
基于NDN架构的车联网内容检索协议
2021-07-05 06:00李丹霞杨雅婷黄婉莹
北京理工大学学报 2021年6期
李丹霞, 杨雅婷, 黄婉莹
(1.北京理工大学 计算机学院,北京 100081;2.延安大学 数学与计算机学院,陕西,延安 716000;3.北京理工大学 信息与电子学院,北京 100081)
汽车“电动化、智能化、网联化、共享化”代表了未来汽车技术与产业发展的方向[1],车联网作为智能交通系统的一个重要组成部分,在车联网中实现高效的内容检索具有十分重要的意义[2].车联网具有网络拓扑快速变化、间歇性连接和传输信道不可靠等特性,这些特性使得在车联网中实现多跳、可靠的内容检索成为一个技术难点.基于传统TCP/IP架构的车联网在多跳内容检索方面已经做了大量的研究,然而这种以主机为中心的端到端的网络架构并不能很好地适应高度动态的车联网[3].
ICN(information-centric networking)[4]作为一种未来互联网的新架构,有着基于内容名称路由、网络内缓存和内容级安全等特性,这些特性为车联网带来了全新的发展方向.NDN(named data networking)[5]是ICN架构中一个典型的研究项目.在NDN中,内容请求者(Consumer)通过将请求内容的名称嵌入到其发送的兴趣(Interest)包中来获得数据(Data)包.每个中继路由器利用接收到的Interest包建立起一个PIT表(pending interest table),通过PIT表记录的接口来构建返回Consumer的反向路径及实现请求聚合.任何接收到Interest的内容提供者(Provider)都会发送相应的Data包.基于NDN的车联网架构被称为VNDN[6-7],VNDN的内容检索不依赖于任何特定链路、中继节点或目的地的存在,请求的数据可以从沿着转发路径或目的地区域的任何节点获取,因此这种架构对高度动态的车联网有更好的健壮性.在高度动态的车联网中频繁建立和维护路由表变得不可行[8],因此将NDN直接应用于车联网面临的2个基本问题是如何找到并选择合适的Provider,以及如何缓解由洪泛转发造成的广播风暴.
在已有的VNDN文献中,对于地理位置相关的应用,文献[8-9]中Consumer将感兴趣的内容所在的地理位置嵌入到Interest包中,中继车辆根据这个地理位置信息将Interest转发至Provider.对于地理位置无关的应用,文献[10]在发现Provider阶段采用的是限制性的洪泛机制.文献[11]提出依托RSU建立骨干转发网,在骨干节点上维护转发表,以通过转发表为地理位置无关应用寻找Provider.该协议中转发表的形成是依靠车辆周期交换所缓存内容信息形成的.然而,这一机制导致大量频繁的一跳数据包产生且形成的转发表并不能适应Provider的高度动态变化.Navigo[12]和CCVN[13]是VNDN中2种典型的可以解决地理位置相关和地理位置无关应用的内容检索协议.Navigo中设计了一种附加机制,用于将内容名称映射到内容所在的位置,Interest包沿最短地理路径转发.对于地理位置无关的应用,Navigo需要通过初始的限制性洪泛来获得Provider的地理位置信息.在CCVN中Consumer根据初始的限制性洪泛获得的多个Provider的响应度和跳数来为后续请求选择最优的Provider.因此已有的文献并没有有效地解决以上存在的两个基本问题.
为了有效地解决上述问题及在VNDN中实现可靠高效的内容检索,本文提出了一种基于分簇和预测机制的VNDN内容检索协议CPCoR.CPCoR的主要贡献如下.
① 本文创新地通过车辆和路边单元(roadside units,RSU)的协同交互,建立动态的网络内容索引表.通过查找网络内容索引表Consumer可以发现多个地理区域内的Provider,并找出最佳Provider.
② 在街道内转发中提出了基于预测的簇建立和维护机制,分簇的网络结构可以有效减少数据包转发过程中MAC层的竞争,提高网络稳定性[14-15]及实现车辆的请求聚合.同时簇的建立和维护开销相比其他已有的分簇协议大幅度下降.
③ 在街道间转发中,综合考虑了道路吞吐量、Interest满足率和到Provider的剩余代价以选择最优的转发街道,实现以更少的网络资源消耗和更高的吞吐量传输数据包.
1 网络模型及协议概述
1.1 网络模型
本文以图1所示的城市环境中的车联网作为研究模型.车辆通过V2I(vehicle-to-infrastructure)连接与RSU通信,通过V2V(vehicle-to-vehicle)连接与相邻车辆通信.RSU之间通过有线骨干网络进行连接(如图1所示),RSU被部署在每个路口,RSU的传输距离为500 m.车辆传输距离为200 m,记为R.每一条街道被划分为长度相同的簇,每个簇的长度为1/2R.任意时刻每个簇选择一辆车作为簇头(cluster head,CH),簇中其余的车辆被称为簇成员(cluster member,CM).每辆车通过数字地图和全球定位系统(GPS)来获得其当前所在位置.

