
基于多模态联合注意力机制的网民情感分析研究
2021-07-17 14:59范涛吴鹏王昊凌晨
情报学报 2021年6期
范涛,吴鹏,王昊,凌晨
(1.南京大学信息管理学院,南京 210023;2.南京理工大学经济管理学院,南京 210094)
1 引言
舆论是网络舆情的空间载体,网民情感是舆论的观点和态度的一种体现[1]。在网络舆情事件中,网民情感对网络舆情事件的发展和演化有着极大的影响。例如,在新冠肺炎(COVⅠD-19)疫情中,对“武汉医生被训诫谈话”“武汉红十字会物资分发”等事件被彻查的背后,除了客观因素外,网民的负面舆论和由此折射出来的负面情感对事件的发展都有着推波助澜的作用。因此,如何在网络舆情事件中,自动准确识别网民情感是极其重要的。
目前,已有文献对网民情感分析做了相关研究。例如,Wu等[2]利用OCC(Ortony,Clore,Collins)模型建立文本情感标注规则,并利用卷积神经网络对文本进行情感分类;Zhang等[3]建立扩展的情感词典,结合机器学习模型对文本进行情感分类。从上述研究中可以看出,情感分析的对象皆为文本内容。然而,随着社交媒体平台的不断发展,文本不再是网民表达观点和态度的唯一内容载体。采用文本结合图片或者短视频,以一种多模态相结合的形式进行表达,已逐步成为网民倾诉心声的偏爱方式[4]。虽然通过融合不同模态的情感特征,能够有效地提升模型情感分析的性能,但这仍是一项具有挑战性的任务。
不同的模态本质上是相互异质的,然而在内部特征中,模态之间是相互关联的。如何有效地捕捉这样的交互关系,是多模态情感分析的关键,并且已有研究做了相关探索。例如,Majumder等[5]提出一种结合上下文的高维融合建模方式,将文本、声音和图片等模态多次进行高维融合,从而获得融合后的特征。然而,基于注意力机制原理,能够体现文本、图片或音频的情感,仅集中于文本中的部分词或图片和音频中的部分区域,融合模态整体信息则会引入噪声,并造成信息冗余。Huang等[6]基于注意力机制,分别对文本和图片进行建模后,将生成的具有关键特征的文本和图片向量进行融合,输入至全连接层中,从而预测情感。然而,在现实中,体现文本情感的某个关键词和图片中的部分区域存在着对应关系。例如,在图1中,体现微博情感的“最美逆行者”和图片中的“医生形象”相关,和图片中的其他区域联系较弱。因此,如果对不同模态内容单独进行注意力机制建模,那么将无法捕捉这样的关系。

图1 多模态数据样例
为了有效捕捉不同模态之间的交互,充分学习不同模态的特征,减少模型训练中的冗余信息,从而提升多模态情感分析模型的性能,本文借鉴Zhang等[7]提出的用于命名实体任务中的自适应联合注意力机制,提出了多模态联合注意力机制情感分析模型(multimodal co-attention sentiment analysis model,MCSAM)。MCSAM主要由多模态联合注意力机制和中间层融合策略组成。多模态联合注意力机制是由词引导的注意力机制和图引导的注意力机制构成的。其通过让文本中的词来引导图片区域的情感权重和让新生成的图片情感向量引导句子中词的情感权重,捕捉不同模态之间的关联和交互关系,并生成具有深度语义的文本和图片特征向量。然后,利用中间层融合策略融合文本和图片的表示向量,并输入至多层全连接中,生成预测的情感标签。本文的主要贡献如下:
•本文提出基于多模态联合注意力机制的网民情感分析模型。该模型能够充分捕捉到模态交互后的注意力分布,并且有效减少模态中的冗余信息和噪声。
•本文结合“新冠肺炎疫情”等多模态网络舆情的数据进行实证研究,并同其他state-of-the-art模型,如MAM(multimodal attention model)、TFN(tensor fusion network)等,进行对比分析。实验结果验证了MCSAM的优越性。
本文的其余部分安排如下:第2节介绍了目前的相关研究进展,第3节详细描述了本文所提出的模型,第4节为实证研究,第5节为总结和展望。
2 相关研究
2.1 网民情感分析研究
网民情感对网络舆情事件的酝酿、爆发和消解整个过程都具有重要的影响。吴鹏等[8]结合情感词向量和双向长短期记忆网络,对网民的负面情感进行了多分类研究。辜丽琼等[9]利用词向量和K-means聚类方法对网民的评论进行了情感追踪分析。夏一雪等[10]利用仿真的方法对突发事件中网民的负面情感进行了分析。朱晓霞等[11]结合改进的TF-ⅠDF方法和LDA模型提取文本的关键情感词,进行网民情感的演化分析。张鹏等[12]基于构建的突发事件情感词典,并结合TF-ⅠDF等方法对网民情感进行分析。
从上述研究中可以发现,目前,网民情感分析的研究对象主要基于文本,缺乏结合多模态内容的研究。
2.2 单模态情感分析研究
1)文本情感分析
现有的文本情感识别方法分为基于词典的方法、基于统计的方法和基于深度学习的方法[13]。基于词典的方法主要依靠语言学,利用人工构建的情感词典,从而识别句子中的情感词或者规则,并以此进行文本情感分析[14]。但是此类方法严重依靠情感词典规模和质量,并且存在扩展性差、迁移性差等问题。基于统计的文本情感识别方法主要是采用机器学习方法,将人工标注的训练预料作为训练集,抽取文本情感特征,并利用该模型进行情感分类[15-16]。
深度学习作为机器学习发展的一个研究热点,被应用至自然语言处理任务中。例如,Kim[17]提出用于文本情感分析的1d-CNN(one-dimensional convolutional neural network),并取得了良好效果。Ma等[18]提出了一种带有高维注意力机制的扩展的长短期记忆网络(long short-term memory,LSTM)网络,该网络能够聚合同情感相关的常识知识,并表现优越。
2)图片情感分析
相较于文本情感分析,图片情感分析由于受限于人类情感与图片语义间的“情感鸿沟”,因此其任务更具有挑战性。传统的图片情感分析方法主要利用手工特征,如线条[19]、颜色[20]、亮度[21]等,作为图片的表示向量,然后将其输入至分类器中,进行情感分类。
卷积神经网络(convolutional neural network,CNN)[22]能够学习图片中复杂且抽象特征,并在多个计算机的视觉任务中获得成功,有学者将其应用至图片情感分析中。例如,Chen等[23]提出一个包含多个CNN的深度神经网络对图片情感进行分类,模型性能显著优于传统的机器学习模型。Yang等[24]提出一个考虑图片局部区域信息和整体信息的图片情感识别模型,并取得了良好的效果。Campos等[25]通过迁移预训练模型的权重,并对其进行微调操作,从而提升模型性能。
