高模型置信度,对实际车辆进行仿真测试。Chen[3]等提出一种新型HiL 仿真平台,该平台利用HiL 仿真对自动驾驶车辆场景感知、路径规划、决策及控制算法进行闭环测试与评价,可将测试算法快速迁移到真实自动驾驶汽车上,但是并未将自动驾驶汽车的执行机构接入测试回路。
整车在环(Vehicle-in-the-Loop,ViL)仿真是HiL 仿真的一种特殊类型,ViL 通过将自动驾驶系统集成到真实车辆中,并在实验室条件下构建模拟道路、交通场景以及环境因素,可系统地实现基于多场景的自动驾驶车辆功能与性能测试。Zhao[4]等提出了一种基于整车在环(Vehicl-in-the-loop,ViL)的仿真平台,该平台实现了多自由度高动态试验台的结构设计、虚拟测试场景自动重构方法和传感器数据模拟及注入方法,但是这种仿真平台的搭建需要先设计出匹配的物理试验台,需要一定的平台搭建成本;试验台所模拟的场景是否比虚拟场景更加接近真实程度,还有待考证。Li[5]等提出了一种基于驾驶在环(Drive-in-the-loop,DiL)的仿真平台,该平台实现了对TCU 换挡策略驾驶性快速主客观评价,建立了能够识别驾驶意图和道路环境的TCU 换挡策略模型,可获得主观评分结果。但测试场景较为单一,评分结果也具有主观性。
模型在环(Model-in-the-Loop,MiL)仿真是较节省成本的嵌入式系统测试方式。这种测试方式一般在开发的初期阶段及建模阶段中进行,除了建立控制器模型外,还要建立被控对象模型,将控制器和被控对象连接起来形成了闭环,在仿真环境里面测试开发阶段的算法[5]。本文提出了一种基于模型在环的仿真方法,主要考虑环境的变化,比如前方有辆障碍车对本车的影响、突然Cut in 的障碍车对本车的影响以及道路属性由直线转为S 弯对本车的影响等,而忽略了实车车况和路面质量等现实性因素,是一种较为理想的仿真模型。相对于其他基于HiL 和基于ViL 的方法,本方法的优点是以较低的成本在开发初期就可以验证算法的可靠性并且可以加快强化学习算法的验证速度。基于场景的自动驾驶虚拟仿真平台主要包含以下3 个方面的内容:
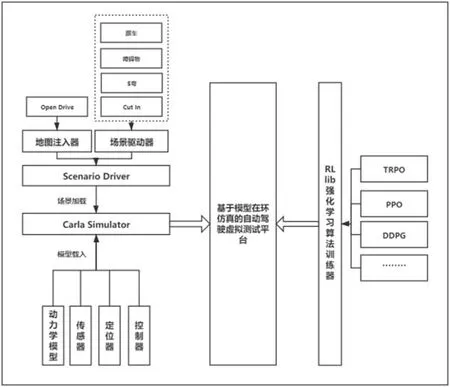
图1:基于模型在环仿真的自动驾驶虚拟测试平台
(1)自动驾驶测试场景:测试场景是自动驾驶测试的核心,基于OpenDrive 的地图定义格式,通过地图导入器导入了自定义格式的地图;基于Open Scenario 的场景定义格式,通过场景注入器构建了跟车、障碍物、S 弯和Cut in 等驾驶场景。
(2)自动驾驶虚拟测试环境:测试环境是自动驾驶虚拟测试的工具基础,本仿真平台是基于模型在环测试(Model-in-the-Loop,MiL)的平台体系。包含了虚拟传感器、天气模拟器、虚拟控制器和HMI 显示器。
(3)自动驾驶加速测试方法:加速测试是自动驾驶虚拟测试的重要优势,如何利用有限的场景和特征反映无限丰富与复杂的行驶环境,本仿真平台基于一种并发算法训练框架RLlib,可创建多个训练环境,并根据多个策略训练多个智能体。
2 仿真平台结构及工作原理
2.1 虚拟测试环境
Carla 仿真器是一种客户端-服务端的架构,也就是传统的C/S架构。服务端负责一切与仿真器本身相关的:传感器渲染、物理计算,对虚拟世界的所有成员进行数据驱动和更新。由于Carla 目的是模拟现实世界的结果,服务端最适合是在一个专用的GPU 上运行,尤其是在跑机器学习的时候。客户端端则根据server 端返回的传感器数据进行具体的控制,调整参数等。基于Carla 的仿真环境模块可以分为提供了定位器、传感器、控制器和HMI 模块的仿真器Carla Simulator 与提供Map 和Open Scenario 场景的场景驱动器Scenario Driver 两个模块。其中Carla 仿真器结合UnrealEngine 游戏引擎,提供了虚拟车辆仿真模型包含了3D 外观模型与一般的车辆动力学模型。ScenarioRunner 场景驱动器模块则提供了加载自定义OpenDrive 地图以及Open Scenario 场景的接口或功能。图1 为虚拟测试环境大体框架。