图1 网络模型Fig.1 Network model
1.2 CPCoR协议概述
CPCoR协议分为3部分:街道内转发机制、网络内容索引表的形成和街道间转发机制.RSU和车辆协作形成动态的网络内容索引表(network content index,NCI),RSU周期性的广播发送NCI,其发送频率根据网络环境动态调整.RSU通信范围内的簇头收到周期发送的NCI后更新并存储.Consumer所在簇的簇头收到Consumer发送的Interest包后,这个簇头通过查找其所存储的NCI,找出离这个Consumer的曼哈顿距离最近的Provider所在的簇,并将这个簇的地理位置嵌入到要转发的Interest包中.至此,其他中继簇头依据街道内转发机制和街道间转发机制转发收到的Interest包直至到达Provider.在Data包返回时,为了解决可能的Consumer移动,Consumer原来所在簇的簇头会再广播一次收到的Data,使可能移动到周围的Consumer收到Data.为了防止V2I和V2V数据之间的冲突,车辆的V2I和V2V通信被部署在不同的信道上.
本文用到的关键符号如表1所示.
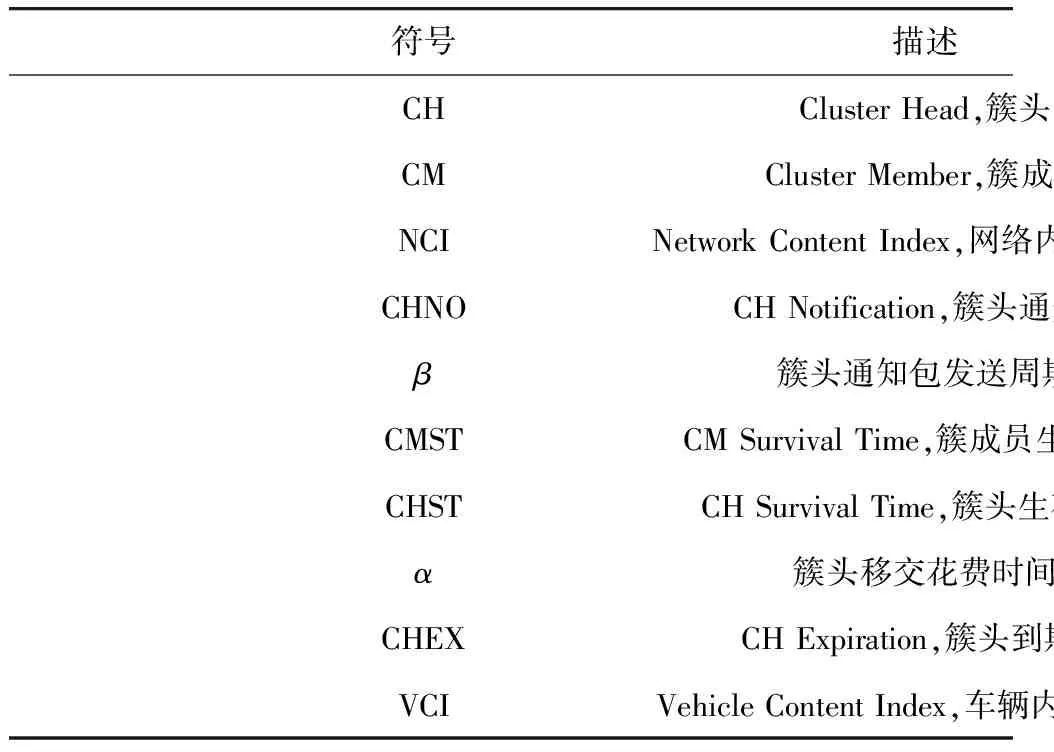
表1 关键符号表
2 街道内转发机制
数据包只通过簇头进行转发,如果遇到一个簇中没有车辆,则该簇的数据包转发会中断.VNDN中任何缓存了所请求内容的车辆都可以成为Provider,因此面临网络分割时VNDN较传统TCP/IP架构有天然的优势.
2.1 簇的建立和维护
例如,图2中某一路口及街道被划分为7个簇,图中给出了这7个簇的当前簇头、簇边界和簇头到期边界.

