
基于深度学习的关节点行为识别综述
2021-06-24 09:40薛盼盼王传旭
电子与信息学报 2021年6期
刘 云 薛盼盼 李 辉 王传旭
(青岛科技大学信息科学技术学院 青岛 266061)
1 引言
人类行为识别是计算机视觉的一个重要分支,在很多方面都有广泛应用,例如智能监控、人机交互、视频检索和运动分析[1]。目前,已有一些学者对行为识别进行了综述,比如朱煜等人[2]、罗会兰等人[3]、张会珍等人[4]、Zhu等人[5],这些综述文章无论是侧重于传统行为识别方法还是侧重于深度学习行为识别方法,所利用的信息多是RGB(Red(红色)、Green(绿色)、Blue(蓝色))数据和深度数据,没有专门针对关节点信息行为识别进行系统的归纳总结。近年来,关节点数据的获取随着低成本设备的发展更加容易,例如Microsoft Kinect[6]。随着深度学习的发展,利用关节点数据进行行为识别的研究取得了丰硕成果,但目前在该领域的系统归纳较少。与RGB数据和深度数据相比,关节点本身是人体的高级特征,不易受外观影响,同时能够更好地避免背景遮挡、光照变化以及视角变化产生的噪声影响,同时在计算和存储方面也是有效的[7]。利用关节点数据进行行为识别从发展历程上主要分为两大类:基于手工特征的方法和基于深度学习的方法。传统的利用关节数据进行行为识别是基于手工特征[8—10]。
关节点数据通常表示为一系列点的坐标向量,在不同的深度学习网络和算法中,关节点数据一般表示为伪图像、向量序列和拓扑图,不同的深度学习主干网络架构适合处理的数据表示方式也不同。通常来说,基于深度学习算法的改进主要是针对3个方面:数据处理方式、网络架构和数据融合方式。数据处理方式主要表现为是否进行数据预处理和数据降噪的方法,不同技术之间的数据融合方式也较为相似,对研究工作区分较大的是网络架构,因此本文也将根据主干网络架构的不同对关节点行为识别方法进行归纳总结。
2 基于深度学习的关节点行为识别
在深度学习背景下,关节点行为识别是针对已剪辑好的包含关节点位置数据的视频片段进行的特征提取和识别。常见处理关节点数据的深度学习方法有卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)、图卷积网络,对应的关节点数据的表示方式为伪图像、向量序列和拓扑图。本节按照主干网络将基于深度学习的关节点行为识别方法分为基于卷积神经网络的关节点行为识别、基于循环神经网络的关节点行为识别、基于图卷积网络的关节点行为识别和基于混合网络的关节点行为识别。图1为基于深度学习的关节点行为识别流程图。首先原始的关节点数据输入网络,其中横轴方向表示关节点的编号,纵轴方向的(x,y,z)表示关节点的3维坐标,竖轴方向表示时间帧,然后将其馈送到不同的网络模型中进行行为特征的提取,最终得到行为识别结果。
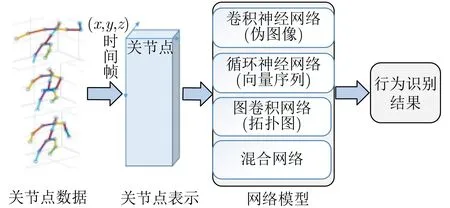
图1 基于深度学习的关节点行为识别流程图
2.1 基于卷积神经网络的关节点行为识别
CNN提供了一种有效的网络架构,可以在大型数据集中提取人体行为特征,这些特征可通过从数据中学习到的局部卷积滤波器或内核来识别。基于CNN的方法分别将时间帧和骨架关节的位置坐标编码为行和列,然后将数据馈送到CNN中进行行为识别,类似于图像分类。图2为基于卷积神经网络的关节点行为识别流程图。首先将原始的关节点数据输入到行为识别网络中,一般为了方便使用基于CNN的网络做特征提取会将关节点数据进行转置映射到图像中,其中行表示不同的关节,列表示不同的帧,(x,y,z)的3D坐标值被视为图像的3个通道,然后进行卷积操作。卷积展开的作用是将多维的数据1维化,该环节是卷积操作和全连接之间的常用过渡方式。全连接是在整个卷积神经网络中起到“分类器”的作用,也就是将学到的特征空间表示映射到样本标记空间。最后经过这一系列的操作就能够得到行为识别的结果。