表1:车辆控制参数

表2:实际偏移量的参数值
2.2 虚拟车辆仿真模型
虚拟车辆仿真模型包含了车辆动力学模型和虚拟控制器。车辆动力学模型包括纵向、横向、横摆和侧倾运动以及4 个车轮的转动和2 个车轮的转向运动,本平台简化转向系统,直接以前轮转向角作为输入并假设左右两侧车轮转向对称,动力学模型如图2 所示。
根据图2 中的动力学模型可知:


式(5)的通式可以表达为:

式(6)中:状态变量为X=(xr, yr, θ)T;控制输入量u=(ur, af)T,其中状态X 变量参考车辆的状态输出,u 则为控制输入。对于这个控制输入u,有4 个自由度,分别是油门(Throttle)、方向盘转角(Steer)、刹车(Brake)和档位(Gear);表1 为4 个控制参数的类型和描述。
2.2.1 虚拟传感器
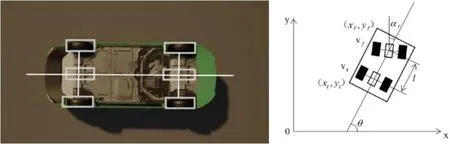
图2:动力学模型

图3:车辆坐标系

图4:沿道路参考线的“内部”车道建模
虚拟传感器通过在场景中模仿摄像头从周围环境中检索数据,模拟了传感器的探测原理。虚拟传感器基于导入的Open Drive 地图的定位信息感知本车周边环境并模拟感知信号。本仿真环境主要传感器是以摄像头为主,感知信号包括了摄像头的fov 视角长度、焦距和旋转角以及障碍车的相对坐标等,同时接入模型在环仿真测试系统,给算法模型提供所需的环境感知数据。
2.2.2 虚拟定位器
虚拟定位器用的GNSS 传感器模型,通过度量标准位置添加到Open Drive 地图定义的初始地理参考位置中计算。本平台使用的是游戏引擎常用的左手坐标系,及车身的正方向为x 轴,与车身正方向垂直的为y 轴,本平台忽略高度的变化。本车的坐标为世界坐标系下的坐标,而传感器所感知到的障碍物的坐标均为相对本车的坐标。如图3 所示。
从图3 可以看到,本车(Ego Vehicle) 的坐标为,这个坐标是相对于世界坐标系下的。以本车为原点的坐标系则称为本车坐标系,此时障碍车的坐标是本车坐标系下的坐标为,这样做的目的是便于在同一个坐标系下计算出障碍车的方向角和定位。
2.3 测试场景
2.3.1 地图
Open Drive 是一种开放格式规范,其定义的道路都是由基本几何形状(弧、直线等)的参考线(Reference line)组成。沿着这个参考线可以定义道路横截面,其中车道偏移记录(Lanes Record)根据参考线定义出其他车道。
车道偏移记录定义了车道参考线(通常与道路参考线相同)的横向偏移。实现车道相对于道路参考线的(局部)横向移动。这种车道偏移可以制作不同的道路场景,给场景的自定义建模提供了方便。图4 说明了沿道路参考线的其他“内部”车道的建模。

图5:自定义地图

图6:驾驶场景

图7:跟车场景行为树

图8:RLlib 多智能体多策略框架
其中给定点的实际偏移量是使用三阶多项式函数计算的,公式为:

