
模糊集合隶属函数的确定方法及实验
2021-07-14 02:04梁蓉蓉潘小东
四川师范大学学报(自然科学版) 2021年4期
梁蓉蓉, 潘小东
(西南交通大学 数学学院,四川 成都611756)
1965年,美国控制论专家Zadeh[1]引入了模糊集合的概念.模糊集合是描述和处理模糊信息的一种重要数学工具,其基本思想是在绝对真(用1表示)和绝对假(用0表示)之间增加额外的真值,用以模拟事物之间差异的中介过渡过程,即利用一个从论域U到[0,1]的函数(隶属函数)来模拟模糊概念(如青年、高个子等)的外延.经过50多年的研究与发展,模糊集合在理论和应用取得了长足进步,目前已成功应用于诸如聚类分析、图像识别、自动控制、人工智能等研究领域[2-5].对于模糊集合的理论和应用至关重要的问题是:如何确定隶属函数和又如何判断所确定隶属函数的合理性.
研究者已提出各种确定模糊集合隶属函数的方法,包括模糊统计法、二元对比排序法、插值法、模糊分布法、专家调查法等[6-7].模糊统计法的思想是基于统计实验,让被调查者就某个模糊概念(记为A),各自给出自己认为合适、清晰的外延集,通过计算这些外延集关于元素x的覆盖频率,获得x关于模糊集合A的隶属度,但此方法计算量巨大,且合理性有待进一步验证.二元对比排序法根据对象间的对比关系来确定它们关于某个模糊概念的外延隶属程度.模糊分布法借鉴概率论思想,事先给定若干类型模糊集合的隶属函数,如矩形分布、梯形分布、正态分布、柯西分布、Z型分布等.对于某个具体的模糊概念,根据其内涵和特点选择合适的模糊分布函数,设定相应参数从而确定隶属函数,但这2种方法缺乏必要的理论依据,且具有较强主观性.
针对上述确定隶属函数方法存在的问题,研究者开始尝试其他解决途径,方法之一就是对Zadeh的模糊集合概念进行扩展.1975年,Zadeh[8]提出了二型模糊集合概念,采用语言值(如“非常真”“十分假”等)来表示元素关于模糊集合的隶属度.1976年,Grattan-Guinness[9]将元素关于模糊集合的隶属度从区间[0,1]上的一个实数扩展为区间[0,1]的一个闭子区间,并由此建立了区间值模糊集理论.1986年,Atanassov[10]提出了直觉模糊集合概念,通过引入“非隶属度”,直觉模糊集能从正反两方面刻画事物的模糊性.2002年,刘心等[11]提出了扰动模糊集.2010年,Torra[12]提出了犹豫模糊集的概念.为便于人们能够准确理解二型模糊集合,2014年,莫红等[13]通过引入多值映射来定义二型模糊集合的主隶属度,运用常规映射定义次隶属度,给出了二型模糊集合新定义,提出了FOU划分法来表述连续区间二型模糊集合.
将上述几种模糊集进行交叉、融合,还可以得到其他类型模糊集合.2012年,Zhu等[14]将犹豫模糊集与直觉模糊集进行结合,首次提出了对偶犹豫模糊集.同年,赵涛等[15]在二型模糊集和直觉模糊集基础上,给出了二型直觉模糊集概念,证明通过特定变形,二型直觉模糊集可成为一型模糊集、直觉模糊集、区间值模糊集、区间值直觉模糊集的广义形式.2014年,吴婉莹等[16]将对偶犹豫模糊集概念拓展到区间值,提出了区间值对偶犹豫模糊集.2017年,王飞跃等[17]采用集合论的方法给出了单位模糊集合和二型模糊集合及其在一点的限制等定义.根据论域、主隶属度及隶属函数的特性对二型模糊集合进行分类,提出了一些与二型模糊集合相关的结论.周林涛[18]研究了复杂环境下基于二型模糊集的多因素决策方法.李丽颖等[19]提出了区间值对偶犹豫模糊集距离与相似性测度之间的关系,给出了区间值对偶犹豫模糊集的距离公式及熵公式,由此给出基于区间值对偶犹豫模糊熵的权重模型,应用于权重未知的区间值对偶犹豫模糊多属性决策问题.这些模糊集合的扩展研究极大拓广了模糊集理论的研究思路,丰富了模糊集理论及应用的研究内容,对其发展具有重要意义.然而,无论采用语言值、区间值,还是加入非隶属度,这些拓展在隶属函数的确定及其合理性验证依然存在问题.如果无法弄清楚对象x隶属于模糊集合A的隶属度程度到底是0.7还是0.8,那么同样无法弄清楚用哪个语言真值或者哪个区间来表示更合适.
