
基于GAN 网络的去除人脸运动模糊算法
2021-07-03 03:52侯伟栋
现代计算机 2021年12期
侯伟栋
(四川大学计算机学院,成都610065)
0 引言
有很多原因会造成图像模糊,在日常拍照或者是监控视频中,因为摄像机和物体之间发生了相对运动,而造成的图像问题,称之为运动模糊。运动模糊与普通模糊不同的是,普通模糊通常是一些噪声模糊核与图像数据卷积的结果,而运动模糊的模糊核与其并不相同,其主要形成原因是随机的相对运动,我们把这些随机的相对运动也称之为模糊核,而实际原理大不相同。
在计算机视觉领域,关于人脸和去除模糊一直都是比较热门的研究课题。去除运动模糊是去除模糊的一个分支,近几年关于去除运动模糊的研究越来越多,但是这些研究对图像本身的内容并不怎么关注。很多时候我们需要针对特定场景下的图像来去除运动模糊,这些研究的算法具有普适性但没有针对性,它们并不关注图像本身的信息,所以在特定场景下效果并不突出。
无论是日常拍照还是视频监控,很多时候大家对人脸图像更为看重,因此在人脸图像上去除运动模糊显得尤为重要。本课题基于此,针对人脸进行去除运动模糊的算法研究,在人脸这个特定场景下将具有更好的表现效果。
1 相关工作
关于图像模糊问题大约分为两类,一种是在了解模糊核的基础上进行去除模糊,被称为非盲目去模糊,另一种是在不知道模糊核的情况下,被称为盲目去模糊。早期的研究主要是非盲目去模糊,即在模糊核是已知的前提下[1],如何恢复图像,当时主要使用经典的Lucy-Richardson 算法,或者Tikhonov 滤波器来对图像进行反卷积运算,但是这些方法虽然都有一定的效果,但是从视觉效果上来看还是比较差。之后出现了一些基于迭代的方法[2],通过使用带参数的先验模型来改进每次迭代的模糊核以及目标图像,虽然效果有一定提升,但是这些算法的运行时间和迭代次数是不可预估的。
随着近些年深度学习的兴起以及神经网络在图像领域的大规模应用,越来越多的去除运动模糊方法采用深度学习的方法,并且其效果也被大大加强,渐渐地使用深度学习去除运动模糊的算法逐渐成为了主流,效果也越来越好。Sun 等人[3]采用卷积神经网络(CNN)的方法来预估模糊核,取得了不错的效果,Gong 等人[4]则使用完全卷积网络进行运动轨迹的预估,从而预测模糊核具体表达方式,Nah 等人[5]采用了多尺度的卷积神经网络,端到端的去除运动模糊,所有这些方法都使用CNN 来估计未知的模糊函数。
考虑到现有的神经网络算法都是为了解决图像的运动模糊问题,而并不针对图像的类别,为了更好地解决人脸图像的去除运动模糊问题,本文在生成对抗网络[6](GAN)的基础上提出了一种深度学习方法,该方法采用自己制作的虚拟人脸运动模糊数据集,将上采样网络、卷积神经网络以及残差网络结合起来,通过使用跳跃链接的方式关联前后端网络输出,得到了最终的端到端的网络结构,这种方法能够很好地去除人脸图像的运动模糊,下面是本文方法介绍。
2 算法介绍
2.1 数据集制作
在现有的公开数据集中,只有运动模糊的数据集,并没有根据图像内容分门别类,为了更好地训练网络的针对性,我们制作了人脸图像运动模糊的数据集。首先,从现有的人脸公开数据集CelebA_HQ 和FFHQ中人工筛选出可用的人脸正面图片,之后采用Orest Kupyn 等人[7]提出的一种基于马尔科夫随机过程的生成模糊核运动轨迹的算法,对图像进行处理,得到对应的人脸运动模糊图像。将生成的运动模糊图像和原图编为图像对,即生成了最终的虚拟数据集,如图1所示。