2.3 多模态情感分析研究
从模态融合的视角来看,多模态情感分析研究可分为特征层融合、中间层融合和决策层融合等[26]。
在特征层融合中,通过拼接、相加等方式融合不同模态的特征,形成单一的长向量,并输入至分类器。例如,Poria等[27]将文本特征、音频特征以及面部特征相拼接,生成融合后的特征向量,并将其输入至多核SVM(support vector machine)中,完成情感分类。Pérez Rosas等[28]拼接视频中,不同模态的特征,输入至SVM分类器中进行情感分析。然而,特征层融合后生成的多模态融合特征,不能很好地捕捉模态之间的相关关系,并包含冗余特征和噪声。
中间层融合通常发生于深度神经网络中,通过对不同模态的特征进行编码,形成相应的特征表示,并进行融合。例如,Zadeh等[29]提出张量融合模型,通过将编码后的不同模态的特征进行外积,形成空间上的3维立方体,作为融合后的多模态特征,输入至全连接层中进行情感分类。Huang等[6]结合注意力机制,对文本和图片分别进行建模,对新生成的文本和图片特征向量进行融合,并进行情感分类。虽然基于中间层融合的方法均取得了较好的效果,但是捕捉网络中模态的交互依然是难点。
在决策层融合中,不同的模态独立建模,利用基于规则或者投票的方法,对不同模态情感分析模型输出的情感类别概率进行融合,生成情感标签[30]。例如,Song等[31]利用不同的网络输出不同模态的情感预测概率,并将其融合输入至人工神经网络或k最邻近算法中,产生最终情感标签。对于决策层融合,不同的模态能够选择最优的模型进行情感类别概率预测,然而模态间的关联和交互没有被充分考虑。
3 模型设计
本文提出的基于多模态联合注意力机制的网民情感分析模型结构如图2所示,其主要由多模态联合注意力机制和中间层融合策略组成。多模态联合注意力机制分为词引导的注意力机制和图引导的注意力机制,两者分别捕捉文本和图片交互后的注意力分布,从而生成新的特征表示向量;然后,通过中间层融合策略,融合文本和图片特征,并输入至多层感知机中,产生最终的情感预测类别。下文将详细描述提出的算法和模型。
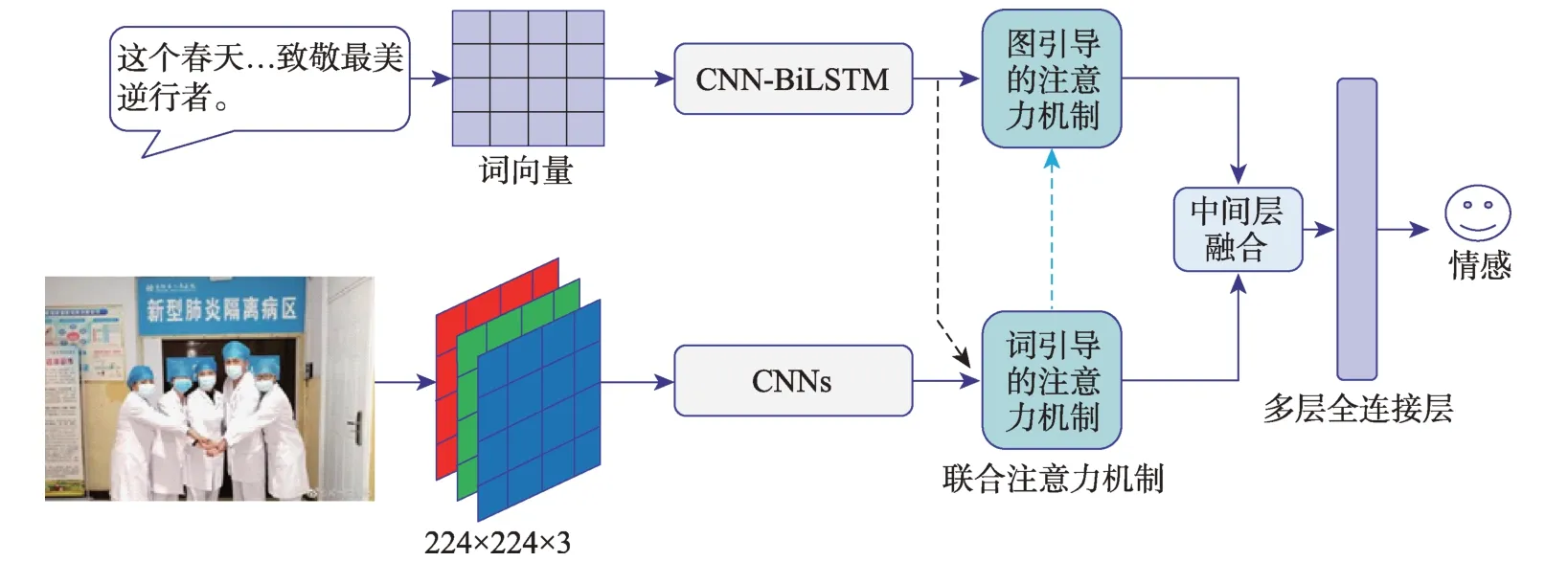
图2 基于多模态联合注意力机制的网民情感分析模型
3.1 图片特征提取
CNN在多个视觉任务中取得了巨大成功,并被应用至图片情感分析中。对于图片特征提取,常用的方法有利用预训练图片模型中的全连接层提取图片的特征,或者利用传统的手工特征。为了获得图片中不同区域的空间特征,本文利用在ⅠmageNet[32]中预训练的VGG16(visual geometry group 16)[33]模型中的最后一层池化层(pool5),提取图片的空间特征。VGG16网络中pool5输出的特征图大小为7×7×512,其中512为特征向量的维度;7×7为特征图的数量。令v={v1,v2,v3,…,vi,…,vn}表示与网络舆情文本相对应的n张图片。经过pool5层抽取得到的图片特征,j=1,2,…,N},那么图片特征中j区域的特征维度为512,区域数量为N=49。