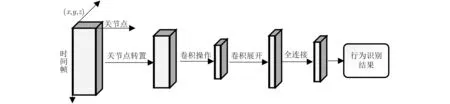
图2 基于卷积神经网络的关节点行为识别流程图
2017年Kim等人[12]提出一种残差时间卷积网络用于关节点行为识别,该网络框架是一种明确学习易于解释的3D人类行为识别的时空表示方法。残差时间卷积是在CNN的基础上设计的,网络由1维卷积的堆叠单元构成,并且能够在时间和空间上分配不同程度的注意力,但是该方法的识别精度一般。同年Li等人[13]采用双流CNN架构组合人体关节的位置和速度信息,同时引入了一种新的骨架变换器模块,实现了重要骨架节点的自动重新排列和选择,该方法较高的识别准确率证明了CNN模拟时间模式的能力。Liu等人[14]提出视图不变方法,不仅消除视图变化的影响还能保留原始关节数据中的运动特征,同时提出一种增强的骨架可视化方法用于视图不变的人体行为识别。Ke等人[15]于2017年最先将迁移学习应用于关节点行为识别中。同年Ke等人[16]又进一步将原始关节点数据转换为3个灰度图像片段,灰度图像是使用关节与参考关节之间的相对位置生成的,这与Li等人[13]的转换方法类似,Ke等人[16]所提出的方法首先将每个骨架序列转换成3个片段,每个片段由几帧组成,用于使用深度CNN进行空间时间特征学习,识别准确率提高了约4%。由于先前的研究并未完全利用人体行为中视频片段之间的时间关系,Le等人[17]在2018年提出了一种新的框架,该框架首先将骨架序列分割为不同的时间段,然后利用从细到粗的CNN架构同时提取关节点序列的时间和空间特征。该网络架构较浅,能够一定程度上避免数据量不足的问题,从表1可以看出,在SBU这种不是特别大的数据集上识别精度很好,达到了99.1%。Li等人[18]提出层次共现网络,首先将每个关节点进行单独的编码,用CNN独立地学习每个关节点的点水平特征,然后将每个关节都视为CNN的通道来学习层次共现特征,其行为识别准确率超越了大多数基于卷积神经网络的关节点行为识别方法。刘庭煜等人[19]针对生产车间工作人员行为识别与智能监控问题提出一种基于关节点数据的生产行为识别方法,首先将预处理好的人体关节点数据合并成人体行为的时空特征RGB图像,然后送入3维深度卷积神经网络中,该方法具有较高实用价值,并且在数据集MSR Action3D上的准确率可以达到84.27%。针对复杂的交互动作识别准确率不够高的问题,姬晓飞等人[20]提出一种基于RGB和关节点数据双流信息融合的卷积神经网络,其中RGB视频信息在送入卷积神经网络之前进行关键帧的提取缩短了训练时间,双流信息的融合提高了识别准确率。Yan等人[21]提出基于姿态的行为识别网络,该网络是一个简洁3维CNN框架,由空间姿态CNN、时序姿态CNN和动作CNN 3个语义模块组成,可以作为另一个语义流与RGB流和光学流互补,该网络框架较为简洁,但是准确率一般,在JHMDB数据集上的准确率仅为69.5%。