近年来,不断有学者提出各种模糊集合隶属函数的确定方法.1995年,李德毅等[20]提出隶属云的新思想,给出了用数字特征描述隶属云的方法和正态隶属云的数字模型.2004年,李德毅等[21]利用云模型把随机性和模糊性结合起来,用数字特征熵揭示随机性与模糊性的关联,并以此表示一个定性概念的粒度.正态云模型通过期望、熵和超熵构成的特定结构发生器,生成定性概念的定量转换值,描述概念的不确定性.2008年,袁杰等[22]提出了采用最小二乘法拟合离散数据来获得隶属函数.2010年,于少伟[23]提出了利用区间数的方法确定隶属函数.2015年,王晓娟[24]提出利用改进型BP神经网络建立模糊集隶属函数的设计方法,给出了设计步骤,并应用于实例中,仿真结果表明此方法具有一定的有效性和可行性.2016年,马万元等[25]从统计学的角度提出了一种基于概率统计的模糊隶属函数计算方法.
然而,上述方法也未能真正解决模糊集合隶属函数的确定问题.因为建立一种科学的确定模糊集合隶属函数的方法,首先需要弄清模糊集合旨在刻画的对象究竟是什么,需要深入分析模糊现象,并以模糊现象的本质及其主要特征做为建立相应数学理论和方法的出发点,否则我们的研究势必成为无本之木,然而上述方法并未充分考虑这一点.在文献[26]中,对模糊现象的本质及其主要特征进行深入分析,提出了关于模糊现象本质及其特征的新观点;在此基础上,Xu等[27-28]建立了隶属度公理系统,并以此给出了模糊集合的公理化定义.
本文在模糊公理系统框架下,基于文献[26]所提出的关于模糊现象本质的新思想,通过设计统计实验,深入分析影响模糊集合隶属函数确定的关键因素,并在此基础上,提出关于确定模糊集合隶属函数的一般性原则.
1 模糊集合的公理化
1.1 模糊现象的本质文献[26]认为模糊性产生于对对象进行分类的过程中,是事物发展、演化过程中连续性、渐进性的一种表现形式,同时是事物本身连续性、渐进性和人类主观认知方式共同作用的结果.因此,模糊现象是模糊性的外在表现形式,它产生于模糊划分,并将事物发展、演化的连续性过程“离散化”.
一种常见的将事物发展过程中连续性、渐进性“离散化”的方法就是使用自然语言,即通过有限个模糊谓词来描述事物所具有的某种属性,或者说是自然语言提供一种将事物发展过程中的连续性、渐进性离散化的有效方法.因此,模糊现象经常与自然语言的使用联系在一起,模糊谓词即是连接“连续”和“离散”之间的桥梁.
1.2 模糊划分的定义基于对模糊现象本质及其特征的认识,文献[27-28]给出了模糊划分的定义.
