
基于MapReduce并行关联挖掘的网络入侵检测
2021-07-06 02:10徐胜超
计算机技术与发展 2021年6期
徐胜超,宋 娟,潘 欢
(1.广东财经大学华商学院 数据科学学院,广东 广州 511300;2.宁夏大学 宁夏沙漠信息智能感知重点实验室,宁夏 银川 750021)
0 引 言
随着计算机网络的发展及新型网络协议的出现,近年来各类网络入侵攻击行为持续增加,普通的数据挖掘算法已经不能满足网络入侵检测的需求。作为数据挖掘的重要分支,关联规则挖掘已经成为了研究热点[1-4]。关联规则算法中,很多都能够产生频繁项集,在这些关联挖掘产生频繁项集的过程中,连接数据库和产生侯选项集的数目非常大,这样将大大增加了关联规则算法的时间代价,降低了效率。例如经典的Apriori算法增强了丰富的颜色到数据的分析与处理,其目的是为了发现不同的数据项在历史交易数据库中的关系,核心功能是通过重复扫描数据项,获得频繁项集和研究项集之间的关系。目前,Apriori算法和并行化的Apriori算法都得到了很大的改善[5-7]。
关联规则模型中的Apriori算法主要应用在大量的历史交易数据中,用来发现频繁模式和数据项之间的关联性。尽管如此,考虑到Apriori算法的固有的特点,当数据容量十分大的时候,它的缺点和不足体现得更加明显,此时使用Apriori算法来分析和处理数据将变得非常消耗时间与内存空间,效率低下[8]。所以为了快速处理大容量数据,文献[9]提出了基于Apriori算法的重要状态确定方法来完成网络入侵检测。文献[10]提出了改进的Apriori算法来完成频繁模式树的建立,将其应用到数据挖掘领域。
针对早期的低效率的传统Apriori算法而言,要处理网络入侵检测的海量大数据,目前比较常见的是Hadoop分布式计算框架。同时改进早期经典的Apriori算法,建立新的框架用来处理频繁项集的挖掘的并行Apriori算法,用来加快计算速度,节省内存空间。该文提出的基于MapReduce云计算的并行关联挖掘的网络入侵检测方法Cloud-Apriori就是基于这个思路。Cloud-Apriori的实验通过构造Hadoop集群来完成。实验结果表明改进的并行Apriori算法具有很高的检测精度和更少的运行时间,提高了网络入侵检测效率。
1 Hadoop框架分析
1.1 分布式框架
文中关联挖掘的网络入侵检测采用了Hadoop云计算平台,这样可以并行处理频繁项集,以进一步提高大数据处理的速度与效率[11]。
