
基于数据挖掘技术的中长期负荷预测方法
2021-07-07 03:29钱霜秋吴仲麒王资远
电气技术 2021年6期
张 敏 钱霜秋 吴仲麒 王资远
(1. 国网江苏省电力公司南通供电公司,江苏 南通 226000; 2. 天津天电清源科技有限公司,天津 300000)
0 引言
电力负荷的中长期预测可以帮助电力部门做年度规划、调度计划及检修计划,对变电站选择建址、制定规划也有着重要的指导意义[1]。但经济社会、产业结构、相关政策、气候条件、电价水平等多种因素互相交织影响、关系复杂,难以区分出各类因素对中长期负荷的影响水平[2]。针对中长期负荷预测国内外学者已进行了大量研究,主要研究方法是构建电力负荷历史时序数据与各类影响因素的相关性数学模型,然后通过时序外推法实现预测,但是这类方法预测精度不高,非线性拟合能力差[3]。
近年来,基于智能技术的负荷预测方法主要应用在中长期负荷预测中。文献[4]采用改进的进化算法——基因表达式编程算法解决了传统算法容易陷入局部最优的问题,但存在过拟合的问题。文献[5]采用长短期记忆(long-short term memory, LSTM)神经网络,将历史负荷数据、气候、经济等影响因素数据整合到模型中,有效解决了过拟合的问题,但是LSTM神经网络用于短期负荷预测较多,在中长期预测中精度不高。文献[6]利用主成分分析法对负荷的影响因素进行特征提取,降低数据维度,然后与BP(back propagation)神经网络模型相结合,有效克服了收敛速度慢和容易陷入局部最优的缺陷,虽然主成分分析法可以消除变量值间的相互影响,但是降维不可避免地会使变量意义不明确。文献[7]先使用关联矩阵筛选出强相关因素,然后使用时间序列法X12-ARIMA(autoregressive integrated moving average model)模型对负荷和影响因素进行分解,但是非线性拟合度较差。最近几年,科研人员又提出一种新的思路,即先使用聚类分析,将海量的负荷数据聚类,然后再对这些簇类分别进行预测,最后每类负荷的预测值之和就是整个负荷数据的预测值。文献[8]基于K-均值(K-means)算法对农村发展模式进行聚类,针对不同农村发展模式进行预测,最终验证了方法的可行性,但是K-means是一种硬划分聚类算法,一些馈线负荷可能属于不同的行业,但是却具有相似的用电特性。文献[9]采用模糊C均值(fuzzy C-means, FCM)聚类法改善了聚类算法用于负荷分类时不够精确的缺陷,但是其在考虑影响因素时预先建立了影响因素关联度矩阵,并未达到精细化探究影响因素相关关系的目的。
综上所述,本文在考虑负荷预测时,先采用模糊C均值聚类分析方法使馈线负荷数据按照彼此相近的负荷特性划分为同一簇类,随后使用相关性分析和灰色关联分析挖掘出不同馈线簇类的差异化影响因素中对各类馈线影响较大的因素;径向基(radial basis function, RBF)神经网络具有模型结构简单、预测精度高且适用于大数据大样本的优点,因此最后选用RBF神经网络对各簇类馈线负荷进行电力需求预测。图1为本研究的技术路线。
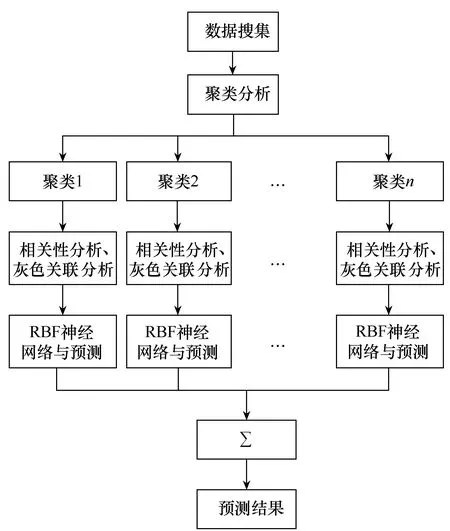
图1 技术路线
1 聚类算法
聚类算法是数据挖掘中常用的一种算法,按照一定的计算规则把一些未知类型的数据分为具有相似特性的若干簇类[10]。聚类分析算法可以作为其他数据挖掘算法的数据预处理步骤,也可以作为一个独立的数据挖掘算法进行信息挖掘,从而进行数据特性研究。我国现行的传统负荷分为:农业负荷、工业负荷、商业负荷、城镇居民及其他负荷四大 类[11]。在电力负荷预测中,可通过聚类分析算法把海量的负荷数据聚类,对用户负荷进行更为细致的分类。本文采用FCM算法对馈线日负荷特性数据进 行聚类分析[12]。
相较于传统的“硬划分法”——“非此即彼”,FCM算法是一种“软划分”的方法,即通过模糊聚类得到样本属于各个类别的隶属程度,突破了样本仅属于一个分类的界限,表达了样本的“中间性”[13]。FCM聚类方法属于基于目标函数的模糊划分法[14]。FCM算法引入隶属度的概念,以一种模糊的形式划分表示样本属于各聚类中心的隶属程度。对于给定的 数据集合,X划分为c(2≤cn≤ )类,聚类中心向量为,令表示jx属于第i类的隶属度,隶属度矩阵为,且有。
FCM算法的目标函数是基于欧式距离判定样本隶属程度,目标是使目标函数值达到最小。其目标函数为
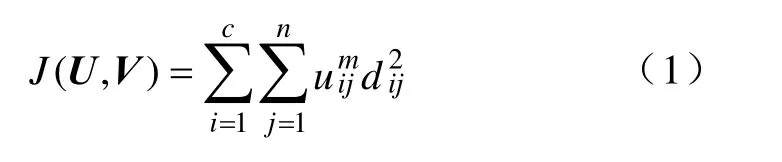
式中:dij为样本ijx到聚类中心vi之间的欧氏距离;m为模糊加权指数(m>1)。算法步骤如下:
1)设置目标函数精度 0ε>。
2)初始化模糊聚类中心。
3)计算隶属度。
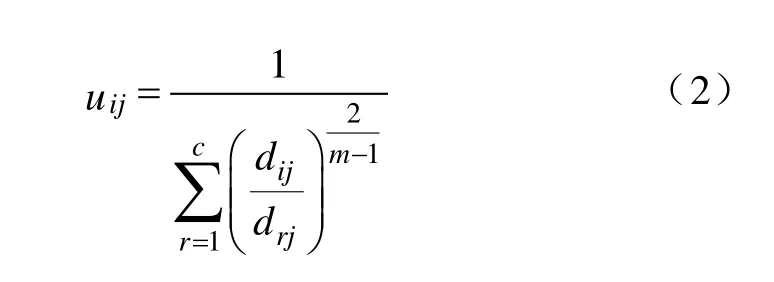
4)计算聚类中心。

