
一种基于堆叠自编码器的WiFi室内定位算法
2021-06-19 08:15马佩勋
导航定位学报 2021年3期
马佩勋
(长沙民政职业技术学院 软件学院,长沙 410004)
0 引言
随着无线保真(wireless fidelity, WiFi)的广泛覆盖,以及多数移动设备支持电气和电子工程师协会(Institute of Electrical and Electronic Engineers,IEEE)802.11标准,基于WiFi的室内定位系统得到了广泛关注[1]。如文献[2-3]分别提出了基于传播的 WiFi定位和指纹匹配定位。相比于基于传播的WiFi定位,指纹匹配定位算法具有高的定位精度。
指纹匹配定位算法先记录 WiFi 接入点(access points, APs)信号(指纹),再利用指纹信息匹配设备的位置。典型的指纹匹配WiFi定位算法由离线阶段和在线阶级构成:在离线阶段,获取各点APs的接收信号强度(received signal strength,RSS),并记录每点位置所对应的RSS值,构成位置数据库;在在线阶段,通过测量用户位置的RSS值,再将 RSS值输入数据库,进行匹配,进而估计用户位置,如图1所示。

图1 WiFi定位流程图
然而,由于无线信号内的固有噪声,指纹匹配WiFi定位算法仍面临着挑战[4]。为此,研究提出了不同的策略应对挑战,旨在提高定位精度[5]。例如,文献[6]通过概率技术统计信号的内在噪声,其性能优于文献[7]的方案。然而,这些技术方案假定不同的AP间的信号彼此独立[8]。为解决AP间信号彼此不独立的问题,本文提出基于堆叠自编码器的WiFi室内定位(stacked denoising autoencoders WiFi-based indoor localization, SDIL)算法,其能够应用于不同设备的异构环境,获取强健的定位精度。SDIL算法先通过深度学习,自动捕获在不同AP与不同的指纹位置间的非线性关系,并且无需假定各点独立;再通过指纹匹配定位算法估计节点位置。同时为了实现强健的定位精度,利用堆叠式去噪声自编码建立深度学习模型,获取含噪声WiFi信号与不同指纹点位置间关系;最后引用概率模型进一步处理输入信号的噪声。实验数据表明,提出的SDIL算法能够获得约1.21 m的定位精度。
1 系统模型及问题形式化表述
1.1 系统模型
考虑如图2所示的系统结构。整个系统由离线训练阶段和在线定位阶段构成。在离线训练阶段,建立N个深度神经元,其对应N个指纹训练点。即一个深度神经元对应一个训练点。