Hadoop是一种开源并行大数据处理的总体支撑平台,一般基于MapReduce的并行算法中采用了6个步骤来表示任务流Job stream的流程情况。每个任务流都表示为一系列的Map任务或者Reduce任务,并行关联挖掘的Apriori算法作为一个应用程序,其包括的所有子任务组成了一个有向无环图,如图1所示[12]。在部署Hadoop的时候,主控节点部署为JobTracker,工作机一般部署为TaskTracker。因特网上有很多关于Hadoop的文献,由于篇幅原因这里不再过多累述,这6个具体步骤如下:
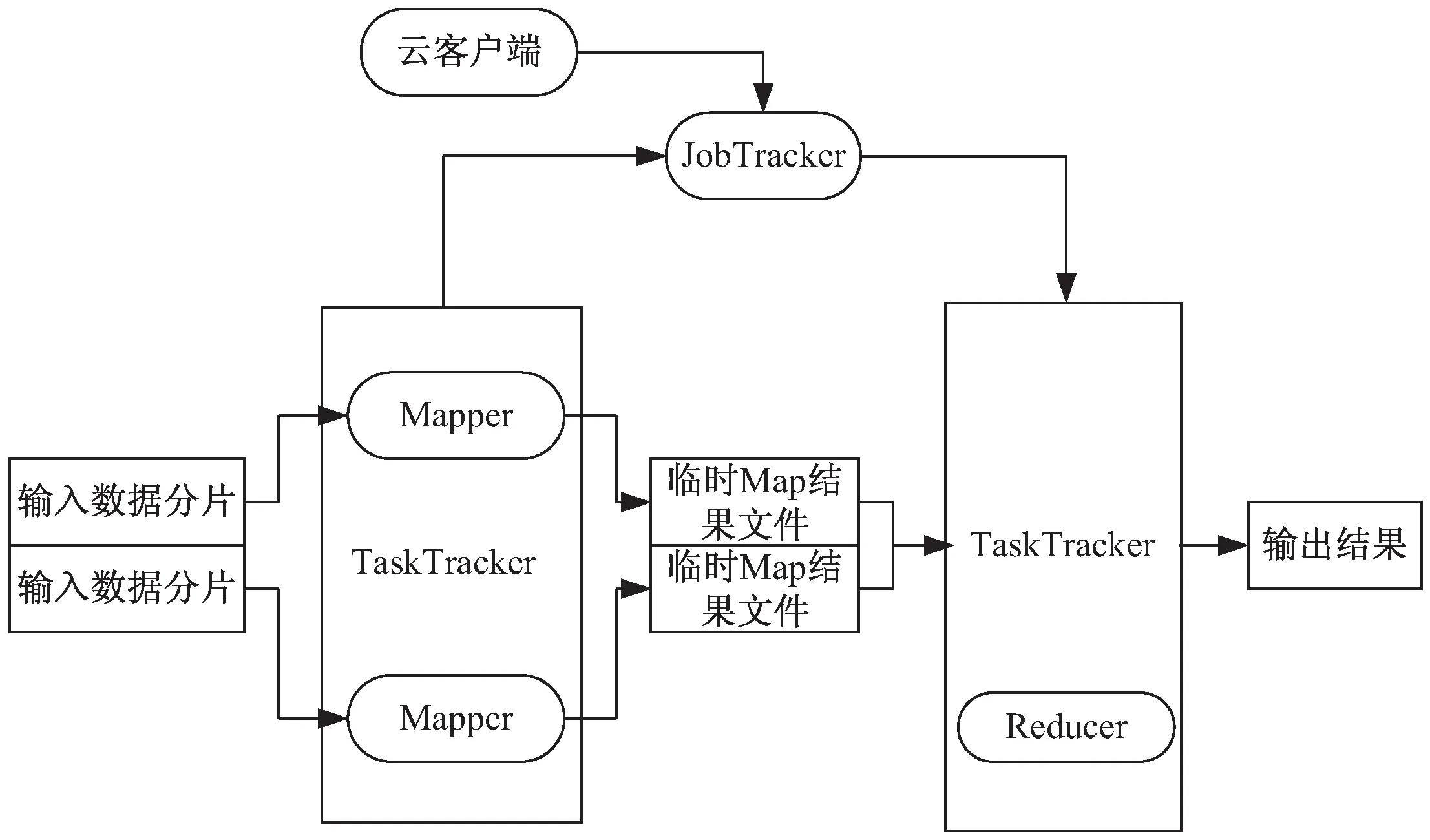
图1 基于MapReduce的并行关联挖掘任务流
(1)对输入的大数据的样本数据集文件进行设置与分片;
(2)主节点(JobTracker)调度从属节点(TaskTracker)执行Map子任务;
(3)从属节点读取输入源片段;
(4)从属节点执行Map子任务,并将临时结果文件保存在本地;
(5)主节点调度从节点执行Reduce子任务,Reduce阶段的从属节点读取Map子任务的输出文件;
(6)执行Reduce子任务,将最后的结果保存到HDFS分布式文件系统当中。
有了这6个步骤,并行关联挖掘的Apriori算法的编程人员就可以摆脱本身分布式计算的编程细节,可以使用高级语言在很短的时间内,完成分布式计算的编程。
1.2 MapReduce模型分析
Map操作和Reduce操作是MapReduce并行编程模型的关键操作,所有的任务流必须经过这2个阶段。MapReduce中的任务流可以通过下面的公式表示:
DAG=(W,E,DAGinfo)
(1)
W={Wname,{Map},{Reduce},Param,Input,
Output}
(2)
其中,W表示被并行处理后的任务的集合,Wname表示子任务的名称;Map和Reduce分别表示映射和规约操作;Param表示任务执行所需要的参数信息;Input和Output分别表示输入任务和输出任务相关的数据信息;E表示在DAG图中的两个任务之间的边;DAGinfo表示DAG图中的特殊鉴别信息。
公式(2)中的Map操作可以更详细地表达如下:
Map=(Mname,InK,InVal,OutK,OutVal,
Propereties)
(3)
其中,Mname表示Map操作的名称;InK和InVal分别表示在输入Map操作过程中Key-value关键字与关键字值之间的映射对;OutK和OutVal分别表示在输出Map操作过程中Key-value关键字与关键字值之间的映射对;Properties表示在Map操作过程中的属性参数。公式(2)中的Reduce操作可以更详细地表达如下:
