
基于评论有用性投票的低频关键词提取方法研究∗
2021-06-29 08:41陈艳平
计算机与数字工程 2021年6期
刘 莎 陈艳平
(贵州大学 贵阳 550025)
1 引言
近些年来,随着互联网及电子商务平台的迅速发展,在线评论的有用性成为影响消费者决策的一大重要影响因素。在线评论是用户在体验商业产品和服务后的评估和体验,并为其他用户提供有价值的信息。用户可以通过在线评论了解商家的产品和服务,这有助于他们做出更好的消费决策,并降低产品和服务的参考成本。著名Jupiter Re⁃search公司通过多年调查分析,研究发现75%的消费者在餐厅用餐、旅游住宿、购买商品、亲子游乐场等多项消费之前,会参考互联网上的用户体验后的评论信息。国内也一样,比如淘宝、京东、美团、去哪儿等平台。
由于网络的开放性,发布在线评论的成本很低,许多垃圾邮件和虚假信息使得评论中的信息质量参差不齐,导致评论数量多,噪音大,难以区分,而且评论方式有很多,语言表达也不同,有些评论并不能给我们带来有用的参考价值,如何从大量评论中找到有价值的信息是我们研究的重点和难点。
文中提出了评论有用性投票的低频关键词提取方法。主要是从餐厅的评论中找出低频关键词,通过研究有用性投票来给消费者提供更多的选择和决策,而不是仅仅看用户给这家餐厅打的星级来作为评判指标(一般是五颗星)。因此,低频关键词的识别和提取就成了我们所面临的一大困难,它主要存在以下三个问题。
1)低频关键词的各个部分之间的内聚性弱,无法计算它们之间的相互信息。
2)由于低频关键词之间的组合从概率的角度评价具有随机性,难以采用标注的方式来使用机器学习的方法。
3)低频关键词也存在表示方面的问题,由于出现次数少,缺少上下文信息,难以通过现有表示方法(如:Word2Vector)来对其进行表示。
基于以上困难,目前仍没有较多关于评论有效性投票方面的研究,这将成为我们重点研究的课题,它能更好地解决目前存在信息量大、查找感兴趣的主题困难,后期信息利用也很困难的问题,便于用户在信息化时代更加容易且方便地查找有用性信息。
2 相关工作
2.1 在线评论有用性投票
关于在线评论有用性投票方面的研究,大多是管理学、经济学、社会学研究的相对较多。在国外,2011年,Lotte M.Willemsen[1]等通过分析Amazon.com上发布的经验和搜索产品的评论,发现此内容分析的见解和消费者收到的评论的比例相关联。2012年,Racherla,Pradeep等通过实验发现评论者和评论者的特征对于理解评论的有用性至关重要。在国内,2010年,郝媛媛[3]等从文本特征、建立模型并进行有用性分类提出了在线影评的有用性。2013年,廖成林[4]等认为评论的等级和评论者的排名与评论的有用性成反比,评论的深度和购买经验与评论的有用性成正比。