Caetano等人[22,23]、Li等人[24]从设计新的骨架表示图像入手,其中Caetano等人[22]提出一种基于树结构和参考关节的3维行为识别的骨架图像表示方法,在JHMDB数据集上的识别准确率与Yan等人[21]所提出方法相同。Caetano等人[23]又引入了一种新的方法通过计算骨架关节的运动幅度和方向值来编码时间动态,使用不同的时间尺度来计算关节的运动值能够有效过滤噪声运动值。Li等人[24]是用集合代数的方式对骨架关节信息进行重新编码。Yang等人[25]提出了一个轻量级的网络框架,该网络由多个卷积神经网络组合而成,大大提高了速度,但是识别精度和其他方法相比较低。主干网络为卷积神经网络的关节点行为识别及代表性工作如表1所示。
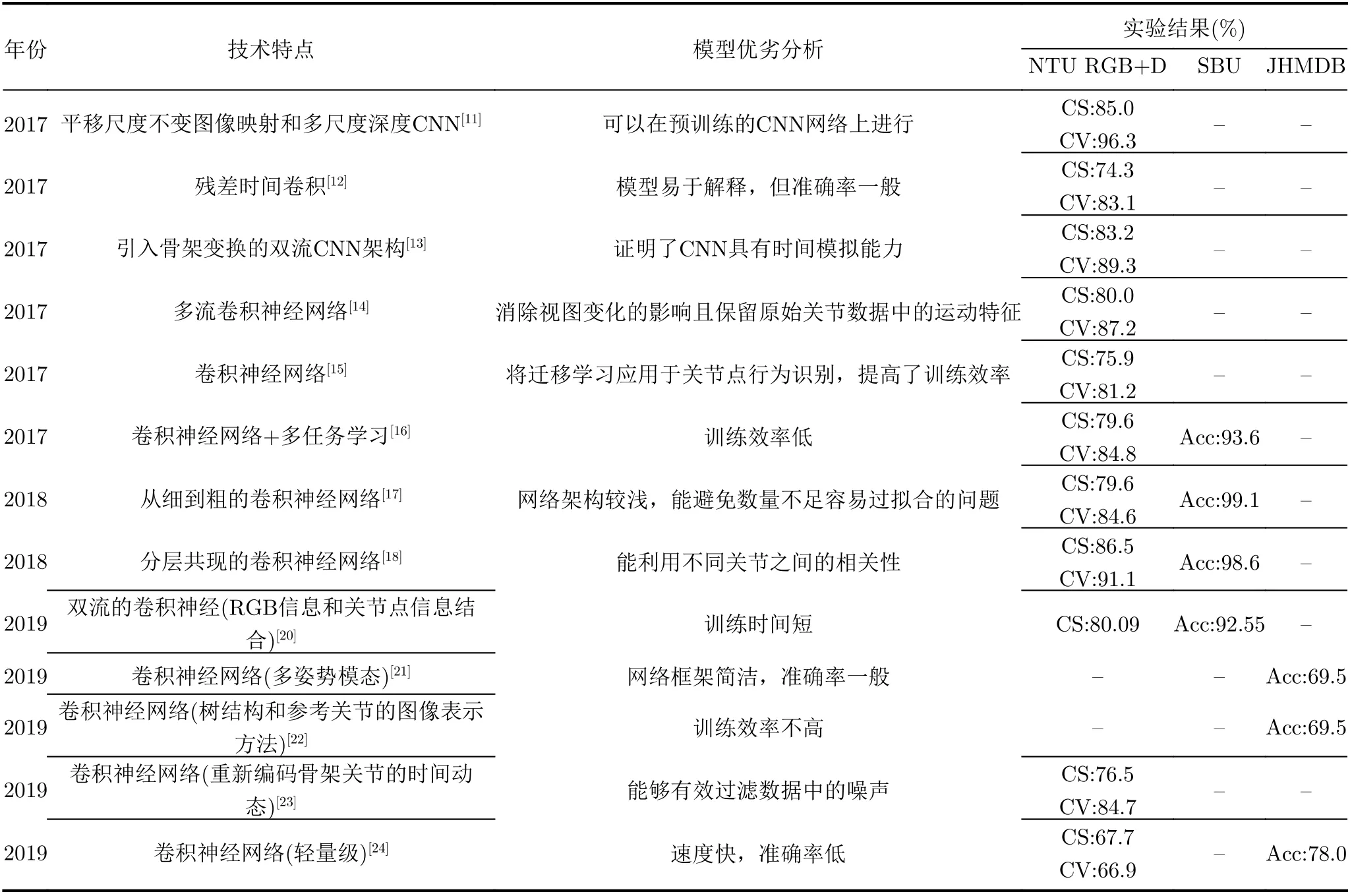
表1 主干网络为卷积神经网络的关节点行为识别及代表性工作
2.2 基于循环神经网络的关节点行为识别
循环神经网络(RNN)可以处理长度可变的序列数据,长短期记忆模型(Long Short Term Memory,LSTM)是一种变种的RNN,由于其细胞状态能够决定哪些时间状态应该被留下哪些应该被遗忘,所以在处理关节点视频这种时序数据时有更大优势,从而被较多地应用到关节点行为识别中,图3为基于循环神经网络的行为识别流程图。首先将关节点数据表示为向量序列,每一个向量序列包含一个时间帧上的所有关节点的位置信息;然后将向量序列送入以循环神经网络为主干的行为识别网络中;最后得到行为识别的结果。
Shahroudy等人[26]在2016年提出了NTU RGB+D数据集,同时提出了一种新的递归神经网络来模拟每个身体部位特征的长期时间相关性进行关节点数据的行为识别,可以更有效并且直观地保持每个身体部位的上下文信息,但是识别准确率不高,在NTU RGB+D数据集上跨表演者模式(Cross Sbuject,CS)的准确率是62.9%,跨视角模式(Cross View,CV)的准确率是70.3%。该文献为之后利用NTU RGB+D数据集进行行为识别研究的方法提供了对比的基准。Liu等人[27]提出一种基于信任门的长短期记忆模型(SpatioTemporal-Long Short Term Memory, ST-LSTM),信任门模块能够降低关节点数据的噪声,提高行为识别的准确率。Liu等人[28]又在ST-LSTM的基础上做了进一步的改进,在LSTM中加入一种新颖的多模式特征融合策略,使在多个标准数据集上的准确率(比如NTU RGB+D和UK-Kinect)都有较大提升,其中在NTU RGB+D数据集上的准确率提高了约3%。2017年Liu等人[29]提出全局上下文感知长短期记忆模型框架(Global Context-aware Attention Long Short Term Memory networks, GCA-LSTM),该框架主要由两层LSTM构成,第1层生成全局的背景信息,第2层加入注意力机制,更好地聚焦每一帧的关键关节点从而提高行为识别准确率。同年Liu等人[30]又在GCA-LSTM的基础上进行了扩展,加入粗粒度和细粒度的注意力机制,识别准确率在NTU RGB+D数据集上约提高了3%,在UK-Kinect数据集上提高了约1%。Zheng等人[31]提出了一种双流注意力循环LSTM网络,如图4所示。循环关系网络学习单个骨架中的空间特征,多层LSTM学习骨架序列中的时间特征。该双流的网络中,一个网络输入的是原始关节点数据,另一个网络输入的是成对关节之间的连线数据,关节点数据强调绝对位置,连线数据强调相对位置。