Reduce=(Rname,InK,InVal,OutK,OutVal,
Propereties)
(4)
其中,Rname表示Reduce操作的名称,后面的参数InK和InVal等的含义都与Map操作中是一致的。E表示在DAG图中的两个任务之间的边。E的详细描述如下:
E=(Path,StartTK,EndTK)
(5)
其中,Path显示了数据流的传输路径,StartTK表示当前的任务,EndTK表示任务的子任务。
2 Cloud-Apriori并行关联规则挖掘模型
2.1 基本模快
Cloud-Apriori的关联规则数据挖掘如图2所示。
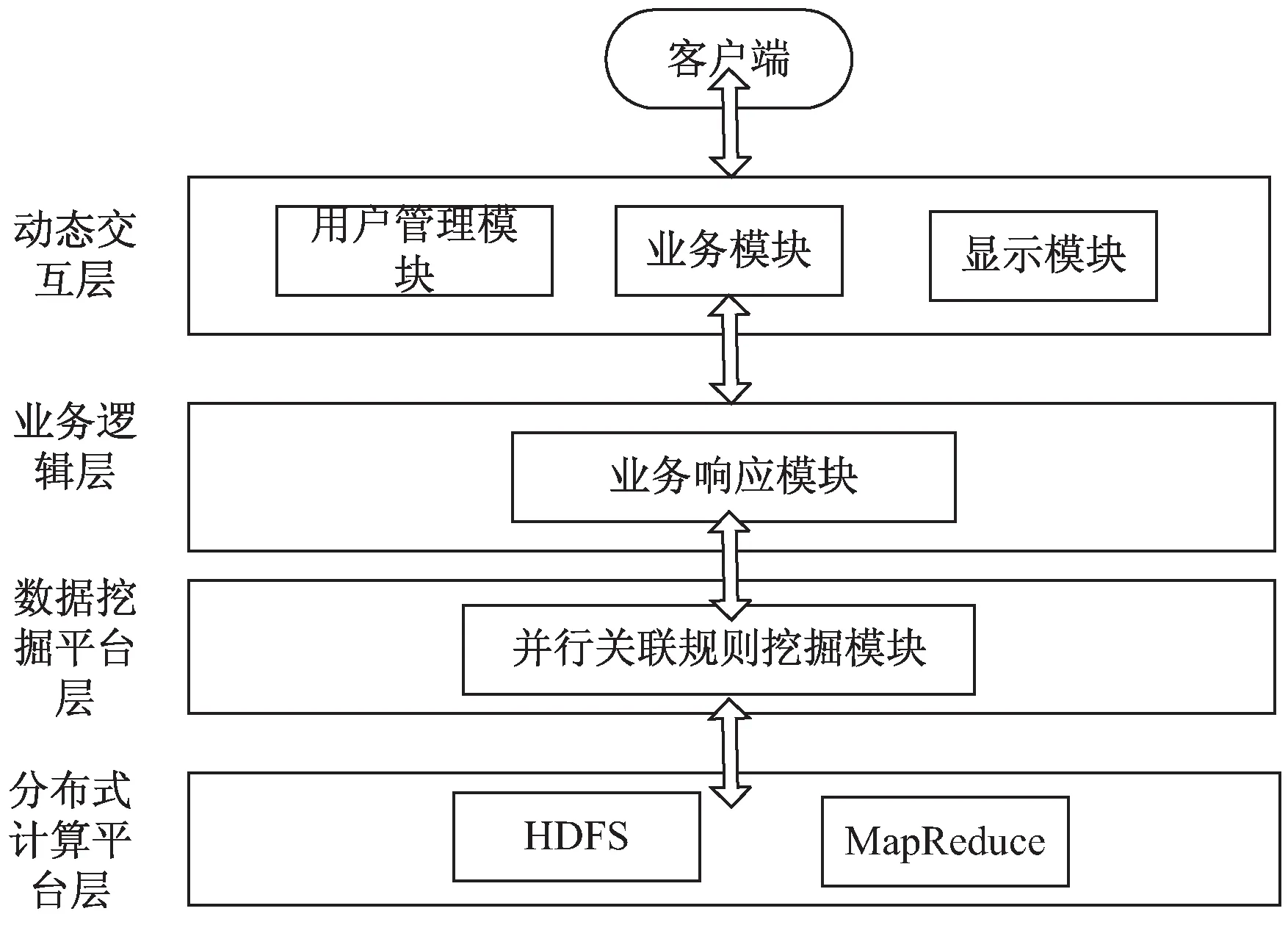
图2 基于Cloud-Apriori的并行关联挖掘模型
主要包括:
(1)动态交互层:用来与客户端通过接口进行交互;
(2)业务逻辑层:用来完成针对交互层和数据挖掘平台层的所有业务处理操作的命令和控制;
(3)数据挖掘平台层:是该文基于Hadoop的关联规则算法的核心层,具体完成大数据的处理,包括并行数据挖掘算法,工作流模块,数据装载模块和存储模块;
(4)分布式计算的平台层:它是利用Hadoop框架来获得HDFS分布式文件的存储和MapReduce的工作的执行。
2.2 关联规则Apriori算法原理
关联规则表示两个实体在某种规则下的一些隐藏信息,关联挖掘的目的是发现这些隐藏的关系[13]。关联规则可以通过数据模型来描述,例如X表示关联规则的前提假设,Y表示后续的关联规则。另外,关联规则算法有一个关于支持度(support)和置信度(confidence)的定义,如公式(6),这里A和B分别表示了不同的事件。
(6)
关于支持度和置信度的通信关系可以通过公式(7)来计算:
(7)
关联挖掘的Apriori算法的基本思想是使用频繁项集的优先知识信息来完成迭代计算,该过程是层对层的搜索进行的[14]。
为了实现在Apriori算法下的关联分析,一般的关联挖掘的步骤如下:
步骤1:设置最小的需求支持度min_Sup和最小的置信度min_Conf;
步骤2:顺序地连接和扫描数据集,确定每个数据项的支持数量,选择出在步骤1中的最小支持度min_Sup的频繁项集1;
步骤3:随机地结合2个频繁项集1来生成侯选的频繁项集2,然后顺序地连接数据集和完成对侯选的频繁项集2的支持度的计算,最后根据步骤2过滤频繁项集2;
步骤4:重复步骤3直到产生了空的最高序号的频繁项集;
