
基于改进极限学习机的转炉出钢合金化锰收得率预测模型
2021-06-21 06:33周凯啸林文辉孙建坤冯小明方炜刘青
中南大学学报(自然科学版) 2021年5期
周凯啸,林文辉,孙建坤,冯小明,方炜,刘青
(1.北京科技大学钢铁冶金新技术国家重点实验室,北京,100083;2.新余钢铁股份有限公司,江西新余,338001)
近年来,钢铁领域的智能制造技术不断发展,转炉炼钢的控制技术逐渐由人工经验、静态控制转变为依靠模型的智能控制。转炉炼钢过程的出钢合金化操作是整个冶炼的重要环节。在出钢过程中,操作人员需要根据冶炼钢种的工艺要求加入相应的合金,在脱去钢水多余氧的同时,使钢水中硅、锰等合金元素含量达到钢种成分要求。在传统的合金加入方法中,合金加入量由操作人员凭借经验估算,常常出现因估计加入量的偏差较大导致合金的浪费或多次补加。为了提高合金加入量的精准度,冶金工作者从合金化的冶金工艺理论和数学预测模型等角度开展了研究。一些学者从冶金机理[1-4]角度对合金化过程进行了研究,其结果定性地判断了不同因素对合金化过程的影响,为转炉出钢合金化提供了指导,但以此准确计算合金的加入量较为困难。张春霞等[5]通过BP神经网络预测合金元素的收得率,并基于此使用多元线性规划的方法得到最优的合金配料方式。龚伟等[6]通过参考炉次法得到合金元素的收得率,同样采用了多元线性规划的方法得到最优配料方式。杨凌志等[7]通过历史炉次的合金加料数据自学习,建立了合金元素收得率动态库,依此计算合金的加入量,提高了合金加料的准确度。
由以上研究可知,出钢合金化预测模型的建立主要是围绕获得合金元素的收得率展开,可归纳为3 种方法:建立合金元素收得率预测模型[5]、参考炉次法[6]、建立合金元素收得率动态库[7]。其中,参考炉次法是选取和当前炉次生产钢种相同的最近几炉生产数据,并选取一个基准值进行简单的加权平均,难以完整考虑到当前炉次的特点;建立收得率动态库是对所有历史炉次加料情况进行自学习,对某一元素的收得率不断进行修正,实际得到的是收得率的平均值;而建立收得率预测模型可以充分考虑到不同炉次的特点,获得较为准确的收得率。因此,本研究选择建立收得率的预测模型。BP 人工神经网络能够有效处理一般的非线性关系,应用较广,但需要设置的网络训练参数较多、训练速度较慢且容易陷入局部最优解;而极限学习机算法(extreme learning machine,ELM)训练过程需调整的参数少,训练速度快,且能够得到唯一的最优解。陈恒志等[8]采用ELM 对连铸坯质量预测进行建模,张小晨等[9]采用ELM对转炉冶炼终点碳温预测进行建模,均取得了较好的效果。因此,本文采用极限学习机算法来预测合金元素收得率,为提高预测精度,引入了正则化参数及改进粒子群算法(improved particle swarm optimization,IPSO)对ELM 算法进行优化,建立基于改进粒子群算法优化的正则化极限学习机(IPSO-RELM)的Mn元素收得率预测模型,并根据合金元素的预测结果来计算硅锰合金加入量,使用国内某钢厂120 t转炉生产HRB400钢的实际生产数据进行建模。
1 转炉出钢合金化工艺
转炉冶炼结束后,在出钢合金化过程中有一小部分合金与钢液的溶解氧发生化学反应,转化为脱氧产物进入渣中,大部分合金则进入钢中,进入钢中的合金元素质量和总的合金元素加入量的比值即为该合金元素的收得率。以HRB400钢为例,该钢种Mn 元素目标质量分数要求为1.40%~1.55%,而转炉冶炼终点Mn 质量分数只有0.1%~0.3%,因此,需要加入硅锰合金,使成品钢种Mn含量达到工艺要求。本文根据生产实际,推导得出合金加入量计算公式为