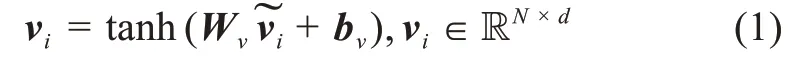
其中,Wv表示全连接层中的权重;bv表示偏置项;d表示输出维度;tanh为双曲正切激活函数。
3.2 文本特征提取
本文利用word2vec(word to vector)[34]模型对大规模网络舆情文本进行无监督训练,获得富含句法信息和语义信息的词向量,作为模型输入。令t={t1,t2,…,ti,…,tn},其中t表示网络舆情图文数据集中的文本。对于每一个文本ti,本文利用在大规模网络舆情文本中训练好的词向量模型Vec对其进行向量化表示,则l={l1,l2,…,li,…,ln},并且
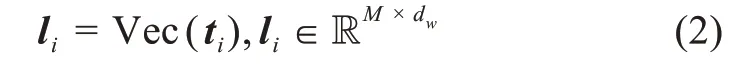
其中,M为句子长度;dw为词向量的维度。本文将l={l1,l2,…,li,…,ln}作为网络舆情文本的表示。
3.3 CNN-BiLSTM模型
常用的文本情感分析模型有LSTM[35]、CNN[17]等。例如,吴鹏等[36]提出结合OCC模型和CNN模型分析网民情感,并输出三种情感类别;金占勇等[37]提出利用LSTM模型,对突发灾害事件网络舆情情感进行识别。LSTM作为RNN的变体,能够巧妙地控制其独特的门结构,有效地学习上下文的语义信息,是一种优异的序列模型。通过卷积核在窗口中的滑动,CNN能够有效的学习句子中的n-gram特征,生成由词组成的短语向量。不同于上述的研究,本文提出结合CNN和LSTM的CNN-BiLSTM模型,结合了两种模型的优点,对向量化表示的网络舆情文本进行特征抽取。对输入的由词向量表示的句子,j=1,2,…,M}进行卷积操作,其中M表示句子的长度。令表示卷积核,卷积核数量为z,s表示卷积核(窗口)大小,经过卷积核wk卷积得到的特征图为
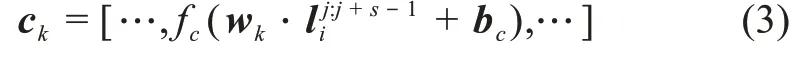
其中,bc为偏置项;fc为非线性激活函数relu。对卷积后得到特征图谱进行最大池化,用于聚合特征,降低数据敏感度,输出的最大池化特征图谱=max(ck)。本文对卷积进行了填充操作,经过卷积池化输出的句子特征表示为li'。然后,本文将短语特征向量表示的句子特征li'与词向量表示的句子特征li相拼接,生成富含短语特征和词特征的句子表示矩阵li'',作为BiLSTM网络的输入。BiLSTM是由双向的LSTM构成的,前向LSTM能够通过时间顺序传递序列信息,反向LSTM能够逆序传递序列信息,从而能够更好地学习上下文信息。LSTM由输入门、遗忘门、输出门以及细胞状态组成,通过结合每个门所用的公式,学习具有时间依赖的句子表示,j=1,2,…,M},其中,d为BiLSTM编码后的特征维度,M为句子长度,具体公式为
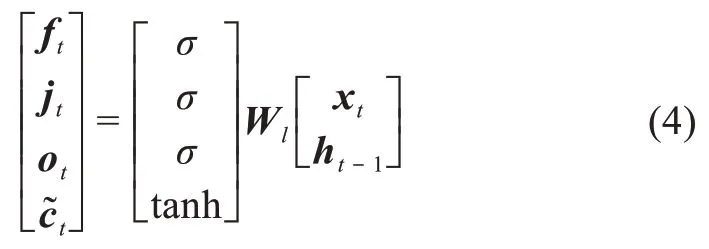

其中,Wl表示权重矩阵;ft、jt、ot分别表示t时刻的遗忘门、输入门和输出门;xt为t时刻的输入;⊙表示点乘操作;σ表示sigmoid激活函数;tanh表示双曲正切激活函数。
3.4 多模态联合注意力机制
本文中的多模态联合注意力机制由词引导的注意力机制和图引导注意力机制构成,具体如图3所示。
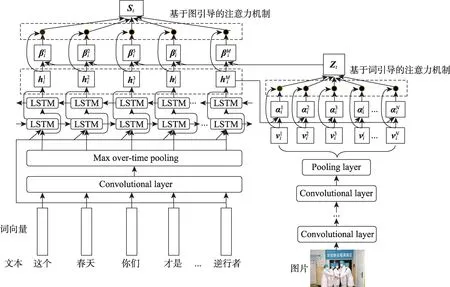