步骤5:输出关联挖掘的结果,算法结束。
2.3 Cloud-Apriori挖掘算法的设计
前面提到MapReduce编程模型采用了主-从(Master/Slave)模式,即主控节点上可以部署Job Tracker,在从节点上可以部署Task Tracker。在DAG的有向无环图中,为了更好地分配正确的任务流到所有的处理节点,该文采用并行MapReduce的任务流处理技术,具体的实现机制如图3所示。
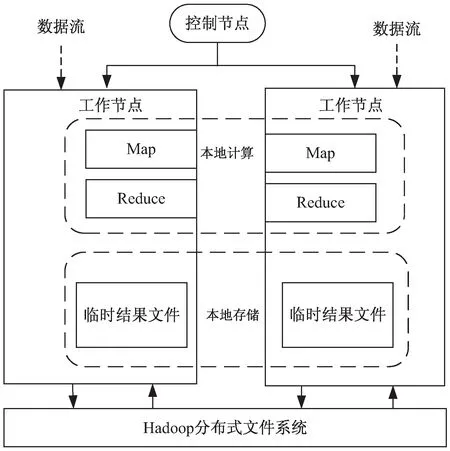
图3 MapReduce的并行关联挖掘工作机制
2.4 Cloud-Apriori挖掘算法的实现
(1)产生频繁项集。
文中算法采用了自顶向下的方式,从概念的第一层开始到最后一层,利用MapReduce产生大量的频繁项集,包括在不同的概念层之间的层次交互。对于每一层来说,MapReduce操作产生一个频繁集的数据项,包括特殊层的交互,这种操作将一直迭代,直到在本层中不能发现更多的频繁项集为止。
在数据入口的处理中,主要使用了三个类:输入格式Input format、输入分片Input split和记录阅读器Record Reader。在这三个类中,输入格式又被输入数据处理一次,每个输入的分片在后面的类中处理。记录阅读器的功能是对数据块的输入分片进行分析,并将其信息对接到多个key-value关键字和关键值的映射对中,并发送到Map函数。与任务相关的关键字和关键值的映射

表1 关键词和关键值的映射表描述
(2)Map和Reduce的处理。
当使用Hadoop来完成大数据处理的时候,在文件中的每行都被作为交易记录对待,在行中的每个入口都被一个空格符号分离开。在客户端提交了文件到HDFS后,文件中的数据块的默认尺寸是64 MB,每个迭代的轮次都执行一个MapReduce任务。每个Map节点同时处理多个数据块,处理完后输出到候选集及其对应的支持度。
Reduce操作持续地处理Map操作阶段的结果,所有的具有相同的键值的关键字-关键值对都将完成规约操作,最后完整的频繁项的支持结果将完成。这些并行的规约过程都采用MapReduce结构设计,包括Map()函数和Reduce()函数,它们都运行在Hapdoop平台上,加快了关联规则挖掘的计算速度。下面是Map()函数和Reduce()函数的伪代码,这些代码经过少量的修改即可在Java语言环境下执行。
下面的Map_Class是Map阶段的类描述代码:
Map_Class{
1. map(key,value){
2. Sort=0;
3. Dis=Max_Value;