式中:M为硅锰合金加入量,kg;t为钢水质量,kg;b为Mn元素目标质量分数,%;a为冶炼终点Mn元素质量分数,%;ω(Mn)为硅锰合金中Mn元素的质量分数,%;Y为Mn元素收得率,%。
为了提高合金元素收得率的准确性,在统计了大量生产数据的基础上,建立了基于IPSORELM算法的Mn元素收得率的预测模型,并基于此计算合金的加入量。
2 IPSO-RELM算法原理
2.1 极限学习机算法
极限学习机算法[10]是前馈型神经网络的一种,相对于一般的BP神经网络,该算法具有求解速度快、准确度高的特点,因为极限学习机求得的解是直接经过运算得到的唯一解,而BP神经网络的解是通过迭代得到的数值解。同时,极限学习机算法中输入层和隐含层的连接权值和隐含层偏差随机给定,其训练过程所需调整的参数少。
ELM 算法的结构如图1所示,是一种单隐层前馈型神经网络[11],其结构包括输入层、输出层和隐含层。本研究中,输入变量为对Mn元素收得率有较大影响的工艺参数,输出变量为Mn 元素收得率。

图1 单隐层前馈神经网络模型Fig.1 Feedforward neural network model of single hidden layer
对于一个极限学习机模型,存在任意n个不同的数据样本(Xj,Yj)∈Rn×Rm,网络含有L个隐含层节点,隐含层神经元的激活函数为G(x),输入层连接权值矩阵和神经元隐含层偏差分别为ωi和bi,则ELM模型为

写成矩阵形式为

式中,Ym为第m个输出层神经元的输出;G(ωi,bi,xj)为第i个隐含层神经元的输出矩阵;β为隐含层和输出层的连接权值矩阵。
ELM 算法中的输入层权值矩阵ωi和隐含层偏差bi随机产生,只需确定合适的隐含层节点数,解得输出值Mn元素收得率预测值与实际值偏差最小的连接权值矩阵β即可。
2.2 正则化极限学习机
在使用ELM 算法进行建模时,经常会出现训练效果好,预测结果差,即过拟合问题,难以实际应用。为了避免模型出现过度拟合,增强模型的泛化能力,提高在实际预测中的准确度,通过正则化[12]方式,建立正则化极限学习机(regularized extreme learning machine,RELM),即引入正则化系数λ,控制隐含层与输出层的连接权值矩阵β的范围,使其绝对值不过大,避免出现过拟合的情况,提高模型的泛化能力。RELM算法的数学表达式为

式中,E为极限学习机的风险总和;λ‖β2‖为结构风险;‖ε2‖为经验风险;εj为训练误差和矩阵。
RELM算法的求解过程如下。
首先,构造拉格朗日方程:
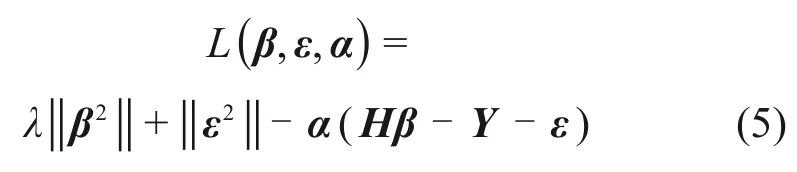
其中:α为拉格朗日算子。
其次,分别对式(5)中各个变量求偏导,并使之为0得:
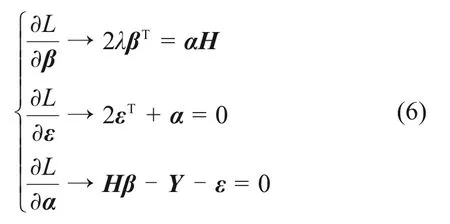
最后,可解得:

其中:I为单位矩阵。
2.3 粒子群算法
由于ELM 算法中输入层和隐含层连接权值和隐含层偏差均为随机产生,通常并不是模型的最优解,需经过多次训练才能得到较好的结果,且手动训练具有随机性,不易得到ωi和bi的最优值,因此,引入了粒子群算法(PSO)[13]对ωi和bi进行寻优。本研究中,该算法可以描述为:将ωi和bi作为一个D维搜索空间由s个粒子组成的种群中个体的坐标,粒子种群Z为
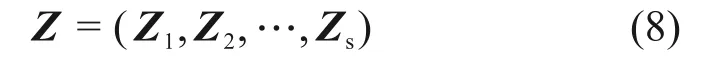
第i个粒子的位置Zi为

粒子坐标即为ωi和bi,将其代入到ELM 算法中,计算出粒子i对应位置Zi时的适应度,本研究中,适应度为Mn元素收得率预测值和实际值的均方误差。
粒子i的初始速度V为
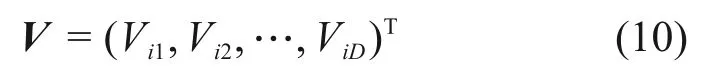
通过式(11)对粒子的位置进行更新,直到使适应度满足要求或达到最大迭代次数。

式中:k为迭代次数;η为惯性权重系数;为第i个粒子的个体最优值,为全体粒子的最优值;d=1,2,…,D;i=1,2,…,s;c1,c2为学习因子;r1∈rand(0,1),r2∈rand(0,1);α为 约 束因子。
惯性权重系数η的表达式为

式中:ηmax和ηmin分别为所设置的惯性权重系数初始值和结束迭代时的最小值;N为最大迭代次数。
PSO 算法通过迭代来计算粒子的全局最优值。为解决粒子群算法在迭代寻优过程中存在容易陷入局部极值的问题,提高算法的收敛速度,采用一种非线性权重方法来弥补标准粒子群算法的不足[14],这种算法可描述为

当k较小时,η接近ηmax,使算法拥有全局搜索能力;随着迭代次数增多,η以非线性速度递减,保证了算法局部搜索的能力,从而使算法能灵活地调整全局搜索与局部搜索能力。
IPSO-RELM 算法的训练流程如图2所示,通过IPSO 算法获取最优的输入层权值和隐含层偏差,以及引入正则化系数对隐含层和输出层的连接权值β进行约束,能够提高ELM 算法的预测性能。

图2 IPSO-RELM算法训练流程Fig.2 IPSO-RELM algorithm training process
3 Mn元素收得率预测模型
根据某钢厂120 t 转炉生产HRB400 钢种的实际生产数据,建立基于IPSO-RELM 综合优化算法的出钢合金化Mn元素收得率预测模型,再以此计算出钢过程硅锰合金的加入量。
3.1 模型输入项确定
为使模型有好的预测效果,需选择对冶炼过程起关键作用的因素作为模型的输入变量。根据出钢合金化过程化学反应机理,合金化过程Mn的损失主要由Mn同钢水中氧的反应造成,因此,钢水终点Mn 质量分数及氧质量分数对Mn 元素的收得率有直接影响,应作为模型的输入变量。在一般情况下,在冶炼终点不会对氧含量进行检测,而转炉冶炼终点的碳氧积通常维持在一个较为稳定的水平,因此,可以通过终点碳含量代替终点氧含量,作为模型的输入变量。此外,其他冶炼终点钢水成分及冶炼终点温度也会影响硅锰合金与钢水之间发生的化学反应。
为了能够更全面了解影响Mn元素收得率的因素,运用SPSS 统计分析软件,对影响Mn 元素收得率的工艺参数进行皮尔逊相关性分析,得到在0.05水平上显著相关的工艺参数及其皮尔逊相关系数,如表1所示。