图3 多模态联合注意力机制
3.4.1 词引导的注意力机制
在多模态情感分析研究中,已有关于注意力机制的研究。例如,Huang等[6]提出深度多模态注意力融合模型,通过对文本和图片分别进行注意力机制建模,将提取的文本和图片注意力权重进行融合,输入至全连接层中,从而获得情感标签。然而,在现实中,体现文本情感的词仅和图片中的部分区域相关联。如果忽略图片和文本之间的关联,分别进行注意力机制建模,那么会影响模态间的整体交互。不同于这些已有的研究,本文利用词引导的注意力机制,通过利用编码后的词来引导图片中各个区域的注意力分布,充分捕获文本和图片之间的交互和关联关系,同时减少冗余信息和噪声。
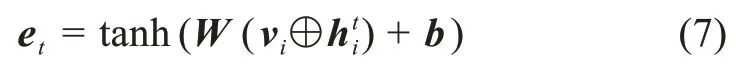
其中,W表示全连接层中的权重矩阵;b表示偏置项;⊕表示拼接操作。拼接操作具体是指vi中的每一列向量同相拼接。本文利用softmax函数来计算注意力权重αt:
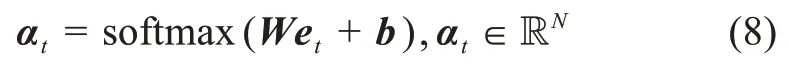
在注意力机制中,图片中的每一个区域均会被分配一个介于[0,1]区间的得分αt,j(1≤j≤N)作为注意力权重。最后,基于注意力权重分布,得到新生成的与词相关的图片特征向量Zt:
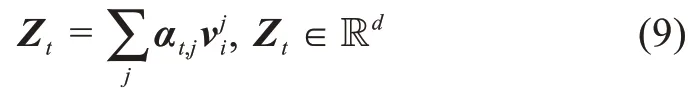
3.4.2 图引导的注意力机制
通过词引导的注意力机制,本文获得图片的新特征表示。而在文本中,不同的词与文本情感的相关性是未知的。因此,本文结合图引导的注意力机制,通过引入新生成的图片特征Zt来引导文本的词进行注意力权重计算。经过编码后的句子特征矩阵为,j=1,2,…,M},M为句子长度,d为编码后特征维度。将句子特征矩阵hi和对应的图片特征向量Zt输入至一层全连接层中,进行非线性激活,得到归一化后的特征e't:
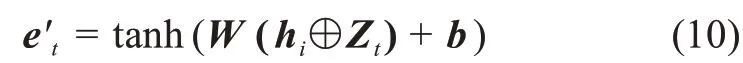
其中,W表示权重矩阵;b表示偏置项;⊕表示拼接操作。拼接操作具体指hi的每一列向量同Zt相拼接。本文利用softmax函数来计算注意力权重βt:
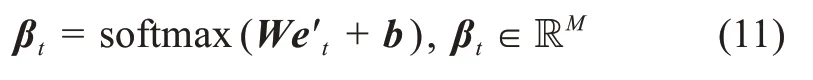
在注意力模型中,句子中的每个词均会被分配一个介于[0,1]之间的得分βt,j,1≤j≤M,作为注意力权重。最后,基于注意力权重分布,得到新生成的与图片特征Zt相关的句子特征向量St:
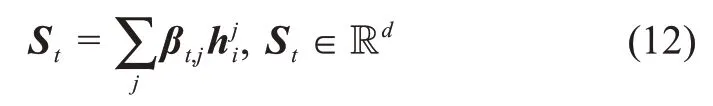
3.5 多模态融合
通过词引导的注意力机制和图引导的注意力机制,本文分别得到新的文本和图片特征St和Zt,利用中间层融合方式,将文本特征St和图片特征Zt进行融合。
本文将St和Zt融合输入至多层全连接层中,对融合后的特征进行编码,用于最终的情感分类:
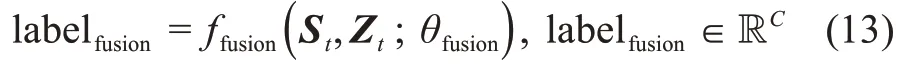
其中,labelfusion代表模型预测的情感标签;θfusion代表全连接层中的参数;C代表情感类别数量。
4 实证研究
本节将首先介绍实验环境及评价指标,然后介绍本文所用的数据集及数据的预处理过程。最后,本文将提出的模型在网络舆情事件数据集中进行验证,并同基线模型作对比,报告的结果均为最优结果。