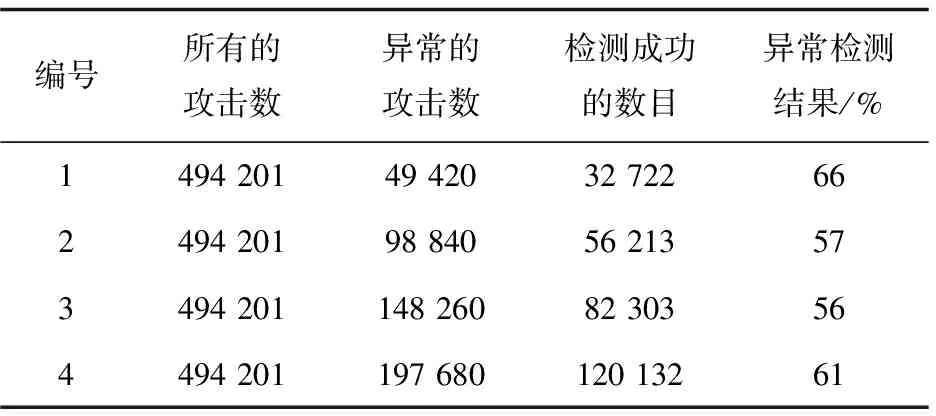
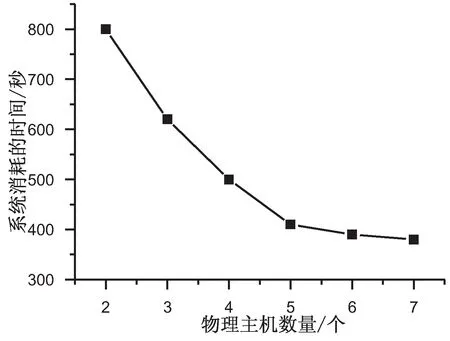
4.for(int i=1;i 5.Records Dis=dis(i,pointer); 6.if(Records Dis 7. Sort=i; 8.min Dis=Records Dis; 9.} 10. } 11.produce<"Sort" , value>; 12. } 13. } 下面的Reduce_Class是Reduce阶段的类描述代码: Reduce_Class{ 1.reduce(key,value){ 2. D1=0; 3. Sort=k; 4. Temps=new int[D1]; 5. for(int i=0;i 6 . for(int D1=0; D1 7. D1++){ 8. Temps[i]=value[D1][i]; 9. } 10. } 11. for(int j=0;j 12.pointer+=Temps[j]; 13. } 14.produce 15. } 16. } (3)计算复杂度分析。 如果i是原始数据集D的交易数,j表示每个交易记录的平均长度,采用传统的Apriori关联挖掘算法,在L1层中计算时间复杂度为T1=O(i*j),整个算法的时间复杂度为: O(|Ck|*|Lk-1|)+O(i*|Ck|)] (8) 如果采用基于MapReduce的并行关联挖掘的Apriori算法,Hadoop集群有a个节点,每个节点都操作1个数据块,则获取频繁项集的整个时间复杂度可以表示为: O(|Ck|*|Lk-1|)+O(i*|Ck|)]}/a (9) 从公式(8)和公式(9)比较可以看出,从理论上讲,基于MapReduce的并行Apriori关联挖掘算法可以很好地降低执行时间。集群的物理节点个数越多,则执行时间越短,效率越高。 测试平台的具体参数包括:8个计算节点(Intel i7的3.2 GHz主频处理器,8 GB内存。节点之间的通讯为Intel 82574L芯片组主板,双网卡,带宽为1 GB/S。 Hadoop分布式平台的版本为2.2,JDK的版本为1.8.0。其中一个节点上部署JobTracker,另外7个节点上部署TaskTracker。每个TaskTracker上有1个reduce工作slot和2个map工作slot,每个物理主机的IP地址配置如表2所示。 