
引入标记分布的人脸表情图像生成
2021-07-03 03:52杨静波赵启军吕泽均
现代计算机 2021年12期
杨静波,赵启军,吕泽均
(四川大学计算机学院,成都610065)
0 引言
人脸表情是人的情感最直接的表现形式之一,由于数字媒体等技术的需要如今有越来越多针对人脸表情的研究,如人脸表情识别[1-2]与人脸表情迁移[3-4]等。而随着深度学习的发展,人脸表情识别方法与人脸表情迁移方法的效果都有明显提升。但深度学习方法往往需要大量训练数据,现有人脸数据库的数据量往往有限、数据质量参差不齐,且大多数针对传统六种基本表情。
得益于生成对抗网络[5]的提出,许多基于生成对抗网络的人脸表情生成方法被验证。但现有的人脸表情生成方法往往更关注于传统六种基本表情,忽略了表情的丰富性。于是,本文提出引入标记分布[6]的人脸表情图像生成方法,用有限训练数据获得更丰富的表情数据,最终生成高质量的人脸表情图像,对人脸表情数据库进行扩充。该方法基于生成对抗网络,使用Arousal-Valence 维度情感模型划分表情类别以表示更丰富的表情,同时引入标记分布弥补数据量的缺失,并在Oulu-CASIA 数据库和OSU 数据库上进行了验证。
1 相关工作
1.1 Arousal-Valence维度情感模型
量化面部情感行为的模型一般分为3 类[7]:①分类模型:从情感相关类别中选取代表性的情感分类,如Ekman[8]提出的六种基本表情:高兴、厌恶、惊讶、悲伤、愤怒和恐惧;②维度模型:在连续的情感区域内选择一个值来代表情绪;③面部动作编码系统模型:所有的面部动作都由动作单元表示。
Arousal-Valence 维度情感模型是,从Arousal 和Valence 两个维度描述情感。其中Arousal 代表激活度,取值从-1 到1 代表情感从平静到激动。Valence 代表愉悦度,取值从-1 到1 代表情感从消极到积极[9]。本文方法将两个维度各划分21 类,共21×21 个表情粒度。
1.2 生成对抗网络
生成对抗网络[5]是十分典型和有效的生成模型之一,由生成器和判别器两部分组成,生成器生成“假”图像,判别器用以判别“真”和“假”图像,通过生成器和判别器的博弈最终生成高质量的图像。其中一个代表是条件生成对抗网络[10],引入条件信息控制图像生成:

其中G表示生成器,D表示判别器,x表示真实数据,z表示随机噪声,y表示条件。
1.3 人脸表情图像生成
人脸表情图像生成是很有挑战性的图像生成任务之一,人脸图像复杂,人的表情更是多样。近年来基于生成对抗网络的人脸表情图像生成方法不断被提出改进,如G2-GAN[11]使用人脸特征点作为几何先验控制表情的生成,ExprGAN[12]提出了表情强度控制模块,这两者均基于传统基本表情对表情进行划分生成。AttGAN[13]对人脸多种属性进行编辑,改进的CAAE[16]和本文一样基于维度情感模型,但其训练数据量较大。Cascade EF-GAN[15]提出局部关注和级联生成的思想,其基于表情动作单元对表情进行划分,但网络结构复杂。
本文提出的引入标记分布的人脸表情图像生成方法,则是在ExprGAN[12]的基础上,引入标记分布,使用较轻量级的生成对抗网络,在较少的训练数据下生成高质量人脸表情图像。
2 算法实现
2.1 标记分布
在训练数据量充足的情况下,训练阶段使用的标签往往是独热标签,即一个训练数据对应一个类别标签。但本文中为了在训练数据有限的情况下获得训练数据提供的更多信息,利用标记分布学习与标记增强[6],将代表一个类别维度表情标签转化为服从高斯分布的分布式形式,为缺少训练数据类别也提供部分信息。标签处理伪代码如下:
输入:维度情感模型标签(V,A),V、A∈[-1,1],保留小数点后一位
输出:训练使用的42 位表情标签y