4.1 实验环境及评价指标
本文所用的编程语言为python 3.6,使用的深度学习框架为pytorch 1.0.1和keras 2.2.4。本文的实验均在内存为8G、处理器为Ⅰntel Core i7-7700HQ的机器上完成。为了排除其他不必要因素对实验产生的影响,实验中每个模型所用的训练集与测试集均一致。其中,实验数据集的80%作为训练集,剩余的20%作为测试集。
本文实验所用评价指标为宏平均精确率(marco-precision)、宏平均召回率(marco-recall)和宏平均F1值(F1-score)。在本文中,上述指标分别简称为P、R及F1值。
4.2 实验数据集获取及预处理
1)数据集获取
本文从新浪微博中搜集了近期发生的网络舆情事件数据,包括“新冠肺炎疫情”“武汉红十字会”等网络舆情事件。搜集的数据集包含2459个文本和图片对,均为对应关系。数据示例如图1所示。除此之外,本文还从微博中抓取了近年发生的网络舆情事件数据,用于训练词向量,对数据进行清洗后,获得总计2911235条文本。
2)数据集预处理
在实验开始之前,本文对中文数据进行了预处理。首先,本文对微博中的一些无意义符号进行去除,利用python中jieba①https://pypi.org/project/jieba/包并结合本地词典对文本进行了分词处理,同时利用停用词词典对文本进行了去停用词处理。对于图片,本文利用python中的CV2②https://pypi.org/project/opencv-python/读取图片,并将图片的大小调整224×224×3,适应本文所构建的图片情感识别模型的输入。
3)数据集标注
本文对实验数据集进行了双人标注,标注的情感分别正面、中性和负面。实验数据集由两位信息管理与信息系统专业本科生进行情感标注,其有着多年的社交媒体使用经验,标注结果的kappa系数为0.747,标注结果具有较高的一致性。对于不一致的标注,通过讨论产生最终的情感标签,最终的情感标注结果如表1所示。

表1 情感标注结果
4.3 模型设置
本文利用word2vec中的skip-gram模型训练词向量,词向量维度设置为100。文本长度设置为50,如果文本长度超过50,那么截断;反之,则补零。卷积层卷积核大小设置为2,数量为256。图片输入大小为224×224,带有RGB三通道。本文利用预训练VGG16模型中的pool5层提取图片的空间特征,大小为7×7×512,图片特征区域数量为7×7,维度大小为512。输入至一层全连接层中,激活函数为tanh,维度同CNN-BiLSTM输出维度相一致。融合后的多模态特征输入至两层特征维度分别为300和3的全连接层中,激活函数分别tanh和softmax。
在训练过程中,本文利用adam作为目标函数的优化器,学习率设置为0.001。损失函数为crossentrophy,训练批次大小为128,训练轮数设置为100。本文采用earlystopping技术,检测参数为损失值,当损失值连续10轮不下降,训练随即停止。
4.4 基线模型
本节介绍用于与提出的模型相对比的基线模型,其中有些模型在公开数据集中,达到state-ofthe-art效果。T表示文本,V表示图片。