定义1[27-28]设U= [a,b]⊂R.定义在U上的一个模糊划分是由定义在U上的n个函数所构成的集合,即
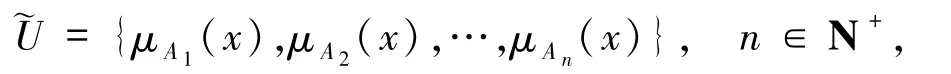
其中,μAi:U→[0,1](i=1,2,…,n)定义了元素x∈U隶属于模糊子类Ai的隶属程度,并且满足下列条件:
1)∀x∈U,∃i∈使得
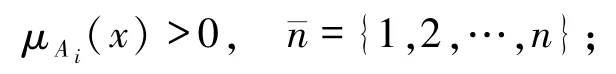
5)∀x∈U,有
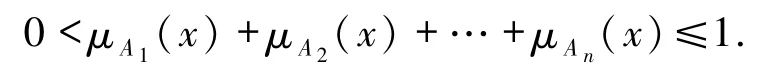
若U上的一个模糊划分~U满足
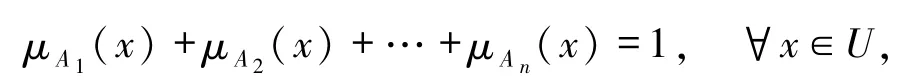
由模糊性本质和定义1可知,模糊集合产生于模糊划分,其隶属函数是对模糊划分之下模糊子类的数学描述,因而模糊集合隶属函数的确定会受到模糊划分的影响.但以上仅为理论分析,模糊划分对隶属函数确立的影响还缺少必要的实验研究,此外还需探明确定模糊集合隶属函数时的关键性因素.本文基于模糊现象本质及其主要特征,通过设计统计实验,深入分析影响模糊集合隶属函数确立的关键性要素,特别是模糊划分对隶属函数的影响.
2 实验研究
2.1 实验方案统计实验分为2组:第1组在无模糊划分条件下进行,第2组在模糊划分条件下进行.实验采用抽样调查的方法,通过发放调查问卷的方式收集实验数据.实验的调查问卷如下:
第1组实验调查问卷包含以下问题:
1)据资料记载,人的身高范围在0.55~2.5 m.按照您的理解,您认为“高个子男子”的身高范围应该是________(单位:m.例如:[1.8,2.5]);
2)您认为“中年人”所指的年龄区间应该是________(单位:岁.例如:[50,70]).
第2组实验调查问卷包含以下问题:
1)据资料记载,人的身高范围在0.55~2.5 m.如果把男人按身高分为3类:矮个子、中等个子、高个子.请根据您自己的理解,分别写出这3类男人各自的身高范围__________(单位:m.要求这3个区间互不相交且完全覆盖区间[0.55,2.5].例如:[0.55,1.5]、[1.51,1.79]、[1.8,2.5]);
2)世界卫生组织把人按年龄分为5类:未成年人、青年人、中年人、老年人、长寿老人.请您根据自己的理解分别写出这5类人分别所对应的年龄区间__________(单位:岁.要求这些区间互不相交且完全覆盖区间[0,134],134岁是目前吉尼斯记录认证的人的最高寿命).
2.2 数据收集及处理调查问卷在西南交通大学学生群体中采用随机抽样方式进行发放,为避免被调查者填写问卷时受惯性思维影响,2组问卷分别发放给2组不同被调查对象.2组问卷共计发放630份,收集到2组有效调查问卷共计600份.对收集到的原始数据进行整理及预处理,主要审核数据完整性和准确性,准确性审核主要是检查数据是否有误,是否存在异常值等.经预处理后的有效数据见表1.
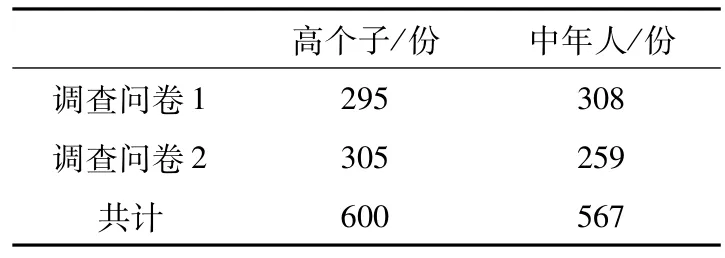
表1 调查问卷有效份数Tab.1 The valid number of questionnaires
2.3 关于实验结果的分析1)模糊集合隶属度稳定性、一致性分析.图1(a)和(b)分别为无模糊划分和有模糊划分条件下,高个子隶属度与实验次数的关系曲线图.图2与图3为无模糊划分和有模糊划分条件下,“高个子”和“中年人”这2个模糊概念的隶属函数图像对比.