5)若式(4)满足范数矩阵式,则停止迭代;若不满足,则设置 1kk= +,转向步骤3)。

2 相关性分析和灰色关联分析
相关性分析可以定量地衡量两组数据之间的相关程度,因此做相关性分析的数据都应该是成对出现的[15]。本文采用Pearson相关系数作为度量指标,Pearson相关系数计算式为[16]根据表1确定变量间的相关强度。

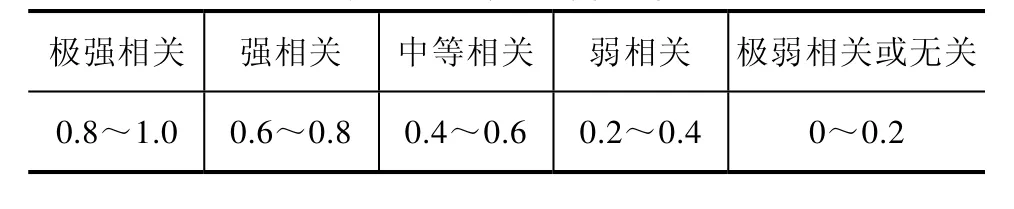
表1 相关强度明细
本文对采集到的信息先采用相关性分析,剔除相关性较弱的影响因素,对剩下的影响因素进行灰色关联分析,分析出电力需求与其他影响因素的关联程度,从而使对电力需求的预测更加精确。灰色关联分析的主要技术路线如下[17]:
2)数据变换。对原始数据进行处理变换,保证灰色关联分析在同一量纲下进行。本文采用极差最大化变换方法,即
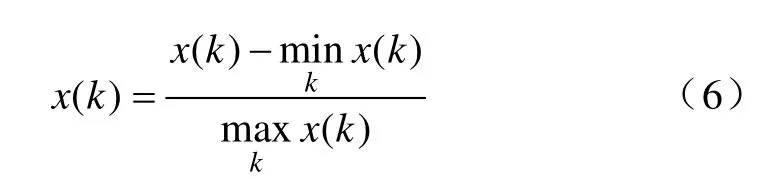
3)计算关联度。采用典型的关联度模型——邓氏关联度模型,Xi与 0X的关联度为
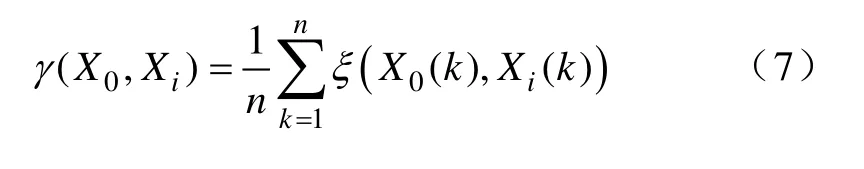
式中:X0(k)为参考序列数据变换后的序列,即馈线数据;Xi(k)为比较序列,即经相关性分析筛选后的影响因素序列;ξ(X0(k),Xi(k))为关联系数,有

