
基于深度图像的人体行为识别算法研究
2021-07-03 03:52王维高刘朝辉
现代计算机 2021年12期
王维高,刘朝辉
(西安石油大学电子工程学院,西安710065)
0 引言
人体行为识别是计算机视觉与模式识别学科中最热门的研究主题之一,已被成功应用于智能监控、人机交互、虚拟现实等众多领域[1-2]。随着科学技术的不断发展,其研究对象由传统摄像机拍摄的RGB 图像逐渐转变为深度传感器采集的深度图像[3]。因为深度图像与RGB 图像相比,可以不受光照环境影响,同时还具有提供人体三维空间信息的优势。
对于深度图像的人体行为识别,Li 等人[4]将深度图像序列进行三维点云(Bag of 3D Points)建模,然后采样其边缘轮廓三维点来表示行为姿态;Yang 等人[5]利用深度运动图(DMM)捕获时间上叠加的运动能量,并通过梯度直方图(HOG)提取行为特征;Chen 等人[6]提出局部二值模式(LBP)算法来获得紧凑的运动特征表示,同时讨论了特征级融合和决策级融合对分类结果的影响。
然而以上研究都是人为提前构建特征向量,其性能依赖研究对象的特征设计,不能很好地体现方法的鲁棒性,因此可以将行为数据直接作为输入的深度学习方法成为众多学者关注的重点。对于深度学习的人体行为识别,Simonyan 等人[7]提出一种双流卷积神经网络(CNN)模型,利用帧图像和光流图像作为二通道CNN 的输入,最终得到了很好的识别效果;Du 等人[8]构建了一个八层的CNN 模型,将多通道表面肌电信号图像作为模型的输入,对预先定义的八种行为进行分类识别。
在上述研究的基础上,本文提出一种基于深度图像的人体行为识别改进算法。该算法将深度图像投影到三个正交的笛卡尔平面坐标系上获得DMM,然后在DMM 上构建三个子通道的CNN 模型用于图像数据的训练,最终把测试集DMM 的识别概率进行平均值输出。
1 文中算法
1.1 深度图像预处理

(1)求取深度图像序列的最大像素值为Max=max(Mapa*b*n),其中a*b为帧尺寸,n为帧数;
(2)确定三个投影视图的尺寸,分别为Size(Mapf)=a*b,Size(Maps)=a*Max,Size(Mapt)=Max*b;
(3)若Mapf(x, y)代表Mapf的第x行第y列像素,当Mapf(x,y)≠0 时,则该点在Maps上的投影公式为Maps(x, Mapf(x, y))=y,在Mapt上的投影公式为Mapt(Mapf(x,y),y)=x。
对于含有N帧的深度图像序列,其深度运动图DMMv(v∈(f,s,t))的计算方法为:
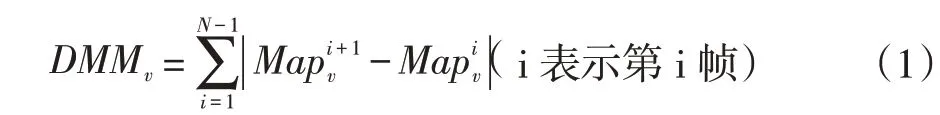
然后去除DMMv中像素值为零的部分,从而得到人体行为的有效区域(见图1)。

图1 行为识别算法流程
1.2 CNN模型构建
CNN 是一种带有多层次结构的深度神经网络,它主要由卷积层(Conv)、池化层(Pooling)和全连接层(FC)组成。其中卷积层用于收集图像的局部特征,池化层用于筛选图像的有效特征,全连接层用于传输综合特征到分类器进行分类识别。CNN 的基本原理就是通过构建多层次网络来获得目标的高层次特征,从而表示数据的抽象语义信息,以期获得更好的特征鲁棒性[9]。
本文构建的CNN 模型如图1 所示,单通道的CNN拥有十二层,包含1 个输入层、4 个卷积层、4 个池化层、2 个全连接层和1 个分类层:第一层为输入层,输入的是缩至224×224 的DMMv。中间十层为训练层:其中有四层为卷积层(Conv1~Conv4),卷积核(kernel)的大小和数量依次为7×7×32、5×5×64、3×3×128、3×3×256,卷积层步长(stride)都为1,采用填充(padding)算法,目的是不丢弃卷积过程中的特征图(feature map)信息;并在每一个卷积层后面都连接一个池化层,选择2×2 的池化核进行最大池化,池化层步长都为2,以避免平均池化的模糊化效果;后两层为全连接层,第一个全连接层产生1024 个神经元节点(FC-1024)输出,第二个全连接层产生20 个神经元节点(FC-20)输出;同时卷积层和全连接层都采用修正线性单元:ReLU 激活函数f(x)=max(0,x)来加速网络训练,以提高CNN 特征学习能力;并在第一个全连接层的ReLU 函数后面采用Dropout 技术,以概率0.5 移除一些神经元节点和相应的输入输出连接,进而增强模型泛化能力,防止过拟合。最后一层为分类层,选用Softmax 分类器,利用它可以得到输入数据对已知类别的最大概率标签,公式如下:

