
基于动态词典匹配的语义增强中文命名实体识别算法
2021-07-14 00:14陈曙东欧阳小叶
无线电工程 2021年7期
陈曙东,罗 超,欧阳小叶,李 威
(1.中国科学院大学 微电子学院,北京 100049;2.中国科学院 微电子研究所,北京 100029)
0 引言
自然语言处理(Nature Language Processing,NLP)是人工智能领域的热点研究方向,在机器翻译、语音识别、情感分析、问答系统、聊天机器人、文本分类和知识图谱等方面都有重要应用。命名实体识别(Name Entity Recognition,NER)[1-5]作为自然语言处理的一项基本任务,旨在从非结构化文本中识别出命名实体(如人名、地名和组织机构名)。
传统的命名实体识别方法主要包括基于规则[6]的方法、基于统计机器学习的方法以及二者混合的方法等。其中,基于规则的方法借助知识库和词典,利用语言学专家手工构造的规则模板进行命名实体的识别,是命名实体识别中最早使用的方法。基于统计机器学习的方法通过人工选取文本特征,借助融合语言模型和机器学习算法进行命名实体识别,代表性的方法主要包括隐马尔可夫模型[7]、最大熵[8]、支持向量机[9]和条件随机场(Conditional Random Field,CRF)[10-12]等。
近年来,随着基于神经网络的各类深度学习方法的快速发展,NER研究逐渐从机器学习转向深度学习。该类方法首先使用大规模的未标注语料进行词向量训练,然后通过将预训练的词向量输入到深度学习网络模型,用以实现端到端的命名实体识别。Huang等[13]利用双向长短时记忆(Bidirectional Long Short-Time Memory,BiLSTM)网络和CRF来进行命名实体识别,此模型获得较好的表现。相比传统机器学习方法,基于深度学习的方法通过自主学习而非人工方式从原始数据中获得更深层次和更抽象的文本特征,较好地解决了传统方法特征选取难度大和对数据的人为干扰等问题,因此成为研究热点。
与英文的NER任务相比,由于中文的句子中词组不是自然分开的,所以纯粹基于字符的中文NER方法的缺点是没有充分利用词组的信息,考虑到这一点,Ma等[14]提出了SoftLexicon模型,利用了词典匹配的方法,用词集标签“B,M,E,S”来表示字符在匹配的词组结果中的位置,再对每个词组的频率进行静态归一化,来表示词集标签的权重。但是,对于词组标签信息进行静态归一化,而不是动态地让模型学习词组标签的权重,会导致模型并不能自动学习到特征,当遇到词典中没有出现的词组时,模型就不能很好地对词集标签进行权重赋值。
针对词组静态归一化的不足,本文提出了基于动态词典匹配的语义增强中文NER(Semantic Enhanced Chinese NER algorithm Based on Dynamic Dictionary Matching,SEDDM)算法。新算法解决了SoftLexicon模型存在的静态归一化等问题,并且具有更优的性能,通过在不同数据集上的实验测试,结果有效验证了新算法的实体识别准确率更高。
1 相关工作