表1 Mn收得率影响因素的皮尔逊相关系数Table 1 Pearson's correlation coefficient of influencing factors for Mn yield
通过相关工艺参数和Mn元素收得率的皮尔逊相关性分析得到的7个显著相关变量,其中包括冶炼终点钢水成分,而没有包括冶炼终点钢水温度。为使所建模型更好地反映冶金过程的规律,在上述7个工艺参数的基础上,增加冶炼终点钢水温度作为模型的输入变量来进行Mn 收得率预测研究。综上,通过冶金机理分析同数理统计分析相结合的方式,确定铁水Mn 质量分数、铁水P 质量分数、终点C 质量分数、终点Mn 质量分数、终点P质量分数、终点S质量分数、烧结矿加入量和冶炼终点钢水温度共8个变量作为本文模型的输入项。
3.2 模型构建
采集某钢厂120 t 转炉生产HRB400 系列钢种483组有效数据,其中,383组用于进行建模训练,剩余100 组用于对所建模型的预测能力进行测试,这100 组用于测试数据收得率的结果如图3所示。由图3可知,Mn元素收得率在84%~97%之内。

图3 Mn元素收得率实际值分布图Fig.3 Distribution of actual values of Mn yield
为避免所建模型的各输入项数据因数量级不同而影响模型的预测效果,通过式(14)对建模的数据进行归一化处理[15]。将作为模型输入项和输出项的原始数据映射到[0,1]范围内,以消除因输入项数据的数量级不同对模型产生的不利影响。
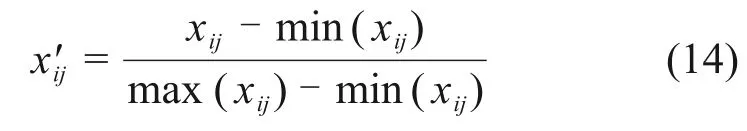
式中,xij为数据样本的原始数据;x'ij为经过归一化处理的数据;i表示第i个样本点;j表示第j个输入变量;min(xij)和max(xij)分别为原始数据样本中的最小值和最大值。
使用MATLAB软件建立IPSO-RELM模型,导入模型的输入项和输出项数据后,对模型进行训练。为获得最优的预测效果,需对IPSO-RELM 算法的参数不断进行调试,IPSO 部分的相关参数参考了文献[9]和文献[16]的研究成果,RELM部分需要调整的参数为隐含层节点数和正则化系数,参数的选取为逐一调整的方式,即固定其他参数,只调整1 个参数。IPSO-RELM 算法的特征参数如表2和表3所示。采用这些特征参数所建模型的预测效果最好。