在每个流中,首先增加每个关节点或关节连线数据的维数,然后发送给RNN用于提取单个骨架中的空间特征,同时生成一个可学习的掩码将更多注意力集中在骨架的潜在区分部分,再使用多层LSTM学习骨架序列的时间特征,最后以加权平均运算作为融合策略,以合并来自两个流的预测。该网络能更加有效地利用丰富的结构或关节信息,准确率较高。Li等人[32]提出了一个独立递归神经网络(Independently Recurrent Neural Network, IndRNN),不同层之间的神经元之间跨层连接,同一层中的神经元彼此独立,能更好地在网络较深的情况下防止梯度爆炸和梯度消失。王佳铖等人[33]针对车间作业行为识别问题提出了基于工件注意力的车间行为在线识别模型,不仅通过将人的关节点信息输入以门控循环单元为基础的模型对行为动作进行分类,还同时将工件的语义特征作为注意力融入进去,该方法有利于提高车间数字化管理能力,最终在自建数据集上准确率为88.5%,但是在标准数据集IXMAS上准确率仅为29.8%,这说明该方法适用性较差。主干网络为循环神经网络的关节点行为识别及代表性工作如表2所示。
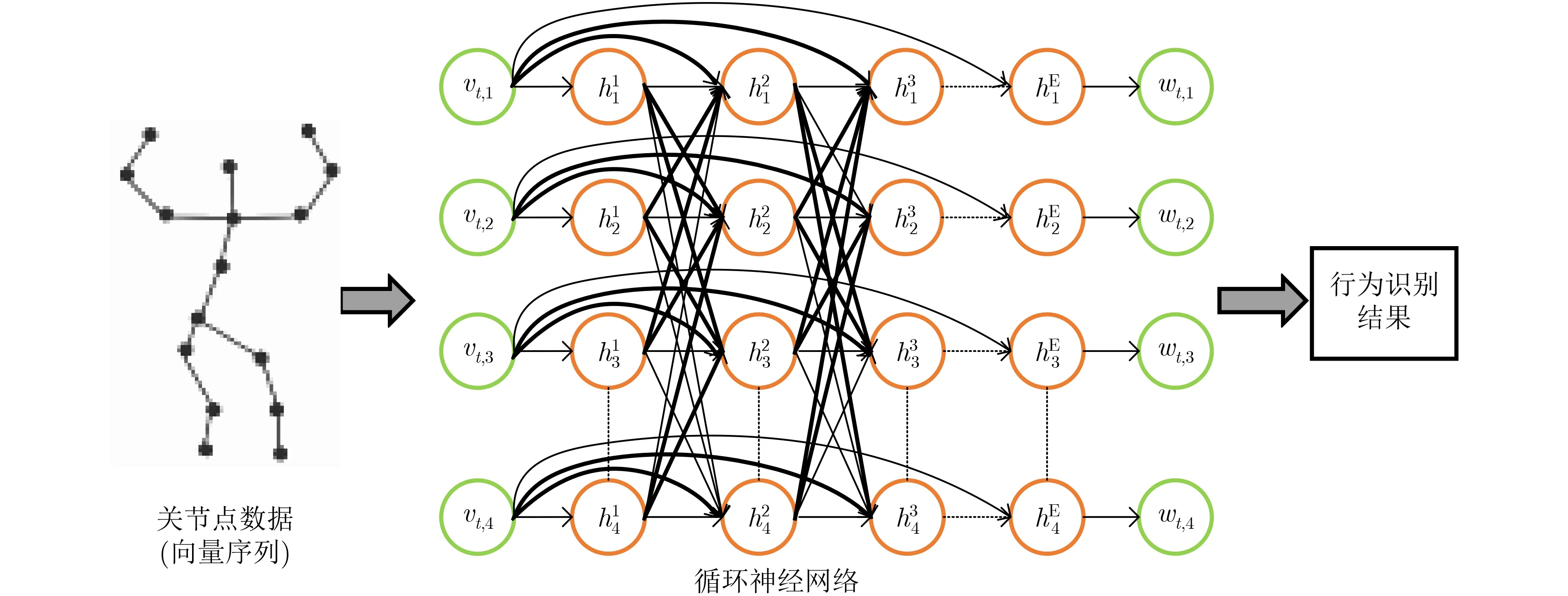
图3 基于循环神经网络的行为识别流程图
2.3 基于图卷积网络的关节点行为识别
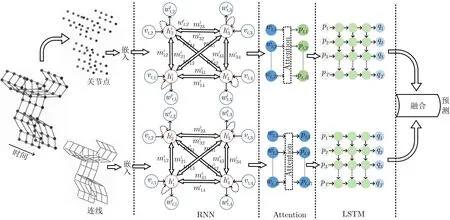
图4 双流长短期记忆模型框架[31]
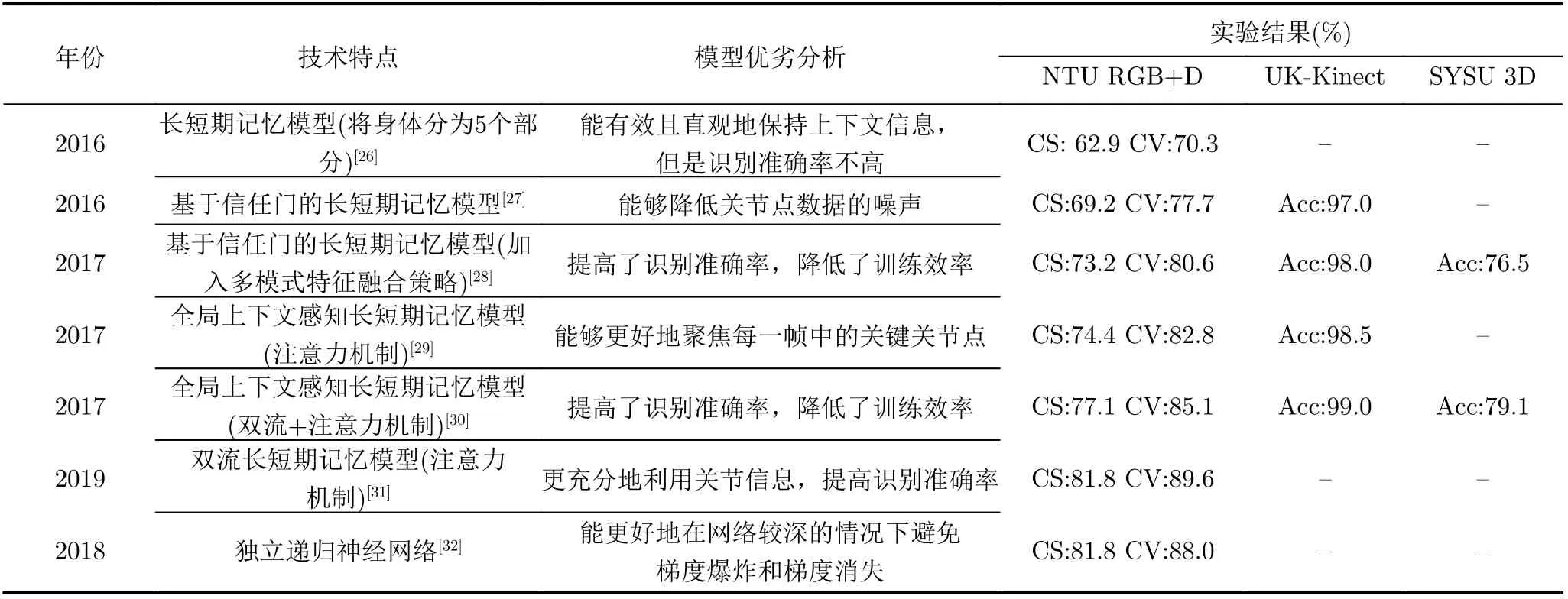
表2 主干网络为循环神经网络的关节点行为识别及代表性工作
人体骨架关节本身是一种拓扑图,卷积神经网络无法直接处理这种非欧几里得结构的数据,因为拓扑图中每个点的相邻顶点数目可能不同,难以用一个同样大小的卷积核进行卷积计算,而图卷积神经网络能够直接处理这种拓扑图。图5为基于图卷积网络的行为识别流程图。首先将关节点数据表示为拓扑图,在空间域上顶点由空间边缘线连接,在时域上相邻帧之间对应关节由时间边缘线连接,每个关节点的属性特征是空间坐标向量;然后将拓扑图输入以图卷积网络为主干的行为识别网络中,最终得到行为识别的结果。

Yan等人[34]使用图卷积进行关节点行为识别能够形成骨架关节的层次表示得到较好的识别结果,但由于感受野较小,难以学习无物理联系的关节之间的关系。Shi等人[35]、Li等人[36]都在试图克服这些问题,Shi等人[35]提出的双流自适应图卷积网络,骨架关节的拓扑图可以用BP算法自适应地学习,增加图形构建模型的灵活性。该双流框架不仅利用骨架数据的1阶信息(关节点信息),还利用骨架的2 阶信息(骨骼的长度和方向),在N T U RGB+D数据集上准确率较Yan等人[34]的方法提高了约7%。Li等人[36]提出了一种编码器-解码器的方法来捕获隐含的关节相关性以及使用邻接矩阵的高阶多项式获取关节之间的物理结构链接。Gao等人[37]将图形回归用于基于骨架的行为识别,对于图卷积而言,图形的表示很重要,图形回归的方法能够优化时空帧的基础图形,充分利用人体关节之间空间上物理和非物理的依赖关系以及连续帧上的时间连通性。Li等人[38]提出一种时空图卷积方法,能够将自回归滑动平均序列学习能力与局部卷积滤波器结合。对于每个帧构造无向图,其中仅按照人体关节的自然连接构造图,无时间连通性,在NTU RGB+D上的识别准确率CS和CV分别为74.9%和86.3%, 与其他方法相比准确率较低。