在初始的中文NER中,常见做法是,先使用现有的中文分词(Chinese Word Segmentation,CWS)系统进行分词,然后将词级序列标记模型应用于句子的分割[15]。然而,CWS系统不可避免地会出现对语句的错误分割,导致实体边界的划分和实体类别的预测错误。因此,He等人[16]提出基于字符的中文NER,被证明是有效的。Huang等人[13]使用BiLSTM进行字符特征提取并使用CRF进行解码,该方法已实现较好的性能。其中,BiLSTM-CRF 模型是解决文本序列标签问题的基准模型。
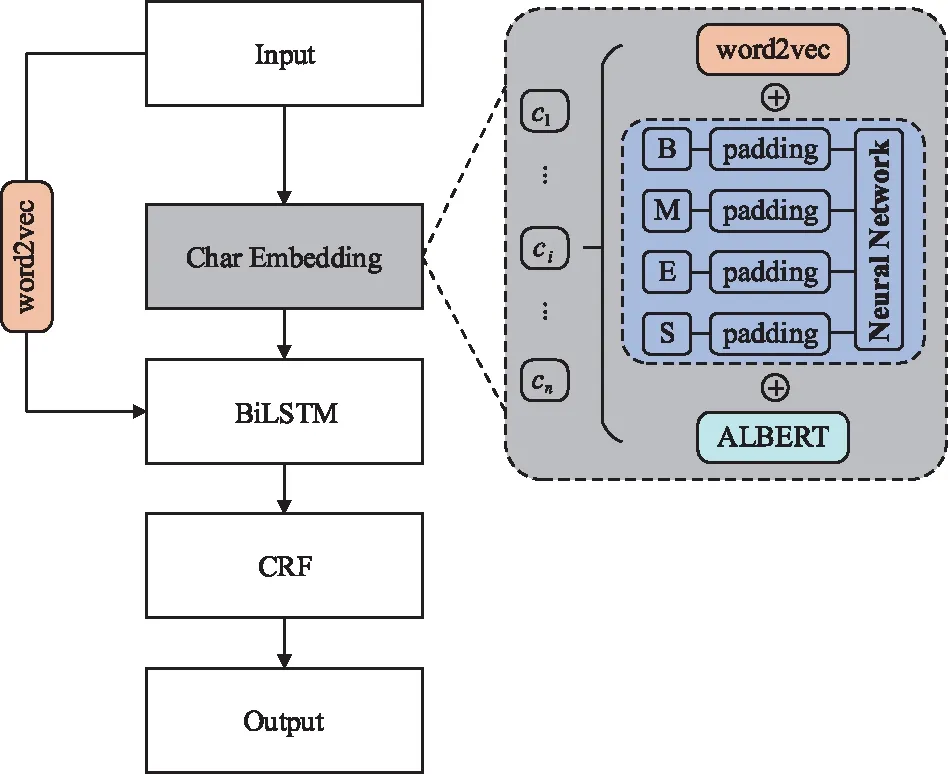
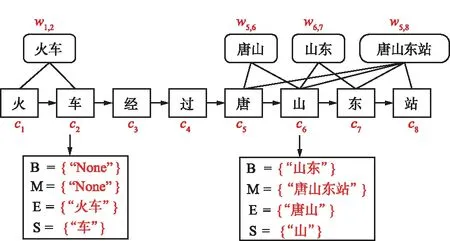
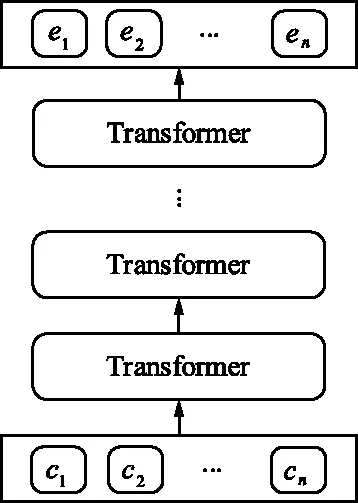
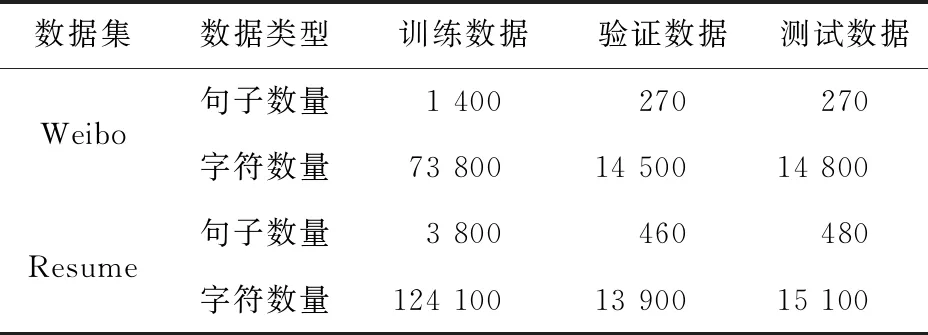
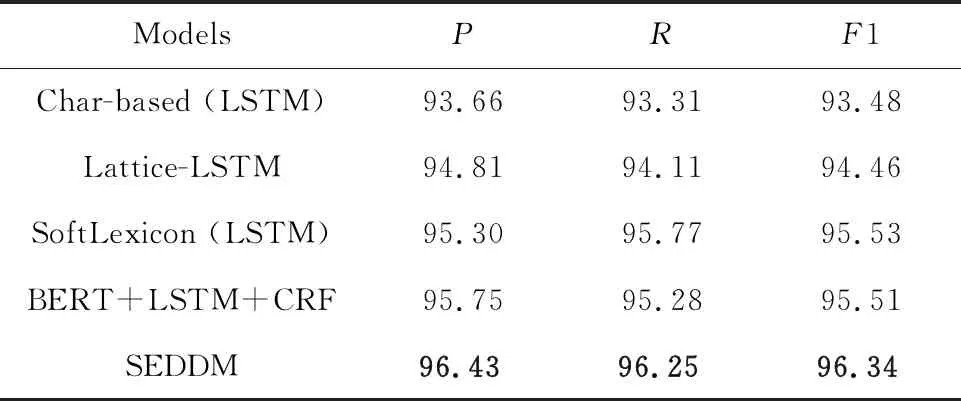
但是,纯粹基于字符的NER方法,其缺点是没有充分利用词组的信息,考虑到这一点,Zhang等[17]提出了Lattice-LSTM模型,其设计将词汇信息,整合到基于字符的神经网络模型中。为了达到这个目的,首先对输入的句子执行词汇匹配。如果对于i 然而,Lattice-LSTM的模型结构太复杂,使得模型训练和预测速度变慢;此外,很难将Lattice-LSTM的结构迁移到其他神经网络模型中(例如CNN[18]、Transformers[19])。为了解决这些问题,Ma等[14]提出了SoftLexicon模型,该方法利用字符在匹配词组中的位置,分为“B,M,E,S”4个词集标签,并使用静态归一化的方法,将这4个词集进行权重分配,最终将词集信息合并到字符表示中。由于只是改变字符的特征表示,所以可以使用通用的序列建模层和标签推理层。 本文提出一种新的基于字典的动态词组权重语义增强模型SEDDM神经网络来获得词集“B,M,E,S”的权重,并引入ALBERT预训练模型特征,增强字符的特征表示。在2个数据集上,获得较好的结果。 在本文中,保留SoftLexicon的优点,同时克服其缺点。为此,提出了一种新的方法,通过神经网络来调整匹配词组各个标签的权重,使得模型具有更好的推广能力。本文将此方法称为基于动态词典匹配的语义增强中文NER算法,模型如图1所示。 图1 基于动态词典匹配的语义增强中文命名实体识别算法模型 首先,对输入的句子在字符表示层获得字符的增强特征表示,其中,字符增强特征表示主要由3部分组成:① 将输入序列的每个字符映射为一个密集向量word2vec;② 将序列中相邻的字符在词典中进行词组匹配,并按照字符在词组中的位置,划分为“B,M,E,S”4个类别,由于标签中匹配到的词组个数不尽相同,所以经过padding为统一长度后,运用神经网络进行标签权重分配,得到词组的文本信息;③ 加入ALBERT预训练模型的字符特征表示,并将这些特征整合为每个字符的增强特征表示。然后,在序列建模层运用BiLSTM对字符的word2vec向量与字符增强特征进行模型训练;④ 将序列建模层输出,运用条件随机场识别出命名实体。 2.1.1 字符向量 对基于字符的中文NER模型,输入语句被视为字符序列s={c1,c2,…,cn}∈Vc,其中Vc是字符词汇表。