表2 Hadoop云平台的物理主机的配置 所有物理主机上都安装Linux操作系统,Hadoop的主目录安装在usr/local/hadoop,同时在profile文件中修改和配置好环境变量: # /etc/profile export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/usr/local/hadoop export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH 为了比较普通的关联规则挖掘Apriori算法和基于MapReduce的并行关联挖掘Apriori算法的性能,文中采用了Kddcup数据集。Kddcup数据集是在网络入侵检测中采用的最常见的标准Benchmark数据集[15],它也是一个在国内外最有代表性和影响性的网络入侵检测数据集。该数据集中的记录主要被划分为两个部分:用于训练的数据集和用于测试的数据集。训练数据集具有一个具体的鉴定符,测试数据集没有鉴定符。测试数据集也包括不在训练数据集中的一些攻击类型,这样就使得系统的网络入侵检测能力更加的真实可信。 (1)精确度比较。 模拟地攻击数据包,并将其保存到日志文件中,实验中一个大约有2 000个攻击数据包,用来测试并行关联挖掘算法的有效性。算法的预检测引擎可以丢弃那些认为是正常的数据包,减少没有必要的异常检测。 公式(10)很好地体现了网络入侵检测系统的错误检测率(error detection rate,EDR)[16]: (10) 其中,MP表示丢弃的攻击包的数量,DP表示网络入侵中所有攻击包的数量。文中关联规则挖掘Cloud-Apriori算法完成网络入侵检测的结果见表3和表4(分别表示传统的Apriori算法和基于Cloud-Apriori算法并行关联挖掘的结果)。 表3 传统的关联挖掘的网络入侵检测 表4 基于Cloud-Apriori的关联挖掘的网络入侵检测 通过比较表3和表4可以看出,基于Cloud-Apriori算法的网络入侵检测的性能只有少量的改善,不是很明显,这是因为文中的并行关联挖掘算法只是在任务执行阶段完成了并行处理操作,所以整个算法的检测精度只有少量提高。 (2)入侵检测速度和效率的比较。 前面的实验主要针对检测精度,这部分完成传统的Apriori关联规则挖掘算法和基于MapReduce的Apriori并行关联挖掘的算法的时间比较,如表5所示。 表5 传统和并行的网络入侵检测速度的比较 从表5可以看出,当需要检测的数据尺寸比较小的时候,MapReduce的Apriori关联挖掘的优势还体现不出来,它的消耗时间有时比传统的Apriori关联挖掘还要多。