由图1可知,对同一模糊概念,随实验次数增加,有模糊划分之下使用模糊统计法确定的隶属度具有更好的稳定性.由图2可知,在模糊划分下被调查者认为1.95 m是高个子的程度是0.983 6,随身高增加,是高个子的程度趋近于1,由此可认为身高大于等于1.95 m的人都是“高个子”;而无模糊划分下,“高个子”的隶属函数图像在身高为1.9 m时达到最大值0.932 2,之后随身高增加,属于高个子的程度逐渐降低,最终稳定于0.63,但这与认知不一致.通过分析问卷1的数据发现,被调查者在填写“高个子”所对应的区间时,具有一定的“随意性”,即被调查者在填写区间时写下自己认为是“高个子”的区间,但是所给出的区间就会出现类似于区间[1.8,2.2];而问卷2是在给出模糊划分的限制条件下,使得被调查者对“高个子”这一模糊概念更明确,给出的区间都类似于区间[1.8,2.5].“随意性”产生的原因是在收集数据时,对模糊概念的限制条件太少.由图3可发现,“中年人”的隶属函数图像在模糊划分下比未给出模糊划分下要更符合认知.通过上述分析,对于同一模糊概念,在已知模糊划分条件下,采用模糊统计法确定的隶属度具有更好的稳定性和一致性.
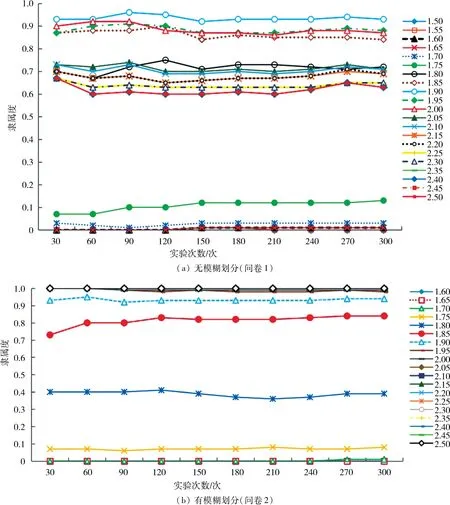
图1 高个子隶属度与实验次数关系曲线Fig.1 Relation curve between the tall and test times

图2 高个子隶属函数对比曲线Fig.2 The contrast chart of membership function of the tall

图3 中年人隶属函数对比图Fig.3 The contrast chart of membership functions of middle-aged people
2)模糊划分下模糊集合隶属函数对定义1符合程度分析.表2为问卷2中关于模糊概念“矮个子”“中等个子”“高个子”数据,基于模糊统计法计算论域中任意一个元素x对这3种模糊概念的隶属程度.图4为表2所对应的隶属函数图像.利用相同计算方法,图5为“未成年人”“青年人”“中年人”“老年人”和“长寿老人”的隶属函数图像.
由表2可知,论域U=[0.55,2.50]中的每一个元素x,都对应一个模糊子类Ai,使得 μAi(x)>0.对于每一个模糊子类Ai都有一个元素x,使得μAi(x)=1或趋近于1.在已知模糊划分下,各模糊概念的隶属函数在最大值左侧不减,在最大值右侧不增,如图4所示.对于论域中任意一个元素x,有
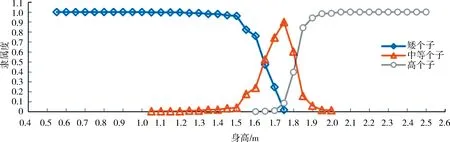
图4 矮个子、中等个子、高个子隶属函数曲线Fig.4 The curve of membership function of the short,the medium and the tall
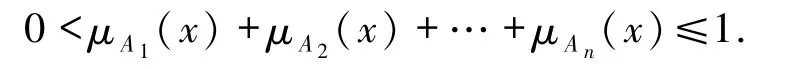
如表2中,1.7 m对矮个子的隶属度是0.245 9,对中等个子的隶属度是0.744 3,对高个子的隶属度是0.009 8,而0.245 9+0.744 3+0.009 8=1.上述性质对属性年龄的模糊子类隶属函数仍符合,如图5所示.