图2 簇建立实例Fig.2 Examples of cluster establishment
簇的建立和维护机制如下:
(1) 每个簇头在其担任簇头的时间内,会按照时间段β周期发送簇头通知包(CH notification,CHNO),CHNO中包含了这个簇的编号.
(2) 一辆车V在进入一个簇的边界后,默认是一个簇成员.当V在β时间内没有收到一个CHNO,则V会发送CHNO宣布成为一个簇头.反之,如果V收到CHNO,则V的状态保持为簇成员.作为一个簇成员,V在进入一个簇后会发送Hello包.Hello包的内容包括V的车辆编号、行驶方向和V在本簇的生存时间(CM survival time,CMST),CMST的计算将在2.2节中介绍.簇头收到V发送的Hello包后将相应的信息写入簇成员表.簇成员表的一个条目包含簇成员的编号、CMST以及这个条目的有效时间.V在其生存时间到期后,也就是离开簇时会发送只包含其编号的Hello包.簇头收到这个Hello包后,会将V从簇成员表中删除.
(3) 簇头在其生存时间(CH survival time,CHST)到期时,会选择新的簇头.簇头在离开簇之前要将其要离开的消息发送给新的簇头,本文中设定这个传输时间为α=0.2 s,也就是说簇头在到达簇边界之前的αs要将卸任信息发送给新的簇头,CHST的计算会在2.2节中介绍.簇头在其CHST到期后选择当前簇成员表中CMST最长的簇成员作为新的簇头.旧簇头会在其发送的簇头到期包(CH expiration,CHEX)中写入新簇头的编号,那么新簇头在收到CHEX后会立即发送CHNO宣布成为新的簇头.当簇成员收到新簇头发送的CHNO后,会发送Hello包,使得新簇头建立其簇成员表.
2.2 CMST及CHST的确定
在实际生活中,车辆的移动受驾驶员行为和交通规则的制约,因此车辆的移动具有一定的规律性[16].本文通过预测算法来计算CMST及CHST,其中轨迹预测在2.3节中介绍.
簇成员在进入一个簇或者在簇头变化的时候都会发送Hello包,在发送Hello包之前,簇成员对其CMST进行预测.如图3所示,如果簇成员在簇内的最后一个轨迹预测位置坐标刚好在簇边界线上,那么CMST的值等于t1.反之,如果不在簇边界线上,那么CMST=t1+t2CM.t2CM的计算如公式(1)所示,其中((xa,ya),va)和((xb,yb),vb)分别表示簇边界线两侧的轨迹预测坐标和速度,xborder表示簇边界线对应的横坐标值.

图3 CMST和CHST的预测Fig.3 Prediction of CMST and CHST
(1)
节点在成为簇头后会对其CHST以及簇头到期边界进行预测.如图3所示,如果CH在簇内的最后一个轨迹预测位置坐标刚好在簇边界线上,那么CHST=t1-α.反之,如果不在簇边界线上,那么CHST=t1+t2CH.t2CH的计算如式(2)所示.两种情况下簇头到期边界的横坐标xexp都如式(3)所示.
(2)
xborder=xborder-α(va+vb)/2
(3)
2.3 轨迹预测算法
2.3.1获得高斯混合模型的最优参数
通过分析车辆的运动规律,可以预测复杂环境下车辆的轨迹信息.车辆在城市道路中行驶,车辆的移动模式不是单一的,而是包含多种移动模式.因此为了准确地刻画一条车辆轨迹,本文利用高斯混合模型建模.
p(δj|h,λh)
(4)
每个轨迹模式用一个高斯过程表示,数据是由H个高斯分布分模型线性组合产生的,其中选择第h个分模型的概率为
p(λh)=ωh
(5)