尽管如此,随着数据容量的不断增加,基于Cloud-Apriori算法的关联挖掘逐步体现出它的优势,特别是当遇到海量大数据的时候,传统的Apriori关联挖掘甚至无法完成网络入侵检测,而基于Cloud-Apriori算法的关联挖掘可以充分利用分布式并行计算的优点,它的执行过程不受数据容量的限制,这也是早期很多传统的软件都被淘汰的原因,不适应近年来的大数据、云计算技术的发展。 为了进一步验证和分析基于MapReduce的并行关联挖掘的网络入侵检测方法的执行时间,改变了物理主机的数量,图4显示了在相同的数据容量条件下,不同的物理主机数目的执行时间比较。 图4 随着物理主机个数变化的执行时间比较 从图4可以看出,当数据容量相同的时候,物理主机从2增加到7个,执行时间平缓减少,执行效率也平稳增加。 当物理主机个数到了6~7个的时候,执行时间越来越平稳,表明Cloud-Apriori算法并行关联挖掘的算法可以很好地提高网络入侵检测的速度。它也证明Hadoop集群计算虽然可以提高速度,但是加速的比例是缓慢的,因为大数据处理是一种数据密集型应用,不能线性地降低处理时间。 该文提出了基于MapReduce并行关联挖掘的网络入侵检测算法,利用Benchmark数据集和网络入侵检测这种大数据应用对算法效果进行了仿真。结果表明,Cloud-Apriori算法比传统的Apriori算法有更好的分类精度和更少的运行时间。但是,Hadoop是一个比较低版本的开源的云平台,下一步的工作将关联挖掘Apriori算法移植到更高级别的云计算平台,以进一步提高关联规则挖掘算法的速度与效率。
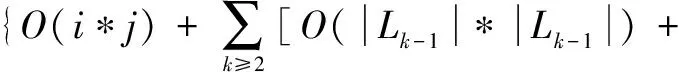
3 系统测试与性能分析
3.1 测试环境
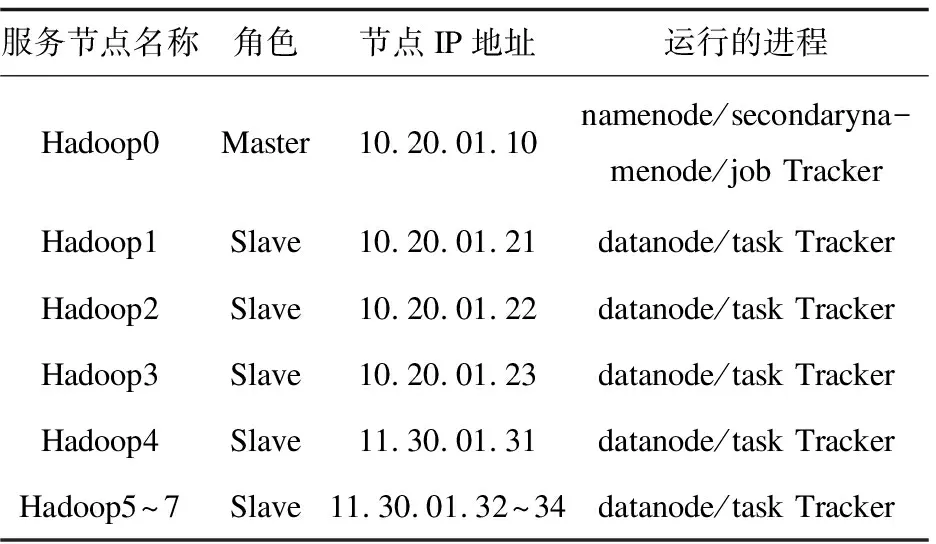
3.2 实验数据
3.3 入侵检测的性能分析


4 结束语
猜你喜欢
中国现代医生(2022年21期)2022-08-22导航定位学报(2022年4期)2022-08-15消费电子(2022年5期)2022-08-15现代电子技术(2022年4期)2022-02-21智能计算机与应用(2021年4期)2021-06-05当代陕西(2019年15期)2019-09-02华东师范大学学报(自然科学版)(2019年3期)2019-06-24学苑创造·A版(2018年11期)2018-02-01电子技术与软件工程(2016年24期)2017-02-23读者(2017年5期)2017-02-15