图1 虚拟数据集
数据集中所有图像数据尺寸均为256×512,均由256×256 大小的运动模糊图像和其对应的原图像组成,数据集中总共有近6000 张图片,其中4700 多张用于训练,1100 多张用于测试。
2.2 GAN网络
Goodfellow 等人提出了生成对抗网络的概念,即生成器和鉴别器。生成器接收混乱数据并生成样本,鉴别器接收真实数据和生成的样本数据,并尝试区分它们。最终的目标是得到一个能够生成使得鉴别器无法区分的样本生成器。生成器G 和鉴别器D 的博弈过程如公式(1)所示:
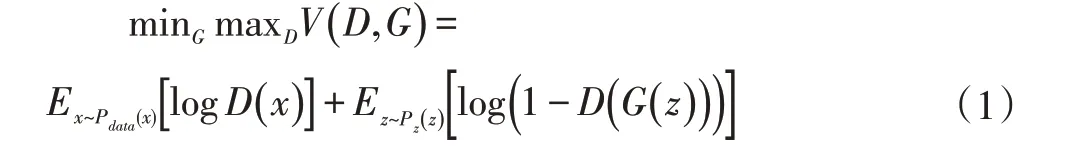
公式中G表示生成器,D表示鉴别器,x表示真实数据(GroundTruth),z表示输入的混乱数据,G(z)表示生成器生成的样本数据,D(*)表示鉴别器判断输入数据是否是真实数据的概率。整个公式的目标就是最大化G,最小化D。生成对抗网络被应用于很多不同的图像领域,如图像超分辨率[8]、风格迁移[9]、图片合成[10]等。
2.3 网络结构
卷积网络,GAN 网络被越来越多地用到了图像处理领域中。本文提出的神经网络模型结合了以上两种网络结构,如图2 所示。
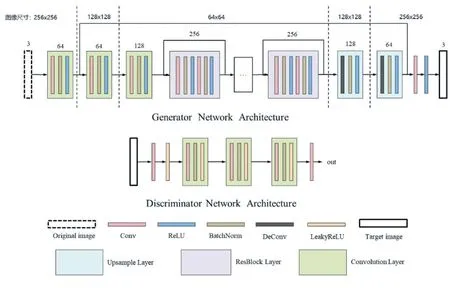
图2 神经网络模型结构
首先介绍下生成网络。首先数据加载器会将图像对加载到网络中,图像对的尺寸大小为256×512,在进入网络之前将图像对切分为运动模糊图像和真实图像,最终运动模糊图像会作为原始输入,输入到网络中。图像通过第一层卷积网络层,分解为维度为64 的图像特征层,但图像大小不变,之后两层的卷积网络中使用了池化的操作,每次都将图像变为原来的1/2,在通过第三层网络后,图像大小变为64×64,维度变为256。网络中段使用4 个串联的残差模块增加网络的深度,采用这种结构,能在增加图像特征信息的基础上,保证梯度信息不会消失,保障网络的训练过程,并且残差模块并不会更改图像的大小以及维度。最后的部分使用连续两层的上采样网络,将图像放大到原来的大小,同时将图片维度进行压缩,与前面的卷积网络形成对应,再通过一个卷积网络生成最终的样本图像。整个生成网络中,将卷积网络、残差网络、上采样网络结合起来,既加深了网络深度,提取了更多的深层特征,又避免了由于网络过深而产生的梯度消失问题。为了得到更好的生成效果,在网络前端添加了一个跳跃链接线,将前端产生的图像特征与后端的图像特征相叠加,这样更好地加强了网络前后端的联系。
其次是鉴别网络。在鉴别网络中使用了三个串联的卷积层作为主体结构,将生成网络输出的样本图像和对应的真实数据分别传入网络中,最终生成了两个1维的数据,鉴别网络的最终目的就是为了分辨这两个数据的真假。
2.4 损失函数
本文的损失函数由对抗损失和均方误差损失结合而成,如公式(2)所示。

其中L 为本文最终的损失函数,a、b 为不同损失函数的权重参数,具体设置为a=0.01,b=2,LGAN为GAN 网络中的对抗损失,LM为输出样本图像和真实图像之间的均方误差。
其中对抗损失描述的是鉴别网络在对输入图像真假进行判断是产生的损失,如公式(3)所示。

公式中所描述的是输入1~N 个样本的散度的叠加,I 代表生成网络最终输出的样本数据。
均方误差损失描述的是生成的样本图像数据与真实图像数据之间的差距,如公式(4)所示。

其中n 为样本的个数,m 代表每个图像样本数据中二维图像点的个数,w 代表每个点出的权重参数,x为真实图像每个二维图像点处的数据,y 为输出样本二维图像点处的数据。
3 训练细节
本文使用PyTorch 深度学习框架实现的网络模型。为了优化训练效果,在反向传播的过程中,生成网络反向传播一次,鉴别网络反向传播4 次。使用Adam[11]作为优化器对网络进行优化,batch size 设置为8,总共训练200 个epoch,学习率lr 最初设置为0.001,在第100 个epoch 之后开始衰减,在200 个epoch 时衰减为0。整个网络在CPU 为Intel Core i7 8700K,内存为32GB,显卡为NVIDIA 2080 的电脑上进行训练,整个训练时长大约为4 天。
4 实验结果
在网络训练结束后,选取训练时最佳的网络参数加载入网络中进行测试,最终的测试结果和真实数据如图3 所示,可以发现本文中提出的网络结构取得了明显的效果,证明了本方法的可行性和有效性。

图3 实验结果
5 结语
本文提出了一种端到端的神经网络模型,模型结合了GAN 网络、卷积网络、残差网络几种基本的网络结构,并通过跳跃链接的方式加强了网络的整体联系。通过使用自己生成的数据集训练后,网络能够很好地完成去除人脸运动模糊的任务。实验证明此网络能够比较好地恢复运动模糊人脸的图像细节,在视觉效果上有着很好的表现力,但是该算法在人脸是正脸时有着很好的表现力,当人脸为侧脸时效果会有所下降,如何解决这一问题是后面研究的重点。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
奥秘(2021年5期)2021-06-15
小雪花·初中高分作文(2017年9期)2018-05-21
软件(2017年6期)2017-09-23