其中,offset 为给定位置的横向偏移,a,b,c,d 为道路偏移系数, 为沿着所述条目的起始位置和实际位置之间的基准线的距离。表2为实际偏移量的参数值。
一个标准的Open Drive 格式的道路由多个车道(Lane Section)组成,每个车道分别有中心线,根据对应的车道的ID,根据公式7,调节自定义参数配置,生成如图5 所示的地图(A 点为起始点,B 点位终止点)。
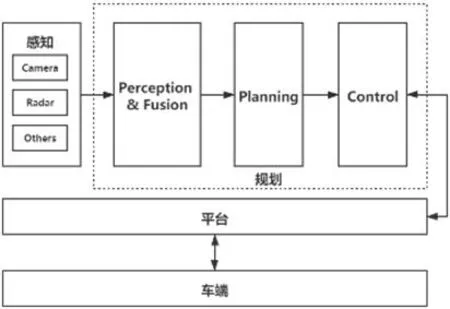
图9:自动驾驶软件模块间逻辑关系
2.3.2 场景
Open Scenario 是一种开放文件格式[7],在初始化的时候,将本车和障碍车的位置预设好,并通过行为树或者其他方法来约束障碍车的运动,这样通过不同的地图出生点和障碍车的行为可以模拟出很多交通场景。本平台提供了场景驱动器,通过编写xml 格式的静态场景文件,该文件内定义的是场景的名称、类型、车辆的出生点以及天气的情况,然后根据用户的需求撰写对应的Python 脚本来实现对场景内元素的动态控制。图6 分别是跟车、障碍物、弯道和前车切入四种驾驶场景。
平台提到的驾驶场景分别由不同的行为控制器所驱动,通过定义了行为树的状态机来控制指定驾驶场景里面的交通参与者的行为。如图7 跟车场景下,障碍车的行为树。
3 基于模型在环的仿真测试模型
RLlib 中由三个关键概念:策略,采样和训练器[8]。策略是RLlib 中的核心概念,策略用于定义智能体在环境中的行为。在一个训练环境,只有一个单独的智能体和策略。在向量式环境中,策略推断是一次针对多个智能体的,而在多智能体中,可能会有多个策略,每个策略控制多个智能体,如图8 所示。
在本文所使用的自动驾驶虚拟仿真平台是可以创建一个训练环境,有多个智能体,并且可以对应单个策略或多个策略。这大大增加了算法验证的效率以及覆盖率。
在RLlib 中,多组训练环境是每个步骤具有多个智能体的环境,例如,在交通模拟中,环境中可能有多个“汽车”的主体。 RLlib中的多代理模型如下:
(1)以用户身份,定义预先可用的策略数量
(2)一个将代理ID 映射到策略ID 的函数。伪代码如下所示。
算法1 多客户端运行算法模型
输入:训练的智能体数目:"num"_c ars,障碍车的距离:car _o bs _s pace,
本车的车间距:car _e go _s pace
输出:相应策略下训练的输出结果
1.自定义环境文件存取到env 变量中;
2.自定义环境中的配置信息:
3.config ={
4.“multiagent”:{
5.“policies”:{
6.#如果第一个元组值为空,则使用默认的策略
7.“car1”:(None,car_obs_space,car_act_space,”gamma”: 0.85),
8.“car2”:(None,car_obs_space,car_act_space,”gamma”: 0.99);
9.},
10.“policy_mapping_fn”:
11.#随机的选取车辆更新策略;
12.agent_id 为随机选择的”car1”或者”car2”;
13.}
14.}
15.将config 配置文件写入到训练器的可配置项中进行训练;
16.数目为num_cars 个智能体组成的交通环境为一个env;
17.if env 不为空 then
18.调用env.reset()函数重置env 中所有环境参数;
19.将更新障碍物new_obs,奖励值rewards,信息infos 赋值到env.step 的每个步骤中,作用在num_cars 个对象{"ca" "r" _1,car_2,...,car_*}中;
20.end if
21.end
22.final;
23.return 更新后的障碍物new_obs,奖励值rewards,信息infos;
4 实验结果与分析
自动驾驶算法模块包括平台、规划和感知三大模块。平台模块提供了车端硬件与无人驾驶系统之间的异步通信等功能;规划模块提供了数据融合、预测、规划和控制等功能[9];感知模块提供了雷达和摄像头获取车道线及障碍物等其他信息的数据,给到规划的融合子模块进行数据处理后分发给规划其他子模块。各个模块之间的大致逻辑关系如图9 所示。
本文的仿真平台则是将图9 中的感知、平台和车端利用基于Carla 的仿真环境替代,规划模块中的控制则使用基于RLlib 的强化学习算法模型替代,采用了第3 节所介绍的加速测试方法,在一张地图里面利用强化学习算法训练多个智能体在指定驾驶环境下的行驶,通过智能体在环境里面不断试错,达到相对最优控制[10],最终得到一个训练周期完成一次模型验证。
4.1 功能验证
通过该仿真平台,为仿真车辆配备虚拟摄像头以及碰撞传感器,尝试跟车功能的自动驾驶算法虚拟仿真验证,配合Open Scenario提供的跟车场景,包含了直道行驶、障碍车跟车场景。通过多轮反复调试,验证了传统强化学习方法TRPO 算法[11]在该场景下的从A 点开到B 点的性能表现。
仿真平台采用了RLlib 的框架,建立一个环境(env),这个环境中定义了Carla 仿真环境所使用的地图、场景以及客户端等参数。分别定义了三种方法reset(),step()和is_done():reset()定义的是满足is_done()定义的条件或者异常情况下的一些重置方法,比如说场景里面障碍车和本车的一些控制参数重置和出生位置重置。其中最关键的就是step()函数了,Open Scenario 场景是在该函数获取,动作值、步数和奖励值定义和更新也在这个循环的step()函数里面。
4.2 算法导入