一般灰色关联分析不评价关联强度,而是关注于比较序列的关联度排序,评价哪种因素与参考序列关联度最高。本文选择关联度最高的前两个因子作为影响因素集合。
3 神经网络模型
神经网络模型是一种模仿动物神经网络行为特征,可以自行根据环境变化总结规律完成识别与控制的模型,其基本工作原理如图2所示。一个神经网络由许多神经元构成,一般包括三个层级——输入层、隐藏层、输出层[18]。输入层用于接收外界输入信息,输入层的神经元数量与输入变量有关,每个输入变量都应有一个对应的输入节点,外加一个偏置节点构成输入层;输出层则是为了输出最终的预测结果;隐藏层介于输入层和输出层之间,实现输入层到输出层的线性变换[19]。

图2 神经网络基本工作原理
本文所使用的RBF神经网络从输入层到隐藏层为非线性变换,将输入直接映射到隐藏层,而不再需要权重链接,从隐藏层到输出层为有权链接。
RBF神经网络的基本思想是用径向基构成隐藏层,本文的隐藏层激活函数使用高斯函数,即
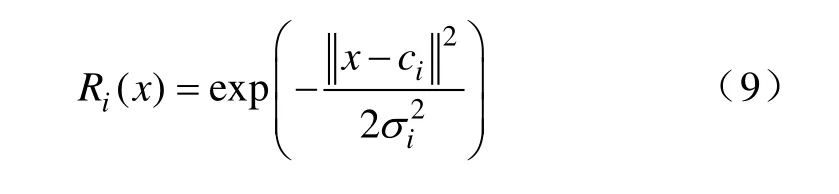
式中:ci为第i个基函数的中心值,与输入向量同维数;σi为基函数第i个中心点宽度的标准化常数;为x和ci的距离。
4 算例分析
本文选取江苏省南通市2019年7月最大负荷发生日4 299条馈线的96点日负荷曲线数据,利用FCM聚类算法对这些用户进行聚类,综合比较下,可分为18类聚类,随机选取其中8类馈线簇进行举例,分析用电特征。图3为经归一化处理的聚类中心馈线负荷曲线,图3(a)为用电水平较低的馈线,图3(b)为用电水平较高的馈线。图中,纵轴表示用电水平,横轴表示一天内从00:00—23:45时段内96个时间点。可以总结出这8种聚类的用电特征:聚类1的馈线全天处于较高的负荷水平,具有三个用电高峰期,可能为三班倒工作制,属于需要全天高负荷工作的重工业;聚类5的馈线整体负荷水平不是很高,且表现出白天休息晚上工作的特征,应为以公共照明为主的公共服务业;聚类6的馈线在11:00—12:00迎来第一个用电高峰期,在晚上18:00—22:00迎来用电最高峰,其中20:00达到最高负荷,应属于以餐饮业为主导的服务业;聚类8的负荷用电高峰在10:00—21:00,且中间用电水平未出现过明显低谷,应为商业或金融业用户;聚类11的总体用电较为稳定,应为两班制的轻工业负荷;聚类14整体用电水平不高,且表现出白天休息晚上工作的特征,应为夜班制的轻工业用户;聚类16的用户全天都有较高的用电水平,且在20:00—22:00有一个用电高峰,应为全天工作的工业主导的用户,且会在白天避开其他负荷用电高峰,在晚上投入更多的负荷;聚类17整体用电水平较低,具有三个用电高峰,应为公共服务业[20]。

图3 经归一化处理的聚类中心馈线负荷曲线
对得到的负荷特征曲线进行相关性分析和灰色关联分析,分别考虑外部因素对这八类用户特征的影响。本文采用南通市2016~2019年电力消费数据 和GDP、第一产业增加值、第二产业增加值、第三产业增加值、规模以上工业增加值增长率、人均GDP、城镇化率、城镇居民人均可支配收入、城镇居民人均住房建筑面积、居民消费价格总指数等数据作为原始数据进行相关性分析和灰色关联分析,数据来源于江苏省年鉴及南通市政府工作报告。表2为电力需求数据与其他外部因素的皮尔逊相关分析数据。在经过相关性分析后,提取出各聚类结果中相关性为强的因素,进一步做灰色关联分析,得出关联性更强的影响因素,以聚类1和聚类6为例进行实例说明。