2.2 低频关键词提取
在国外,较早就开始研究关键词提取了。美国纽约大学开展的Linguistic String项目[5]开始于60年代中期并一直延续到80年代。该项目的主要研究内容是建立一个大规模的英语计算语法库,与之相关的应用是从医疗领域的X光报告和医院出院记录中抽取关键词。2008年,Frans Coenen[6]研究了许多替代关键词生成方法和短语构建策略,结果表明该方法使得分类准确性提高了。在国内,2007年,张敏[7]等提出了以KeyGraph算法思想,构建词网络的自动抽取关键词的理论机制,并通过实验得到了较好的实验效果。2014年,黄磊等[8]又提出了改进方法,即DI-TTFIDF算法,它的准确度高于传统的TTFIDF算法。
3 模型方法
本文中,我们讨论低频关键词的识别及提取。将数据集文档中的评论先分割成句子,通过神经网络模型训练、聚类生成关键词的词义结构,紧接着进行词义结构排序、关键词抽取,再根据餐厅评论的主题相关性对相同短语模式中的低频关键词排序,从而达到我们所要提取的低频关键词。具体框架如图1。
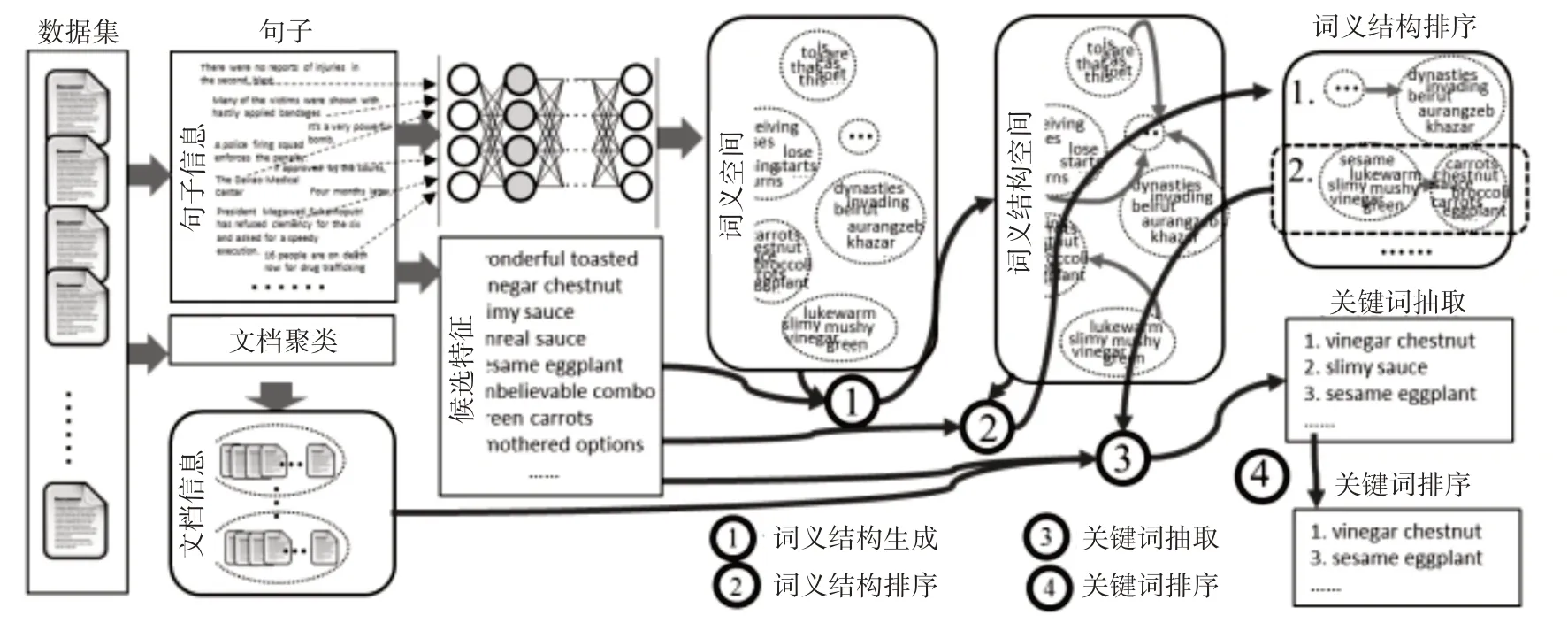
图1 低频关键词提取框架图
3.1 词义结构生成
词义结构生成基于自然语言处理中的词聚类或分类的方法。常用的有以下三种:1)利用外部知识库(如WorldNet、HowNet和Cyc等)直接获得词的语义类别。该方法的缺点是知识库构建困难且难以更新。2)利用机器学习中的分类器识别单词的词类。该方法需要标注一定数量的数据集,对分类器进行训练。当单词的类别比较多时,该方法难以适用。3)采用无监督聚类的方法。该方法利用大规模无标注的数据集进行训练,利用单词出现的上下文信息将单词自动聚为不同的类别。相对来说,聚类的方法性能较弱,但是训练数据容易获取,词类别数量的选择也比较灵活。
我们采用的是基于自然语言处理中的词聚类方法,将评论中单个的词映射到一个带语义的向量空间。在该空间中,语义上相近的词其欧拉距离也很接近。然后,利用欧拉距离进行单词的聚类,属于同一词类的词,语义上也相近。每个词类用一个标签表示,代表该类词在语义空间中的语义。然后,利用标签替换候选关键词中的所有单词,生成关键词的语义结构。具体表示由式(1)给出:
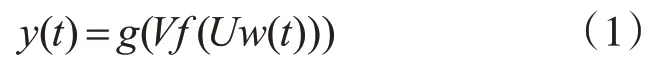
其中,w(t)和y(t)分别表示输入层和输出层,s(t)=f(Uw(t))表示隐藏层。
3.2 词义结构排序