每个字符ci用一个密集向量(嵌入)表示: 式中,ec表示字符嵌入的查找表。 2.1.2 词组匹配的标签分类 对于输入的句子,将各个字符与其临近的字符组成词组,在词典中进行匹配,所有匹配到词组的字利用4个细分标签“B,M,E,S”来记录。对于输入序列s={c1,c2,…,cn}中的每个字符ci,这4个集合构造如下: 式中,wi,j为子序列{ci,ci+1,…,cj},相当于组成的词组;L为使用的词典,对于某一个字符,如果词典中没有词组与之匹配,则用“None”来表示,词组匹配的分类如图2所示。 图2 词组匹配的分类 利用词典匹配的方法,找到每个字符所匹配到的词组,并对这个字符在词组中的位置进行标签分类。其中,B表示字符处于词组的开始,M表示字符处于词组的中间,E表示字符处于词组的结尾,S表示单个字符。在输入句子“火车经过唐山东站”中,以字符c6(“山”)为例,可以在词典中匹配到的词组有w5,6(“唐山”)、w5,8(“唐山东站”)和w6,7(“山东”)。其中c6处于w6,7的开始,所以将词组“山东”归类到标签B中;c6处于w5,8的中间,将词组“唐山东站”归类到标签M中;c6处于w5,6的末尾,将词组“唐山”归类到标签E中。 2.1.3 词集标签权重 获得每个字符的“B,M,E,S”标签词集后,求得4个标签的最大长度lenmax,将标签长度小于lenmax的进行0向量填充,然后将填充后的标签向量输入到神经网络中。 特别的,设z(w)表示词典的词组w出现在统计数据中的频率,得到词集S的权重表示如下: vs(S)=g(Z·w1+b1)·w2+b2 , 其中, , 式中,ew为词嵌入查找表;p(·)为进行0向量填充;g(·)为ReLU激活函数。在这项工作中,统计数据集是由训练和验证数据集组成。如果任务中有未标记的数据,则该未标记的数据集可以作为统计数据集。此外,值得注意的是,如果词组w的子序列覆盖了另一个短词组,则w的频率不会增加,这避免了短词组的频率总是小于覆盖它的长词组的频率的问题。 2.1.4 ALBERT预训练模型 ALBERT预训练语言模型采用双向Transformer获取文本的特征表示。其模型结构如图 3所示。其中c1,c2,…,cn表示序列中的每一个字符,经过多层双向Transformer编码器的训练,最终得到字符的特征向量表示e1,e2,…,en。Transformer的模型结构为Encoder-Decoder,ALBERT采用的是其 Encoder部分,该部分由多个相同的基本层组成。其中,每个基本层包含2个子网络层:第1个为多头自注意力机制层;第2个为普通前馈网络层。 图3 ALBERT模型结构 2.1.5 字符增强特征 将4个词集的向量表示组合成一个固定维的向量特征。为了尽可能多地保留特征信息,选择将4个词集的特征连接起来,表示如下: es(B,M,E,S)=[vs(B);vs(M);vs(E);vs(S)]。 此处,vs表示词集S的权重。最后一步是特征合并,将词集特征与ALBERT预训练模型特征添加到字符的表示中,每个字符的增强特征表示为: 结合了词典信息与ALBERT预训练模型特征,然后将字符的向量表示与字符的增强特征输入到序列建模层,该层对字符之间的依赖关系进行建模。