
基于指纹传感器的盲文识别算法研究∗
2021-06-29 08:42贺磊盈
计算机与数字工程 2021年6期
杨 胜 陶 磊 贺磊盈
(浙江理工大学 杭州 310018)
1 引言
目前我国约有盲人1000万,占全世界盲人总数的18%。每年平均约有45万人失明,即几乎每分钟便会出现一例新盲人。盲文学习方式单一,且现行盲文无音调,存在相同或相似点阵,学习难度极大。因此研发一款能够帮助盲人在未能学习盲文的时候阅读盲文信息或学习盲文的设备非常有必要。该装置能解决盲人阅读困难的问题,让更多盲人有机会接触盲文,学会盲文,让盲文的学习变得更加高效、简单,提高盲人的受教育水平,进而提升盲人的就业能力,改善盲人的生活状况。
国外的盲人人机信息交互研究工作已显露出要由实验室转向商品化的明显迹象。克拉荷马大学Zhenfei Tai等提出了一种新的盲文识别系统,可用于自动确定垂直和水平方向上的旋转角度、凹痕和间距,确定图像旋转角度的关键因素[1]。Sohar大学,阿曼大学Kebangsaan Malaysia的Abdallah M.Abualkishik等为古兰经盲文翻译(QBT)提供了一个特定的翻译,实现将古兰经经文和他们的背诵规则翻译成盲文代码[2]。在国内,盲文识别研究也已取得一定研究成果,清华大学江铭虎等已初步实现了盲文至汉字的转换,为盲文的计算机翻译提供了方法[3]。长春大学李念峰等运用图像处理技术进行了基于图像处理的盲文自动识别系统的研究,能较为准确地识别并翻译盲文图像[4]。长春理工大学尹佳利用数字摄像机采集盲文图像,并能读出汉语拼音,有效地解决了单双面纸介盲文的提取识别问题[5]。西安科技大学党海岩等于2007年对中国盲文计算机系统语句级输入法进行了研究,进一步优化了盲文翻译的算法步骤,提高了翻译的准确度[6]。昆明理工大学李荣瑞等构建卷积神经网络自动学习盲文特征,在多种噪声条件下均可取得较高的识别率[7]。河海大学李婷等提出一种基于深度学习的盲文点字识别方法,利用深度模型——堆叠去噪自动编码器,解决了盲文识别中特征的自动提取与降维等问题[8]。东北大学王倩倩等采用垂直分割法和连通域标签类分割法相结合的形式对简谱符号进行分割,将识别组合好的明文简谱转换为盲人可以阅读学习的乐谱[9]。兰州大学刘彪通过设计基于卷积神经网络(CNN)的盲文音乐图片识别模型,形成了以CNN为基础的盲文音乐图片识别方法,达到了很好的准确率[10]。以上这些方法和系统大多数都用来识别盲文,但不适合盲人直接阅读盲文书籍。
本文主要研究内容是利用半导体指纹传感器采集盲文点阵信息并研发出一套有效准确的穿戴式盲文识别装置。通过图像处理技术对采集的盲文图像信息进行预处理、二值化处理、开运算、连通域检测、重心计算及坐标索引号的转换,从而准确获取盲文编码,再与国家标准盲文库进行比对获得正确的盲文信息,最终通过语音模块播放。
2 盲文的识别
2.1 盲文信息的概述
盲文分很多种,我国现行盲文经《新盲字方案》规定,该方案有五十二个字母,每个音节有声韵两个点符组成,分词连写,必要时使用少量声调符号以区别同音字和生僻词。每个盲文由3×2的点阵构成,通过不同的排列方式代表不同的意义,把盲文和汉字联系在一起。同时盲文凸点间距约为2.4mm左右,相邻点阵间的距离约为4mm。
2.2 盲文信息的采集
图像采集部分为ZFMS-21系列半导体指纹采集模块,模块以高性能高速DSP处理器AS601为核心,采集图像的尺寸192×192,采集头的有效区域为9.6mm×9.6mm,分辨率为508DPI。这样,每个盲文凸点在图像中的相邻距离为48个像素点。本文研究过程中采用的图像采集装置如图1所示。