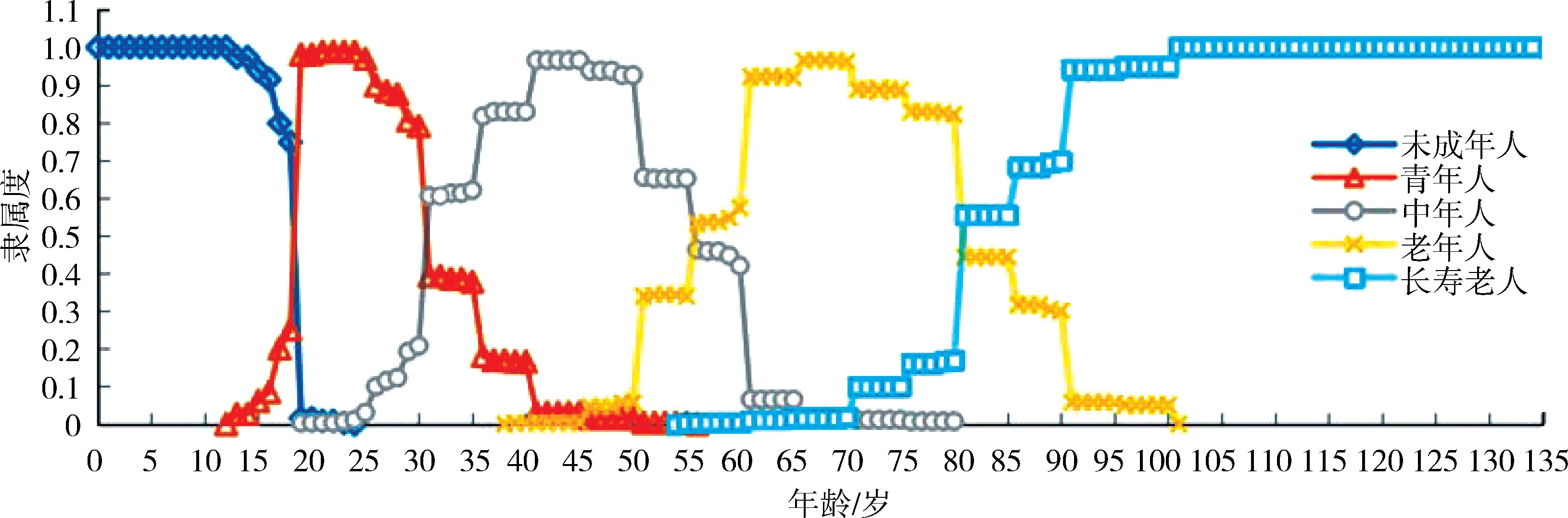
图5 未成年人、青年人、中年人、老年人、长寿老人隶属函数曲线Fig.5 The curve of membership function of the young,the middle-aged,the elderly,and the long-lived elderly
3)模糊集合隶属函数的波动分析.图6与图7分别为模糊概念“高个子”与“中年人”各自论域中每一个元素在无模糊划分和有模糊划分下的隶属度方差.可知,整体上隶属函数在无模糊划分条件下波动振幅较大,而在有模糊划分下较稳定,波动较小.这说明被调查者在模糊划分下对模糊概念的理解更清晰化,而在部分点(如图6中的身高1.75 m)或部分区间(如图7中的[51,60]),在模糊划分下隶属度的波动振幅大于无模糊划分下隶属度的波动振幅,这是因为问卷2在给出模糊划分的条件下,让被调查者分别给出同一属性的各模糊子类所对应的区间.这些波动较大的元素或区间可看成是2个相邻模糊子类的“分界点”,在“分界点”处的隶属度波动比较大的原因在4)中会进行说明.由图2和图3可明显观察出,未给出模糊划分的隶属函数的跨度比模糊划分下隶属函数的跨度要大.由上述分析可知,在未给出模糊划分的条件下,隶属函数呈现出较大波动振幅和跨度,且在边界处波动更为明显.