表2 RELM模型的基本参数Table 2 Basic parameters of RELM model

表3 IPSO部分的基本参数Table 3 Basic parameters of IPSO
将Mn元素收得率的预测结果与实际检测结果对比,如图4所示。可见:Mn 收得率预测值和实验值吻合较好,两者相对误差的最大值为7%。Mn收得率预测值和实验值相对误差分布如图5所示。可见,相对误差±5%内的命中率为98%,相对误差±3%内的命中率为80%。
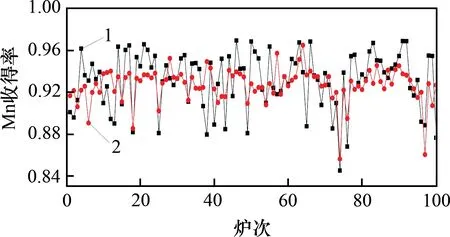
图4 Mn元素收得率预测结果与实际值对比Fig.4 Comparison of predicted Mn element yields with actual values
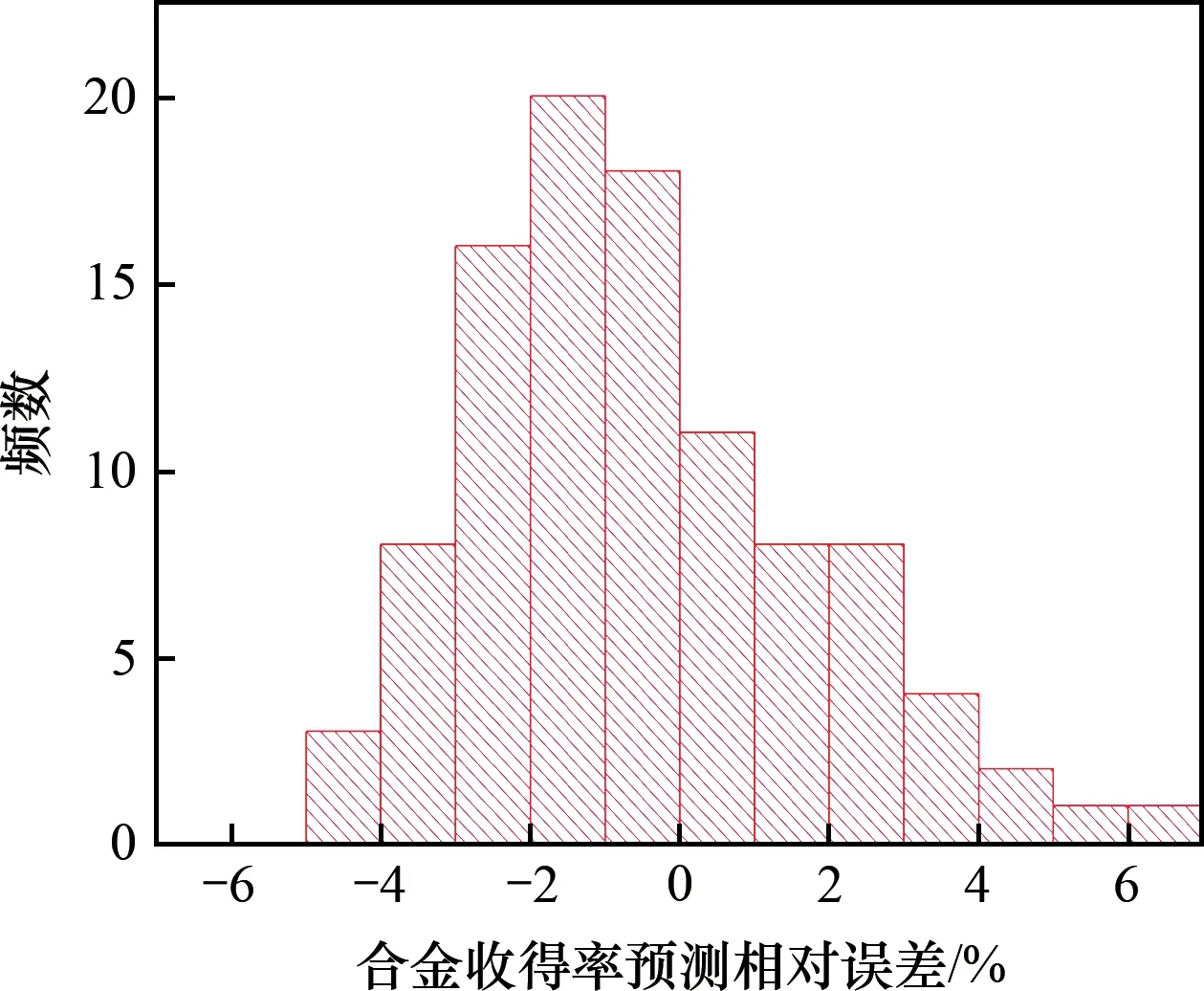
图5 Mn元素收得率预测相对误差Fig.5 Relative error of Mn element yield prediction
将IPSO-RELM 算法的预测结果与BP 神经网络预测和人工经验预测(即取收得率的平均值用于计算)进行预测性能对比,如表4所示,其中,RMSE 为均方根误差。由表4可见,2 种预测模型的计算结果均优于人工经验,且IPSO-RELM 算法的各项指标均优于BP神经网络的各项指标,尤其是在相对误差为±3%内的命中率差距较为明显,说明所建模型IPSO-RELM 算法具有更好的预测能力,更有助于实现钢中Mn 元素含量的窄成分控制。在实际生产中,可将模型通过编程语言编写为可应用程序,自动获得当前炉次影响Mn元素收得率的工艺参数,并代入模型中进行计算,即可得到当前炉次Mn元素收得率的预测值。