2.2 网络结构
网络的输入为R128×128×3的人脸表情图像和R42的表情标签,输出生成的R128×128×3人脸表情图像,是一个端到端的过程。网络结构为条件生成对抗网络,分为生成器与判别器,同时引入人脸识别模型对生成人脸表情图像的身份进行控制。其中生成器由编码器和解码器两部分组成,判别器与表情识别模块共享部分权重。
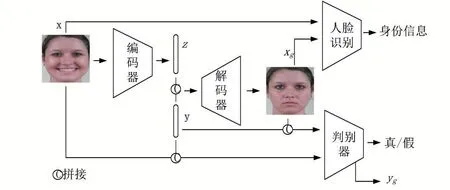
图1 网络结构
2.3 生成器
生成器由编码器和解码器组成。编码器输入为原始输入图像x,输出为低维特征z。低维特征z∈R50,与表情标签y有相同维度。将z与y拼接在一起作为解码器的输入,使解码生成的图像具有表情标签y提供的表情信息。为保证图像生成质量,本文通过最小化输入人脸表情图像x与生成人脸表情xg之间的L1 距离控制生成图像与输入图像的差别:
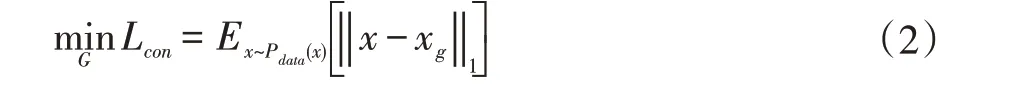
2.4 判别器
本文使用传统的条件生成对抗网络损失函数来对生成图像进行约束,判别器的输入为原始输入图像x与生成图像xg,对抗损失函数表示为:
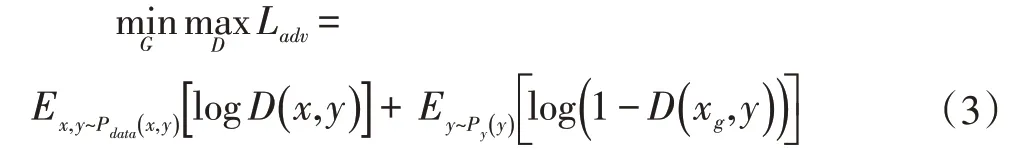
其中P表示数据分布。
2.5 人脸识别模块
为了保持x与xg之间的人脸同一性,本文参考Ex⁃prGAN[12]引入一个预先训练好的人脸识别模型VGG Face[16]来增强人脸身份特征层的相似性:

其中fj是人脸识别网络第j层卷积层的特征映射,ρj为对应权值。
2.6 表情判别器
表情判别模块与判别器共享权重,实质是一个人脸表情识别网络。由于本文表情标签的特殊性,其不同于常见的人脸表情识别网络是分类模型,而是一个回归模型。其输入为原始输入图像x和生成图像xg,分别输出yx与yg,本文通过最小化输入yx与yg之间的L2 距离控制生成图像与输入图像的表情:
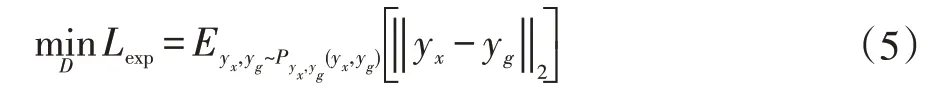
3 实验与分析
3.1 数据库
本文方法在Oulu-CASIA 数据库[17]与CFEED 数据库[18]上进行验证,两数据库数据均不为Arousal-Va⁃lence 维度情感模型标识数据。Oulu-CASIA 数据库数据为包含80 名采集者6 种基本情绪的三种不同光照条件下的表情视频图像序列,本文选取正常光照条件下的视频图像对所有帧的图像数据进行重新人工标注,并采用2.1 小节方法对标签进行处理。同样,对CFEED 数据库中包含230 名采集者正常光照下通过面部表情动作单元标注的表情图像数据,做相同标注处理。最终获得15407 张数据,15000 作为训练数据,其余作为测试。
本文使用MTCNN[19]对所有数据进行人脸检测和对齐,并将人脸区域裁剪缩放为128×128 大小的图像。
3.2 实现细节
本文主体为条件生成对抗网络,生成器由编码器和解码器构成,编码器在VGG 网络的基础上加入输出维度50 的全连接层,共五层卷积层和四层全连接层。解码器包含一个全连接层和七个反卷积层。判别器则由四个卷积层和两个全连接层组成。表情判别器模块则在判别器的基础上加入四层全连接层,与判别器共享权重。总损失函数