Tang等人[39]提出深度渐进强化学习方法,该方法可以提取关键帧,然后用图卷积网络进行行为识别,行为识别的准确率一般,但是提高了训练效率。在实际应用中经常遇到关节点信息缺失的问题,大多数的基于关节点行为识别的模型都是针对完整的骨架数据,但是真实场景中可能会出现部分关节点信息缺失的情况,Song等人[40]提出针对不完整骨架的行为识别的激活图卷积网络,以提高图卷积网络在关节点行为识别中的鲁棒性。Peng等人[41]提出将神经体系结构搜索用于构建图卷积网络,该搜索策略中将交叉熵演化策略与重要性混合方法相结合,提高了采样效率和存储效率。Wu等人[42]提出将空间残差层和密集连接块增强引入时空图卷积网络,这种方法能够提高时空信息的处理效率,并且也容易与主流时空图卷积方法结合。Shi等人[43]在双流自适应图卷积网络[35]的基础上进行改进,将骨架数据表示为基于自然人体关节和骨骼之间运动依赖的有向无环图,准确率提升了约1%。Li等人[44]提出了一种新颖的共生图卷积网络,该网络不仅包含行为识别的功能模块,还包含动作预测模块,两个模块相互促进,显著提高了行为识别和动作预测的准确率,在NTU RGB+D数据集上CS和CV的准确率均超过90%。Yang等人[45]提出一个带有时间和通道注意力机制的伪图卷积网络,通过这种方式不仅能提取关键帧,还能筛选出包含更多特征的输入帧。行为识别性能优于大多数方法,但仍存在问题,因为帧数远远大于通道数,可能会导致省略一些关键信息。图卷积网络虽然能提高识别的准确率,但计算较复杂,计算速度也较慢,Wu等人[46]、Chen等人[47]更关注提高图卷积网络的速度,其中Wu等人[46]所提到的方法比Chen等人[47]所提到的方法产生高达两个数量级的加速。主干网络为图卷积网络的关节点行为识别及代表性工作如表3所示。

图5 基于图卷积网络的行为识别流程图
2.4 基于混合网络的关节点行为识别
与以上3种主干网络架构相比,基于混合网络的关节点行为识别的研究充分利用了卷积神经网络和图卷积网络在空间域上特征提取的能力以及循环神经网络在时序分类的优势,能够得到较好的行为识别结果。图6为基于混合网络的关节点行为识别流程图。首先将原始的关节点数据根据不同的混合网络的需要进行相应的关节点表示;然后将其馈送进混合网络中,混合网络的主干网络一般会包含卷积神经网络、基于循环神经网络、图卷积网络中的两个或更多;最终将提取到的行为特征进行行为分类得到行为识别结果。
Zhang等人[48]提出了一种视图自适应方案,根据该方案设计了两个视图自适应神经网络,分别基于LSTM和CNN,视图自适应子网会在识别期间自动确定最佳的虚拟观察视点。视图自适应神经网络由两大部分组成,一个是由视图自适应子网和主LSTM组成的视图自适应循环网络,将新的视点下的关节点表示送入主LSTM网络确定行为识别,如图7所示;还有一个是由视图自适应子网和主CNN组成的视图自适应卷积网络,将新的观察视点下的关节点表示送入主CNN中确定行为类别。分阶段训练完之后,再将两部分网络的分类分数融合预测。该方法不仅减弱了视角不同对行为识别结果的影响,同时利用了CNN擅长提取空间域特征和循环神经网络擅长提取时间域行为特征的优势,得到了较好的行为识别结果。Hu等人[49]不仅考虑时间域和空间域行为特征的提取,还提出了一种残差频率注意力方法,主要用来学习频率模式,该文献所提出的网络框架可以看作CNN的变体和图杂交方法结合,取得了较高的行为识别准确率。