图1 半导体指纹传感器
当前市面上大多数半导体指纹传感器均已要求接触表面为微导电环境,而盲文大多数为纸质。在纸质盲文所造成的绝缘环境下,半导体指纹传感器无法采集指纹图像数据。在纸质盲文上涂上一层导电胶可以满足预期的采集要求,后期为满足移动使用在任意纸质盲文上,也可以在半导体指纹传感器上加装导电碳膜。这些能为半导体指纹传感器营造出一个很好的微导电环境,从而实现盲文点阵图像的有效采集。
由于半导体指纹传感器传感面积的尺寸较小,采集区域最多可包含两个盲文点阵。这与数字摄像机采集盲文相比,控制了其他点阵对目标点阵的干扰,可以从硬件上实现对单个点阵的识别,有效提高了盲文识别的准确性。同时由于获取盲文图像尺寸像素较小,盲文图像的传输速度较快。
2.3 盲文凸点的提取
盲文点阵的提取使用的数学形态学处理包括二值化、开运算、连通域检测、形状筛选和重心计算。通过这一系列的运算即可得到各点阵的重心坐标、大小和周长。
2.3.1 盲文图像的预处理
由于半导体指纹传感器为接触式电容传感器,使用时图像会因为使用者指尖按压用力不均匀,接触面不清洁等原因产生较多毛刺。因此首先要对图像进行二值化处理。设定一个阈值,根据阈值将大于阈值的像素点的灰度值设置成255,小于阈值的像素点设为0,也就是将整个图像呈现出明显的黑白效果。由于采集的图像灰度值和按压力度有关,所以应该设置动态阈值,动态阈值采用OTSU算法[11~12]。
盲文书为纸质材料,对盲文的采集存在很多干扰,往往采集的图像会存在一些毛刺点,因此要对处理过的二值图像进行开运算处理。通过开运算能够很好地将盲文图像存在的毛刺点过滤,提高原点筛选的准确性。
2.3.2 凸点重心的提取
对比多种连通域标记算法[13~15],最终选择通过使用更高效的Two-Pass方法[15]检测连通域并记录点阵个数、单个点阵中的各点坐标以及各个点阵的周长和面积,可在较短时间内完成连通域的检测和关键信息的采集。
在理想情况下,盲文凸点为标准圆形特征。使用圆形特征可很好地对目标点阵进行筛选。圆度的公式可以表示为

其中S表示面积,P表示周长(点阵面积和周长均可由连通域算法得到)。当C=1的时候,表示图像为一个完美的圆形。如果图形和圆差别越大,其C值会变的越大,因此需要设定一个标准阈值C0来进行判断。若是计算出来的C值大于C0,则说明和圆偏差较大,反之则形状接近圆。
同时设定一个最小面积Smin来排除较小点的干扰,将面积小于Smin的点阵都排除掉,这一定程度上也弥补了开运算缺陷,从而提升识别的正确率。最终计算每个连通域的重心,并作为凸点在图像中的位置。重心的计算公式如下:
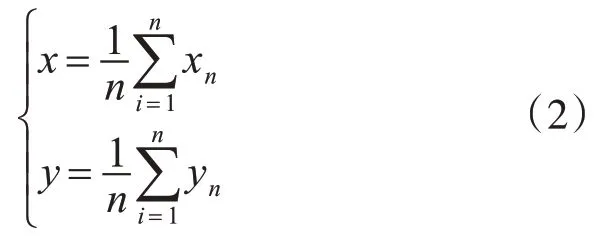
其中n表示连通域中像素点的个数。
2.4 盲文点阵的索引号计算
2.4.1 盲文凸点位置的排序
通过凸点提取运算得到各点阵的重心坐标后,为方便得到各个盲文凸点对应的索引号,应将图像坐标系中的各个盲文凸点都投影到一个新的盲文坐标系中。盲文坐标系的相关参数定义如图2所示。盲文点阵的行方向为盲文坐标系的X轴,盲文点阵的列方向为Y轴,盲文坐标系的原点位于盲文点阵中左上方。盲文坐标系和图像坐标系之间存在以下变换关系:
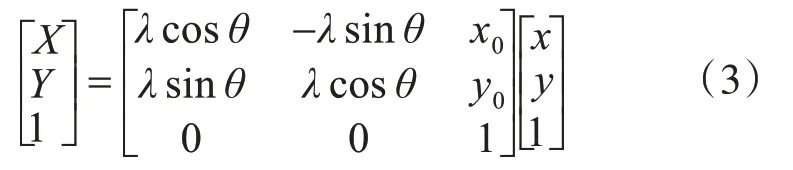
其中λ为投影的缩放比例,等于图像中相邻盲文凸点之间距离的倒数,即1/48;θ为盲文坐标系的X轴和图像坐标系x轴的夹角;x0、y0分别为盲文原点在图像坐标系下的横、纵坐标。
根据盲文点的特征可以发现,同一组盲文点在图像坐标系的间距值只有四种情况,即48,48 2,96和48 5,它们分别可以描述两个点之间的相对位置(如图3所示)。如果距离值是48,那么两个盲文点的理想位置关系是水平或竖直相邻,它们之间连线的矢量方向为0°或90°;如果距离值为96,那么两个盲文点的理想位置关系是竖直,它们之间连线的矢量方向为90°;如果距离值为48 2,那么两个盲文点的理想位置关系是倾斜,它们之间连线的矢量方向为45°或135°;如果距离值为48 5,那么两个盲文点的理想位置关系是倾斜,它们之间连线的矢量方向为arctan(2)°或arctan(-2)°。
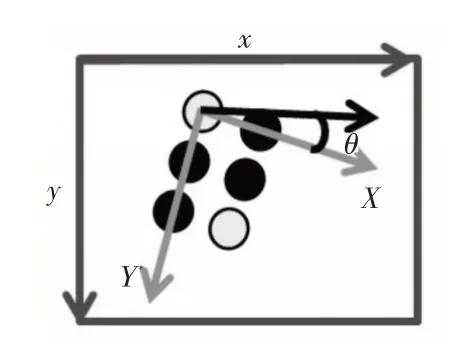
图2 盲文坐标系