在文档中,相对于低频关键词,其词义结构具有较高的出现频率,可以用来判断一个语义机构是否有效。通过词义结构生成,可以得到关键词的语义结构,表示关键词的使用模式。如果词聚类的个数为K,允许的语义结构长度为n,则可能参数的语义结构的数量为Kn个。为了减少噪音,需要对其进行排序。
在所有评论中,低频关键词的出现次数非常少,上下文信息稀疏。每个低频关键词所对应的词义结构包含很多关键词。语义结构的排序可以使用多种排序方法。我们主要采用每个语义结构所对应的关键词的数量作为评价的指标。
3.3 关键词排序
因为低频关键词的上下文信息稀疏,难以利用其上下文信息对单个词义结构下的不同低频关键词进行排序。我们采用低频关键词中的各个单词在文档集中的上下文信息对低频关键词进行排序。比如餐厅评论中出现“这家餐厅的花生很好吃…牛奶的味道也很好。”假如“花生牛奶”为低频关键词,出现频率低,上下文信息稀疏。但是单词“花生”和“牛奶”在文档中的出现频率却比较高。利用这些单词在整个文档集中的上下文信息,可以根据其同文档主题的相关性进行排序。为了对低频关键词进行排序,首先生成该关键词对应的向量Vi,该向量由式(2)给出:

其中Pi表示当前排序的关键词,Wi表示构成该关键词中的单词,表示单词Wi在文档集中的上下文信息(该词多次出现的周围的词特征)所构成的向量。则,对Vi的评分可以由式(3)给出:
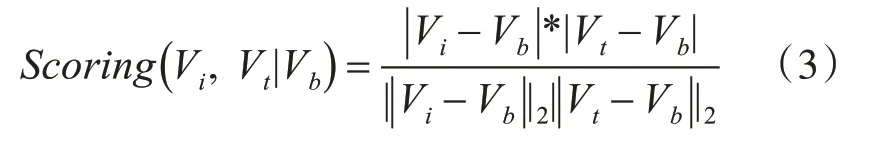
其中Vt为文档聚类后人工选择的文档簇所生产的词频向量,表示和餐厅有用性相关的主题。Vb表示用全部文档集中的词频生成背景向量。分别计算每个关键词对向量Vi的评分,即可得到低频关键词的排序。
4 实验及结论
4.1 实验数据
本次实验我们主要从Yelp.com中提取数据,Yelp是美国最大的商户点评网站,其中包含各地餐馆、购物中心、酒店、旅游等23个领域,用户可以在Yelp网站中给商户打分,提交评论,交流购物体验等,每条评论都会有一个分数表明其有用性。
Yelp数据包含984,502条餐厅评论和584,762条非餐厅评论,我们主要聚焦在Yelp数据集中与餐厅有关的评论,并根据收集的评论的有用性将其分为两类:第一类,有用性评论,其中有用值>0有449,437条评论;第二类,无用性评论,其中有用值=0有535,065条评论。
4.2 实验过程
文中我们主要通过候选词生成、短语过滤、短语评分这三个方面来进行实验。最终通过判断提取出的低频关键词占评论里有用性比例,看它是否对用户选择和决策具有有用性,从而验证我们的实验效果。以下将分为三部分进行详细介绍。
4.2.1 候选词生成
在现代生成语言学中,很难将功能词与内容相关的词分隔开来。我们的主要工作是将功能词作为边界形成候选词。具体步骤如下:
1)在文档中,首先将每条评论通过标点符号来进行分隔,比如{,。;!?:};