图2 系统模型
首先,利用签名收集(signature collector, SC)模块扫描 APs,并收集不同指纹位置的 RSS值,将这些测量值传输至云端的服务器;其次,利用预处理(preprocessor, PR)模块,将WiFi测量值转换成适合深度网络训练模型的格式;最后,将预处理后的数据传输至噪声嵌入(noise injector, NI)模块。通过嵌入噪声,扰乱原始的测量值,再将原始的测量值和经噪声嵌入后的测量值转化至模型训练(model trainer, MT)模块,即将它们作为训练模块的输入。MT模块负责为每个指纹点产生和训练去噪声预编码模型。
完成了离线阶段后,便进入在线阶段。先扫描各Aps信号,并捕获这些点(盲节点)的RSS值。再将这些数据进行预处理,最后由概率定位模块估计盲节点位置。
1.2 问题形式化表述
不失一般性,在二维(2D)物理空间Θ内部署M个接入点。在整个Θ空间内部署N个离散指纹位置点,并收集训练数据。在在线定位阶段,持有移动设备的用户扫描附近APs。令ℓ表示用户的位置。
用M维的矢量x= (x1,…,xM)代表一个WiFi扫描值。矢量x中元素xi对应一个接入点i的接收信号强度 RSS。因此定位问题可表述为:给定矢量x= (x1,…,xM),寻找位置 ℓi,使其能够获得最大化概率P(ℓi|x)。
2 SDIL算法
2.1 预处理模块
预处理模块承担了将记录的WiFi RSS值xi转换成相应的特性矢量的任务。由于并非每次扫描都能包括所有的M个APs,当RSS值过低,例如当RSS值小于-100 dB·m时,则无法捕获该AP的RSS值,这就需采用固定的尺寸矢量,将其作为机器学习模型。并将所捕获的 RSS值进行归一化处理,使其分布在[0,1]上。
2.2 离线训练模型的构建
作为深度学习的变形结构,去噪自编码器(denoising autoencoder, DA)具有良好的学习数据集特征的能力。将多个DA进行堆叠,便形成堆叠的去噪自编码器(stacked denoising autoencoder, SDA)。
由于SDA无需吉布斯采样,训练更容易,SDA受到广泛应用。为此,本文提出的SDIL算法也采用SDA,充分利用SDA在训练过程中的无监督学习和对数据的破坏能力,加强学习到数据集中的特征和数据结构。换而言之,通过SDA降低数据中的噪声数据,提升学习数据集特征能力,提高离线训练模型的准确性。
具体而言,令x表示原矢量数据。通过映射,在隐含层产生新的输出为
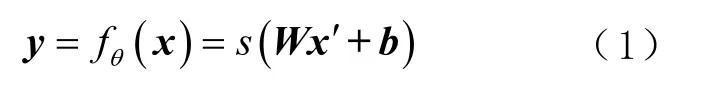
式中:x′为对x加入噪声后的数据;θ={W,b},为映射的参数集;W为权值矩阵;b为偏置向量;s为一个非线性函数。
令gθ′(y)表示解码器函数,其将y重构为z,即
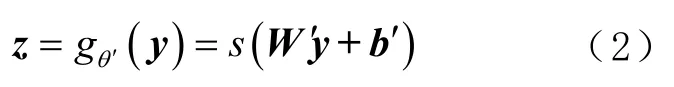
式中:θ′= {W′,b′},为映射参数集;W′为逆映射的权重,W′=WT;b′为偏置向量。
将x与z进行比较,构建重构误差,并通过调整模型参数,使误差最小,即
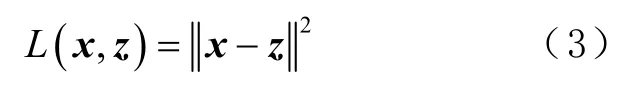
图3给出 DA结构。先原始输入数据进行扰乱,再经自动编码和解码后重构成z,并通过最小化误差,得到原始数据x。

图3 去噪声编码模型
利用离线训练模型获取最优的映射参数集,使原始数据与重构后的数据间的误差最小。即基于最小化的重构误差原则,当重构误差不再减少,就结束训练。离线训练模型的输出就是映射参数集θ={W,b}。
2.2.1 基于掩盖腐化的NI
由于多径和衰落影响[9],在固定位置所检测的APs数随时间变化。利用掩盖腐化方法仿真波动的接入点[10]。图4为一个掩盖腐化的NI示例。

图4 基于掩盖腐化的NI示例
如图4所示,先由腐化参数f产生随机的二值变量矢量,再将二值矢量与原始矢量x相乘。这就使得0值所对应的AP点的数据丢失。这正好符合有些AP点、用户无法捕获它的RSS值的情况。当没有检测到AP点的RSS值,就将该RSS值设为零。
2.2.2 模型训练
由SDA构成深度学习模型。每个堆栈对应一个指纹位置。利用西格莫伊德(Sigmoid)函数,将输出值限定于0至1的范围内,即
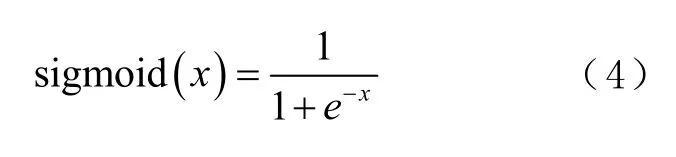
式中x表示任意实数值。
引用微调策略(fine-tuning stage, FTS),对模型进行端到端的训练。先随机初始化权重值,然后将每个输入的训练值遍历网络,进而得到重构数据。再将原始数据与重构数据差值的平方和作为调整权重的损耗函数。同时,引用梯度下降算法对不同层的权重系数进行调整。
2.3 在线定位阶段
在在线定位阶段,实现对用户位置的估计。具体而言,将未知位置用户所获取的 WiFi扫描值,输入至每个指纹匹配位置的深度模型,再依据概率模型,选择与重构值相似度最高的位置作为用户位置。
假定用户在位置ℓi接收到了WiFi信号,用信号强度矢量x= (x1,…,xM)表示这些信号,其中M是环境的 APs总数。为了估计用户位置,先计算概率P(ℓi|x),这表示在给定信号强度矢量x下,用户位于指纹位置ℓi的概率。依据贝叶斯(Bayesian)理论[11],先验概率P(ℓi|x)为