Si等人[50,51]、Gao等人[52]都是采用图卷积和LSTM相结合的方式进行关节点的行为识别研究,图卷积更加擅长空间域的特征提取,LSTM更加擅长时间域的特征提取。Si等人[51]所提出的注意力增强图卷积LSTM网络(Attention enhanced Graph Convolutional Long Short Term Memory network, AGC-LSTM),不仅可以提取空间域和时间域的行为特征,还通过增加顶层AGC-LSTM层的时间接受域来增强学习高级特征的能力,从而降低计算成本。Gao等人[52]提出基于双向注意力图卷积网络,利用聚焦和扩散机制从人类关节点数据中学习时空上下文信息,取得了非常好的实验结果,其中在NTU RGB+D数据集上的准确率达到国内外领先水平。Zhang等人[53]将关节的语义(帧索引和关节类型)作为网络输入的一部分与关节的位置和速度一同馈送进语义感知图卷积层和语义感知卷积层,通过实验证明,利用语义信息能够降低模型复杂度和提高行为识别的准确率。利用关节点数据进行行为识别时,骨架关节的复杂时空变化纠缠在一起,Xie等人[54]提出一种时间空间重新校准方案来缓解这种复杂的变化,这是第1次为关节点行为识别开发RNN+CNN网络框架。Weng等人[55]提出一种可变形姿态遍历卷积网络,在执行遍历卷积时通过考虑不同权重的上下文关节来优化每个关节的卷积核大小,对嘈杂的关节更具有鲁棒性,然后将学习的姿势馈送到LSTM共同优化姿势表征和时间序列。主干网络为混合网络的关节点行为识别及代表性工作如表4所示。
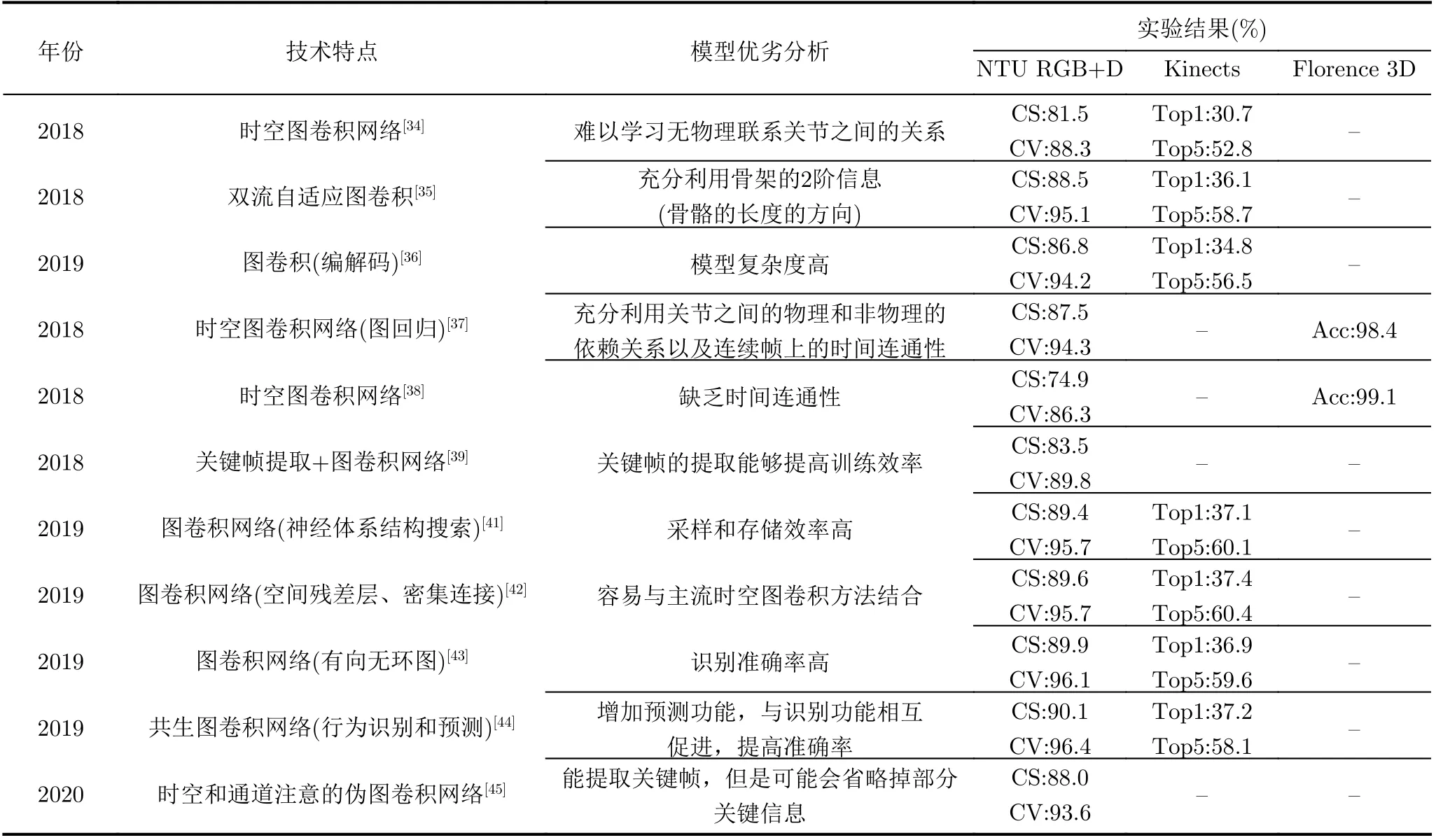
表3 主干网络为图卷积网络的关节点行为识别及代表性工作
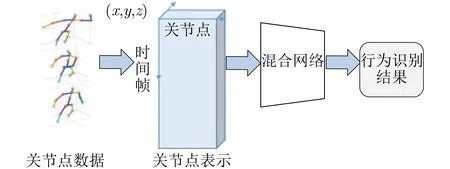
图6 基于混合网络的关节点行为识别流程图

图7 视图自适应循环神经网络[48]

表4 主干网络为混合网络的关节点行为识别及代表性工作
3 关节点数据集发展及评估标准
3.1 关节点数据集发展及简述
近年来,深度学习的快速发展使数据驱动学习在行为识别领域取得了较好的成果,大规模的数据集的提出对深度学习的发展有着重大意义。在基于深度学习的关节点行为识别的研究中,相关数据集的发展也同样起着较大的推动作用。在关节点行为识别研究中常用的数据集主要分为两大类,一类是利用Kinect摄像机获取多模态行为识别数据集[9,26,56—69],另一类是从包含RGB信息的行为识别数据集[68,70,71]中用OpenPose工具箱估计每个关节点的位置[72]。早期的数据集规模较小,相对而言更适用于在深度学习出现之前的手工提取特征方法。同时早期的数据集还有其他的局限性,首先,由于表演者的数量较少和表演者的年龄范围较窄导致行为的内部变化非常有限;其次,行为类别数量较少,通过找到简单的运动模式就可以容易地区分每个行为类别,使分类任务的挑战性降低。为了满足深度学习的需求,大规模数据集相继出现。新加坡南洋理工大学在2016年公开了NTU RGB+D数据集,为国内外进行行为识别研究提供了数据支撑;DeepMind公司在2017年公开了Kinects数据,该数据集从You-Tube上收集,以HMDB-51[71]和UCF-101[73]为基准,具有较大的规模和较高的质量。表5列举了常用来做关节点行为识别的多模态数据集,接下来重点介绍在关节点行为识别研究中常用的大规模数据集[26,68,69]。