该层的通用架构包括双向长短时记忆BiLSTM网络,卷积神经网络(CNN)和Transformer模型。本文使用了单层BiLSTM来实现。其中,正向LSTM神经网络的定义为: ht=ot⊙tanh (ct), 在序列建模层之上,通常应用条件随机场来依次对整个字符序列进行标签推断: 可以使用维特比算法来有效解决。 本实验的数据采用中文Resume数据集、中文Weibo数据集,数据集统计结果如表1所示。在Resume数据集中,按照句子数量划分为:训练数据1 400、验证数据270和测试数据270,按照字符数量划分,分别为73 800,14 500,14 800个字符。同理,在Weibo数据集中,按照句子数量划分为:训练数据3 800、验证数据460和测试数据480,对应的字符数量分别为124 100,13 900,15 100个字符。 表1 数据集统计 Weibo数据集分为:named entities(NE)、nominal entities(NM)和Overall三种类型,分别表示常用的命名实体(NE)、宽泛的名义实体(NM)和二者均包含的实体(Overall)。比如:“画家”“书法家”在NE中不算作命名实体,但是在NM中却算作命名实体。 模型采用训练数据集训练,验证数据集验证,测试数据集评估,采用精确率(Precision,P)、召回率(Recall,R)、F1 值评估中文命名实体识别模型的性能,当且仅当一个预测标记的实体与真实实体完全匹配时才将其视为正确,计算公式如下: 测试数据集F1值(best_test)的更新条件为:在多轮的迭代中,若当前验证数据集的F1值(current_dev)比之前最佳F1值(best_dev)高的时候,则更新best_dev,best_test值: when current_dev > best_dev : best_dev = current_dev best_test = current_test。 实验在Pytorch 1.6.0中实现了所有的神经网络模型,将随机梯度下降法作为优化器,学习率learning rate设置为0.005,模型的batchsize设置为1,dropout大小为0.5,lstm隐藏层设置为500,迭代次数epoch设置为100,神经网络中间层大小为2×lenmax。 在实验中,GPU为NVIDIA RTX 2060 SUPER,模型在GPU上进行训练。在Weibo数据集上,100个epoch共训练了7 h;在Resume数据集上,100个epoch共训练了15 h。 实验结果对比方法:Peng等[20]提出使用3种类型的中文嵌入方法,利用NER的训练文本,对embedding进行微调;Peng等[21]提出对每一个在词的不同位置中出现的字,训练一个字向量的方法;He等[22]提出了一种基于BiLSTM神经网络的半监督学习模型;He等[23]提出了跨域学习和半监督学习的统一模型;Char-based(LSTM)是最常用的字符级命名实体识别方法;Lattice-LSTM是Zhang等[17]对Char-based(LSTM)的改进方法;SoftLexicon(LSTM)是Peng等[14]对Lattice-LSTM的改进方法;BERT+LSTM+CRF是加入预训练模型BERT后,结合传统LSTM+CRF得到的结果;SEDDM表示本文提出的基于动态词典匹配的语义增强中文命名实体识别算法。 