式中:p(ℓi) 为用户位于位置ℓi的先验概率;p(x|ℓi) 为位置ℓi时出现信号强度矢量x的概率;p(x)为出现信号强度矢量x= (x1,…,xM)的概率;N为指纹数据库里的位置数,即训练的位置数。假定所有位置是等概率的,则式(5)可改写为
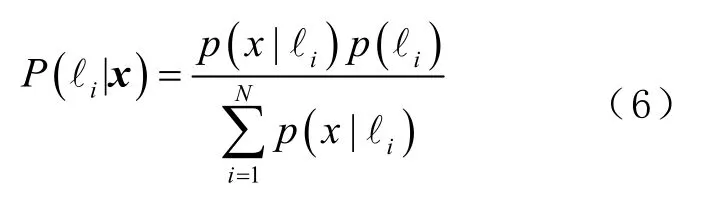
传统的指纹匹配算法,例如文献[6]是假定所有APs间的RSS信号值彼此独立,并没有考虑到不同APs间的相关性。换而言之,SDIL算法是通过重构离线深度学习模型,来估计条件概率P(ℓi|x)。即从每个深度模型获取初始值的重构值,再计算重构值与初始值的相似度。由于矢量x= (x1,…,xM)包含了M个APs点的信号值, 重构值考虑这M个Aps信号值与用户所在的位置的相关性。下面用相似函数表述此相关性。由于径向基核(radial basis kernel, RBK)函数的输出值介于0至 1范围内,将径向基核函数作为相似函数。用P(x′|ℓi) 表示相似函数,即
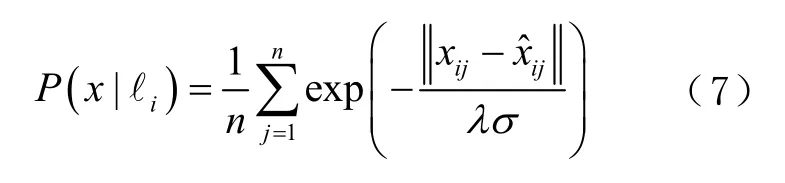
式中:xij、分别为第j个 WiFi扫描的原始数据及重构后的数据;σ为输入扫描的方差;λ表示径向基函数参数值;n是总位置数。由式(7)可知,P(x′|ℓi)包含了n个扫描点位置信息,即在估计决策用户位置时考虑了各扫描点间的相关性。
将用户位于ℓi位置的概率作为其权值,把所有指纹点的中心位置作为用户位置[12],即
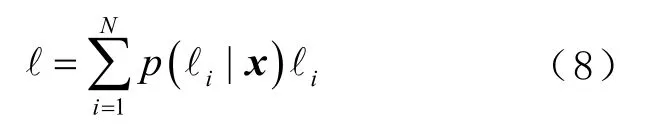
3 性能分析
3.1 实验场景
选择约1 600m2的康复医疗区域,在此区域内部署122个APs, 进行数据实测,如图5所示,其中黑色空圆心表示AP所在位置。由5个志愿者使用不同的安卓手机,在 48个不同位置收集数据。由这些数据的7 200抽样值构成训练数据库。
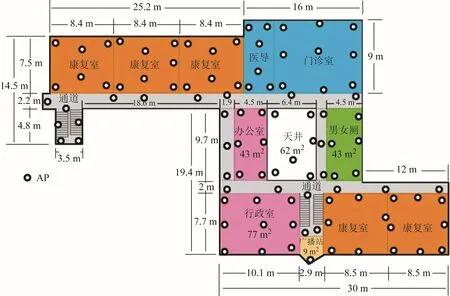
图5 康复医疗的平面图
用户通过安卓系统的软件开发工具包(software development kit, SDK)软件,扫描 APs,获取WiFi信号数据。这些数据包括MAC地址,RSS以及时间戳。具体的实验参数如表1所示。