p(δi|h,λh)=N(δi|μh,Σh)=
(6)
参数λh={ωh,μh,Σh},μh和Σh分别表示第h个分模型的均值和协方差矩阵.
已知观测数据点δi,引入一个隐变量z,以0-1随机变量zih表示δi是否来自第h个分模型,zih的定义为
(7)
则N个观测数据点S={δ1,δ2,…,δN}的联合密度,即似然函数为
(8)
利用标准期望最大化(expectation-maximization,EM)算法对参数λ进行最大似然估计.其中初始参数λ0及分模型的个数H通过K-means算法获得.
肾脏科不合理应用伏立康唑片的另一显著问题是给药剂量不足。91.91%的患者在第一个24 h内未给予负荷剂量,则其血药浓度无法在第一天接近稳态浓度,即使之后给予足量维持剂量也需到第6天才能到达稳态[1,14]。病历资料显示,除1例在用药几天后改为正确维持剂量外,其余135例患者全部存在维持剂量过低的情况,既不科学也不经济。另外,若腹膜透析患者发生腹膜炎,“指南”推荐可使用抗真菌药物预防和治疗真菌性腹膜炎,此时伏立康唑片的推荐剂量也为常规维持剂量200mg q12h po[9]。
2.3.2高斯混合回归轨迹预测

(9)
其中
(10)
预测通过计算如下条件概率密度以实现
(11)
这仍然是一个高斯混合模型,模型参数为
(12)
(13)
(14)
(15)
对应的协方差为
(16)
3 网络内容索引表
NCI的形成包含两种情况:一种是当有缓存内容的车辆进入一个子网时,另一种是当簇头收到Data包时.一个RSU将其覆盖范围内的道路划分成几个子网,例如图4中RSU覆盖的街道被划分为4个子网.

图4 RSU覆盖范围内的子网划分Fig.4 Subnet division within RSU coverage
当有缓存内容的车辆进入一个子网时:该车辆将其所缓存的内容的索引表发送给RSU,这个索引表被称为车辆内容索引表(vehicle content index,VCI),其结构如表2所示.VCI中包含了车辆在子网内的预测轨迹S*及内容名,那么通过一次发送预测轨迹,RSU就可以获得该车辆缓存的内

表2 车辆内容索引表(VCI)Tab.2 Vehicle content index
容在子网内的动态位置,而不是车辆频繁的发送内容所在位置广告.当车辆离开子网的时候会向RSU发送离开信息,RSU删除该车辆所发送的VCI.
当簇头收到Data包时:如果簇头发现自己所在的子网中没有Data包对应内容的索引信息,则该簇头会发送信息给它的一个簇成员.该簇成员是这个簇所在子网中生存时间最长的车辆,这个簇成员缓存收到的Data包并向RSU发送VCI,这样做的目的是为了使这个Data包后续能提供更好的Provider服务.如图5所示,簇头CH选择簇成员CM3发送Data,CM3是同一行驶方向的簇成员中CMST时间最长的节点.

图5 簇头移交DataFig.5 CH handover received Data
RSU将以上2种方式收到的VCI通过SDN(software defined network)发送到整个网络中,SDN的结构设计在本文中不做讨论.每个RSU将收到的VCI进行计算、合并得到NCI,其结构如表3所示.

表3 网络内容索引表(NCI)Tab.3 Network content index table
4 街道间转发机制
当一个Interest包被位于路口的簇头CHinter收到,CHinter需要决定选择哪条街道作为下一条组成路由路径的街道.为了形成最优路由路径,路由性能被计算以帮助CHinter做出决定.公式(17)用于计算通过街道ROAB到达Provider(Vp)的路由性能RP(ROAB,Vp).
RP(ROAB,Vp)=ω1THAB+ω2ISRAB+ω3COB,Vp
(17)
其中ω1、ω2和ω3为加权因子,其值根据具体应用环境进行设置,且ω1+ω2+ω3=1.
如图6所示,THn,B为街道ROAB中第n簇头CHn到路口B的吞吐量,则THAB=THn,B,THn,B的计算如下.