其中l1=l3=l3=1、l2=0.1。
训练使用TensorFlow 深度学习框架,使用Adam优化器进行优化。由于训练数据有限,对全局训练造成困难,本文采用两阶段增量训练,第一阶段仅训练解码器于判别器,损失函数为:
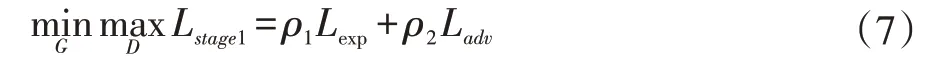
ρ1=1,ρ2=0.01。第二阶段加入所有部分,使用总损失函数Ltotal进行训练。
3.3 生成效果
为达到数据扩充的目的,可使用本文方法对数据库数据进行数据扩充。首先可对数据库以采集身份信息数据进行表情丰富性的扩充,如图2 所示为部分生成效果,针对输入人脸,赋予不同的表情标签,可获得表情更多样的人脸表情数据。

图2 输入人脸表情图像生成效果
其次,可仅使用解码器对随机噪声进行图像生成,获得不同身份信息的人脸表情图像生成,如图3 所示。网络结构中低维特征z使用服从均匀分布的随机噪声,提供不同于数据库数据的身份信息与图像信息,与表情标签拼接后作为解码器的输入,获得更多身份信息的人脸表情图像。

图3 输入随机噪声生成效果
可以看出,以数据库原有图像作为输入,可以在保留身份信息的前提下获得更丰富的表情图像。以随机噪声作为输入,可以生成新的身份信息的多种表情图像。可以看出图3 第三行生成的CFEED 数据库图像风格数据视觉效果略差,考虑是因为CFEED 训练数据仅为Oulu-CASIA 数据库数据的1/2。
3.4 图像质量评估
针对生成图像,使用PSNR 在Oulu-CASIA 数据集上对图像质量进行评估,PSNR 为峰值信噪比,常用来对图像质量进行评估,其数值越大代表生成图像质量越高。本文与ExprGAN 方法[12]进行对比,可以看出本文生成图像质量略高。
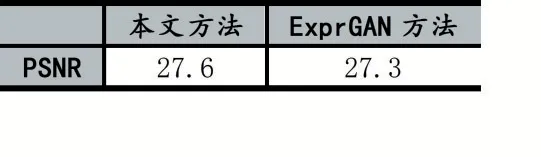
表1 AV-GAN 方法数据分布
4 结语
为对人脸表情图像数据进行扩充,本文提出了可在小规模数据集上运用标记分布进行人脸表情图像生成方法。在Oulu-CASIA 数据库与CFEED 数据库上的实验结果表明,使用本文方法可以生成较高质量的人脸表情图像。
猜你喜欢
当代陕西(2022年4期)2022-04-19
奥秘(2021年5期)2021-06-15
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
小雪花·初中高分作文(2017年9期)2018-05-21
海峡姐妹(2018年3期)2018-05-09
米娜·女性大世界(2016年8期)2016-08-17
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