表1 实验参数
为了更好地分析SDIL算法性能,选择文献[6]提出的基于概率指纹匹配定位(probabilistic fingerprinting based Indoor localization, PFIL)和文献[13]提出的基于深度学习的定位(deeplearning based indoor localization, DLIL)算法进行参照。PFIL算法假定APs间彼此独立,在训练数据时,没有考虑APs所采集数据的关联性。DLIL算法也采用深度学习算法,但没有处理数据中的噪声。
3.2 定位精度
图6显示各算法在不同定位误差下的累积分布函数(cumulative distribution function, CDF)曲线。
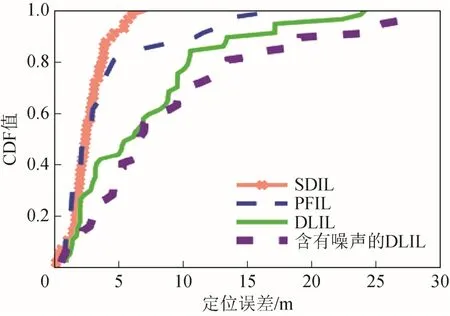
图6 各算法的CDF曲线
从图6可知,相比于PFIL和DLIL算法,SDIL算法获得了更好的定位精度。表2列出PFIL、DLIL和SDIL算法的平均定位精度。

表2 不同方法的定位精度 单位:m
由图6和表 2可知,SDIL算法的定位精度优于PFIL和DLIL算法。原因在于:PFIL算法没有捕获不同APs与指纹位置间的相关性;DLIL算法没有考虑无线信号的内在噪声。因此,对DLIL算法加入噪声后,其定位性能急速下降。SDIL算法不仅对数据中的噪声进行了处理,也考虑了不同APs与指纹位置间的相关性,提高了定位精度。
3.3 运行时间
利用矩阵实验室(matrix laboratory, MATLAB)软件编写算法软件,在主频为172.6 GHz、随机存储器(random access memory, RAM)为16 GB、显卡为恩维迪亚(Nvidia)GTX 960M的电脑上运行该软件。图7显示了匹配122个APs时,PFIL算法、DLIL算法和SDIL算法的运行时间。
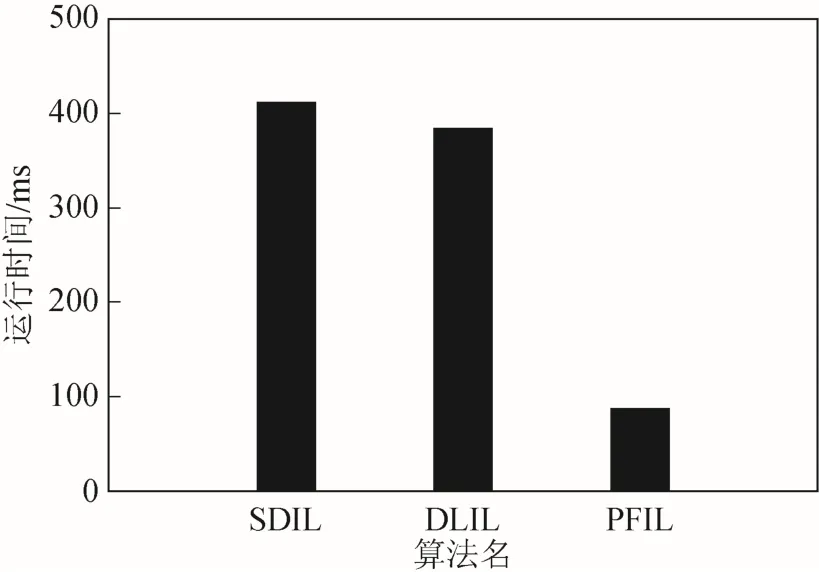
图7 运行时间
从图7可知,PFIL算法的运行时间最低,而 DLIL算法的运行时间介于 PFIL与 SDIL算法之间。本文提出的 SDIL算法运行时间最长,达到412 ms,但412 ms的定位时间是可以满足要求的。
4 结束语
针对室内定位问题,提出基于深度学习的WiFi室内定位SDIL算法。SDIL算法引用堆叠去噪声自编码深度学习法训练模型,并利用概率技术应对信号中的噪声。仿真数据表明,提出的 SDIL算法能够达到 1.21 m的定位精度。相比于PFIL算法和DLIL算法,SDIL算法提高了定位精度。但是,SDIL算法的运算时间长,达到412 ms。在基于位置服务的应用中,412 ms的定位时间可以满足要求。目前还没有单独考虑离线训练的性能以及x中添加的噪声对训练性能的影响,后期将考虑训练点数以及添加噪声对性能的影响。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位学报(2022年5期)2022-10-13
电脑知识与技术(2022年15期)2022-07-02
电脑爱好者(2020年23期)2020-12-30
小天使·一年级语数英综合(2020年10期)2020-12-16
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
儿童时代·快乐苗苗(2016年2期)2016-10-22
电脑爱好者(2015年5期)2015-09-10
青少年科技博览(中学版)(2015年7期)2015-08-12