•BiLSTM-T[8]是一种优异的用于处理文本等输入的序列模型,常被用于情感分析任务中。
•CNN-BiLSTM-T[38]模型由卷积层、池化层和全连接层组成,能够很好地捕捉文本空间特征,是一种优异的文本情感分类模型。
•CNN-BiLSTM-attention-T模型是本文提出模型的组成部分,对文本单独进行注意力机制建模,利用softmax层对新生成文本特征向量进行情感分类。
•CNN-V[33]是利用预训练的VGG16模型进行图片特征进行特征提取,输入至softmax层进行情感分类。
•CNN-attention-V模型是本文提出模型的组成部分,对图片空间特征单独进行注意力机制建模,利用softmax层对新生成的图片特征向量进行情感分类。
•SVM[28]是利用SVM用于对拼接后的文本特征和图片特征进行情感分类。
•MAM[6]是一个基于注意力机制的多模态融合情感分析模型,通过对不同模态分别进行注意力机制建模,能够有效地学习多模态情感特征。
•TFN[29]是通过对不同模态的情感特征进行高维融合,能够较好的捕捉不同模态间内部动态交互。
同时,本文还将仅使用词引导的注意力机制模型(word-guided attention,WGA)和仅使用图引导的注意力机制模型(image-guided attention,ⅠGA)进行对比。
4.5 实验结果及分析
1)单模态
表2呈现的是单模态情感分析结果。在文本模态中,通过对比CNN-BiLSTM和BiLSTM的实验结果,可以看出CNN-BiLSTM具有一定的优势。BiLSTM能够充分学习句子中的序列特征,结合句子中的过去信息和将来信息;CNN能够通过网络中卷积核在句子中的滑动充分学习句子的n-gram特征;而CNN-BiLSTM则属于两者优势的结合,这也是CNNBiLSTM表现优越的原因。对比应用了注意力的CNN-BiLSTM-attention和未使用注意力机制的CNNBiLSTM,可以看出引入注意力机制模型的优势,这同样也体现在图片情感分析模型CNN和CNN-attention的对比结果中。因此,引入注意力机制在情感分析中具有一定的优势,并能够提升模型性能。

表2 单模态情感分析结果
对比文本模态情感分析结果和图片模态情感分析结果可以发现,文本情感分析的结果显著优于图片情感分析结果。这表明,相较于图片,文本携带了更多富有情感的信息。
2)多模态
表3呈现的是多模态融合情感分析的实验结果。对比利用特征层融合的SVM模型结果,本文提出的模型MCSAM在三项评估指标中的结果均优于SVM约13%。这在一定程度上表明深度神经网络在学习和融合多模态特征上的优势。与利用高维融合的TFN模型进行对比,MCSAM模型的各项指标均优于TFN模型。虽然高维融合能够捕捉模态中的全面信息,但是同时也带来了信息冗余和引入噪声的风险,导致MCSAM模型达不到最优状态。而利用注意力机制恰好可以避免这一风险,本文通过为文本中的内容和图片内的不同区域分配不同的注意力权重,使得MCSAM模型多加关注文本和图片中富有情感信息的部分,弱化文本和图片中的噪声,从而令模型发挥最优。MAM是一种对不同模态分别进行注意力机制的多模态融合模型,在同MAM的对比中,应用了联合注意力机制的MCSAM依旧优于MAM。