其中x为最后一个全连接层的输出,j为预测类别,w是神经元的权值,k是分类的类别数,P为预测类j的概率。
在测试阶段,将三个通道CNN 测试得到的每类行为DMMv的识别概率进行平均值输出,并将其作为该类的识别结果。
2 实验验证
2.1 实验数据
本文使用微软公开的MSR Action 3D 数据库进行实验。该数据库是由Kinect 深度传感器采集而成,它包括10 个受试者面向摄像机时执行的20 个动作,这20 个动作分别是:高挥手(high wave)、横挥手(horizon⁃tal wave)、锤击(hammer)、接球(hand catch)、前冲(for⁃ward punch)、高抛(high throw)、划X(draw X)、划勾(draw tick)、划圈(draw circle)、拍手(hand clap)、两手挥拍(two hand wave)、侧拳(side boxing)、弯腰(bend)、前踢(forward kick)、侧踢(side kick)、慢跑(jogging)、网球挥杆(tennis swing)、网球发球(tennis serve)、高尔夫挥杆(golf swing)、接球和投掷(pick up and throw)。每一个受试者执行每个动作2 到3 次,共包含567 个人体行为深度图像序列,深度图像分辨率为320×240。
采用和Li 等人[4]一样的实验设置,将20 个动作分成三个子集(AS1、AS2、AS3),每个子集有8 种行为,如表1 所示。在每个子集中,受试者1、3、5、7、9 的动作当作训练数据,受试者2、4、6、8、10 的动作当作测试数据,即使用交叉验证的方法进行实验。

表1 动作子集的设置
2.2 网络训练
本实验的硬件平台为Intel Core i5-4210U 双核CPU,NVIDIA GeForce 820M 显卡,64 位Windows 10 系统;软件平台为MATLAB 2019b。在CNN 模型训练之前,对DMMv行归一化处理,将其统一调整为224×224。CNN 模型的训练步骤如下:
(1)网络模型初始化:初始化各层网络权值和滤波器;
(2)训练参数初始化:每个CNN 的初始学习率(Initial Learn Rate)设置为0.001,优化算法选择Adam,迭代次数(Max Epoch)设置为20,样本容量(Mini-Batch Size)设置为256,训练环境设置为默认(默认的情况是先测试GPU,如果不可用再测试CPU);
(3)将DMMv作为输入,经过前向传递,进入各卷积层、池化层、全连接层和分类器,输出一个包含各类预测的概率值;
(4)计算标定好的数据与通过网络计算出的数据的误差;
(5)经过反向传递,调整训练参数。该过程采用Adam 优化算法,它相对于梯度下降法可以解决稀疏梯度和噪声问题,并能自动调整学习率[10],从而更好地更新网络权值,减小代价函数(Cost Function);
(6)对训练集中的所有DMMv重复步骤(3-5),直到训练次数满足设定值。
经过上述训练步骤,三通道CNN 模型的所有网络权重和结构参数都已得到优化,可正确分类训练集中的人体行为深度图像。当测试集DMMv输入到训练好的模型时,经过前向传递可以得到三个输出概率,取三个概率的平均值即为每个待识别行为对应的输出概率。
2.3 实验结果
实验结果表明:本文所提算法在MSR Action 3D 数据库上的平均识别率达到了97.2%,进一步验证了该算法模型的有效性。本文算法与其他文献算法的实验结果对比如表2 所示。

表2 在MSR Action 3D 数据库上的实验结果
3 结语
为了提高人体行为识别率,更好地体现方法的鲁棒性,本文提出一种基于深度图像的人体行为识别改进算法。该算法使用人体行为深度运动图DMMv作为输入,通过构建三通道的卷积神经网络模型进行识别。实验结果表明该算法在MSR Action 3D 数据库上有着较高的识别率,证明了该算法模型的有效性。在接下来的研究中,将结合人体骨骼数据对CNN 模型进一步改进,从而达到更好的行为识别效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高三版(2021年3期)2021-05-14
中学生数理化·高三版(2021年3期)2021-05-14
福建基础教育研究(2019年6期)2019-05-28
中学生数理化·高三版(2016年3期)2016-12-24