图6 道路路由性能计算Fig.6 Road routing performance calculation
(18)
其中TRn为CHn在路口A到B方向的传输速率.根据公式(18)可以获得THn,B的迭代特性如公式(19)所示.簇头通过CHNO获取邻居簇头的信息,因此CHn可以获得簇头CHn-1拥有的信息THn-1,B.
(19)
ISRn为CHn的Interest满足率,则ISRAB=ISRn,B,ISRn,B的计算如下:
ISRn,B=ISRn×ISRn -1×…×ISR1
(20)
ISRn,B的迭代特性如下:
ISRn,B=ISRn×ISRn -1,B
(21)
从路口B到Provider(Vp)的剩余估计成本COB,Vp的计算方法如下:
(22)
其中,md(B,Vp)表示从路口B到Vp的曼哈顿距离,dAB表示街道ROAB的距离.
图7给出了一个在路口进行路由决策的例子.Interest包从Consumer(Vc)发出经过多跳中继到达路口B时,相邻街道有ROAB、ROBE和ROAB,为了避免路由环路ROAB被去掉.路由性能RP(ROBC,Vp)和RP(ROBE,Vp)被分别计算,具有较大值的街道ROBC被选择作为下一跳转发街道(假设RP(ROBC,Vp)>RP(ROBE,Vp).Interest在路由性能的指导下沿着道路转发,直至到达Provider(Vp).

图7 路口路由决策示例Fig.7 Example of intersection routing decision
5 协议性能评估
5.1 模拟实验设置
为了评估CPCoR的性能,将其与Navigo和CCVN协议进行比较.模拟实验采用的地图如图1所示.车辆移动轨迹由SUMO[17]生成,采用基于NS-3的NDN模拟器ndnSIM[18]实现车辆的NDN网络架构.MAC层采用IEEE 802.11p协议,传播模型采用Nakagami模型.网络中选择一定数量的随机车辆作为Consumer和Provider,在Provider上提供歌曲下载.Provider中每首歌曲的平均长度为3 min,对歌曲的请求符合参数
ρ=1.0的Zipf分布.在模拟实验中记录了歌曲回放期间是否发生了下溢,最大缓冲区大小被设置为30 s.
基础设置为车辆数量600、Consumer数量80和Provider数量20.以下性能指标被采用以验证当车辆数量、Consumer以及Provider数量变化时模拟实验的效果:
请求成功率:定义为被满足的Interest数量与所有Consumer发出的Interest数量之比.
用户满意度:表示为没有因播放缓冲区不足而导致播放中断的歌曲的百分比.
平均开销:平均每个被满足的Interest所花费的Interest包和Data包数量之和.
缓存命中率:从缓存中满足的Interest数量与到达缓存的Interest总数的比率的平均值.
5.2 Consumer数量的影响
如图8(a)所示,随着Consumer数量的增长,CPCoR的请求成功率呈持续上升状态,而Navigo和CCVN的请求成功率呈先上升后下降的状态.这是因为在Consumer数量增长初期,增长的请求使得内容数据被缓存在更多的车辆中,因此带来网络性能的提升.然而,随着Consumer数量的进一步增长,网络流量加剧使得网络性能下降.在CPCoR中,随着Consumer数量的增加,通过请求聚合来共享数据的Consumer的数量也在增加,因此削弱了网络流量增长带来的影响,使得在Consumer数量从100变化到140时仍然能保持稳定的请求成功率.如图8(b)所示,对于用户满意度CPCoR的表现明显优于Navigo和CCVN,尤其是Consumer数量为100或者更多的时候.如图8(c)所示,在各个Consumer数量下CPCoR都需要不到30个数据包,从而提高了整体网络性能.Navigo和CCVN在内容发现阶段采用的都是无目的限制性洪泛,在Consumer数量较多的时候导致了过多的数据包碰撞和重传,使得成功的请求只能依赖于较近的缓存,因此表现为成功满足的Interest的平均开销持续下降.如图8(d)所示,在网络负载较大的情况下,由于大量聚合的实现以及Provider的动态准确定位,CPCoR可以达到36.5%的缓存命中率,而Navigo和CCVN的缓存命中率分别为23.8%和17.6%.