在精确率指标中,MCSAM高于MAM约2.46%。应用注意力机制能够使模型“刻意”关注模态中富含情感信息的区域,但是在多模态中,不同模态间语义是相互关联的。某一模态富含情感的部分仅和另一模态的某些部分或者区域相对应和联系。如果对不同模态单独建模,那么这样的关系便会被割裂,无法捕捉。而利用联合注意力机制,通过令文本中的词来引导图片区域中的注意力权重分布,生成词引导的图片特征向量,再利用新生成的图片特征向量引导文本中词的注意力权重分布,生成图引导的文本特征向量,则可以充分捕捉不同模态间富含情感区域部分的相互关联关系,这也是MCSAM优于MAM的原因。在同WGA和ⅠGA的对比中可以看出,采用中间层融合后的MCSAM显著优于WGA和ⅠGA,这充分说明词引导的注意力机制和图引导的注意力机制联合后的优势,同时,也展现出多模态融合在情感分析中的优势。

表3 多模态情感分析结果
4.6 参数敏感性分析
BiLSTM中的隐藏单元数和dropout值是本文提出的模型中的重要参数。因此,下文评估了不同参数的变化给模型带来的影响。
由图4可以看出,当模型引入dropout技术后,模型的性能得到了显著提升。这表明dropout技术在克服模型过拟合中具有优越性。当dropout值的增大,模型的性能总体上呈现下降趋势;当dropout值达0.1时,模型的性能取得最优。
在模型中,为了便于计算,模型中全连接层、文本及图片特征向量的维度数同CNN-BiLSTM中的输出维度数相同,即与BiLSTM中的隐藏层单元数相关。由图5可以看出,不同的隐藏层单元数对模型的性能有着显著的影响。当隐藏层单元数为300时,模型达到最优。因此,本文所提出的模型中BiLSTM的隐藏层单元数设置为300。
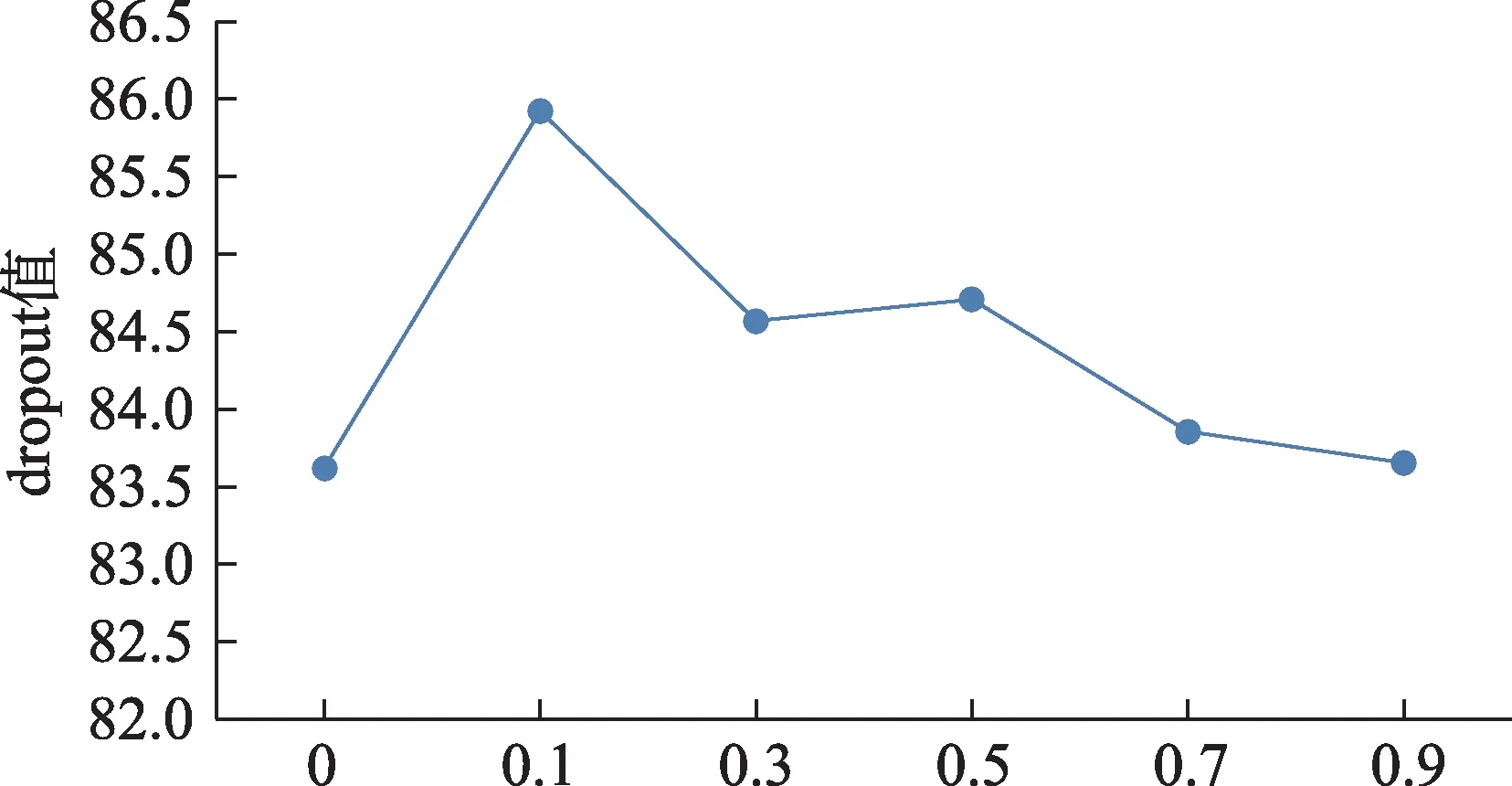
图4 dropout值对模型性能的影响
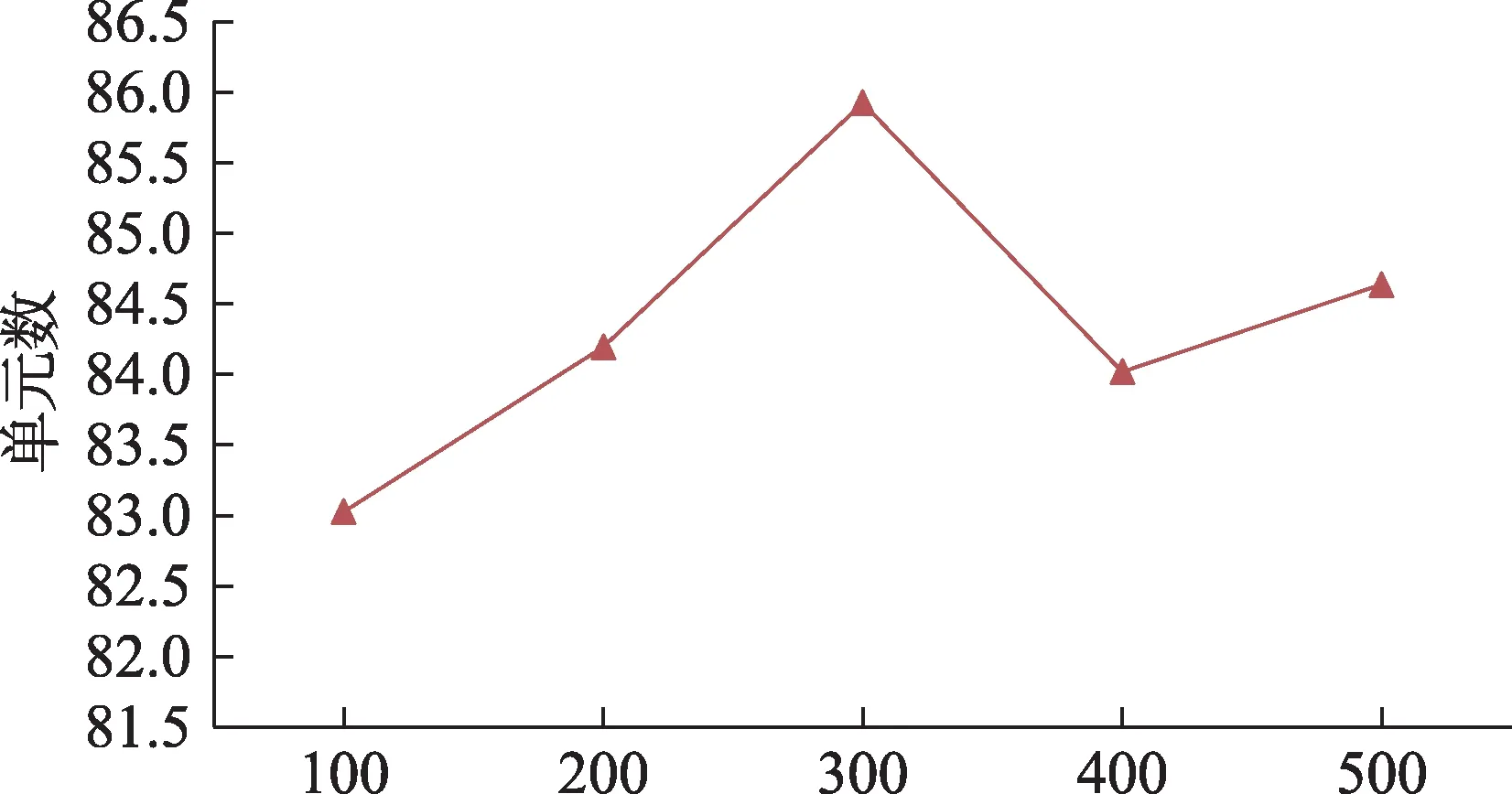
图5 隐藏层单元数对模型性能的影响
5 总结与展望
针对当前网民情感的分析不足,本文引入了一种基于多模态联合注意力的网民情感分析模型。通过联合词引导的注意力机制和图引导的注意力机制来动态捕捉不同模态之间的关联关系,减少信息冗余和噪声,并对新生成的文本和图片特征向量进行中间层融合,输入至多层全连接层中,生成预测的情感标签。本文所提出的模型在真实数据集中进行了实证研究,并与不同的基线模型进行对比分析,实验结果表明,本文提出的模型具有一定的优势。
同时,本文也存在一些不足,如所提出的模型仅在中文数据集中进行了验证。在未来的研究中,将所提出的模型在推特舆情数据集以及公开数据集进行测试,以验证模型性能。同时,如何更好地捕捉不同模态间的关联和交互也将是未来研究的重点。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
甘肃教育(2020年22期)2020-04-13
当代陕西(2019年9期)2019-05-20
文苑(2018年21期)2018-11-09
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年12期)2015-12-10
中国火炬(2014年4期)2014-07-24