图3 盲文点间的四种间距
根据这些信息确定盲文坐标系同图像坐标系的夹角,具体步骤如下:
1)搜索盲文点阵中相距最远的两个点;
2)计算最远两点之间的距离,并同以上四种距离进行比对,选择最接近的一种;
3)计算两点之间的方向,并分别计算同理想情况下的方向的夹角,其中角度最小的夹角即为θ角;
接下来确定偏移量(x0,y0)。首先根据式(4)对所有凸点在图像坐标系下的坐标旋转-θ°得到一组新的坐标:

然后从中分别找出X/Y轴的最小值,最小值对应的点就作为盲文坐标系的原点。假设该点在盲文坐标系中的坐标为(Xmin,Ymin),那么可以通过式(5)计算得到盲文原点在图像坐标系下的坐标(x0,y0)。
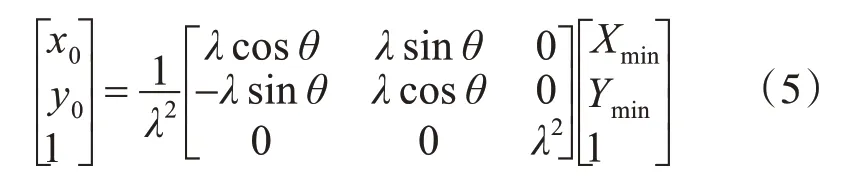
由于纸质材料不规则和采集时的力度不均匀可能导致重心计算得到的各凸点间距有偏差,因此可以采用四舍五入的方式进行取整,使各盲文凸点在新坐标系中的坐标值均为整数。取整函数如下所示:

其中int函数就是对变量X和Y进行四舍五入后取整,取整后的c、r分别描述凸点的列号和行号。
通过以上运算即可得到盲文凸点的相对位置,用坐标(i,j)表示第j行,i列上的点。再将这些坐标进行纵向排序(如图3所示),起点为坐标(0,0),终点为坐标(1,2)。
2.4.2 盲文编码的转换
根据已得的盲文排序进行二进制数的转换,确定该点阵对应的二进制数。如图4所示,盲文上的6个点分别对应6位二进制数的某1位,从1到6分别对应二进制数的低位到高位。若该点存在则该点对应的位为0,不存在则为1,即可得到该盲文点阵对应的二进制数,该二进制数即为盲文点阵的索引号。6位二进制数对应64种情况,包括了所有的声母韵母,根据盲文点阵及其对应的索引号制作相关的库,最终通过该库即可找到索引号对应的声母/韵母。

图4 盲文编码
例如图5坐标排序为{1,5},对应二进制编码为010001,十进制数为17。将索引号在库中进行搜索,得到其对应的声母韵母为“ie”。

图5 盲文编码实例
3 实验和结果
3.1 实验举例
经多次实验确定参数的阈值:圆度阈值C0=1.3,轮廓长度阈值为40,最小面积Smin为150。图6显示两幅盲文图像的处理结果,从图中可以看出,该算法能准确地定位凸点的重心。最后两幅图像得到的二进制数分别为“110111”和“111001”,对应的十进制数分别为“55”和“57”,检索得到它们对应的声母韵母为“ou”和“iong”。