表4 3种预测方法预测能力对比Table 4 Comparison of prediction capabilities of three methods
3.3 合金加入量计算
得到Mn元素收得率的预测值后,基于此计算合金的加入量。该厂冶炼HRB400钢用于增锰的合金为硅锰合金,根据生产实际,推导得到硅锰合金的预测加入量Mp计算公式为

式中,t为钢水质量;ω0(Mn)为Mn 元素目标质量分数;ωend(Mn)为Mn 元素终点质量分数;Yp为Mn元素收得率预测值。
同时,基于Mn元素收得率的实际值计算硅锰合金的理论加入量MT:
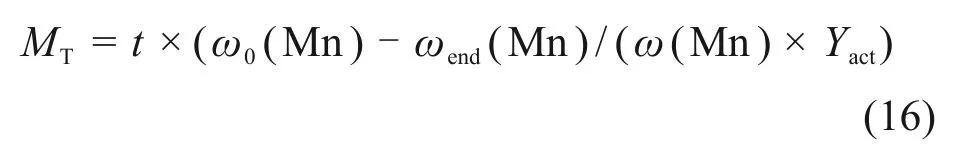
式中,Yact为Mn元素收得率实际值。
根据生产实际,进一步推导得出按硅锰合金的预测加入量加料时成品钢中Mn 元素的质量分数:

式中,ωp(Mn)为成品钢中Mn 元素质量分数预测值,%。
硅锰合金中Mn元素质量分数为66%。根据用于测试模型的100组数据计算硅锰合金的预测加入量和理论加入量,与硅锰合金的实际加入量进行对比,以判断模型的应用效果。
基于预测收得率计算得到的硅锰合金预测加入量与基于实际收得率计算得到的理论加入量对比如图6所示。由图6可知,硅锰合金的预测加入量和理论加入量吻合效果较好,误差在±100 kg 范围内的比例为92%。对于测试的100炉数据,根据式(17)计算得到的成品钢中的Mn 元素质量分数预测值如图7所示。可见:Mn质量分数均在1.20%~1.40%和1.40%~1.55%的要求范围之内。由此可知,成品钢中Mn 元素合格率为100%,能够精准指导实际生产。