图8 Consumer数量对网络性能的影响Fig.8 The effect of consumer number on network performance
5.3 车辆数量的影响
如图9(a)(b)所示,随着车辆数量的增加,网络分割概率减小,网络连通性逐渐变好,因此3种协议的请求成功率和用户满意度都会增加.与Navigo和CCVN相比,CPCoR平均提高了18.9%和53.4%的请求满足率,以及23.3%和60.4%的用户满意度.CPCoR明显优于其他两者的原因有:(1)通过预测选择了生存时间最长的节点作为簇头,增加了链路传输的稳定性,且Data包可能通过同一反向路径返回的概率增加,请求聚合增加;(2)CPCoR中快速、动态更新的网络内容索引表可以及时检索到请求内容所在位置;(3)在选择转发街道的时候,CPCoR综合考虑了各个街道的吞吐量和Interest满足率等,而不是简单的依据地理位置远近进行选择.如图9(c)所示,随着车辆数量的增加,3种协议的平均开销都会逐渐下降,Navigo和CCVN的下降幅度较平缓.CPCoR根据网络内容索引表查询Provider,因此相比Navigo和CCVN减少了23.6%和31.8%的平均开销.如图9(d)所示,随着车辆数量的增加三者的缓存命中率都在上升,在Navigo和CCVN中无目的限制性洪泛导致了节点中更多的Interest包到达,因此表现出更低的缓存命中率.

图9 车辆数量对网络性能的影响Fig.9 The effect of vehicle number on network performance
5.4 Provider数量的变化
如图10(a)~(d)所示,随着Provider数量的增长,3种协议的请求成功率、用户满意度和缓存命中率都在增加,且平均开销都在下降.这是因为Provider的增长减少了从Consumer到最近的Provider或实现请求聚合的车辆的距离.Navigo通过无目的限制性洪泛形成内容与地理位置映射表,且只有车辆在计时器到期后没有收到请求内容时才将与内容绑定的地理接口删除,因此在请求内容时并不能非常有效的到达内容所在地理位置且开销较大.在Provider数量较少时Navigo表现出与CPCoR更大的性能差别.CCVN通过无目标的Interest包转发带回来Provider的活跃程度和距离等信息,但是因为VNDN每个Interest对应一个内容块,找到的Provider并不能为后续请求提供较多的指导意义.CPCoR能适应车联网中Provider位置的快速变化,而Navigo和CCVN找到的Provider的信息可能是过期的,这将导致了更多的重传,降低了网络性能.与Navigo和CCVN相比,CPCoR不仅整体提高了性能,特别是在Provider数量为35时,达到了100%的请求成功率和用户满意度.

图10 Provider数量对网络性能的影响Fig.10 The effect of povider number on network performance
6 结 论
本文提出的CPCoR协议适用于地理位置相关和地理位置无关两种应用.CPCoR中建立的网络内容索引表能动态的适应网络拓扑频繁变化的车联网;街道内转发中基于分簇和预测的转发机制充分展现了VNDN架构中请求聚合的优势;街道间转发机制中利用道路路由性能选择下一条转发街道,而不是不是片面的选择地理路径最短.实验结果表明与传统VNDN内容检索协议相比,CPCoR实现了较高的请求成功率和用户满意度且产生了较小的网络开销.
猜你喜欢
计算机与网络(2020年9期)2020-07-29
电脑知识与技术(2019年22期)2019-10-31
传播力研究(2019年24期)2019-10-21
大学教育(2019年5期)2019-04-23
中国新通信(2019年21期)2019-03-30
价值工程(2018年35期)2018-01-25
物流科技(2017年10期)2017-11-22
初中生世界·七年级(2017年2期)2017-01-20
小猕猴智力画刊(2016年6期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