2)LIWC2015词典中包含了19,281个停用词,我们用LIWC2015词典来检查分隔开的评论,如果在词典中,就将其作为边界以生成候选短语;
3)输出生成的候选短语以获得整个语料库的候选短语。
在整个评论中,会出现一些拼写错误、符号错误或使用不当及地方方言识别等问题,为了减少噪音,降低实验复杂度,我们通过lexicon词典来检查是否会出现上述问题(lexicon词典的单词列表包含67,725个单词),如果候选短语不在此列表中,直接将其丢弃。我们通过以上两大筛除步骤,最终Yelp数据集中短语共1,078,414个,出现次数为31,093,419次。短语类型的分布如图2所示。
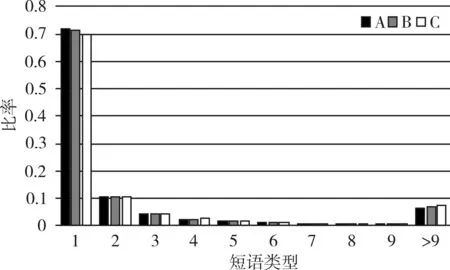
图2 短语类型分布
其中A表示整个语料库,B表示餐厅有用性的数据评论,C表示餐厅无用性数据评论。从中可以看出候选短语出现超过9次所占的比率分别是6.27%、6.98%、7.49%,而只出现过1次所占的比率分别是71.7%、71.12%、70.01%。由此表明删除低频短语将会失去很多有用的的信息,不利于更好地发掘文本信息,也不利于餐厅评论有用性投票的评估。
4.2.2 短语过滤
本次实验主要研究餐厅的评论有用性。为了验证低频关键词的含有很多重要的信息和很大的研究意义,以下将采用三个过程来进行候选短语的过滤。
1)高频率的单词可以增加表示的精确性。因此,为了支持词分组,将删除少于N(本文N=300)次单词出现的短语。
2)实验中,为了简化讨论,只研究过滤后评论包含两个词构成的短语。
3)由于实验目标是研究低频关键词,因此,只讨论出现一次的短语。
通过以上短语过滤,最终在A、B、C三个数据集上分别剩余327,345、120,828、78,247个短语,它们所占比率分别是30.35%、25.61%、23.58%。最终过滤结果如图3所示。
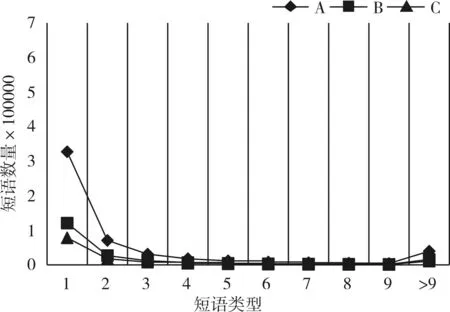
图3 短语过滤分布
4.2.3 短语评分
短语评分对于整个关键词提取非常重要。通过以上短语过滤,最终得到在文中只出现一次的,只包含两个词的餐厅短语含有199,075个。整个Yelp语料库中训练单词分布式表示,并进行k-means聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。其中k代表类簇个数,means代表类簇内数据对象的均值。将其聚类为200个组,每个组由“C000-C199”的标签范围标识。为了减少噪音、降低实验处理难度,达到更好分类效果,通过词标签替换提取出来的关键词,最终生成餐厅有用性短语20,277个,生成餐厅无用性短语16,362个。因为我们主要关注餐厅评论的有用性,在此,只列举有用性分类。具体如表1所示。