图6 硅锰合金预测加入量与理论加入量对比Fig.6 Comparison of predicted addition amount and theoretical addition amount of silicon manganese alloy
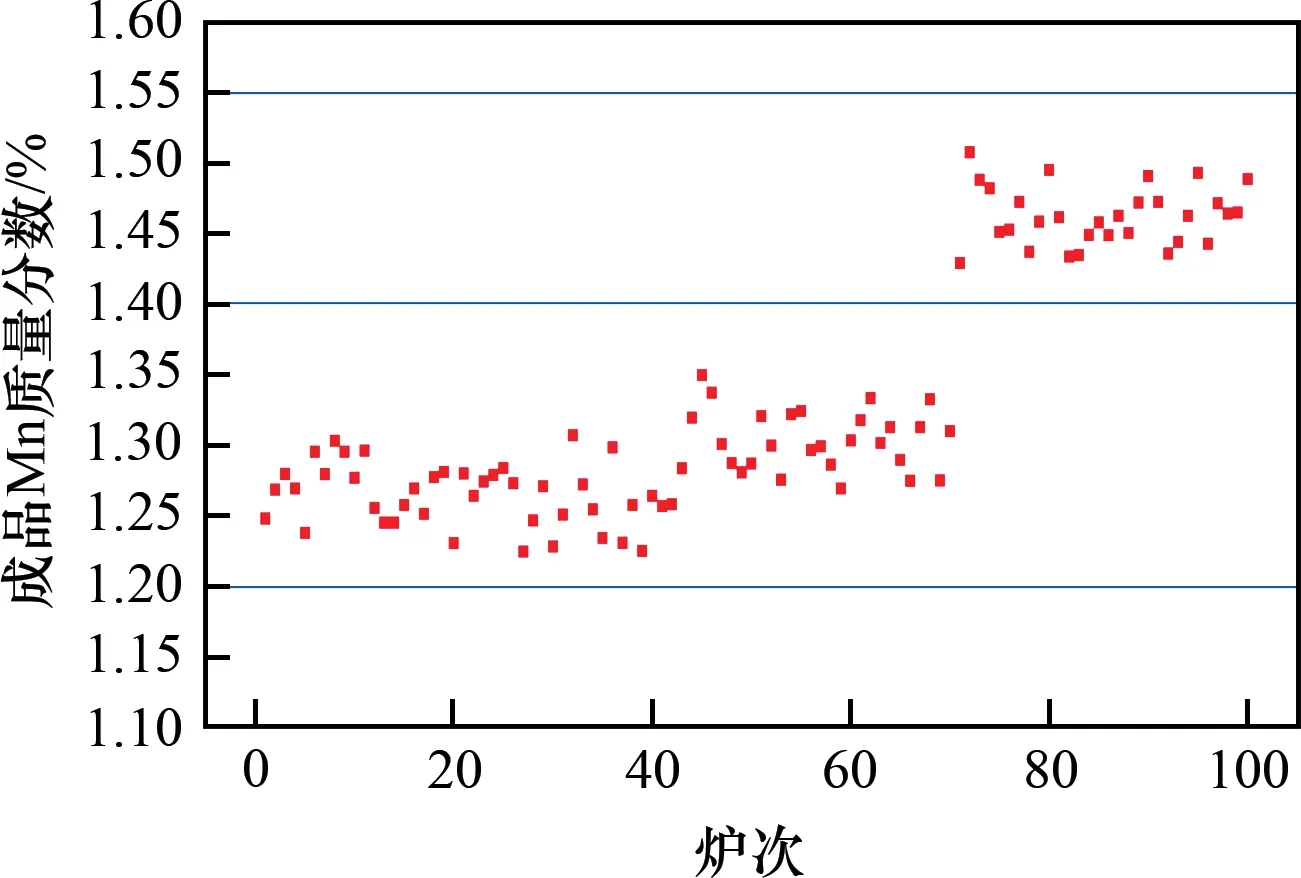
图7 成品钢中Mn元素质量分数Fig.7 Mn content in finished steel
在生产中,每炉次硅锰合金平均加入量为2 120 kg,而根据模型预测得到每炉次硅锰合金平均加入量为2 100 kg,降低了20 kg,该钢厂每个转炉平均每天生产钢水35 炉以上,共3 个转炉,添加硅锰合金的炉次超过80%,按照目前硅锰合金7 000 元/t 的市场价格计算可得,使用本模型在硅锰合金成本上每年可节省400万元以上,具有良好的经济效益。
4 结论
1)在极限学习机算法(ELM)的基础上,引入了正则化参数和改进的粒子群算法(IPSO)对模型进行优化,建立了基于IPSO-RELM 的Mn 元素收得率预测模型。
2)根据皮尔逊相关性分析结果和出钢合金化过程反应机理,确定了8 个影响Mn 元素收得率的工艺参数,作为预测模型的输入变量。基于IPSORELM 的Mn 元素收得率预测模型相对误差范围在±5%和±3%内的命中率分别为98%和80%,均方根误差为0.024,精确度高于人工预测和BP神经网络模型预测的结果。
3)基于Mn收得率预测值计算的转炉出钢过程硅锰合金加入量与理论加入量相比误差较小,并能使成品钢中Mn 元素合格率达到100%;模型预测的硅锰合金的加入量较基于人工经验的加入量平均每炉次减少了20 kg,每年可降低成本400 万元以上,说明该模型有较高的准确度和较好的经济效益,能为实际生产提供指导。
猜你喜欢
材料保护(2022年4期)2022-12-07
铝加工(2022年3期)2022-11-24
材料与冶金学报(2022年2期)2022-08-10
文萃报·周五版(2021年30期)2021-09-05
粉末冶金技术(2021年3期)2021-07-28
粉末冶金技术(2021年1期)2021-03-29
中国金属通报(2020年13期)2021-01-04
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
北京航空航天大学学报(2017年6期)2017-11-23
安徽冶金科技职业学院学报(2015年3期)2015-12-02