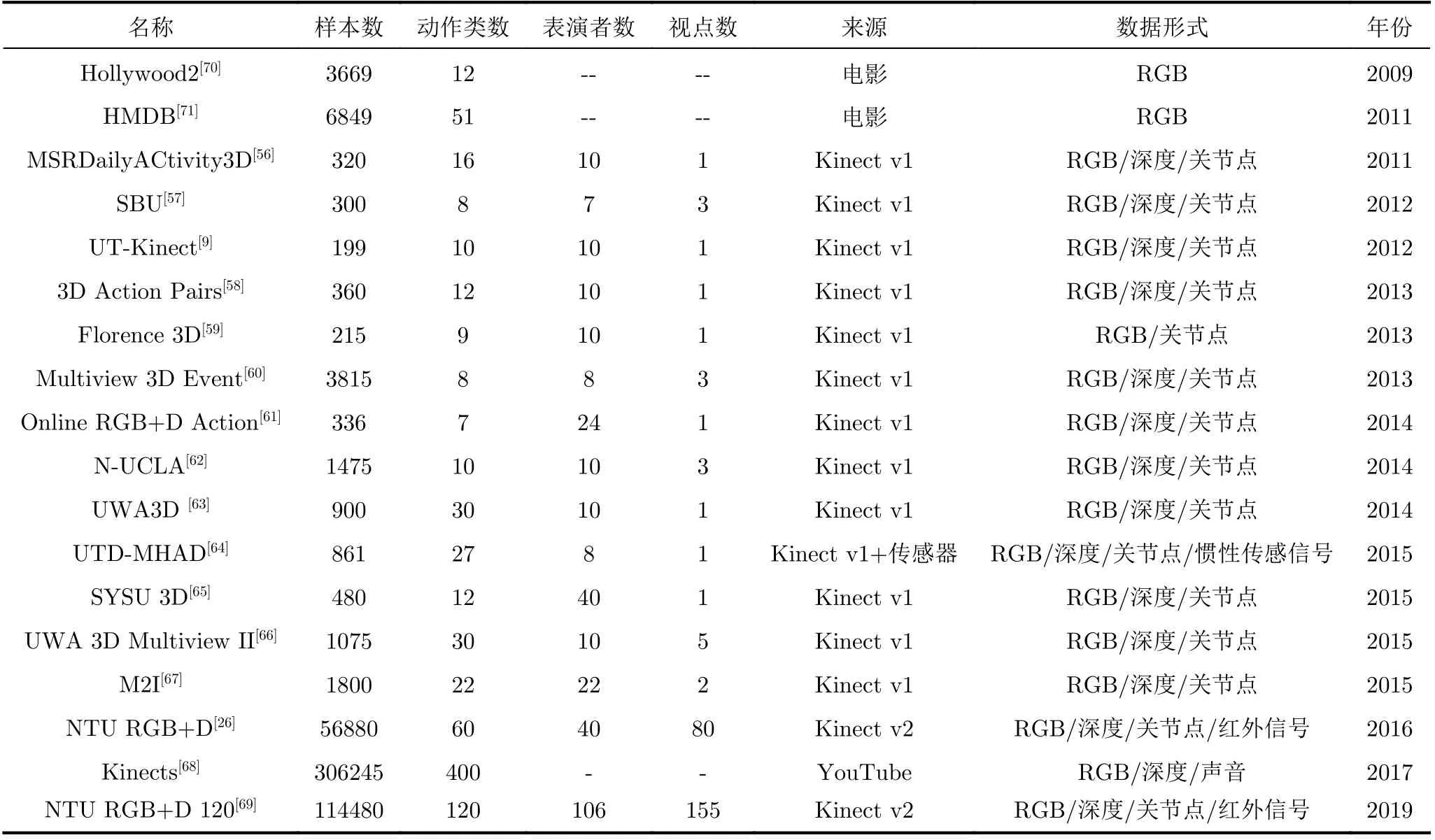
表5 关节点行为识别数据集简介
NTU RGB+D数据集是由新加坡南洋理工大学制作并整理而成的,于2016年公开。深度传感器的出现使获取物体和人体有效的3D结构的成本大大降低[74],该数据集是由3个深度摄像机Microsoft Kinect v2在室内拍摄完成的。3个摄像机的水平方向一致,角度分别为—45°, 0°, 45°。包含了25个主要的身体关节的3D位置,如图8所示[26],关节点位置对照表如表6所示。数据集包含有超过56000个视频样本和400万帧,有40个表演者,60种不同的动作类,涉及日常动作40项(包括饮酒、饮食、阅读等)、交互动作11项(包括拳打脚踢、拥抱等)、与健康相关的动作9项(包括打喷嚏、蹒跚、摔倒等),数据集示例如图9所示[26]。该数据集有302个样本关节点数据不完整,在进行关节点行为识别时可以忽略。
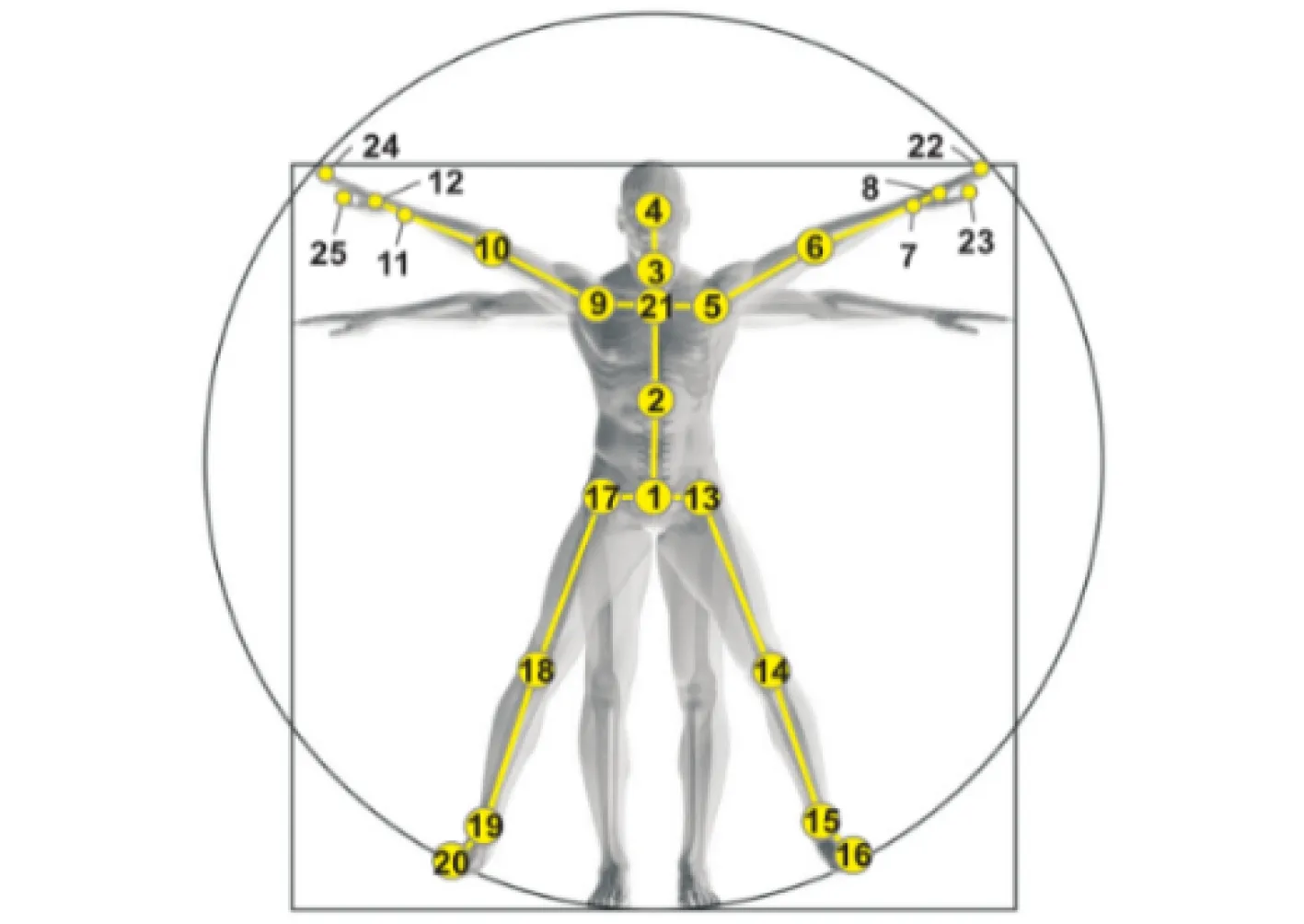
图8 人体关节点示意图[26]

表6 关节点位置对照表
Kinects数据集取自YouTube视频,每段动作剪辑约10 s,包含400个动作类,每个动作类由400~1150个视频剪辑。动作涵盖范围较广,包含人与物的交互、人与人的交互、单人动作。利用公开的Openpose工具箱能够在Kinects数据集提取18个关节点位置(X,Y,C),其(X,Y )为关节点的2维位置坐标,C是位置坐标的置信度,关节框架被记录为18个元组的数组,图10为Openpose工具箱提取关节点示意图[72]。
NTU RGB+D 120数据集在NTU RGB+D数据集的基础上扩充到了120个动作,动作的种类未发生变化,每个动作类包含的动作个数均有增加,日常动作增加到了82个(包括吃、写、坐下、移动物体等),与健康有关的动作增加到了12个(包括吹鼻子、呕吐、蹒跚、跌倒等),交互的动作增加到了26个(包括握手、推、打、拥抱等)。与NTU RGB+D数据集相比,该数据集行为识别的难度有所增加。
3.2 关节点数据集评估标准
常见行为识别准确率的评估标准为Top1和Top5。模型预测某个行为类别的准确率时,如M2I数据集包含行为类别有22个,模型会给出22个按概率从高到低的类别排名。其中Top1的准确率为排名第1的类别与实际结果相符的准确率,Top5的准确率为排名前5类别中包含实际结果的准确率。一般一种模型在一个数据集上实验结果的准确率Acc即为Top1的准确率。NTU RGB+D和NTU RGB+D 120数据集经常出现CS和CV两种测试模式,其中CS为跨表演者测试中Top1的准确率,CV为跨视角测试中Top1的准确率。Kinects数据集较为特殊,对其而言Top5比Top1更有说服力,因为该数据集中一段视频可能包含多个动作但是标签仅标注一个动作,因此在表1—表4中Kinects数据集上的实验结果同时包含Top1和Top5。

图9 NTU RGB+D数据集示例[26]

图10 Openpose提取关节点示意图[72]
4 总结与展望
本文通过对基于深度学习的关节点行为识别进行总结和分析,得出以下结论:
(1) 关节点数据一般有3种表示方式:伪图像、向量序列和拓扑图。卷积神经网络适合处理伪图像,循环神经网络适合处理向量序列,图卷积网络适合处理拓扑图。从表1—表4可知,在NTU RGB+D数据集上仅包含图卷积的方法比仅比包含卷积神经网络的方法平均准确率高约5%,比仅包含循环神经网络的方法高约10%,证明了图卷积在关节点行为识别方面的优越性,这是因为人体关节点所构成的骨架实质上就是图结构,但是通常包含图卷积的网络也更复杂。仅包含循环神经网络方法的识别准确率相对最低,因为行为动作在空间域上的变化幅度要大于在时间域上的,而循环神经网络更适合处理时序性问题。基于混合网络的关节点行为识别方法通常具有两种或多种主干网络的优势其准确率也较高,但同时网络的复杂度也较高。
(2) 目前关节点行为识别方法在标准数据集上的准确率有大幅度提高,以NTU RGB+D数据集为例,已经从CS和CV的准确率分别为62.9%和70.3%[26]提升到了90.3%和96.3%[52]。但实际应用场景中可能会出现关节点的部分数据缺失或需要较高的训练和测试速度以实现实时性,有些学者针对这些问题提出了解决方法,比如缺失关节点的激活[40]或者构建轻量级的网络[24],但目前准确率都一般。也有些研究是针对特殊的应用场景,比如刘庭煜等人[19]针对车间工人行为识别,虽然在特定的场景中准确率较高,但适用性较差。
综合当前基于深度学习的关节点行为识别方法的研究现状,对今后的研究做出如下展望:
(1) 随着5G时代的到来,数据信息的主要载体已经从PC转换到移动端,这有利用将关节点行为识别应用于移动端。但是目前利用关节点进行行为识别的网络模型均较为复杂,其中以循环神经网络和图卷积网络最为明显,难以在实际应用中推广,因此期待未来能够提出更加轻量级并且准确度较高的网络。
(2) 关节点行为识别多应用于无人驾驶、机器人以及医疗监控等领域,行为识别系统在行为动作发生之后对行为进行识别。但是在某些应用场景中人们更希望能够进行行为预测,比如当无人驾驶系统预测到一个人有闯红灯的行为时可以及时调整驾驶轨迹。Li等人[44]就利用关节点的行为预测进行了深入的研究,但是准确率有待提高,这也是未来的研究方向之一。
(3) 目前关节点行为识别的训练数据多是剪辑好的视频帧,无需进行动作检测,但是在实际应用中,能够识别行为发生的时间段是有必要的,因此将关节点的动作检测与行为识别相结合也有较高的研究价值。
(4) 深度学习需要大量的样本进行训练,但对数据集进行准确有效的标注是需要耗费大量人力物力的。无监督学习可以利用无标签的数据进行训练,这将解决数据集标注所面临的问题,具有较大的研究价值。
(5) 虽然很多关节点行为识别方法在标准数据集上识别的准确率很高,但是这些方法都是针对无遮挡的情况进行的,在实际的应用场景中可能会出现部分关节点被遮挡的情况,现在的大部分方法在这种情况下的识别效果并不好,因此提高在有遮挡情况下的识别准确率有利于关节点行为识别与实际应用的结合。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
科学技术创新(2021年19期)2021-07-16
沈阳航空航天大学学报(2020年6期)2021-01-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
中国新技术新产品(2020年5期)2020-05-06
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
军营文化天地(2017年6期)2017-06-28
智能系统学报(2017年1期)2017-06-01
中国煤层气(2014年3期)2014-08-07