表2 相关分析结果
由上述用电特征分析可知,聚类1应为重工业馈线,其受到经济类因素影响较强,受规模以上工业增加值增长率影响也比较强,这与相关分析结果是一致的,聚类6应为餐饮服务业为主的馈线聚类,受经济类和社会发展因素影响比较大,受第三产业影响比较大,这两种聚类对于气候因素的影响都不敏感,接下来做灰色关联分析。表3和表4分别为聚类1、6的灰色关联分析结果。

表3 聚类1灰色关联分析结果(保留四位有效数字)

表4 聚类6灰色关联分析结果(保留四位有效数字)
分析表3和表4结果,与聚类1关联度最高的为GDP和第二产业增加值,与聚类6关联度最高的是GDP和城镇居民人均可支配收入。
使用SPSS Modeler数据挖掘软件做神经网络预测,以最大负荷发生时刻每类聚类的负荷作为历史数据,然后将关联性较强的作为影响因子与历史数据一起作为输入,组成神经网络原始数据,进行负荷预测。
以聚类1和聚类6负荷预测过程为例,其中聚类1的输入层为2016~2019年时间序列负荷值与同时期GDP和第二产业增加值,输出层为2020年最大负荷时刻负荷值;聚类6的输入层为2016~2019年时间序列负荷值与同时期GDP和人均可支配收入,输出层为2020年最大负荷时刻负荷值。
应用SPSS Modeler数据挖掘软件,选用RBF神经网络-增强模型准确度模块,构建负荷预测模型,设定训练分区比例为80%,测试分区比例为20%,预测结果见表5。

表5 神经网络预测结果
各聚类的预测值之和即为总馈线负荷预测结果。为验证本方法的有效性,与线性回归模型、不考虑聚类的RBF神经网络预测模型(输入层为2001~2019年年最大负荷时刻负荷值,输出为2020年年最大负荷时刻负荷值)对比,结果见表6。
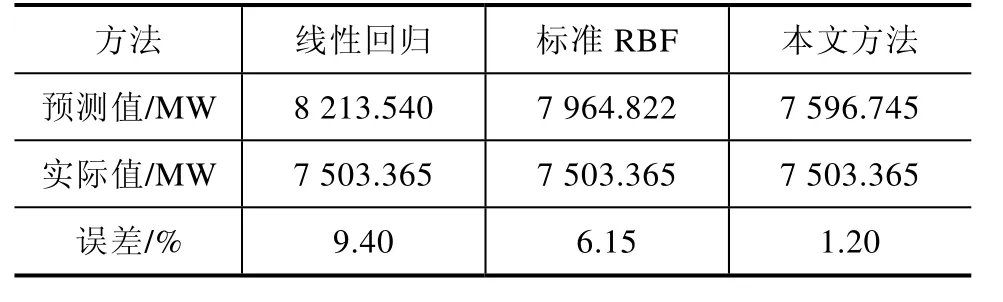
表6 结果对比
传统的线性回归法面对海量复杂的数据时无法建立准确模型,不能很好地拟合非线性数据,而本研究基于数据挖掘技术,能对海量电力数据进行有效挖掘处理,因此预测精度明显提高,而电力负荷之间由于用电行为不同,用电规律也有所不同,使用聚类算法将馈线分类后再分别进行神经网络预测有效提高了预测精度。
5 结论
本文经过研究多篇文献,对模糊算法进行了分析对比,最终选用模糊C均值算法对负荷数据进行聚类。案例数据选自南通市2019年7月最大负荷发生日的日负荷曲线,对各馈线进行汇总聚类,得出八个不同用电特征的聚类结果。对具有不同特征的负荷分别进行相关性分析,找出对电力消费起到强作用的影响因素。以聚类1负荷为例,GDP、第一产业增加值、第二产业增加值、人均GDP、城镇居民人均可支配收入等因素对聚类1的用户具有强关联的影响作用,将这些影响因素与电力数据一起用神经网络进行优化,最终得出聚类1的预测结果。
本文采用聚类、相关性分析、关联规则、神经网络等数据挖掘技术使电力数据得到有效利用,并且使预测结果比传统方法预测结果更加精确。本文提出的基于数据挖掘的方法可为负荷预测、负荷控制甚至电价的制定提供指导。
猜你喜欢
卫星电视与宽带多媒体(2022年10期)2022-07-01
中学生数理化·中考版(2020年12期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
活力(2019年15期)2019-09-25
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
西部广播电视(2015年7期)2016-01-16
西部广播电视(2015年7期)2016-01-16