图10:经典TRPO 算法实现跟车场景
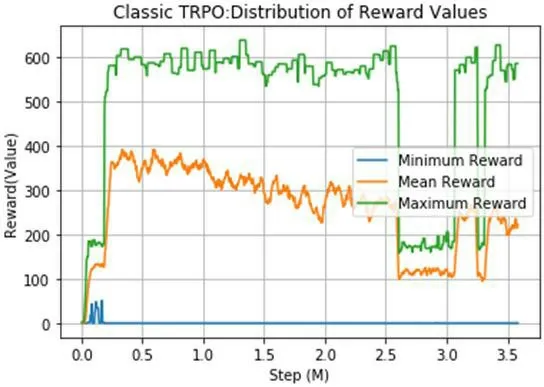
图11:经典TRPO 算法

图12:算法模型输出的控制量
第2.2 节给出一个简化的车辆动力学模型X=f(X,u),X 为仿真环境的输出,u 为算法模型根据X 所对应的控制输入。传统的策略梯度算法(Trust Region Policy Optimization, TRPO)[12]在离散动作空间和连续动作空间都取得很好的效果,这一系列算法的梯度更新满足下列关系:

4.3 仿真及结果分析
从上一小节的图10 中可以看出,有4 个智能体并发的在执行模型的训练,左侧行驶一段距离的车即是场景里面定义好的跟车场景的障碍车,右侧的车辆则是算法模型作纵向控制的本车(EgoCar),本轮仿真因为在直道车场景,所以只考虑车的纵向控制即约束的是控制量中的油门、方向盘转角、刹车和档位。经典TRPO 算法如图11 所示。

图13:HMI 模块

图14:跟车场景下本车数据表现
仿真平台输出的控制量输出如图12。
可以看到本平台验证了TRPO 算法通过RLlib 并发训练框架下对仿真车的控制效果,作为强化学习算法验证工具,输出了TRPO算法的奖励值分布和仿真车的控制量数据可视化。
4.4 实车部署验证
HMI(Human Machine Interaction)[13]提供了必要的可视化信息, HMI 的通信主要是通过CAN 总线接口,利用高德接口本车车辆定位在高德地图上的实时显示,通过websocket 通信,监听车辆关键数据,包括车辆时速、道路限速、设定巡航速度、跟车距离档位、驾驶模式、周边障碍物信息、感知车道线信息等,再通过echarts、babylon 分别呈现2d3d 效果。如图13 所示。
对应跟车场景,根据TRPO 训练出的模型对此的实际反映,从图14(a)(b)可以看出在前车进行刹车制动的时间片区间中,模型给出了减少Throttle 值增加Brake 值的控制指令,即模型对感知给到的前车的速度和跟车距离做出了明显的应对反应,并且实车体验下也确实做到了较为舒适的控制。
5 结语
自动驾驶车辆搭配了自动驾驶软件,自动驾驶软件部署到实车则必须经过大量的仿真测试去验证,本文基于虚拟仿真的技术,开发了一种将车辆的动力学模型、传感器模型、自动驾驶控制算法、地图数据、交通场景等数据和模型组合的方法,采用了一套支持场景注入的自动驾驶仿真器与并发训练框架,并且进行了特定动态场景下的仿真应用测试,该方法所具备的优势有:
(1)搭建了趋于真实并且可以不断优化的车辆动力学模型、传感器模型、自动驾驶算法、地图数据和交通场景。支持现行标准OpenDrive 和Open Scenario 格式,并且有场景驱动器Scenario Driver 将指定的交通场景导入到Carla 仿真器中。
(2)通过一种支持并发训练算法的框架,加快算法验证的效率,本文证明了跟车场景下,传统的TRPO 算法的仿真表现,并通过结果数据可视化更直观的看出算法的优劣程度,为自动驾驶汽车算法的验证和加速测试评价提供了一种真实有效的方案,具有一定的实用性。
猜你喜欢
科学技术与工程(2022年30期)2022-12-05
机械设计与制造(2022年5期)2022-05-19
重庆大学学报(2021年12期)2022-01-12
汽车电器(2021年12期)2021-12-30
学生天地(2020年5期)2020-08-25
电子测试(2018年10期)2018-06-26
小太阳画报(2018年3期)2018-05-14
阅读与作文(小学低年级版)(2016年12期)2016-12-22
汽车文摘(2015年11期)2015-12-02
交通建设与管理(2015年15期)2015-03-20