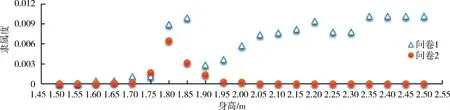
图6 高个子隶属度方差Fig.6 The variance of membership degree of the tall

图7 中年人隶属度方差Fig.7 The variance of membership degree of the middle-age
4)模糊集合隶属函数的图像分析.如图2~5所示,属性身高的每一个模糊子类的隶属函数图像都较光滑,而无论是否有模糊划分,属性年龄的每个模糊子类的隶属函数图像都存在间断点.问卷1要求被调查者给出恰当的区间,即传统模糊统计法,问卷2在此基础上加入了模糊划分这一前提条件.由于不同被调查者受家庭背景、教育程度、人生阅历、性格等影响,所以给出的区间端点存在一定差异,“分界点”的产生也源于此,从而出现间断点,这也是模糊统计法确定隶属函数所存在的缺陷.由图2和图3也可发现,对于同一模糊概念,在给出模糊划分前提条件之下,隶属函数图像的间断点要比无模糊划分下更少.
3 基于模糊划分确定模糊集合隶属函数的一般原则
由统计实验可知,在模糊划分之下,每个模糊划分子类所对应的模糊集合隶属函数在总体上符合定义1中关于模糊划分的5个条件.基于定义1和本文对实验结果的分析,提出基于模糊划分确定模糊集合隶属函数的一般性原则:对于某个模糊谓词(如:中年人),可以采用如下方法确定其隶属函数:
1)确定产生该谓词的模糊划分,如前文所述,模糊谓词产生于模糊划分,例如“中年人”所在的模糊划分为{青年人,中年人,老年人};
2)确定该谓词所对应属性的取值范围,例如“中年人”所对应的属性是“年龄”,年龄的取值范围为U=[0,150];
3)在取值范围U中,分别确定模糊划分中的每个模糊谓词所对应的标准点或标准区间,即使得关于模糊划分中的模糊谓词的隶属度为1的点或者其构成的集合,标准点或者标准区间可通过调查获得,例如“中年人”对应的标准区间为[45,50];
4)基于标准点或标准区间,利用定义1中的条件4)和5)即可大致确定出模糊划分中各模糊谓词所对应的模糊集合的隶属函数.
模糊集合的隶属函数仅是关于对象由量变到质变过程的数学描述,是一种近似的描述.该描述也符合一般性的规律,即符合一定范围内大多数人对模糊谓词的认识规律.从这个意义上讲,隶属度与概率类似.由大数定律知道,概率描述的是大量随机现象的平均规律.
4 结论
本文研究了模糊划分对模糊集合隶属函数的影响,通过2组实验对2个模糊属性值“高个子”“中年人”的隶属函数进行了对比分析.实验表明:在已知模糊划分条件下,采用模糊统计法确定隶属度具有更好的稳定性和一致性,且满足文献[27-28]中模糊划分定义的5个条件.在无模糊划分条件下,隶属函数的波动幅度和跨度更大.因此,模糊划分对模糊集合隶属函数的确立存在显著影响.此外,采用模糊统计法确定隶属函数时存在一个明显缺陷,即区间端点的确定易受社会观念影响,从而导致隶属函数出现间断点.
本项研究虽在一定程度上阐明了模糊划分对模糊集合隶属函数的影响,但由于所涉及的模糊谓词相对较少,实验的调查范围相对较窄,且实验所采集到的数据量也相对较少.因此,影响模糊集合隶属函数确定的关键要素及其影响机制,还需进一步研究,并通过更多的实验数据支撑,这将是今后工作的努力方向.
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31
湖北民族大学学报(自然科学版)(2021年1期)2021-04-02
数学大世界(2021年4期)2021-03-30
数学年刊A辑(中文版)(2021年4期)2021-02-12
山东农业大学学报(自然科学版)(2020年5期)2020-11-02
电子技术与软件工程(2019年24期)2020-01-18
西华大学学报(自然科学版)(2018年6期)2018-11-24
科教导刊·电子版(2017年17期)2017-07-25
初中生之友·中旬刊(2015年1期)2015-06-10
小小说大世界(2014年8期)2014-09-25