表1 短语分组举例
其中C15表示水果类食品,C155表示甜品类,C51表示味道类短语,C63表示肉类或谷类,C125表示情绪副词,C152表示价格或效果的形容词,C149大多表示描述环境的词。
本文收集2013-2014年餐厅有用性评论,为了对相同短语模式的低频词进行排序,我们定义一个目标向量Vt,表示数据集的文本主题相关性,有关低频关键词的识别算法如表2所示。

表2 模型相应算法
4.3 实验结论
从实验中可以得出关于餐厅有用性评论的分布表,如此可以看出出现次数为5以上有用性投票只占了整个餐厅评论的6.08%,而出现次数为1的却占了整个有用性投票的52.78%。提取其中一部分有用性评论,低频词大多是客观表示用餐感受类的词,比如“相当实惠、难以忘怀、十分冷清”等。“有用性”投票越高,这个评论越有价值,所包含的短语也就越有用;高频词大多是关于餐厅实体的词,比如“牛排沙拉、餐厅座椅、芝士面包”等。“有用性”投票越低,这个评论价值越低,所包含的短语也就越无用。具体“有用性”投票分布如表3所示。
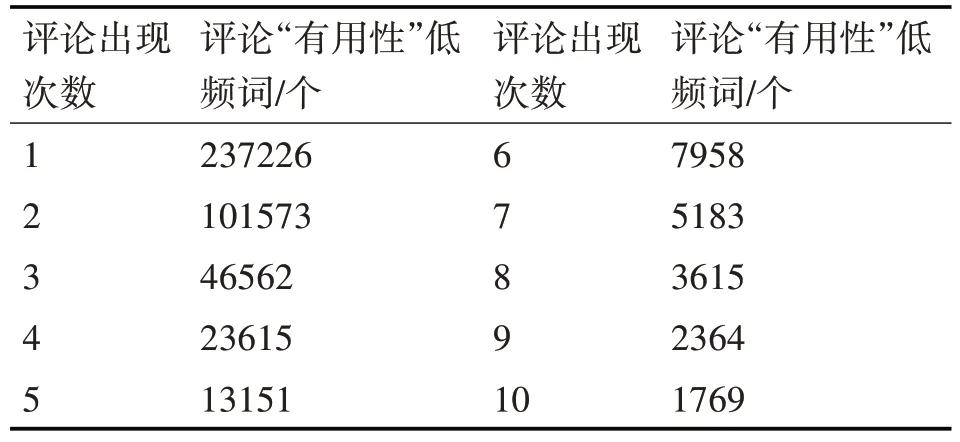
表3 “有用性”投票分布
这个实验不仅表明忽略低频关键词将会失去很多重要的信息,而且验证了我们提出的方法在处理低频关键词这一块取得了很大的进展,并且在餐厅有用性投票处取得了很好的效果,更加客观地为消费者提供准确而有用的信息。
5 结语
本文提出了基于评论有用性投票的低频关键词提取方法研究。首先,通过LIWC2015词典找出评论里相应的边界词并对其进行分割生成候选词;其次,过滤短语,提炼出低频的、与餐厅文本主题相关性大的短语,并且这些短语在餐厅评论中只出现一次;最后,为了减少噪音、降低实验处理难度,我们采用类别标签替换,将每一类短语进行短语评分,从而选出出现频率低且有用性投票高的短语。从整个实验中可以看出通过提取餐厅评论的低频关键词,可以获取更多评论的有用信息,根据我们所提出来的有用性投票能够更加客观地表示人们对这条评论的看法,用户可以更加准确地了解商户,这有助于他们做出更好的消费决策。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
名家名作(2021年4期)2021-05-12
电脑爱好者(2021年9期)2021-05-12
初中生学习指导·中考版(2020年5期)2020-09-10
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
电脑爱好者(2017年7期)2017-05-06