不同模型在Resume数据集上的实验结果如表2所示,相比Char-based(LSTM),本文提出的模型F1值提高了2.86%,说明引入词组信息的有效性;相比Lattice-LSTM,模型F1值提高了1.88%,表明对词组信息整合到字符表示特征中,能拥有更好的表现能力;相比SoftLexicon(LSTM),模型F1值提高了0.81%,表明对词组标签集运用神经网络加权的有效性;相比BERT+LSTM+CRF,模型F1值提高了0.83%,表明ALBERT和词组信息的有效性。总体来看,本文提出的模型拥有比之前模型更好的表现结果,也验证了本文工作的有效性。 表2 Resume数据集的模型结果 不同模型在3种类型的Weibo数据集上的实验结果如表3所示,均为F1值。相比利用了字符嵌入特征的Peng等[20-21]提出的模型,以及跨域学习和半监督学习的He等[22-23]提出的模型,在所有3个数据集上,本文所提出的SEDDM方法的表现,F1值比上述最优方法分别提高了16.66%,3.51%,10.99%;同理,相比Char-based(LSTM)、Lattice-LSTM、SoftLexicon(LSTM)和BERT + LSTM + CRF模型,本文所提出的SEDDM方法,拥有更好的表现结果。 表3 3种Weibo数据集的模型结果 可以看出,在模型整体表现比较差的时候,对NE数据集的识别率比较低,对NM数据集的识别率比较高;当模型整体表现更好的时候,对NE数据集的识别率却变得更高。所以可以看出,模型简单的时候,能较好地识别出宽泛的实体,对于精确的实体表现较差;当模型复杂的时候,对精确的实体表现更好。 对比表2和表3可以看到,相同的模型在Resume数据集与Weibo数据集上的实验结果有较大差异,观察2个数据集的构成,因为Resume数据集中,命名实体所占的比例更大更集中,而Weibo数据集中,命名实体的分布相对比较稀疏。所以,模型在2个不同的数据集上拥有较大的结果。 本文提出了一种基于动态词典匹配的语义增强中文命名实体识别算法,对输入句子中的字符在词典中进行词组匹配,利用4个标签“B,M,E,S”来表示字符在词组中的位置,使用动态权重将字典信息整合到字符表示中,添加ALBERT预训练模型来增强字符的表示,并基于BiLSTM进行序列建模,在中文Resume、Weibo数据集下,相比于之前的方法,其F1值有所提升。2 基于字典的动态注意力权重语义增强模型
2.1 字符表示层

2.2 序列建模层

2.3 标签推理层

3 实验结果与分析
3.1 数据集和评估指标
3.2 参数设置
3.3 实验结果和分析

4 结束语
猜你喜欢
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
英语文摘(2019年5期)2019-07-13
数字通信世界(2019年3期)2019-04-19
中关村(2014年5期)2014-05-15
高中生学习·高三版(2014年3期)2014-04-29