图6 盲文图像的处理结果
观察可得图6(b)和图6(d)中存在一些小面积白点,这些干扰点是由于纸质书籍上存在毛刺导致的,但这些点均不满足面积要求,无法达到最小面积150,因此均会被排除,不会对盲文凸点的识别造成影响。同时观察图6(b)和图6(d)发现,图6(b)左下角区域和图6(d)右上方及中央区域均存在大块白色不规则区域,是由于按压力度不一致导致的,但在圆度计算公式中,这些区域的圆度值均小于圆度阈值C0=1.3,不满足圆度要求,因此均会被排除,不会对盲文凸点的识别造成影响。最终表明提出的盲文识别算法能去除各种干扰,算法的稳定性较好。
3.2 多次实验,准确率统计
经过对现行汉字中的声母韵母共47个字符(其中声母23个,韵母24个)进行了每个字符50次的实验(共声母1150个,韵母1200个),基于视觉的穿戴式盲文识别装置的算法对盲文点阵的正确识别率均能达到95%以上。证明该算法能较好地处理盲文点阵,并较为准确读取信息。

表1 多次识别字符实验结果
4 讨论
由于盲文的特殊性,提出的方法存在一些问题。盲文图像,存在一些点阵的上下偏差(如图7“a”和“i”)。针对这种情况,单独点阵识别,容易产生错误。一种解决的方法是根据前面扫描的盲文,估计水平线(图7 line1)的位置,进而判定当前盲文凸点首行的大概位置,这样就可以确定凸点的排列顺序。
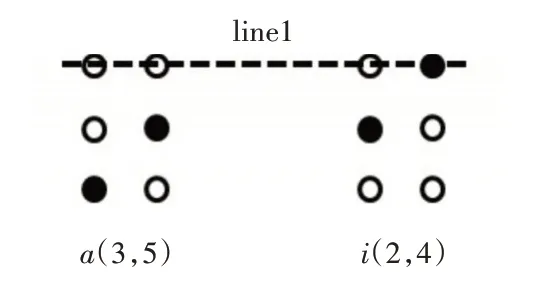
图7 上下偏差实例
此外,盲文凸点存在左右偏差(如图8的“l”和“un”),遇到这种情况,单独点阵识别,容易产生错误。由于算法、传感器特点的影响,本算法暂时无法实现对这种左右偏差的准确识别。所以算法在遇到这种情况时,会将两种发声情况同时放出,由盲人使用者根据上下文情况,选择发声。后期可考虑人工智能根据上下文智能筛选读音。
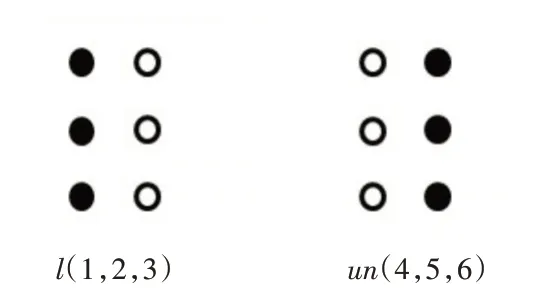
图8 左右偏差实例
5 结语
论文提出的方法能有效利用二值化、开运算、连通域检测、形状筛选和重心计算等图像处理算法提取盲文图像中的盲文字符,并能准确地转化为文字信息和语音信息。下一步工作,进一步优化算法,提高识别速度和精确度,让该设备的识别更为快捷和精准。项目成果有很大的应用前景,为盲文学习与阅读提供了更便利的方法,能在很大程度上改善目前盲人学盲文难的现状,提升盲人的就业能力,改善盲人的生活水平,对社会和国家有着重大的意义。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
导航定位学报(2022年2期)2022-04-11
北京化工大学学报(自然科学版)(2022年1期)2022-03-13
建材发展导向(2021年19期)2021-12-06
疯狂英语·新悦读(2021年9期)2021-11-23
疯狂英语·新阅版(2021年9期)2021-10-30
现代计算机(2021年10期)2021-05-28
语数外学习·高中版中旬(2021年11期)2021-02-14
考试周刊(2018年15期)2018-01-21
中学生数理化·七年级数学人教版(2017年4期)2017-07-08
